PG两个函数使用需求和简单介绍
- 需求背景介绍
- 第一个需求背景是这样的
- 需求升级一下
- 接下来讲讲STRING_AGG()
- 基本语法
- 排序
- 然后我们再说说ROW_NUMBER()
- 基本语法
- 使用 row_number() over (partition by) 进行分组统计
- 使用 row_num限定每组数量
需求背景介绍
第一个需求背景是这样的
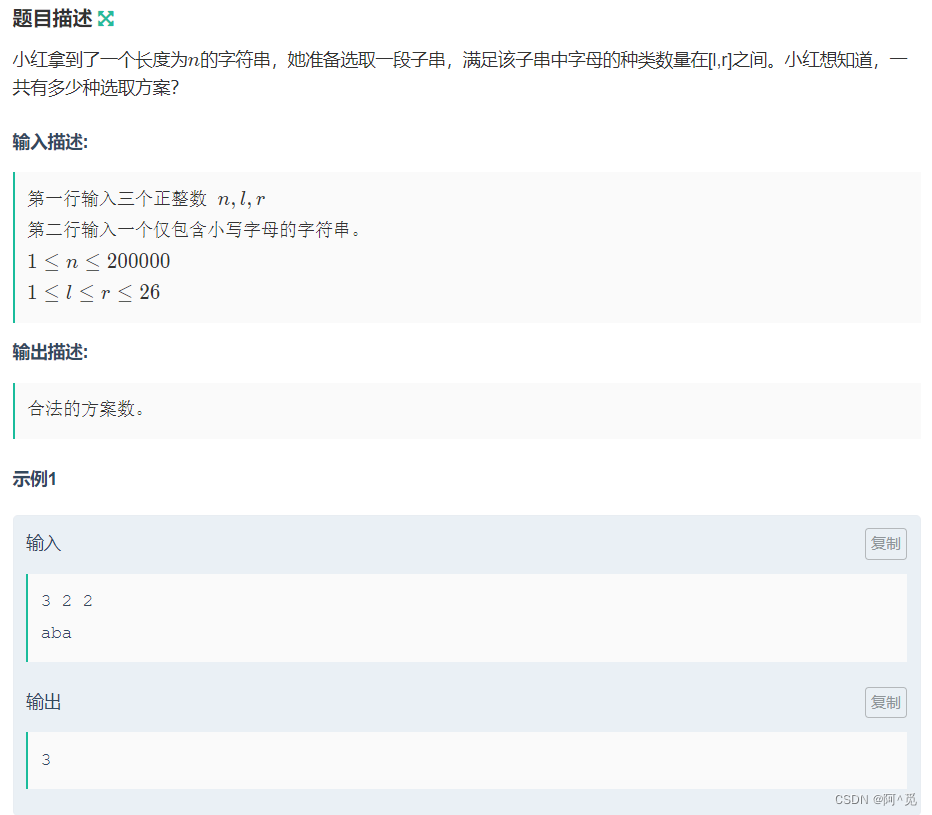
我需要从数据库查询企业的一些信息,其中包括企业曾用名,企业曾用名可能有多个,但是企业主体信息只有一个,且不在同一张表中;我还需要取出另一个表中关联的电话和邮箱,其中电话和邮箱有多个,实际为年份不同可能不一样,也可能为空,我需要取不为空的最新年份的数据。
数据库PG,要求所有曾用名,分隔,企业查询为模糊查询。
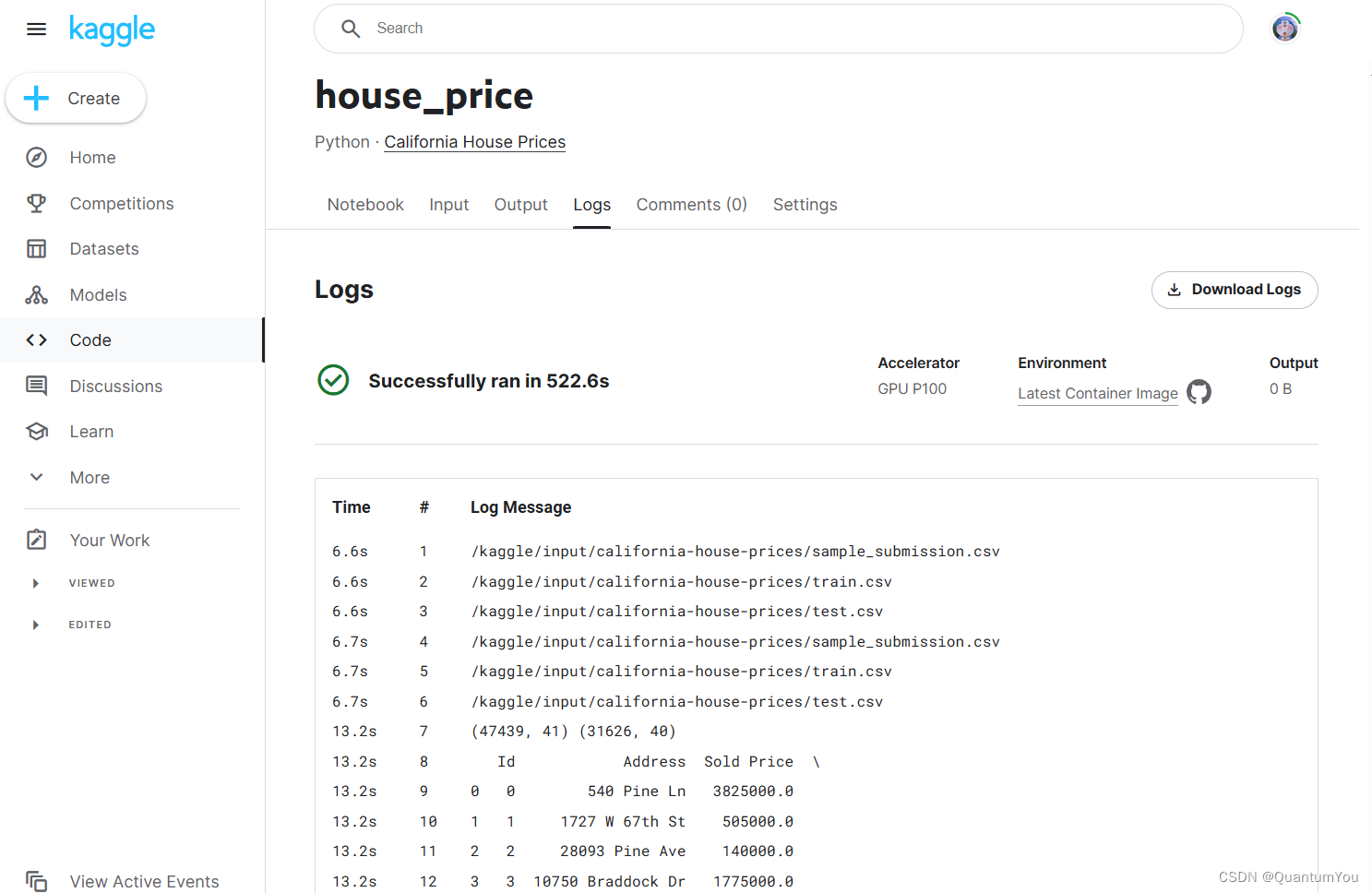
SELECTC.entname as entname,C.uniscid as uniscid,cb.dom as dom,cb.esdate as esdate,cb."name" as frname,cb.regcap as regcap,STRING_AGG ( cm.altbe, ',' ) as nameBefore,A.email as email,A.tel as tel,co.name as entstatusFROMcompanyC LEFT JOIN company_basic cb ON C.entid = cb.entidLEFT JOIN company_modify cm ON C.entid = cm.entidleft join code_ex02 co on cb.entstatus = co.codeLEFT JOIN (SELECTcc.entid AS entid,ca.email AS email,ca.tel AS tel,ROW_NUMBER () OVER ( PARTITION BY cc.ID ORDER BY ca.email DESC ) AS rnFROMcompany ccLEFT JOIN company_ar ca ON cc.entid = ca.entidWHEREcc.entname LIKE concat('%',#{companyName},'%')AND ca.email IS NOT NULLAND ca.tel IS NOT NULLORDER BYca.ancheyear DESC) A ON C.entid = A.entid AND A.rn = 1WHEREC.entname LIKE concat('%',#{companyName},'%')AND cm.altitem = '01'GROUP BYC.entname,C.uniscid,cb.dom,cb.esdate,cb."name",cb.regcap,A.email,A.tel,co.name
可以看到,关联company_ar表,查曾用名,需要使用row_number()函数,取第一行,这就需要先包一层,取rn=1
这里为什么不能使用limit 1,原因是这里是模糊查询,查出来的是多家公司,我需要每个公司取第一行,limit 1不能满足。
