云计算与的定义
长定义是:“云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。”
短定义是:“云计算是通过网络按需提供可动态伸缩的廉价计算服务。
云计算的特点
(1)超大规模。“云”具有相当的规模,谷歌云计算已经拥上百万台服务器,亚马
逊、IBM、微软、Yahoo、阿里、百度和腾讯等公司的“云”均拥有几十万台服务
器。“云”能赋予用户前所未有的计算能力。
(2)虚拟化。云计算支持用户在任意位置、使用各种终端获取服务。所请求的资源
来自“云”,而不是固定的有形的实体。应用在“云”中某处运行,但实际上用户无须了解应
用运行的具体位置,只需要一台计算机、PAD或手机,就可以通过网络服务来获取各种能
力超强的服务。
(3)高可靠性。“云”使用了数据多副本容错、计算节点同构可互换等措施来保障服
务的高可靠性,使用云计算比使用本地计算机更加可靠。
(4)通用性。云计算不针对特定的应用,在“云”的支撑下可以构造出千变万化的应
用,同一片“云”可以同时支撑不同的应用运行。
(5)高可伸缩性。“云”的规模可以动态伸缩,满足应用和用户规模增长的需要。
(6)按需服务。“云”是一个庞大的资源池,用户按需购买,像自来水、电和煤气那
样计费。
(7)极其廉价。“云”的特殊容错措施使得可以采用极其廉价的节点来构成
云;“云”的自动化管理使数据中心管理成本大幅降低;“云”的公用性和通用性使资源的利
用率大幅提升;“云”设施可以建在电力资源丰富的地区,从而大幅降低能源成本。因
此“云”具有前所未有的性能价格比。
大数据的特点
4V+1C。
(1)数据量大(Volume):存储的数据量巨大,PB级别是常态,因而对其分析的计
算量也大。
(2)多样(Variety):数据的来源及格式多样,数据格式除了传统的结构化数据
外,还包括半结构化或非结构化数据,比如用户上传的音频和视频内容。而随着人类活动
的进一步拓宽,数据的来源更加多样。
(3)快速(Velocity):数据增长速度快,而且越新的数据价值越大,这就要求对数
据的处理速度也要快,以便能够从数据中及时地提取知识,发现价值。
(4)价值密度低(Value):需要对大量的数据进行处理,挖掘其潜在的价值,因
而,大数据对我们提出的明确要求是设计一种在成本可接受的条件下,通过快速采集、发
现和分析,从大量、多种类别的数据中提取价值的体系架构。
(5)复杂度(Complexity):对数据的处理和分析的难度大。
Google文件系统GFS
Google文件系统(Google File System,GFS)是一个大型的分布式文件系统。它为
Google云计算提供海量存储,并且与Chubby、MapReduce及Bigtable等技术结合十分紧
密,处于所有核心技术的底层。GFS不是一个开源的系统,我们仅能从Google公布的技术
文档来获得相关知识。
Google GFS的新颖之处在于它采用廉价的商用机器构建分布式文件系统,同时将GFS
的设计与Google应用的特点紧密结合,简化实现,使之可行,最终达到创意新颖、有用、
可行的完美组合。GFS将容错的任务交给文件系统完成,利用软件的方法解决系统可靠性
问题,使存储的成本成倍下降。GFS将服务器故障视为正常现象,并采用多种方法,从多
个角度,使用不同的容错措施,确保数据存储的安全、保证提供不间断的数据存储服务。
GFS的特点:
