Application portability with HIP — ROCm Blogs (amd.com)
许多科学应用程序在配备AMD的计算平台和超级计算机上运行,包括Frontier,这是世界上第一台Exascale系统。这些来自不同科学领域的应用程序通过使用Heterogeneous-compute Interface for Portability(HIP)抽象层被移植到AMD GPU上运行。HIP使得这些高性能计算(HPC)设施能够将他们的CUDA代码转换为可在最新AMD GPU上运行并充分利用其优势的代码。将这些科学应用程序进行移植的工作量从几个小时到几周不等,这主要取决于原始源代码的复杂性。图1展示了几个已移植的应用示例以及相应的移植工作量。
在本文中,我们将介绍HIP可移植性层、AMD ROCm™堆栈中可用于自动将CUDA代码转换为HIP的工具,并展示如何使用可移植的HIP构建系统在AMD和NVIDIA GPU上运行相同的代码。
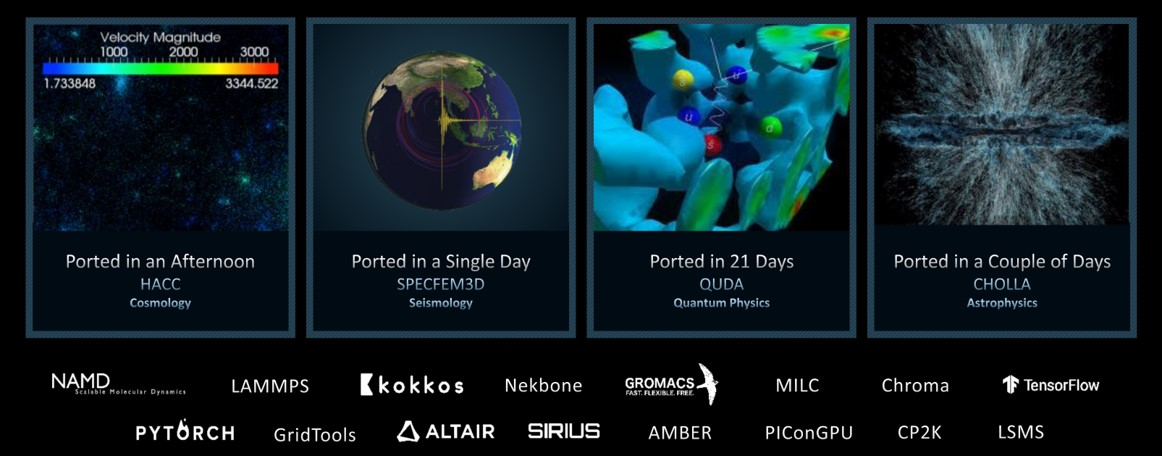
图1:通过HIP将科学应用程序移植到支持AMD Instinct™ GPU的平台上
HIP API
Heterogeneous-compute Interface for Portability(HIP)是一个C++运行时API和内核语言,它使开发人员能够设计可以在AMD和NVIDIA GPU上运行的平台无关GPU程序。HIP的接口和语法与CUDA非常相似,这方便了GPU程序员的使用,并实现了CUDA API调用的快速转换。通过简单地将cuda替换为hip,大部分这样的调用可以在原地进行转换,因为HIP支持CUDA运行时功能的强大子集。此外,如图2所示,HIP代码提供了一种方便性,即维护一个单一的代码库,该代码库可以在AMD和NVIDIA平台上运行。

