SAR-to-Optical Image Translation and Cloud Removal Based on Conditional Generative Adversarial Networks: Literature Survey, Taxonomy, Evaluation Indicators, Limits and Future Directions
Abstract
由于光学图像的局限性,其波段无法穿透云层,图像总会受到云层的污染,导致遮挡区域信息缺失,限制后续的应用。合成孔径雷达SAR能够提供全天候、全天时的地面信息。因此,平移SAR或融合SAR与光学图像获取无云的类光学图像是解决云污染问题的理想方法。
在本文中,调查了现有文献,提供了两种分类方法,一种基于输入类型,另一种基于使用方法。同时,分析了使用不同数据作为输入时的优缺点。最后部分讨论了这些现有方法的局限性,提出该领域未来研究的几个可能方向。
1 Introduction
Sentinel-2、GF-1号、Landsat-8和中分辨率成像光谱仪MODIS等免费光学图像在作物分类、农田检测、历史样本分析、耕地利用强度研究等当前农业应用中发挥着重要作用。然而,由于波长的限制,这些光学图像不可避免地会受到云和阴影的污染,从而导致后续研究所需的地表反射率数据效率低下。
为了解决上述问题,研究者们开始从两个不同的角度进行研究。
一种想法是融合多源、多时相或多光谱光学图像。这种思路的基本原理是使用参考相位的无云图像或波段来恢复目标相位的缺失信息。这种方法的优点是我们有许多多源光学图像数据可供选择。同时,这些数据的各波段范围比较相似,所捕获地物的反射率也比较相似,更有利于数据之间的协同融合。然而,缺点是如果连续出现云条件,则不能有效捕获参考数据。因此,这些方法并不能从根本上解决由于云的存在而导致的信息缺失问题。
另一种思路是将合成孔径雷达SAR与目标光学图像融合或仅使用SAR数据。SAR具有足够穿透能力,可以通过云层捕捉地物。因此,从理论上,SAR与光学数据的融合可以解决第一种方法的不足。然而,这种方法有其局限性。SAR与光学遥感在成像原理上有着本质上的不同,导致一些地物(如道路、操场、机场跑道)在光谱反射率和SAR后向散射系数上存在差异。因此,在这些地物上建立两类数据之间的映射关系仍然比较困难。
可将现有文献分为两类:
- 光学遥感数据上的去云
- SAR在光学图像上的解译
第二类目标最初是为了促进模糊SAR图像的解译,但这类目标可以扩展到无云光学遥感数据的生产。第二类虽然不是在原始被云污染数据的基础上进行去云,但其结果与第一类相似,最后得到的是无云光学遥感数据。
在大多数情况下,这两种方法在选择参考数据时都会尽量根据目标数据选择相同的空间和时间。
- 空间上,距离越近,地物之间的相关性越大;距离越大,差异越大。
- 时间上,间隔越近,地物之间的变化越小。