(1)采用中心服务器模式,简化了设计。
(2)不缓存数据。
(3)在用户态下实现,降低耦合度和编程难度。
(4)只提供专用接口,降低了实现难度和复杂度,提高了通用性和效率。
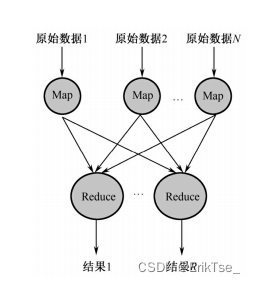
MapReduce模型
MapReduce是Google提出的一个软件架构,是一种处理海量数据的并行编程模式,用
于大规模数据集(通常大于1TB)的并行运算。Map(映射)、Reduce(化简)的概念和
主要思想,都是从函数式编程语言和矢量编程语言借鉴来的。正是由于MapReduce有函
数式和矢量编程语言的共性,使得这种编程模式特别适合于非结构化和结构化的海量数据
的搜索、挖掘、分析与机器智能学习等。
简单地说,一个Map函数就是对一部分原始数据进行指定的操作。每个Map操作都针
对不同的原始数据,因此Map与Map之间是互相独立的,这使得它们可以充分并行化。一
个Reduce操作就是对每个Map所产生的一部分中间结果进行合并操作,每个Reduce所处理
的Map中间结果是互不交叉的,所有Reduce产生的最终结果经过简单连接就形成了完整的
结果集,因此Reduce也可以在并行环境下执行。
分布式锁服务Chubby
Chubby是Google设计的提供粗粒度锁服务的一个文件系统,它基于松耦合分布式系
统,解决了分布的一致性问题。通过使用Chubby的锁服务,用户可以确保数据操作过程
中的一致性。不过值得注意的是,这种锁只是一种建议性的锁(Advisory Lock)而不是
强制性的锁(Mandatory Lock),这种选择使系统具有更大的灵活性。
通常情况下Google的一个数据中心仅运行一个Chubby单元(Chubby cell,下面会
有详细讲解述),这个单元需要支持包括GFS、Bigtable在内的众多Google服务,因此,
在设计Chubby时候,必须充分考虑系统需要实现的目标以及可能出现的各种问题。
Chubby的设计目标主要有以下几点。
(1)高可用性和高可靠性。这是系统设计的首要目标,在保证这一目标的基础上再
考虑系统的吞吐量和存储能力。
(2)高扩展性。将数据存储在价格较为低廉的RAM,支持大规模用户访问文件。
(3)支持粗粒度的建议性锁服务。提供这种服务的根本目的是提高系统的性能。
(4)服务信息的直接存储。可以直接存储包括元数据、系统参数在内的有关服务信
息,而不需要再维护另一个服务。
(5)支持通报机制。客户可以及时地了解到事件的发生。
(6)支持缓存机制。通过一致性缓存将常用信息保存在客户端,避免了频繁地访问
主服务器。
Chubby文件系统
Chubby系统本质上就是一个分布式的、存储大量小文件的文件系统,它所有的操作
都是在文件的基础上完成的。例如在Chubby最常用的锁服务中,每一个文件就代表了一
个锁,用户通过打开、关闭和读取文件,获取共享(Shared)锁或独占(Exclusive)锁。
选举主服务器的过程中,符合条件的服务器都同时申请打开某个文件并请求锁住该文件。
成功获得锁的服务器自动成为主服务器并将其地址写入这个文件夹,以便其他服务器和用
户可以获知主服务器的地址信息。
Chubby 的主要功能
分布式锁: Chubby 提供了一个分布式锁服务,允许多个进程或线程在同一时间对共享资源进行访问控制。它保证了多个进程或线程对共享资源的访问是互斥的,从而避免了冲突和数据不一致的问题。