图2:HIP到设备的流程图,展示了平台无关的抽象层。
图3展示了可用于在GPU上加速代码的各种编程范式和工具,以及系统堆栈中相应的抽象级别。HIP与其他GPU编程抽象层相比更接近硬件,因此它能够以最小的开销加速代码。这一特性使得HIP代码在NVIDIA加速器上的运行性能与原始CUDA代码相似。此外,AMD和NVIDIA都采用主机-设备架构,其中CPU是主机,GPU是设备。主机支持C++、C、Fortran和Python。C++是最常见且支持最好的语言,入口点是main()函数。主机运行HIP API和HIP函数调用,这些调用映射到CUDA或HIP。内核在设备上运行,支持类似C的语法。最后,HIP API提供了许多用于设备和内存管理以及错误处理的有用函数。HIP是开源的,您可以为其做出贡献。
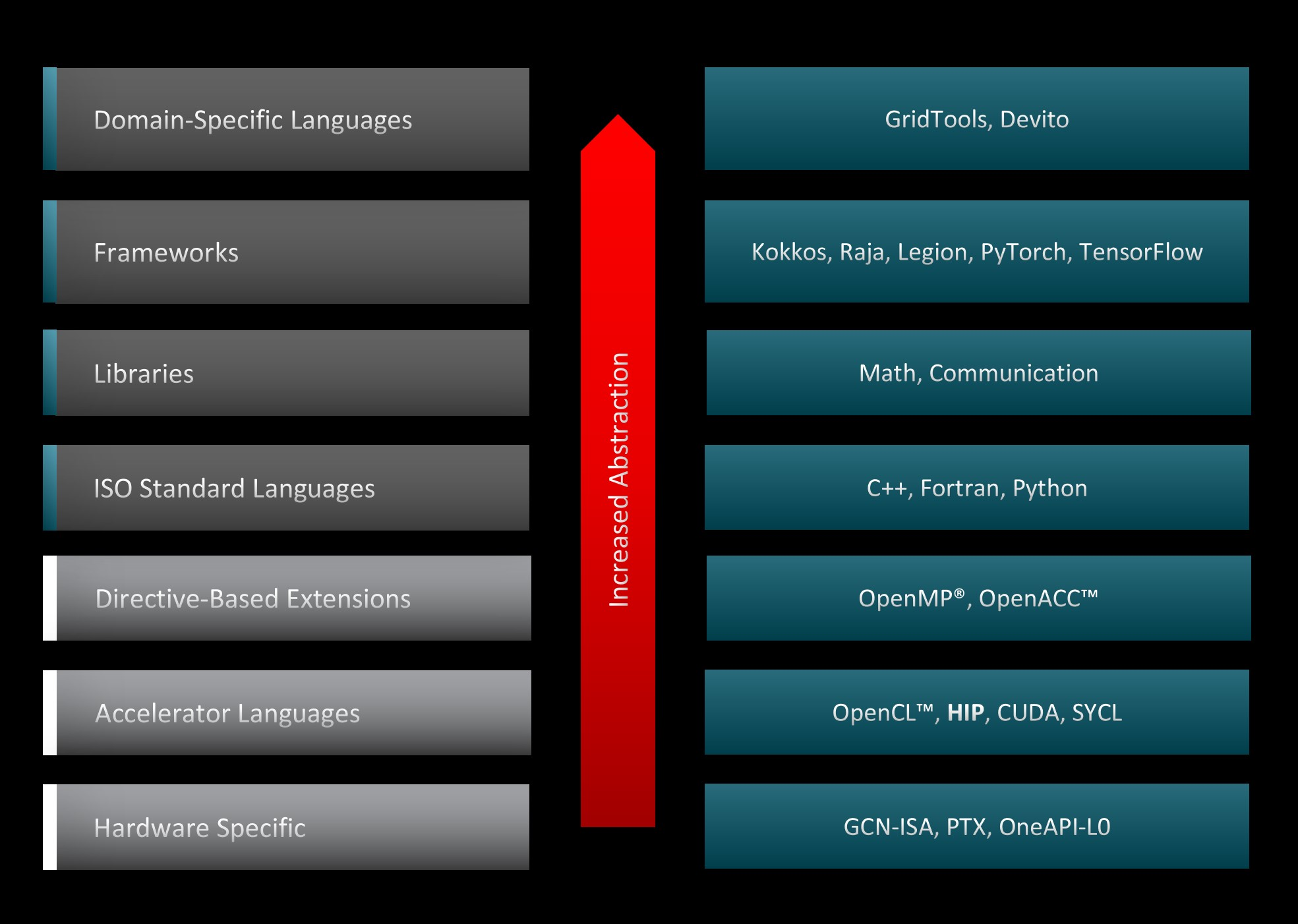
图3: GPU编程抽象层级。
将CUDA应用程序转换为HIP
手动将大型且复杂的现有CUDA代码项目转换为HIP是一个容易出错且耗时的过程。鉴于HIP和CUDA之间的语法相似性,可以构建自动化转换工具来将CUDA代码转换为可移植的HIP C++。AMD ROCm™堆栈提供了转换工具和脚本,这些工具和脚本大大加快了转换过程。这些工具可以单独使用,也可以作为迭代过程的一部分来移植更大、更复杂的CUDA应用程序,从而减少了在基于AMD的系统上部署CUDA应用程序所需的手动工作量和时间。
使用什么工具?
