01
架构概览
Zookeeper 提供了配置服务、分布式同步、命名服务、Leader 选举和集群管理等功能,在大数据时代的开始很多开源产品都依赖 Zookeeper 来构建,Apache Kafka 也不例外。但是随着 Kafka 功能的演进和应用的场景越来越多:
基于 Zookeeper 的协作模式,使得 Kafka 的集群一致性维护越来越复杂;
受到 Zookeeper 性能的限制,使得 Kafka 无法支撑更大的集群规模;
并且 Zookeeper 自身带来的运维复杂性和产品稳定性,也同样将复杂度和风险负担传递到 Kafka 运维人员;
因此作为 Zookeeper 的替代,Kafka 3.3.1 提供了 KRaft 元数据管理组件。下图来自于 KIP-500 [1]提案,左右分别是 Zookeeper 模式和 KRaft 模式的部署架构图。
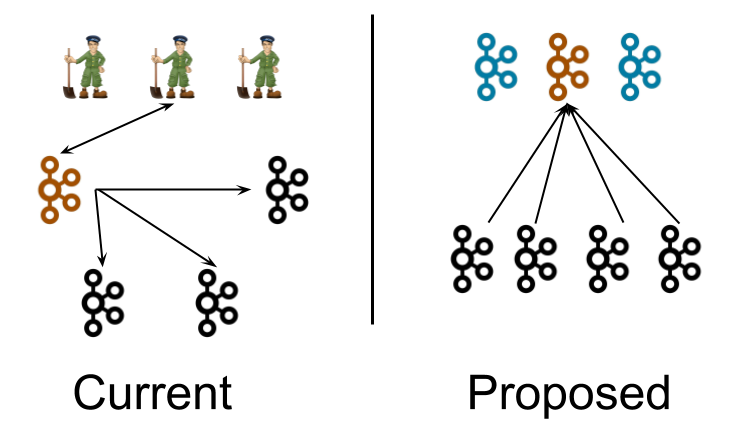
在 Zookeeper (后面简称为 ZK)模式下:
运维部署:3 个 ZK 节点;2..N 个 Broker 节点,其中一个 Broker 承担 Controller 的角色。除了拉起一套最小生产的 Kafka 集群需要至少 3 + N 的资源外,Kafka 的运维人员要同时掌握 ZK 和 Kafka Broker 两套完全不同的系统的运维方式。
通信协调:ZK 节点之间通过 ZAB 协议进行一致性协调;Broker 会通过 ZK 来选出一个 Controller 负责全局的协调,同时也会直接修改 ZK 里的数据;Controller 也会监听和修改 ZK 里的数据,并调用 Broker 来完成集群的协调。虽然 ZK 之间的一致性由 ZAB 来保障了,但是 ZK 与 Controller 之间和 Controller 与 Broker 之间的一致性是相对比较脆弱的。
在 KRaft 模式下:
运维部署:3 个 Controller 节点;0..N 个 Broker 节点。Kafka 节点可以同时承担 Controller 和 Broker 两个角色,因此一套最小生产集群只需要 3 个节点。在测试环境更可以只以 1 节点模式就可以轻量地拉起一个 Kafka 集群。
通信协调:Controller 节点底层通过 Raft 协议达成一致,Controller 的内存状态通过 #replay Raft Log 来构建,因此 Controller 之间的内存状态都是一致的;Broker 订阅 KRaft Log 维护和 Controller 一致的内存状态,并且通过事件驱动的方式执行 Partition Reassignment 之类的操作来实现集群最终一致性协调。整个集群的状态维护和一致性协调都是基于 KRaft 中的事件。
Raft 的原理和实现已经有很多优秀的文章介绍过了,就不在此赘述了。下面着重介绍一下 Kafka 如何基于 KRaft 实现集群的最终一致性协调。
02
最终一致性协调
最终一致性协调分为两部分:Controller 内存数据与 KRaft 的一致性;Broker (分区 / 配置 / ...)状态与期望的一致性。
2.1 Controller
Controller 在生产环境中通常由 3 个节点组成 Quorum,底层使用 KRaft 来进行一致性协调,KRaft 的 Leader 即是 Controller Leader。只有 Leader 会进行请求处理,Follower 只会跟随 Replay KRaft 中的数据,请求处理流程简要如下:
当 Leader 网络层接收到 Broker 发来的请求后,会将请求首先放入到事件队列中,由后台的单线程来处理事件队列中的请求。通过单线程处理机制简化了并发编程的复杂度,并且确保所有请求可以顺序处理;