通过Web of Science检索相关文献,对基于SAR数据的光学数据去云的文献进行收集和整理。

在光学遥感数据去云的研究中,第一种整合光学遥感数据的方法比第二种方法起步早,并且第一种方法的论文较多。基于SAR的光学数据去云方法的发展起步于近年。生成式对抗网络GAN一经建立,许多学者尝试使用这种神经网络来研究SAR-to-Optical解译。
3 Taxonomy
3.1 方法的类别
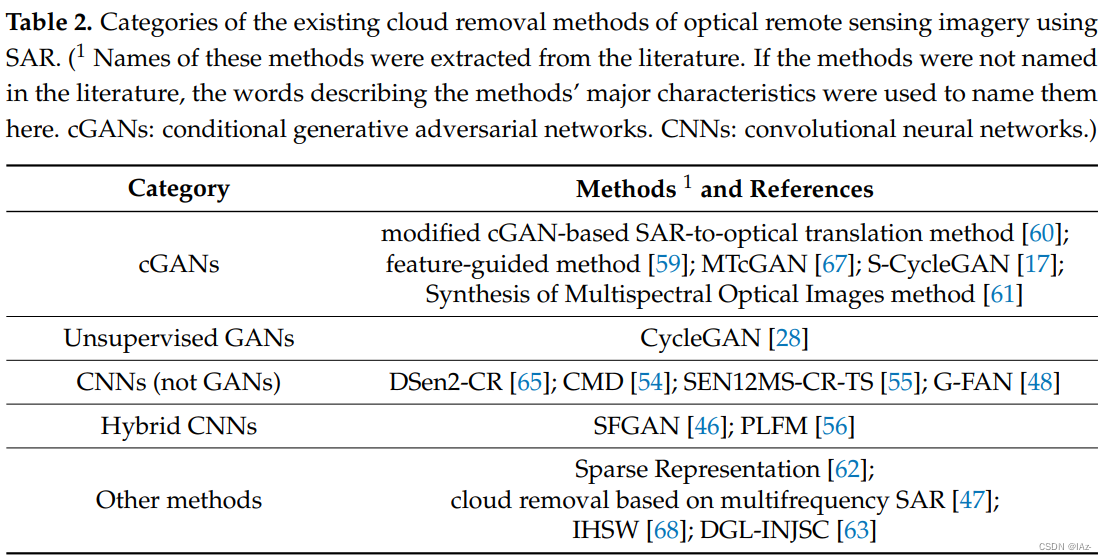
本文根据基于SAR数据的光学遥感数据云研究中GAN的广泛应用,将去云方法分类:
- 条件生成对抗网络(cGANs)
- 无监督生成对抗网络(Unsupervised GAN)
- 卷积神经网络(CNNs)
- 混合卷积神经网络(Hybrid CNNs)
- 其他方法
3.1.1 条件生成对抗网络cGANs
条件生成对抗网络cGAN是对原始对抗网络GAN的扩展,由两个对抗神经网络模块Generator(G)和Discriminator(D)组成。G试图从X域的真实图像中生成Y域的模拟图像来欺骗D。D将从域X和Y的真实图像中进行训练,以区分合成和真实的输入数据。在训练cGAN模型时,输入必须是成对的SAR/光学数据。
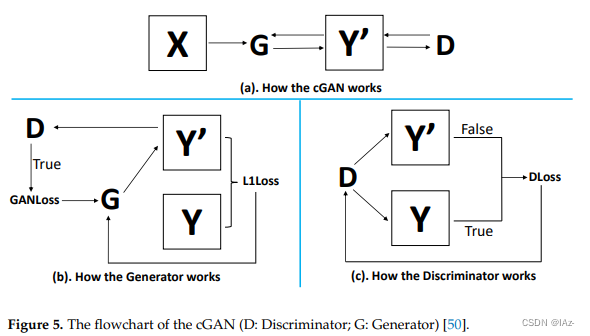
G的损失来自两个部分,GANLoss和L1Loss。
- GANLoss表示模拟图像
是否能够欺骗D(使D判断模拟图像为真实图像)。
- L1Loss表示真实图像
与模拟图像
D负责判别真实图像为真,模拟图像
为假,即DLoss。与G类似,D也试图使DLoss函数的值接近于零,来提高自身的区分能力。
GANLoss是一个将生成器和鉴别器的过程数字化的损失函数。cGAN的目标函数LcGAN(G,D)可表示为式(1):
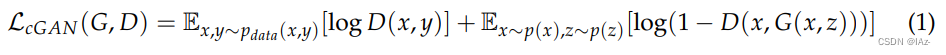
- E和log分别是期望算子和对数算子
- p为图像分布
- z是一个随机噪声向量,遵循一个已知的先验分布p(z),通常为均匀分布或高斯分布
通常,在cGAN的目标函数中加入L1范数距离损失,使模拟图像更接近真实图像,如式(2)所示:
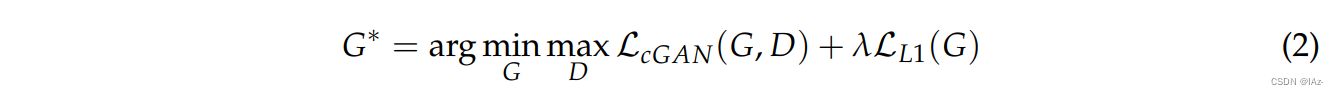
其中为正则化权值,
定义为式(3):

3.1.2 无监督生成对抗网络Unsupervised GANs
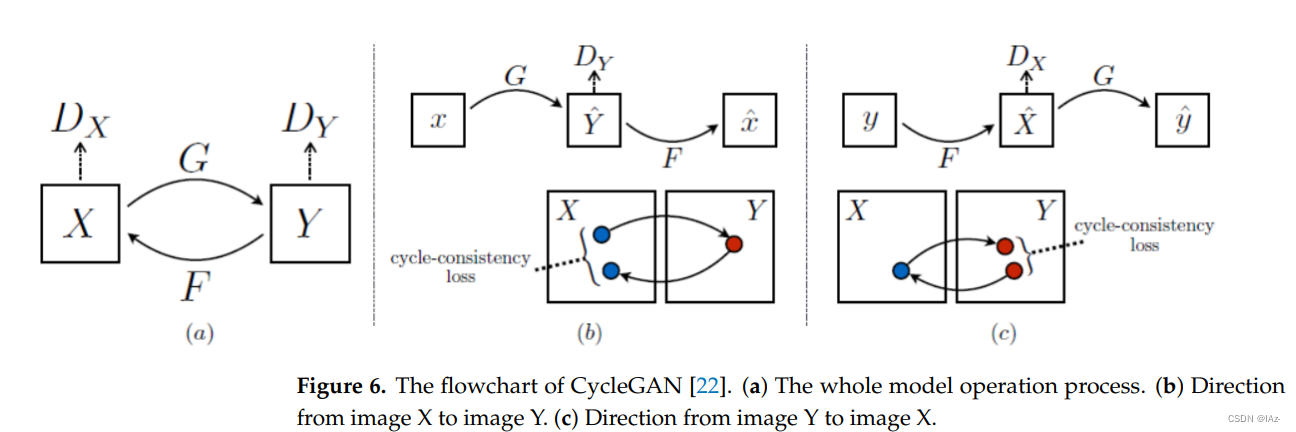
CycleGAN是一种典型的无监督GAN,流程图如图六所示。在没有生成图像对应的真值数据的情况下,不可能使用这两个数据来获得L1损失和测量模型效果。作者认为,当存在两个Generator G和F时,对抗性训练可以学习映射G和F,它们产生的输出分别与目标域Y和目标域X分布相同。但是前提必须限制映射的方向。
CycleGAN主要包括两个Generator (G和F)和两个Discriminator (和