将CUDA转换为HIP的最终工具或策略选择取决于多个因素,包括代码复杂性和开发者的设计选择。为了阐明这一点,我们鼓励开发者使用以下问卷作为模板来收集更多关于他们项目的信息:
代码结构有多复杂?
是否使用了面向对象编程?
是否依赖于模板类?
是否依赖其他库和包?
是否有特定于设备的代码?
设计考虑因素是什么?
我们是否应该为CUDA和HIP维护单独的后端?
代码库是否处于积极开发中?
更新的频率是多少?
开发工作是否专注于某个特定功能?
一旦完成了需求和目标的评估,开发者可以选择以下策略之一来将他们的CUDA代码转换为HIP。
统一的封装器/头文件
在不需要为CUDA和HIP维护单独代码库的场景中,且应用程序没有任何特定于设备的代码时,可以创建一个带有宏定义的头文件,为HIP API调用创建别名并将其链接到现有的CUDA API。以下是一个示例片段:
...
#define cudaFree hipFree
#define cudaFreeArray hipFreeArray
#define cudaFreeHost hipHostFree
#define cudaMalloc hipMalloc
#define cudaMallocArray hipMallocArray
#define cudaMallocHost hipHostMalloc
#define cudaMallocManaged hipMallocManaged
#define cudaMemcpy hipMemcpy
...这个头文件,可以作为您移植项目的起点。
另外,您还可以使用宏定义来构建一个统一的封装,如以下代码片段所示。根据代码编译的架构,封装框架在底层调用相应的CUDA或HIP API。
...
#ifdef _CUDA_ENABLED
using deviceStream_t = cudaStream_t;
#elif _HIP_ENABLED
using deviceStream_t = hipStream_t;
#endif
...