需求升级一下
我需要从数据库查询企业的一些信息,其中包括企业曾用名,企业曾用名可能有多个,且是分开的,数据大概像下图
既有可能有多个,每个还都是分开的,需要拼接,每个完整的企业曾用名使用,分隔,但是企业主体信息只有一个,且不在同一张表中;我还需要取出另一个表中关联的电话和邮箱,其中电话和邮箱有多个,实际为年份不通可能不一样,也可能为空,我需要取不为空的最新年份的数据。
数据库PG,要求所有曾用名先按照id排序之后拼接再,分隔,企业查询为模糊查询。
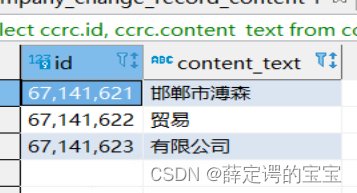
SELECTC.entname as entname,C.uniscid as uniscid,C.dom as dom,C.esdate as esdate,C."name" as frname,C.regcap as regcap,STRING_AGG ( C.content_text, ',' ) as nameBefore,C.email as email,C.tel as tel,c.entstatus as entstatusFROM(SELECTC.entname,C.uniscid,cb.dom,cb.esdate,cb."name",cb.regcap,STRING_AGG ( ccrc.content_text, '' ORDER BY ccrc.ID ) AS content_text,A.email,A.tel,cb.entstatus as entstatusFROMcompanyC LEFT JOIN company_basic cb ON C.ID = cb.entidLEFT JOIN company_change_record ccr ON ccr.entid = C.IDAND ccr.altitem = '名称变更'LEFT JOIN company_change_record_content ccrc ON ccr.ID = ccrc.company_change_record_idAND ccrc.company_chang_type = 0LEFT JOIN (SELECTcc.ID AS ID,ca.email AS email,ca.tel AS tel,ROW_NUMBER () OVER ( PARTITION BY cc.ID ORDER BY ca.email DESC ) AS rnFROMcompany ccLEFT JOIN company_ar ca ON cc.ID = ca.entidWHEREcc.entname LIKE concat('%',#{companyName},'%')AND ca.ancheyear IS NOT NULLAND ca.email IS NOT NULLAND ca.tel IS NOT NULLORDER BYca.ancheyear DESC) A ON A.ID = C.IDAND A.rn = 1WHEREC.entname LIKE concat('%',#{companyName},'%')GROUP BYC.entname,C.uniscid,cb.dom,cb.esdate,cb."name",cb.regcap,A.email,A.tel,cb.entstatus,ccrc.company_change_record_id) CGROUP BYC.entname,C.uniscid,C.dom,C.esdate,C."name",C.regcap,C.email,C.tel,c.entstatus
