Transformer架构详解
- 前言
- Transformer的整体架构
- 多头注意力机制(Multi-Head Attention)
- 具体步骤
- 1. 步骤1
- 2. 步骤2
- 3. 步骤3
- 4. 步骤4
- Self-Attention应用与比较
- Self-Attention用于图像处理
- Self-Attention vs. CNN
- Self-Attention vs. RNN
- Transformer架构详解
- Encoder
- 位置编码(Positional Encoding)
- Decoder
- Decoder vs Encoder
- Cross Attention
- Train
- 结论
前言
在现代深度学习模型的发展中,自注意力机制(Self-Attention)和Transformer架构成为了诸多领域中的重要组成部分。自注意力机制通过捕捉序列数据中不同位置之间的关系,显著提升了模型的表示能力。而Transformer架构则利用多层自注意力机制和前馈神经网络(Feed-Forward Network, FFN),构建了强大且高效的序列到序列模型。本文着重介绍多头注意力机制(Multi-Head Attention)和Transformer架构,深入剖析其核心组件和工作原理,并探讨其在自然语言处理和图像处理等领域中的应用。
Transformer的整体架构
Transformer架构由多层自注意力和前馈神经网络(Feed-Forward Network, FFN)组成,每层都有残差连接和层归一化。典型的Transformer编码器层结构包括:
- 多头自注意力机制(Multi-Head Self-Attention)
- 残差连接和层归一化
- 前馈神经网络(FFN)
- 残差连接和层归一化
接下来我们首先介绍其中的重点部分多头自注意力机制,再详解Transformer的结构。
多头注意力机制(Multi-Head Attention)
在Transformer中,自注意力机制通常采用多头注意力机制,即**将Query、Key和Value分成多个头,每个头分别进行自注意力操作,然后将结果拼接起来。**这种方式可以捕捉不同子空间的特征,提高模型的表示能力。以下是具体步骤。
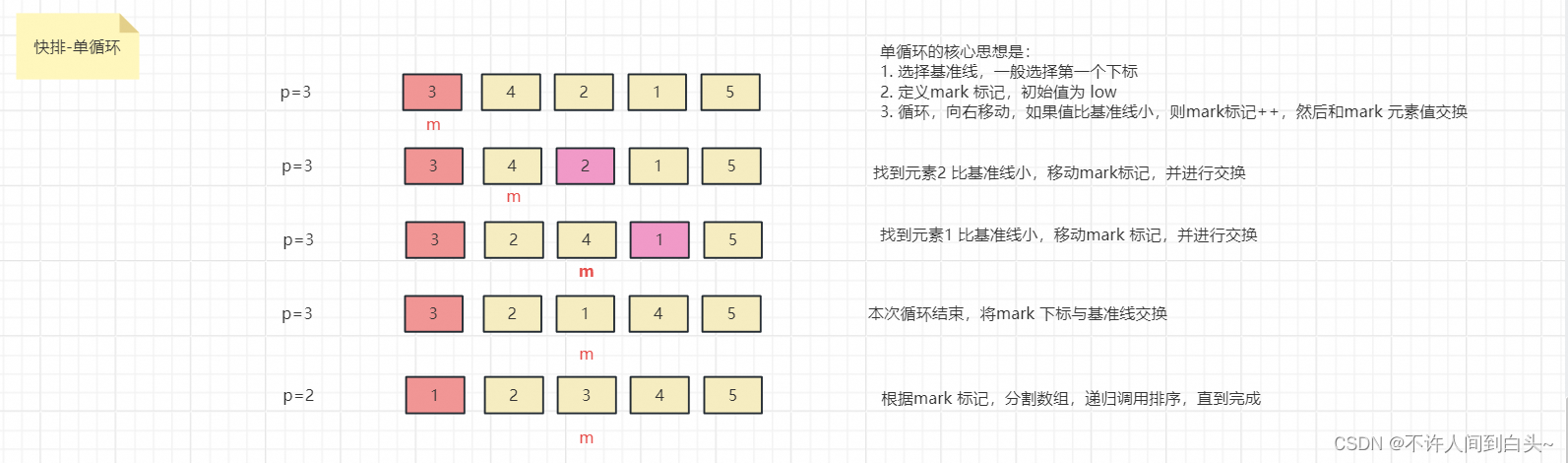
具体步骤
1. 步骤1
针对输入 a i a^i ai分别有对应的 q i , k i , v i q^i, k^i, v^i qi,ki,vi(计算公式位于上一篇文章:self-attention机制介绍和计算步骤),当采用多头注意力机制且设定有两个头时, q i , k i , v i q^i, k^i, v^i qi,ki,vi会被分为 q i , 1 , q i , 2 , k i , 1 , k i , 2 q^{i,1}, q^{i,2}, k^{i,1}, k^{i,2} qi,1,qi,2,ki,1,ki,2和 v i , 1 , v i , 2 v^{i,1}, v^{i,2} vi,1,vi,2。同理,另一个位置的输入 a j a^j aj也分别有对应的 q j , 1 , q j , 2 , k j , 1 , k j , 2 q^{j,1}, q^{j,2}, k^{j,1}, k^{j,2} qj,1,qj,2,kj,1,kj,2和 v j , 1 , v j , 2 v^{j,1}, v^{j,2} vj,1,vj,2。
2. 步骤2
对每个头分别进行自注意力操作。计算输入 a i a^i ai 第一个头的输出值,公式为:
b i , 1 = ( q i , 1 ⋅ k i , 1 ) ⋅ v i , 1 + ( q i , 1 ⋅ k j , 1 ) ⋅ v j , 1 b^{i,1} = (q^{i,1} \cdot k^{i,1}) \cdot v^{i,1} + (q^{i,1} \cdot k^{j,1}) \cdot v^{j,1} bi,1=(qi,1⋅ki,1)⋅vi,1+(qi,1⋅kj,1)⋅vj,1