#ifdef _CUDA_ENABLEDusing deviceStream_t = cudaStream_t;
#elif _HIP_ENABLEDusing deviceStream_t = hipStream_t;
#endif
...优点
- 易于维护
- 高度可移植
- 易于添加新功能
缺点
- 链接所有CUDA API可能需要多次迭代
- CUDA中现有的优化可能不适用于HIP
- 在CUDA API没有HIP等效项的情况下需要手动干预
一般性建议:
• 通常,从NVIDIA GPU开始进行代码移植是最简单的方法,因为您可以逐步将代码部分转换为HIP,同时其余部分保留为CUDA代码。请记住,在NVIDIA GPU上,HIP只是CUDA的一个薄层,因此这两种代码类型可以在_nvcc_平台上互操作。此外,HIP移植可以与原始CUDA代码进行功能和性能比较。
• 一旦CUDA代码被移植到HIP并且可以在NVIDIA GPU上运行,就使用AMD GPU上的HIP编译器编译HIP代码。
Hipify 工具
AMD的ROCm™软件堆栈包含了一些实用工具,这些工具可以帮助将CUDA API转换为HIP API。你可以找到以下两个工具:
hipify-clang:一个在HIP/Clang编译器工具链中运行的预处理器,它在编译过程中作为初步步骤转换代码。
hipify-perl:一个基于Perl的脚本,它依赖正则表达式来进行转换。
Hipify工具可以扫描代码来识别任何不支持的CUDA函数。你可以在ROCm的HIPIFY文档网站上找到支持的CUDA API的列表。
hipify-clang
hipify-clang 是一个预处理器,它使用Clang编译器来解析CUDA代码并进行语义转换。它将CUDA源代码转换为抽象语法树,然后由转换匹配器遍历。应用所有匹配器后,产生输出的HIP源码。
优点:
- 基于Clang的转换器,因此即使是复杂的结构也能成功解析
- 支持Clang选项,如 -I、`-D`、`--cuda-path`等。
- 对新版本的CUDA有无缝支持,因为这是Clang的责任。
缺点:
- 输入的CUDA代码需要是正确的,错误的代码不会被转换为HIP。
- 必须安装CUDA,并且在存在多个安装的情况下需要通过`--cuda-path`选项提供。
- 必须提供所有的包含文件和定义才能成功地转换代码。
使用hipify-clang的一般方式是:
hipify-clang [选项] <source0> [... <sourceN>]可以通过使用命令来识别可用的选项:
hipify-clang --help考虑一个简单的
vectorAdd 示例,其中原始的CUDA代码取两个向量A和B,进行逐个元素的加法,并将值存储在一个新的向量C中:
C[i] = A[i] + B[i], 其中 i=0,1,.....,N-1要将CUDA代码转换为HIP,可以按以下方式使用hipify-clang:
hipify-clang --cuda-path=/your-path/to/cuda -I /your-path/to/cuda/include -o /your-path/to/desired-output-dir/vectorAdd_hip.cpp vectorAdd.cu翻译后的HIP代码 vectorAdd_hip.cpp 如下所示:
#include <hip/hip_runtime.h>
#include <stdio.h>// 用于检查CUDA API调用错误的宏
#define cudaErrorCheck(call) \
do{ \hipError_t cuErr = call; \if(hipSuccess != cuErr){ \printf("CUDA Error - %s:%d: '%s'\n", __FILE__, __LINE__, hipGetErrorString(cuErr));\exit(0); \} \
}while(0)// 数组的大小
#define N 1048576// 内核
__global__ void add_vectors_cuda(double *a, double *b, double *c)
{int id = blockDim.x * blockIdx.x + threadIdx.x;if(id < N) c[id] = a[id] + b[id];
}// 主程序
int main()
{// 为N个双精度浮点数分配的字节数size_t bytes = N*sizeof(double);// 在主机上为数组A、B和C分配内存double *A = (double*)malloc(bytes);double *B = (double*)malloc(bytes);double *C = (double*)malloc(bytes);// 在设备上为数组d_A、d_B和d_C分配内存double *d_A, *d_B, *d_C;cudaErrorCheck( hipMalloc(&d_A, bytes) );cudaErrorCheck( hipMalloc(&d_B, bytes) );cudaErrorCheck( hipMalloc(&d_C, bytes) );...对翻译后的代码快速检查显示:
1. HIP运行时头文件已在顶部自动引入。
2. CUDA类型和API,如`cudaError_t`、`cudaMalloc`等,已被替换为HIP对应项。
3. 用户定义、函数名和变量名保持不变。
4. 从ROCm 5.3开始,默认的HIP内核启动语法与CUDA中的相同。以前的`hipLaunchKernelGGL`语法继续得到支持,可以通过指定`--hip-kernel-execution-syntax`选项给hipify-clang来使用。
Hipify-perl
Hipify-perl 脚本通过使用一系列简单的字符串替换直接修改 CUDA 源代码。
优点:
- 易于使用
- 不会检查输入源 CUDA 代码的正确性
- 不依赖第三方工具,包括 CUDA
缺点:
- 当前无法转换以下构造:宏展开、命名空间、一些模板、主机/设备函数调用、复杂参数列表解析
- 可能需要多次迭代和手动干预
- 没有编译器支持检查是否存在包含文件和定义
hipify-perl 的一般用法如下:
hipify-perl [OPTIONS] INPUT_FILE其中,可用选项可以通过以下命令识别:
hipify-perl --help使用相同的 vectorAdd示例,我们可以使用 hipify-perl 将 CUDA 代码转换为 HIP,如下所示:
$ hipify-perl -o=your-path/to/desired-output-dir/vectorAdd_hip.cpp vectorAdd.cu warning: vectorAdd.cu:#4 : #define cudaErrorCheck(call) \warning: vectorAdd.cu:#36 : cudaErrorCheck( hipMalloc(&d_A, bytes) );warning: vectorAdd.cu:#37 : cudaErrorCheck( hipMalloc(&d_B, bytes) );warning: vectorAdd.cu:#38 : cudaErrorCheck( hipMalloc(&d_C, bytes) );warning: vectorAdd.cu:#49 : cudaErrorCheck( hipMemcpy(d_A, A, bytes, hipMemcpyHostToDevice) );warning: vectorAdd.cu:#50 : cudaErrorCheck( hipMemcpy(d_B, B, bytes, hipMemcpyHostToDevice) );warning: vectorAdd.cu:#71 : cudaErrorCheck( hipMemcpy(C, d_C, bytes, hipMemcpyDeviceToHost) );warning: vectorAdd.cu:#90 : cudaErrorCheck( hipFree(d_A) );warning: vectorAdd.cu:#91 : cudaErrorCheck( hipFree(d_B) );warning: vectorAdd.cu:#92 : cudaErrorCheck( hipFree(d_C) );与 hipify-clang 不同,运行 hipify-perl 脚本会生成许多警告。因为 hipify-perl 使用字符串匹配和替换来转换支持的 CUDA API 至对应的 HIP API,它无法找到用户定义的 cudaErrorCheck() 函数的替换项,并因该函数调用中的每一行打印出警告。快速检查指定输出目录中存储的转换后代码表明:
1. 由 hipify-perl 生成的转换代码与 hipify-clang 转换的代码相同。
2. 用户定义的函数、宏和变量没有改变。
3. 从 ROCm v5.3 起,默认的 HIP 核心启动语法与 CUDA 中的相同。以前的 hipLaunchKernelGGL 语法继续得到支持,可以通过指定 --hip-kernel-execution-syntax 选项给 hipify-perl 使用。
Hipify工具的一般使用建议:
• hipify-perl 较为简单易用,不依赖CUDA等第三方库。
• 使用 hipify-perl 翻译代码可能需要多次迭代。首先,使用 hipcc 构建代码。修正任何编译器错误或警告,然后再次编译。持续此循环直到得到可工作的HIP代码。
• 也可以使用其他预打包的实用程序来帮助收集有关CUDA到HIP代码翻译的信息。例如,您可以使用:
◦ hipexamine-perl.sh 工具扫描源目录,确定哪些文件包含CUDA代码,以及有多少代码能够自动转换为HIP。
◦ hipconvertinplace-perl.sh 脚本来执行指定目录中所有代码文件的就地转换。
• “就地”转换并不总是正确的选择,尤其是如果您希望同时保留CUDA和HIP代码。
• 对于这里考虑的简单例子,hipify-perl 和 hipify-clang 翻译出的代码的相似性可能成立。然而,考虑到 hipify-perl 已知的限制,使用时应谨慎。
可移植的HIP构建系统