)。Generator G主要负责将图像X转换为图像Y, Generator F主要负责将图像Y转换为图像X,两个Discriminator分别负责判断生成的图像是真还是假。整个模型运行过程可分为两个方向:
- 从图像X到图像Y,如图b所示。Generator G将根据图像X生成图像
,Discriminator
将判断生成的图像
,最后使用图像X和生成的图像
- 从图像Y到图像X,如图c所示。这个过程与第一个方向类似。
在周期一致性损失函数的计算只需要图像X、生成的图像、图像Y、生成的图像
,不需要图像X和图像Y的配对,因此整个网络是一个无监督模型。周期一致性损失公式如式(4)所示,完整目标损失如式(5)所示:

其中和
是两个对立的Discriminator,
旨在区分图像X和生成的图像
,
旨在区分图像Y和生成的图像
,
控制两个目标的相对重要性。最终目标如式(6)所示:
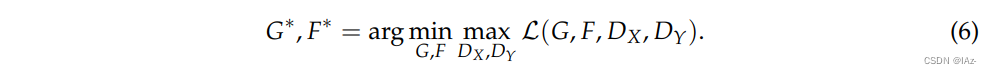
3.1.3 卷积神经网络CNNs
在某种程度上,对抗网络实际上是一种提取高纬度特征的方式,最终通过损失函数作用于网络模型训练。普通的损失函数是一个固定的公式,而对抗网络可以通过不断学习不断改变模型公式。也就是说,只要主网络的结构设计合理,并且损失函数的设计可以衡量模型的训练效果,就不需要使用对抗网络。
有研究采用残差神经网络作为主要网络结构,通过融合Sentinel-1图像和被云污染的Sentinel-2图像的所有波段,恢复Sentinel-2图像的缺失信息。同时,作者提出了一种新的损失函数云自适应正则化损失(cloud- adaptive regularization loss, LCARL),用于估计生成图像中原始云区和原始无云区恢复精度。公式如式(7)所示:
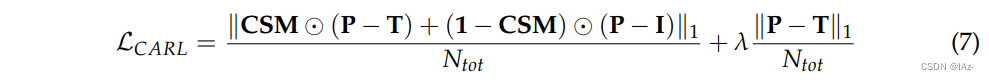
- 其中P、T、I 分别为预测、目标、输入光学图像。
- CSM(云阴影掩膜)具有与光学图像相同的空间特性。
 是一个值为1的矩阵,与光学图像具有相同的空间维度。像素值1表示云或者云阴影,像素值0表示无云区域。
是一个值为1的矩阵,与光学图像具有相同的空间维度。像素值1表示云或者云阴影,像素值0表示无云区域。是光学图像所有波段的像素总数。
与常用的计算去云效果的损失函数相比,该损失函数考虑了图像的有云和无云两种不同的区域属性。
3.1.4 混合卷积神经网络Hybrid CNNs

混合卷积神经网络主要分为两个阶段:
- 无云图像模拟阶段
- 将第一阶段的输出与被云污染的数据融合,得到最终的无云光学遥感图像
在这个过程中,对抗神经网络可以在其中一个阶段使用,也可在两个阶段都使用,也可以根本不使用。混合网络的优点是既可以尽可能地保存原始云污染数据的无云区域信息,又可以利用多源数据恢复云区域信息。