3. 步骤3
同理,继续计算输入 a i a^{i} ai的第二个头的输出值 b i , 2 b^{i,2} bi,2,公式为:
b i , 2 = ( q i , 2 ⋅ k i , 2 ) ⋅ v i , 2 + ( q i , 2 ⋅ k j , 2 ) ⋅ v j , 2 b^{i,2} = (q^{i,2} \cdot k^{i,2}) \cdot v^{i,2} + (q^{i,2} \cdot k^{j,2}) \cdot v^{j,2} bi,2=(qi,2⋅ki,2)⋅vi,2+(qi,2⋅kj,2)⋅vj,2

4. 步骤4
我们已经计算出了了输入 a i a^i ai两个头的输出值,接下来只需将它们进行拼接即可,拼接方法是将 b i , 1 b^{i,1} bi,1和 b i , 2 b^{i,2} bi,2合并为一个向量,并与一个系数 W o W^o Wo相乘,得到 b i b^{i} bi:
b i = W o ⋅ [ b i , 1 b i , 2 ] T b^{i} = W^o \cdot [ b^{i,1}\ b^{i,2}]^T bi=Wo⋅[bi,1 bi,2]T
此时,完成了输入 a i a^i ai最后的输出值 b i b^{i} bi。同理,我们也可计算输入 a j a^j aj最后的输出值 b j b^{j} bj。具体步骤大家可自行根据上述公式进行推算。
Self-Attention应用与比较
Self-Attention用于图像处理
将图片中的一个像素视为具有三个通道的向量输入,整个图片则可以看作是一个向量组输入到Self-Attention中进行处理。这种方法可以在图像处理中应用Self-Attention机制,以捕捉图片中的重要特征。
Self-Attention vs. CNN
- CNN也可以被看作是一种Self-Attention机制,但它仅考虑感受野区域的内容。这里补充一下感受野的概念和计算公式:深度学习常见概念解释(二)—— 感受野:定义与计算公式。
- Self-Attention可以看作是具有可学习感受野的复杂CNN(因为其感受野是通过self-attention机制学出来的,即找到所有和当前所处理的像素有关的像素)。在数据量较少时,CNN模型比较适合,因为模型简单轻便;在数据量较大时,Self-Attention更合适,效率更高。当输入图片数量大于100M时,Self-Attention的效率明显高于CNN。

Self-Attention vs. RNN
首先我们分别列出两个网络的结构图:

通过上图可知,RNN和Self-Attention在功能上非常类似,输入都是向量序列(vector sequence),且输出都考虑了上下文内容。但它们最大的不同是,RNN难以考虑较久之前的内容,因为其逐层处理数据,信息会逐渐丢失。而Self-Attention没有这个问题,且可以并行处理(每一个输出都是同时产生的)。所以从运行效率的角度看,Self-Attention比RNN更有效率。

Transformer架构详解
Transformer是一个序列到序列(Seq2Seq)的模型(也就是输入是sequence,输出也是由model决定长度的sequence),可以应用于多个方面,如语音识别、机器翻译、语音合成,语言模型创作等。
其架构主要由两个组件构成,它们分别是Encoder和Decoder,如下图所示(左边为示意图,右边为详细结构):

Encoder
首先我们来分析Encoder,Encoder部分接受输入向量 [ x 1 x 2 x 3 x 4 ] [x^1\ x^2\ x^3\ x^4] [x1 x2 x3 x4],并通过多个block进行处理,得到要传递给Decoder的中间值 [ h 1 h 2 h 3 h 4 ] [h^1\ h^2\ h^3\ h^4] [h1 h2 h3 h4],block主要包含Self-Attention和前馈神经网络(FFN)层对输入进行处理。下图仅为简单示意图,具体操作在下下张图中。