单线程处理器运行请求对应的 Manager 逻辑。Manager 根据当前内存中维护的状态,生成响应和变更的 Records;
最后再把变更的 Records 提交到 KRaft 中,等多数派确认后就可以将响应返回,并 #replay(Records) 修改 Manager 维护的内存状态;
同时 Follower 也会将 KRaft 中的 Records #replay到内存中,内存数据持续的保持同步;
以 CAS(expectValue, newValue) 举例说明上述的流程,假设内存中的初始状态为 1,Broker Client 提交了请求 CAS(1, 2) 到 Controller:
首先 Leader 会将请求放到事件队列中;
然后 Manager 以单线程模式处理请求,判断内存中的值是 1,等于请求的 expectValue,因此生成成功响应和 Record{value = 2};
最后再把变更的 Records 提交到 KRaft 中,KRaft 确认后返回给请求方响应,并将 Record{value = 2} replay 到 Manager,Manager 内存状态更新为 2;
简而言之,Controller 简版的处理时序如下:开始处理请求 A -> Manager 生成响应和 Records -> Records 在 KRaft 多数派确认 -> Manager#replay(Records) -> 返回响应 -> 处理下一条请求...通过上述的处理时序,Controller 就可以做到“内存状态与 KRaft ”和“多节点之间的内存状态”的一致性:
内存状态与 KRaft :Controller 的内存状态都是基于 KRaft 确认的 Records 变更 #replay出来的,因此内存状态和 KRaft 保持一致;
多节点之间的内存状态:KRaft 底层保证了多节点的 KRaft Log 是一致的,然后基于 “内存状态与 KRaft” 的一致性,通过传递性原则,因此多节点之间的内存状态也是一致的;
Controller 简版的处理时序在正确性上没什么问题,但在性能上有所瓶颈。假设每次 KRaft 多数派确认需要 2ms,意味着 Controller 处理请求的最大吞吐为 500 req/s。因此 Kafka 的实际处理模型中将最耗时的 KRaft 确认这步从处理时序中移除了。具体流程如下图所示:
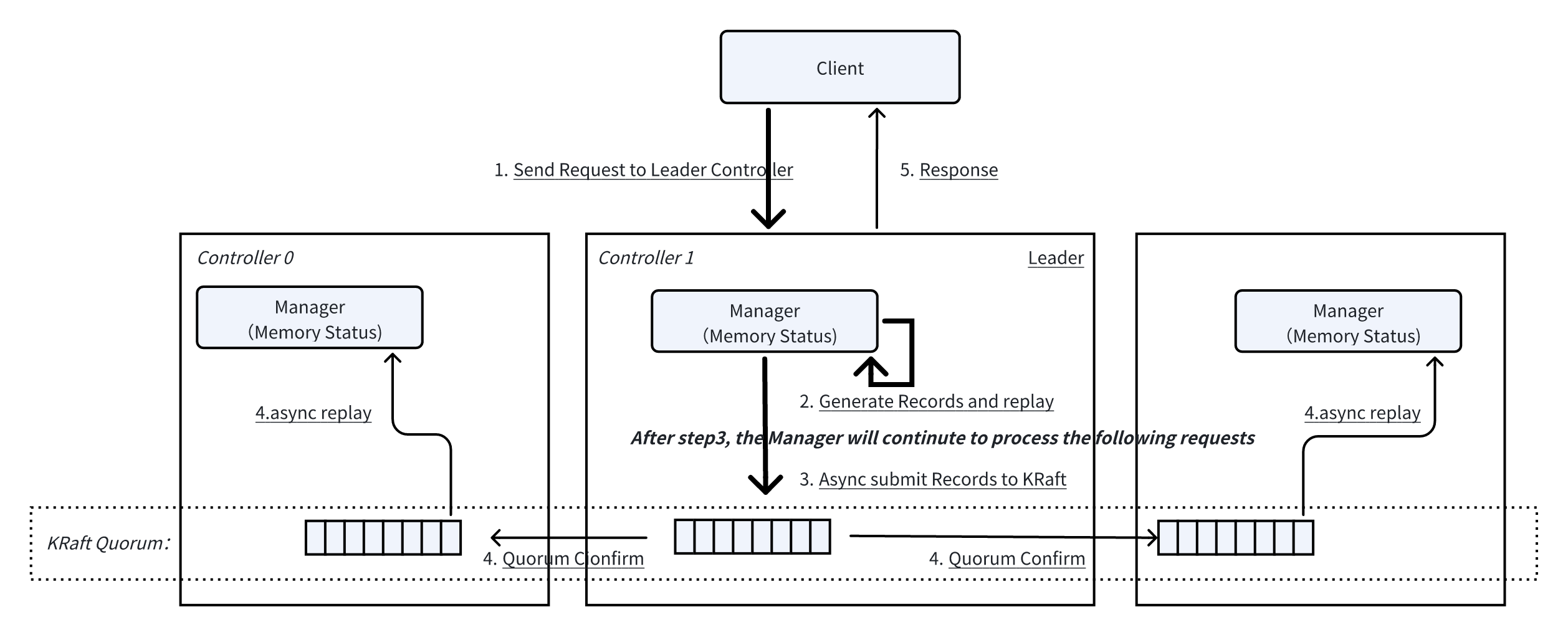
相比简版的处理时序:
Leader 的 Manager 产生出 Records 后立刻 #replay 更新内存状态,并异步提交 Records 到 KRaft,这时候就可以继续处理下一个请求了;
响应仍旧是 KRaft 多数派确认后再返回;
Follower 的内存状态仍旧是从 KRaft Log 的 Records #replay 更新;
Controller 处理请求的最大吞吐为:Min(1s / Manager 代码执行 CPU 耗时, KRaft 写入吞吐)。然而先 #replay 到内存再让 KRaft 确认可能会造成内存里面有脏数据,仍旧以 CAS(1, 2) 举例,考虑如下场景:
Controller Leader 的 Manager 通过 #replay 将内存值从 1 更新成 2;
Leader 提交 Record{value=2}到 KRaft;
假设这时候由于心跳超时抖动等原因,导致该节点不再是 KRaft Leader 了,这时候会提交失败,返回客户端失败;
这时 Controllers 节点内存中的状态分别为 2、1、1,KRaft 中的状态为 1,集群状态不一致;