为了更有针对性地训练网络模型,有研究使用了两个新的损失函数。首先是感知损失函数,用于从高维特征层面判断模型输出的准确性。二是局部损失函数,用于动态判断云污染区域的数据恢复精度。对于感知损失函数,研究者尝试从VGG-16的第8层提取融合结果和地面真值的特征图。公式如(8)所示:
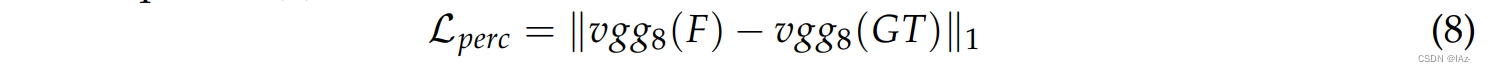
F为融合结果,GT为地面真值数据。局部损失函数的表达式如式(9)所示:

其中M为云掩膜,研究者采用基于深度学习的MSCFF(Multiscale convolutional feature fusion),动态获取每批训练图像的云掩膜。
3.1.5 其他方法
除了以上四种方法外,还有SAR-to-Optical或光学图像去云的研究,属于其他方法。例如,稀疏字典学习(Sparse Dictionary Learning)利用SAR数据去除光学数据中的云污染;将最接近光谱拟合Closest Spectral Fit(CSF)算法与多光谱图像和多频SAR数据相结合,去除光学图像的厚云;构建基于图像理解、目标变换和表示的遥感图像翻译新概念;将强度-色调-饱和度和小波变换集成融合用于SAR-Optical图像平移。
3.2 输入的类别
除了使用的方法和损失函数除外,输入数据在建模中也十分重要。根据不同输入数据组合的类型对文献进行分类。
3.2.1 单时相SAR
在测试阶段的输入数据有单时相SAR数据,是传统SAR到光学图像转换领域常用的输入数据。 在训练阶段,通常需要在单个时相成对地提供SAR数据和光学遥感数据。SAR数据主要用于提供特征信息,光学遥感数据主要用于计算损失函数并结合模型输出。此外,虽然CycleGAN也需要输入SAR和光学遥感数据,但是不需要具有相同的时空特性。使用单时相SAR数据生成无云光学遥感图像的优点是输入数据的获取限制较少,训练数据集的生成相对简单。同时该方法还可以在时间维度上增加SAR数据量。然而,由于雷达数据与光学数据在成像上的本质差异,某些地物在这两类数据上的反射信息是不同的,因此仅使用SAR数据获取某些地物的光学图像的精度无法保证。同时,该方法需要大量的样本供模型充分学习SAR与光学遥感数据的转换关系。
3.2.2 单时相SAR和云污染光学图像
输入单时相SAR与云污染光学遥感数据的组合,增加了缺损的光学数据信息,有助于模型根据云区相邻区域的特征辅助目标区域的恢复;同时,输出结果可以更符合实际情况。但由于目标区域的恢复(特别是在厚云情况下)主要依赖于SAR数据,因此SAR到光学数据的平移过程的精度对结果的影像仍然很大。
3.2.3 多时相SAR和光学图像
多时相SAR和光学影像数据对。通过这种方式,模型学习参考时序SAR与光学遥感数据的转换关系,然后根据目标时刻SAR的特征生成目标光学遥感图像。该方法的优点是可以从光学图像参考时间数据中大致得到目标图像的主要目标分布,然后利用SAR数据的目标时间和参考时间的变化来推断目标图像的反射率。但是要求地物在参考时间和目标时间之间的特征变化不大,否则无法保证准确性。