HIP的最强大特性之一是,如果原始代码使用的是[支持HIP的CUDA API](Supported CUDA APIs — HIPIFY Documentation),那么经过HIP转换的代码能够同时在AMD和NVIDIA的GPU上运行。目前,许多旨在支持这两个平台的应用程序都分别维护着HIP和CUDA的双重代码仓库以及构建系统。使用ROCm™,我们可以拥有一个可移植的HIP构建系统,以避免为同一个项目维护两个独立的代码基础。
在一个可移植的HIP构建系统中,可以选择运行在`amd` 或 nvidia 平台上。通过设置`HIP_PLATFORM`环境变量,我们可以[选择hipcc目标的路径](Frequently asked questions — HIP 6.1.40092 Documentation)。如果`HIP_PLATFORM=amd`,那么`hipcc`将会调用clang编译器和[ROCclr运行时](Frequently asked questions — HIP 6.1.40092 Documentation)来为AMD GPU编译代码。如果`HIP_PLATFORM=nvidia`,则`hipcc`将调用`nvcc`,即[NVIDIA的CUDA编误器驱动](NVIDIA CUDA Compiler Driver),来为NVIDIA GPU编译代码。平台选择也决定了包含哪些头文件以及链接使用哪些库。
本节演示如何使用两种众所周知的构建系统——Make和CMake——实现可移植性。
可移植的Make构建系统
在下面的Makefile示例中,我们可以通过简单地将`HIP_PLATFORM`设置为所需的默认设备`amd`或`nvidia`来选择为AMD或NVIDIA GPU构建代码。设置`-x`标志为`cu`或`hip`将指示构建系统编译到所需的设备,不管文件扩展名是什么。但是,应该注意的是,最终这两种编译器都映射到LLVM。
EXECUTABLE = vectoraddall: $(EXECUTABLE) test
.PHONY: testSOURCE = vectorAdd_hip.cpp
CXXFLAGS = -g -O2 -fPIC
HIPCC_FLAGS = -O2 -g
HIP_PLATFORM ?= amd
HIP_PATH ?= $(shell hipconfig --path)ifeq ($(HIP_PLATFORM), nvidia)HIPCC_FLAGS += -x cu -I${HIP_PATH}/include/LDFLAGS = -lcudadevrt -lcudart_static -lrt
endififeq ($(HIP_PLATFORM), amd)HIPCC_FLAGS += -x hipLDFLAGS = -L${ROCM_PATH}/hip/lib -lamdhip64
endif$(EXECUTABLE):hipcc $(HIPCC_FLAGS) $(LDFLAGS) -o $(EXECUTABLE) $(SOURCE)
test:./$(EXECUTABLE)
clean:rm -f $(EXECUTABLE)对于将在AMD平台上运行的代码,我们需要安装ROCm™,并设置`CXX`变量为推荐的`clang++, 例如 export CXX=${ROCM_PATH}/llvm/bin/clang++,然后使用make`构建,并运行与上一节中相同的vectorAdd应用程序。
make
./vectoradd对于将在NVIDIA平台上运行的代码,我们需要安装CUDA和提供HIP可移植层的ROCm™, 并设置`HIP_PLATFORM=nvidia`来覆盖默认设置,从而为NVIDIA GPU编译代码。
HIP_PLATFORM=nvidia
make
./vectoradd可移植的CMake构建系统
类似于之前的Make示例,目的是有一个构建系统,允许用户在两个GPU运行时HIP和CUDA之间切换。以下代码展示了如何在`CMakeLists.txt`中实现切换:
...
if (NOT CMAKE_GPU_RUNTIME)set(GPU_RUNTIME "HIP" CACHE STRING "Switches between HIP and CUDA")
else (NOT CMAKE_GPU_RUNTIME)set(GPU_RUNTIME "${CMAKE_GPU_RUNTIME}" CACHE STRING "Switches between HIP and CUDA")
endif (NOT CMAKE_GPU_RUNTIME)接下来,要在AMD和NVIDIA系统上构建HIP代码,需要在CMake中启用HIP语言支持,并设置`hipcc`作为编译器,以及相应的编译设备标志:
enable_language(HIP)if (${GPU_RUNTIME} MATCHES "HIP")set (VECTORADD_CXX_FLAGS "-fPIC")
elseif (${GPU_RUNTIME} MATCHES "CUDA")set (VECTORADD_CXX_FLAGS "-I $ENV{ROCM_PATH}/include")
else ()message (FATAL_ERROR "GPU runtime not supported!")