为了解决这个问题,Kafka 设计了一系列支持 MVCC 的 Timeline 数据结构:TimelineHashMap、TimelineHashSet、TimelineInteger、TimelineLong 和底层的 SnapshotRegistry。Controller 的内存状态都通过 Timeline 数据结构来维护,当出现 Leader 切换时,旧的 Leader 会将 Timeline 数据结构的数据回滚到上一个已经被 KRaft 多数派确认的状态,来保证旧 Leader 内存中不会有脏数据。可能细心的小伙伴会发现,解决了写入的脏数据问题,那是不是可能读到还未被 KRaft 确认的数据呢?Timeline 数据结构也考虑到了这点,例如 TimelineLong 提供了 #get(epoch) 接口,其中 epoch 通常传入的是 KRaft CommitedOffset,以此来保障读到的数据都是 KRaft 确认过的数据。对 Timeline 数据结构有兴趣的小伙伴,可以自行研究一下 server-common 模块下 org.apache.kafka.timeline 这个包的实现。
2.2 Broker
在上一章节我们提到,Controller Follower 会 #replay KRaft 中的数据来构建自己的内存状态。Broker 同理也一样会订阅 KRaft 中的 Records 来构建自己的内存元数据,并且根据这些 Records 来执行特定的变更。以分区管理为例,假设集群有 B1 和 B2 两个节点,用户将分区 P1 从 B1 移动到 B2(简化 ISR 变更的过程):
Controller 处理分区移动请求,并生成 PartitionChangeRecord{P1=B2}提交到 KRaft;
B1 #replay到对应的变更记录,更新内存元数据记录 P1 在 B2 上,并开始关闭 P1;
B2#replay到对应的变更记录,更新内存元数据记录 P1 在 B2 上,并开始打开 P1;
这时候 B1 和 B2 都可以通过内存元数据提供一致的的 Topic Metadata 查询服务,并且完成了分区 P1 的移动。通过这种方式,很多变更 Controller 无需再主动调用 Broker 的 RPC 来尝试将集群推进到某个状态,也无需处理 RPC 调用中的顺序和幂等重试等问题。转换思路,Controller 通过 KRaft 来下发期望的状态,然后 Broker 去达成状态,这和 K8s 推荐的声明式管理有异曲同工之妙。
03
总结
我们可以看出 KRaft 替换 ZK,并不是元数据存储重新造轮子,而核心是集群协调机制的演进。整个通信协调机制本质上是事件驱动模型,也就是 Metadata as an Event Log,Leader 通过 KRaft 生产权威的事件,Follower 和 Broker 通过监听 KRaft 来获得这些事件,并且顺序处理事件,达到集群状态和期望的最终一致。
参考资料
[1] KIP-500 Replace Zookeeper with a Self-Managed Metadata Quorum:https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
[2] Timeline:https://github.com/apache/kafka/tree/trunk/server-common/src/main/java/org/apache/kafka/timeline
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com




![【YOLOv8改进[CONV]】SPDConv助力YOLOv8目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/903b12dde8914e6e968782bc23431980.png)