4 Evaluation Indicators
如何评估生成的无云图像的精度也是相关研究的一个重要问题。统计了学者们常用的几个评价指标,如表4所示:
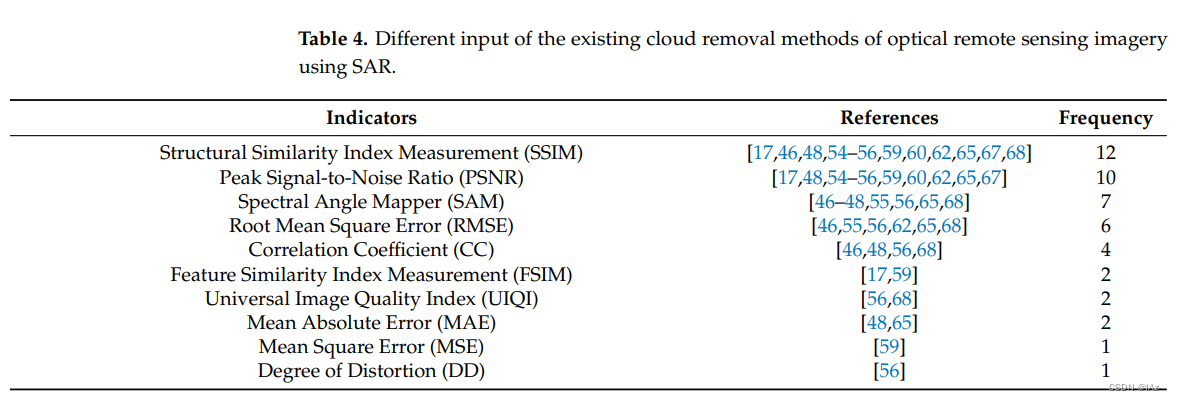
最常用的指标是结构相似指数测量(Structural Similarity Index Measurement,SSIM)。在图像构成方面,SSIM将结构信息定义为独立于亮度和对比度,反映场景中物体的结构属性,将建模失真定义为亮度、对比度和结构的结合。使用平均值、标准差和协方差来估计亮度、对比度和结构相似性。公式如(10)表示:

- 其中
为实际值与模拟值之间的协方差,
和
为增强SSIM稳定性的常数。SSIM取值范围为[-1,1],SSIM越接近1,模拟图像越准确。
第二个常用指标是峰值信噪比(Peak Signal-to-Noise Ratio,PSNR),这是一种传统的图像质量评估(Image Quality Assessment,IQA)指标。一般来说,PSNR越高,图像质量越好。如公式(11-12)所示:

- 其中
和
分别为第i个像素的真实值和模拟值,N为像素数量,MSE为均方误差。
第三个指标是光谱角映射器(Spectral Angle Mapper,SAM),将图像中每个像素的光谱视为一个高维矢量,通过计算两个矢量之间的包含角度来衡量光谱之间的相似性。夹角越小,两种光谱越相似。
第四个指标是均方根误差(Root Mean Square Error,RMSE),用来衡量实际值与模拟值之间的差异。公式定义为:

- 其中
除了上述四个评价指标外,还使用以下指标来评价准确性:
- 相关系数(Correlation Coefficient,CC)
- 特征相似指数测量(Feature Similarity Index Measurement,FSIM)
- 通用图像质量指数(Universal Image Quality Index,UIQI)
- 平均绝对误差(Mean Absolute Error,MAE)
- 均方误差(Mean Square Error,MSE)
- 失真程度(Degree of Distortion,DD)
5 Limits and Future Directions
5.1 图像像素深度
遥感数据是地表物体的反射率信息,从0到1连续记录。考虑到浮点数据的存储将消耗大量的存储资源, 通常将反射率乘以10,000,并保留1到10,000之间的整数。遥感数据的存储格式通常是GeoTIFF,而用于深度学习的图像输入格式通常是PNG格式,一个8位无符号整数,像素深度为[0,255]。因此,为了将遥感数据顺利地提取到深度学习模型中,大多数研究使用将遥感图像保存为PNG格式的方法。