这个sql写起来就比之前的sql又多一层,曾用名字段需要拼接两次,且企业曾用名拼接是需要按照id排序的。
接下来讲讲STRING_AGG()
基本语法
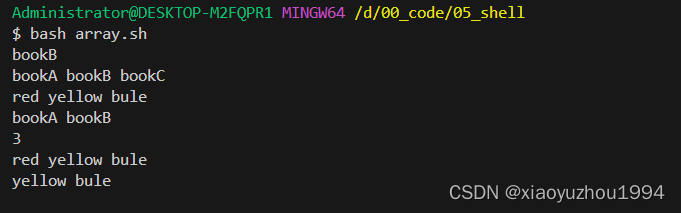
string_agg(column_name, separator)
前边column_name是想要拼接的字段名,后边separator是分隔符。
像上边sql中
STRING_AGG ( C.content_text, ',' )
将content_text 以,分隔
使用像string_agg() 聚合函数,需要使用group by将不需要聚合的字段都写在group by中。
排序
这里升级版需求需要排序然后再聚合拼接,就需要加上order by
这里直接在函数中加上就可以
STRING_AGG ( ccrc.content_text, '' ORDER BY ccrc.ID )
这样就可以实现。
然后我们再说说ROW_NUMBER()
row_number() 函数是 PostgreSQL 中的一个窗口函数,它的作用是为每一行分配一个唯一的序号。当涉及到分组统计时,我们可以使用 row_number() 函数结合 over (partition by) 子句来实现。
基本语法
ROW_NUMBER() OVER ([PARTITION BY partition_expression, ... ]ORDER BY sort_expression [ASC | DESC], ...
)
partition_expression需要是唯一ID,order by 按照自己的实际需求
使用 row_number() over (partition by) 进行分组统计
像上边sql中,
ROW_NUMBER () OVER ( PARTITION BY cc.ID ORDER BY ca.email DESC
我们首先使用 PARTITION BY cc.ID 对数据进行分组,然后使用 ORDER BY email DESC 对每个分组内的数据按照邮箱(其实是随便选的,因为这里需求不做强制要求)降序排序。接着,我们使用 ROW_NUMBER() 函数为每一行分配一个唯一的序号。最后,我们将结果输出到一个新的表中。
使用 row_num限定每组数量
像上边sql中,已经对结果进行了分组统计
ROW_NUMBER () OVER ( PARTITION BY cc.ID ORDER BY ca.email DESC
最终关联的时候取rn = 1,就可以限定数量,这里可以使用<= 等等限定数量。
![Paper速读-[Visual Prompt Multi-Modal Tracking]-Dlut.edu-CVPR2023](https://img-blog.csdnimg.cn/direct/287ae89367ea4728ad458171b35915ee.png)