命名空间管理: Chubby 提供了一个命名空间,用于存储元数据和配置信息。这些信息可以被分布式系统中的各个组件访问和更新。
服务发现: Chubby 可以用来发现分布式系统中的服务。它维护了一个服务注册表,其中包含了系统中所有服务的位置和状态信息。客户端可以通过查询 Chubby 来找到所需的服务。
Chubby 的作用
保证数据一致性: 通过分布式锁机制,Chubby 保证了分布式系统中数据的一致性。
简化分布式系统设计: Chubby 提供了命名空间管理和服务发现等功能,简化了分布式系统的设计。
提高分布式系统可靠性: Chubby 的容错机制提高了分布式系统的可靠性。
Chubby 的应用场景:
分布式数据库: Chubby 可以用来保证分布式数据库中数据的一致性。
分布式缓存: Chubby 可以用来协调分布式缓存中的数据更新。
分布式消息队列: Chubby 可以用来保证分布式消息队列的有序性和一致性。
分布式结构化数据表BigTable
Bigtable是Google开发的基于GFS和Chubby的分布式存储系统。Google的很多数据,包括Web索引、卫星图像数据等在内的海量结构化和半结构化数据,都存储在Bigtable中。从实现上看,Bigtable并没有什么全新的技术,但是如何选择合适的技术并将这些技术高效、巧妙地结合在一起恰恰是最大的难点。Bigtable在很多方面和数据库类似,但它并不是真正意义上的数据库。通过本节的学习,读者将会对Bigtable的数据模型、系统架构、实现以及它使用的一些数据库技术有一个全面的认识。
Bigtable 的主要特点:
(1)分布式存储: Bigtable 将数据分布存储在多个服务器上,能够处理 PB 级的数据规模。
(2)可扩展性: Bigtable 可以根据数据量的增长动态扩展,无需停机维护。
(3)高性能: Bigtable 提供了低延迟的数据访问,能够满足实时数据查询的需求。
(4)多模型支持: Bigtable 支持多种数据模型,包括稀疏数据、半结构化数据等。
(5)强一致性: Bigtable 提供了强一致性保证,确保数据在所有副本之间保持一致。
基础存储架构Dynamo
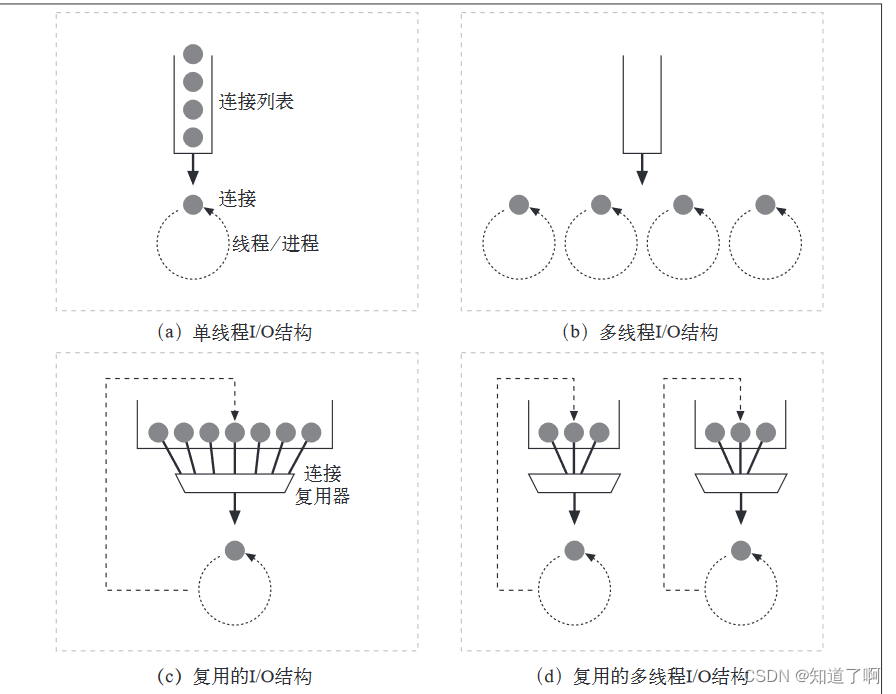
当Web服务刚刚兴起时,各种平台大多采用关系型数据库进行数据存储。但由于Web数据中大部分为半结构化数据且数据量巨大,关系型数据库无法满足其存储要求。为此,很多服务商都设计并开发了自己的存储系统。其中,Amazon的Dynamo是非常具有代表性的一种存储架构,被作为状态管理组件用于AWS的很多系统中。2007年,Amazon将Dynamo以论文形式发表,引起了广泛的关注,并被作为其他云存储架构的基础和参照,例如最初由Facebook开发的开源分布式数据库Cassandra。
EC2
弹性计算云服务(Elastic Compute Cloud,EC2)是AWS的重要组成部分,用于提供大小可调节的计算容量[13]。它为用户提供了许多非常有价值的特性,包括低成本、灵活性、安全性、易用性和容错性等[8]。借助Amazon EC2,用户可以在不需要硬件投入的情况下,快速开发和部署应用程序,并方便地配置和管理。
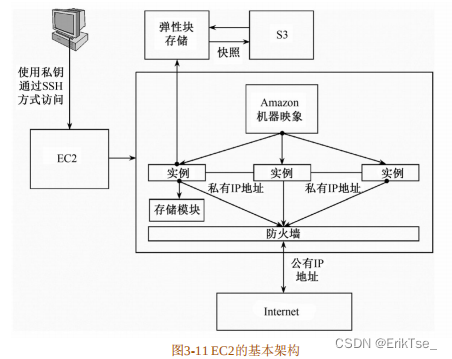
EC2的关键技术有:
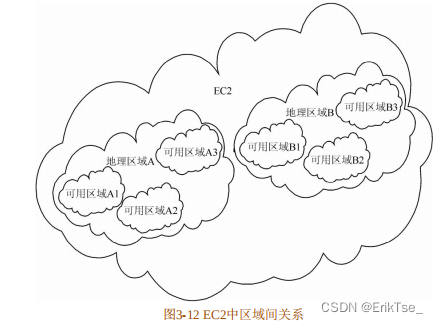
1.地理区域和可用区域
AWS中采用了两种区域[13](Zone):地理区域(Region Zone)和可用区域(Availability Zone)。其中,地理区域是按照实际的地理位置划分的。目前,Amazon在全世界共有10个地理区域,包括:美东(北佛吉尼亚)、美西(俄勒冈)、美西(北加利佛尼亚)、欧洲(爱尔兰)、亚太(新加坡)、亚太(东京)、亚太(悉尼)、南美(圣保罗)、美西服务政府的GovCloud区域和中国(北京)区域。而可用区域的划分则是根据是否有独立的供电系统和冷却系统等,这样某个可用区域的供电或冷却系统错误就不会影响到其他可用区域,通常将每个数据中心看做一个可用区域。图3-12展示了两者之间的关系。EC2系统中包含多个地理区域,而每个地理区域中又包含多个可用区域。为了确保系统的稳定性,用户最好将自己的多个实例分布在不同的可用区域和地理区域中。这样在某个区域出现问题时可以用别的实例代替,最大限度地保证了用户利益。
2.EC2的通信机制
在EC2服务中,系统各模块之间及系统和外界之间的信息交互是通过IP地址进行的。EC2中的IP地址包括三大类:公共IP地址[13](Public IP Address)、私有IP地址[13](Private IP Address)及弹性IP地址[13](Elastic IP Address)。EC2的实例一旦被创建就会动态地分配两个IP地址,即公共IP地址和私有IP地址。公共IP地址和私有IP地址之间通过网络地址转换(Network Address Translation,NAT)技术实现相互之间的转换。公共IP地址和特定的实例相对应,在某个实例终结或被弹性IP地址替代之前,公共IP地址会一直存在,实例通过这个公共IP地址和外界进行通信。私有IP地址也和某个特定的实例相对应,它由动态主机配置协议(DHCP)分配产生。
3.弹性负载平衡(Elastic Load Balancing)
弹性负载平衡功能允许EC2实例自动分发应用流量,从而保证工作负载不会超过现有能力,并且在一定程度上支持容错。弹性载平衡功能可以识别出应用实例的状态,当一个应用运行不佳时,它会自动将流量路由到状态较好的实例资源上,直到前者恢正常才会重新分配流量到其实例上。
4.监控服务(CloudWatch)
Amazon CloudWatch提供了AWS资源的可视化监测功能,包括EC2实例状态、资源利用率、需求状况、CPU利用率、磁盘读取、写入和网络流量等指标。使用CloudWatch时,用户只需要选择EC2实例,设定监视时间,CloudWatch就可以自动收集和存储监测数据。用户可以通过AWS服务管理控制台或命令行工具来维护和处理这些监测数据。
5.自动缩放(AutoScaling)
自动缩放可以按照用户自定义的条件,自动调整EC2的计算能力。在需求高峰期时,该功能可以确保EC2实例的处理能力无缝增大;在需求下降时,自动缩小EC2实例规模以降低成本。自动缩放功能特别适合周期性变化的应用程序,它由CloudWatch自动启动。
6.服务管理控制台(AWS Management Console)
服务管理控制台是一种基于Web的控制环境,可用于启动、管理EC2实例和提供各种管理工具和API接口。图3-13展示了各项技术通过互相配合来实现EC2的可扩展性和可靠性