然而,这种方法类似于有损压缩,光谱信息的损失率达到97.44%,大部分光谱信息丢失,这将导致两个问题:
- 模型获取到的信息量远远低于数据本身所能提供的信息量,不利于模型对光谱信息的特征提取,而且大量信息容易被误分类,不利于发现后向散射系数与光谱反射率之间的关系。这可能导致去云效果不佳。
- 模型的最终输出结果只能是像素值为[0,255]的图像。这些结果对于简单的目视检查是可以接受的,但因信息损失太大,不能用于模型的后续定量计算。
事实上,这个问题并不局限于本文研究的去云领域,在其他利用深度学习研究遥感数据的领域也存在。不建议为了盲目地将遥感数据放入深度学习模型而选择失去遥感数据本身的准确性,这可能会对研究造成实质性的干扰。建议使用GDAL库修改深度学习模型的数据加载模块和数据输出模块,而不是深度学习通常的图像格式,这样可以使深度学习模型直接读取和生成像素深度更高的数据。
5.2 图像波段数
由于遥感数据的专业存储格式与深度学习常用的数据读写格式不一致导致。光学遥感数据捕获不同电磁波段的反射率信息:
- 全色图像--单通道
- 多光谱图像--多通道
- 高光谱图像--数十或数百通道
- SAR图像--多极化模式
通常用于深度学习的PNG数据格式只能容纳三个通道,因此有时光学图像数据和SAR数据被强制删除剩余的通道或重复一个额外的通道,从而使图像数据的通道数达到PNG数据格式要求的三通道。当删除剩余通道时,会丢失一些光谱信息,导致从一开始的数据处理过程中,就人为地删除了可以通过深度学习学习到的特征,不利于去云模型的训练。特别是,云对不同波段的影响是不同的。利用不同波段的融合是去除图像中薄云的有效方法。但是,为了满足PNG格式的要求,只能删除剩余的波段。建议使用GDAL库修改深度学习模型的数据加载模块和数据输出模块,而不是通常深度学习的三通道图像格式,这样可以使深度学习模型直接读取和生成适当通道量的数据。
5.3 全局训练数据集
目前,大多数研究都是利用局部区域的少量数据进行模型训练。然而,对于生成式对抗网络等深度学习模型,需要大量的训练样本来学习知识,也需要足够的验证样本来评估模型效果。然而,由于数据集制作的重复性工作量大,创新程度低,目前可供公开和下载的SAR与光学遥感图像融合数据集仍然很少。因此,基于SAR数据的光学图像去云的全球区域数据集将是该领域研究的重要内容。该数据集需要具备以下特征:
- 涉及世界范围多个地区的感兴趣区--学习到不同地形和地区特征,训练的模型具有泛化性;
- 有配对的SAR和光学数据--SAR和光学图像数据融合;
- 是一个多时间序列--有机会学习到时间维度特征,进一步提高精度;
- 是GeoTIFF格式--保证数据集具有相对完整的信息特征;
- 云污染的目标图像及其无云图像--有可用的验证数据,以供模型训练和优化。
5.4 云区域精度验证