这里注意:block中每层都有残差连接和层归一化,以防止信息丢失。
首先是Self-Attention层,输入通过该层得到输出a,同时加上原始输入b得到残差值a+b以免忽略细节特征,再对获取的残差值进行层级归一化(Layer Normalization),该归一化步骤为计算整层的平均值m和方差 σ \sigma σ,再通过图中所示公式计算即可。

同样,在前馈神经网络(即全连接层FC)处也要做同样的事情,获取残差值并进行层归一化。

最后补充一点,输入在进入Encoder之前需要增加Positional Encoding步骤。其定义如下:
位置编码(Positional Encoding)
由于自注意力机制本身不包含位置信息,Transformer通过添加位置编码(Positional Encoding)来引入位置信息,使模型能够利用输入序列中元素的顺序关系。位置编码是一种给每个位置添加独特位置向量 e i e^i ei的方式,并将这个位置向量加到输入 a i a^i ai中。

Decoder
该文件介绍的Decoder部分是为自回归解码器(Autoregressive Decoder,缩写为AT)。还有一种Decoder是Non-autoregressive Decoder,因为篇幅原因暂不介绍。为了能清楚解释Decoder的作用,我们用语音识别的例子来解释。

在语音识别中,Decoder接受一个特殊的输入标志(如BEGIN)让其开始运行,并生成概率分布(对语音识别来说是一个词汇列表的概率分布,所有列都可以用one-hot vector来表示),从中取出概率最大的输出。

然后将Decoder每次生出的输出作为下一次的输入,每次生成输出都同上一步取概率最大的内容。
但同时我们也要考虑何时让Decoder停下来输入。

同样的,我们增加一个END输入,标注结束。

之后让Decoder判断什么时候输出END,代表结束。
Decoder vs Encoder
但当我们回到Transformer架构(见架构详解第一张图)的时候,我们会发现Decoder和Encoder的架构几乎一模一样,只是Decoder比Encoder多了一个最底下的块,和输出端的线性处理及softmax分类。这个多出来的块包括Masked Multi-Head Attention和其归一化处理。其中Masked Multi-Head Attention是一种特殊的Self-Attention,只是它仅仅考虑当前输入及其左边的上下文。这里图解同样以上面四个输入来举例。

当我们考虑 a 1 a^1 a1的输出时,输入仅考虑 a 1 a^1 a1,不考虑其他。当考虑 a 2 a^2 a2的输出的时候,输入仅考虑 a 1 a^1 a1和 a 2 a^2 a2。同理,到a^3的时候考虑 a 1 , a 2 , a 3 a^1,a^2,a^3 a1,a2,a3,到a4的时候考虑 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4。下图为处理到 a 2 a^2 a2的输出 b 2 b^2 b2时,我们仅计算 a 1 a^1 a1和 a 2 a^2 a2的q,k,v组成的 b 2 b^2 b2。

采用该块的理由:贴合Decoder的执行步骤,因为Decoder的输出是一个一个产生的。
Cross Attention
介绍完Encoder和Decoder后之后,我们来介绍这两个模块之间的联系——Cross Attention。

Cross Attention机制其实和Self Attention一样,只不过q来自Decoder中的Self-Attention(Mask)的输出。让q和来自Encoder输出内容的k和v进行计算获得结果v,再将v通过全连接层。这就是整个Cross Attention的运作过程。
下图中的q是来自Decoder中的Self-Attention(Mask)针对BEGIN的输出。

同理,对于其他的输出也会从Encoder得到q,再从Encoder中得到输出后计算出的k和v进行运算。

Train
计算Decoder输出与真实值(Ground Truth)之间的差异,使用交叉熵(cross entropy)作为损失函数,训练网络的目标是最小化交叉熵。

这里需要注意,Decoder中的输入不仅有来自Encoder的输出,还有Ground Truth,这种输入真实值来推测输出的方法叫做Teacher Forcing。
结论
Transformer架构通过引入多头自注意力机制、前馈神经网络和位置编码,实现了高效的序列到序列转换。这种架构摆脱了传统循环神经网络(RNN)对序列处理的限制,可以并行处理序列中的每一个元素,从而大大提高了计算效率。多头自注意力机制使得模型能够捕捉不同子空间的特征,增强了模型的表示能力。位置编码则引入了位置信息,使得模型能够理解输入序列的顺序。前馈神经网络在每个编码器和解码器层中对自注意力机制的输出进行了进一步的非线性变换,增强了模型的复杂特征学习能力。综上所述,Transformer架构凭借其高效的并行处理能力和强大的表示能力,已经在自然语言处理、图像处理等多个领域中取得了显著的成果,展示了其广泛的应用前景和发展潜力。







![[AI Google] 双子座模型家族迎来新突破:更快的模型、更长的上下文、AI代理等更多功能](https://img-blog.csdnimg.cn/img_convert/134d5128225957ed2581bd8bc7556a62.png)