endif ()set(CMAKE_CXX_COMPILER hipcc)set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${VECTORADD_CXX_FLAGS}")
set (CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} ${VECTORADD_CXX_FLAGS}")
set (CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} ${VECTORADD_CXX_FLAGS} -ggdb")最后,创建一个可执行文件,并且必须在AMD和NVIDIA系统上用相应的运行时链接目标:
set (SOURCE vectorAdd_hip.cpp)add_executable(vectoradd ${SOURCE})
if (${GPU_RUNTIME} MATCHES "HIP")target_link_libraries (vectoradd "-L$ENV{ROCM_PATH}/lib" amdhip64)
elseif (${GPU_RUNTIME} MATCHES "CUDA")target_link_libraries (vectoradd cudadevrt cudart_static rt)
endif ()假设已经安装了ROCm™和CMake,可以使用`cmake`配置代码在AMD GPUs上运行,然后通过运行以下命令构建和启动可执行文件:
mkdir build && cd build
cmake ..
make
./vectoradd对于要在NVIDIA GPU上运行的代码,除了CMake之外,还必须安装CUDA和ROCm™堆栈。与Make示例类似,必须设置`HIP_PLATFORM`,并使用`CUDA` GPU运行时配置代码:
mkdir build && cd build
export HIP_PLATFORM=nvidia
cmake -DCMAKE_GPU_RUNTIME=CUDA ..
make
./vectoradd如果在NVIDIA系统上`HIP_PLATFORM`没有正确设置,CMake和Make仍然会配置和构建代码,然而,可能会观察到运行时错误,比如这样的:
./vectoradd
CUDA Error - vectorAdd_hip.cpp:38: 'invalid device ordinal'在AMD和NVIDIA GPU上,CMake将自动检测和构建基础架构的GPU目标,然而,在需要为不同架构构建目标的情况下,用户可以显式指定`CMAKE_HIP_ARCHITECTURES`或`CMAKE_CUDA_ARCHITECTURES`。有关更多详细信息,请参阅CMake documentation。
额外的移植注意事项
在移植过程中,重要的是检查内联PTX汇编代码、CUDA内建函数、硬编码的依赖关系、不受支持的函数、任何限制NVIDIA硬件寄存器文件大小的代码,以及hipify工具无法转换的任何其他构造。由于hipify工具不运行应用程序,因此必须手动更改任何硬编码的构造,例如将warp大小设置为32。因此,建议避免硬编码warp大小,而是依赖WarpSize设备定义、#define WARPSIZE size或props.warpSize从运行时获取正确的值。hipify工具也不转换构建脚本。设置适当的标志和路径以构建新转换的HIP代码必须手动完成。
更多将 CUDA 代码转换为 HIP 和相关便携式构建系统的代码示例可以在 HIP 培训系列仓库 中找到。
结论
我们展示了开发人员可以利用的各种 ROCm™ 工具来将他们的代码从 CUDA 转换为 HIP。这些工具大大加快并简化了转换过程。通过展示用 Make 和 CMake 都可移植的构建系统的示例,我们还展示了 HIP 的一个最强大的特性,即它能够在 AMD 和 NVIDIA GPU 上运行。
与许多其他 GPU 编程范式不同,HIP API 是一个接近硬件的薄层 API,使得 HIP 代码能够以与其 NVIDIA GPU 上的对应代码类似的性能运行。
下一次
请继续关注,因为我们将发布这个系列的后续文章,涵盖更高级的主题。如果您有任何问题或评论,可以通过 GitHub Discussions 与我们联系。