目前绝大多数的研究都是对整个场景数据进行去云效果的评估,评估结果是对整个场景图像的平均结果。然而,对于去云应用来说,关键是恢复被云或云阴影污染的区域,待去云图像中的原始像素信息可以用于其他未被污染的区域。因此,对于去云研究,从整个场景图像范围来判断模型精度存在一定的局限性,有必要尝试在被云或云阴影污染的区域进行有针对性的精度评估。

表中记录了两种基于SAR的去云方法的全场景结果精度对比。从表中看出方法A具有明显的优势,但是从图中局部的去云效果来看,显然方法B的去云效果更好,因此仅从整个场景结果的评价指标很难评价去云质量。因此,需要单独提取待去云区域的面积,并且需要计算指标来评估去云效果的准确性,这样更加客观。
5.5 辅助数据
大多数研究的输入数据是SAR和光学图像数据,但很少有研究关注云掩膜数据在该领域的价值。目前很多光学数据在下载时都提供了相应的云掩膜数据,同时也有很多开源的云检测模型算法,使得云掩膜数据更容易获取。将云掩膜数据输入到模型中可以让模型提前获取云的分布,从而更有针对性的去云操作。
此外,可以丰富云掩膜数据的类型。除了云和无云之外,可以进一步区分薄云、厚云、云影等区域,并配合损失函数,使模型的结果更令人满意。与式(7)损失函数相比,新的损失函数能够测量和反馈更多的信息,从而提高了精度。方程可以定义为:

- P、T、I分别为预测、目标和输入光学图像。
- 厚云掩膜TCM1(Thick cloud mask)具有与光学图像相同的空间特性。像素值1表示厚云,像素值0表示其他区域。
- 薄云掩膜TCM2(Thin cloud mask)具有与光学图像相同的空间特性。像素值1表示薄云,像素值0表示其他区域。
- 阴影掩膜SM(Shadow mask)具有与光学图像相同的空间特性。像素值1表示阴影,像素值0表示其他区域。
- 云阴影掩膜CSM(Cloud-shadow mask)具有与光学图像相同的空间特性。像素值1表示云或云阴影,像素值0表示无云区域。
- 是一个值为1的矩阵,与光学图像具有相同的空间维度。
5.6 损失函数
目前的研究使用多种精度指标从多个维度验证结果。然而,这只能用于对结果的最终定量评价,并不能对模型的优化有很大帮助。 同时,大多数研究对整个空间采用相对简单的L1损失或L2损失来计算损失函数。可以尝试将SAM等这些多维指标放入模型优化阶段(即损失函数计算),看看它们是否可以帮助模型从不同维度进行优化训练。
由于损失函数计算中使用的是矩阵计算,我们需要对这些常用的精度指标计算公式进行修改,使其符合矩阵计算方法,这将涉及到一些数学知识和编程知识。当然,理论上我们也可以直接将精度指标计算公式不加修改地放入损失函数中进行计算,但这样会大大增加训练时间,而且初始估计耗时可能会高出1000倍,所以不建议这样做。
![[Cloud Networking] Layer 2](https://img-blog.csdnimg.cn/img_convert/ae778f4d1be9c7891bdf05ac5f63e640.webp?x-oss-process=image/format,png)