1、pytyon爬虫
1.1、爬虫简介
Python爬虫是使用Python编写的程序,可以自动访问网页并提取其中的信息。爬虫可以模拟浏览器的行为,自动点击链接、填写表单、进行登录等操作,从而获取网页中的数据。
使用Python编写爬虫的好处是,Python具有简单易学的语法和丰富的库资源,使得编写爬虫程序变得相对容易。Python中有一些常用的爬虫库,如Requests、BeautifulSoup、Selenium等,可以帮助我们更加方便地进行网页访问、数据提取和处理。
爬虫的应用非常广泛,可以用于网页数据的抓取、信息的分析、自动化测试等等。但是需要注意的是,在使用爬虫时,应遵守网站的相关规定,不进行恶意攻击和滥用。
1.2、python基本知识点与困难点
使用爬虫最基本知识点:
- request:使用reqeust发起http请求
- json:解析http请求的返回数据
- Regular expressions:利用正则表达式深度挖掘提取字符串的匹配数据
爬虫工具最难的地方在于登录验证,只要登录通过,拿到token,其他的工作只不过是一些体力活。
2、爬虫简单请求
爬虫最简单的案例,无非是手动登录之后,通过chrome开发者工具,拿到http请求地址,再模拟数据请求。以下是一个简单的案例——获取csdn专栏文章数据
2.1、手动登录并获取目标http地址
1.人工登录csdn网站。
2.点击专栏管理,选择其中一个专栏
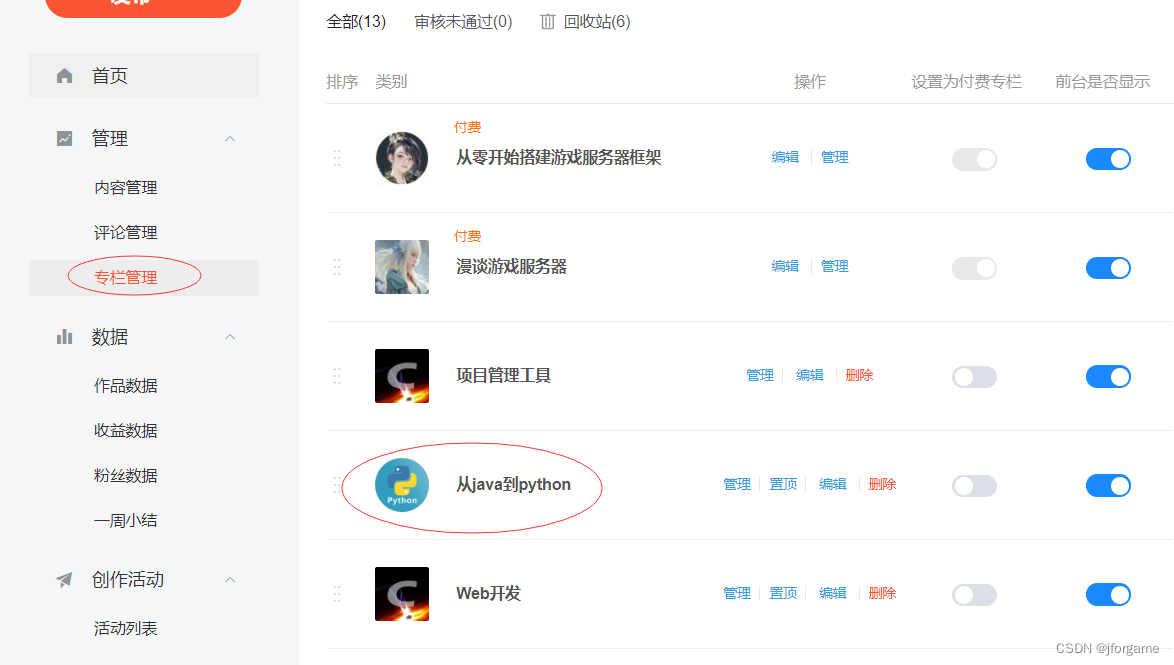
3.点击开发者工具,chrome浏览器使用F12快捷键 ,可以拿到具体的http地址

4.使用python进行http访问
import requests# 目标URL
url = '这里填写目标http地址'
response = requests.get(url)
print(response.text)执行之后,发现有报错。
{"message":"X-Ca-Key is not exist"
}2.2、网站反爬基本原理
网站服务器对于一个http请求,会先检测是否已经登录授权过,若没有,则跳转到登录页面。
服务器在验证登录之后,会生成一个token(token里带有用户个人信息,例如JWT算法)。
客户端登录之后,会在发送的每一个请求都带上token信息(附加到http header)。
2.3、带上header重新进行访问
在开发者工具,查看header信息

由于不知道服务器具体验证哪些参数,最保险的是,把所有header参数到带上。具体参数自行填写。
import jsonimport requests# 目标URL
url = 'http------'# # 定义你的header信息
headers = {'authority': 'bizapi.csdn.net','method': 'GET','path': 'path--------','scheme': 'https','Accept': 'application/json, text/plain, */*','Accept-Encoding': 'gzip, deflate, br, zstd','Accept-Language': 'zh-CN,zh;q=0.9','Cookie': 'token--------','Origin': 'https://mp.csdn.net','Priority':'u=1, i','Referer': 'Referer------','Sec-Ch-Ua': '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"','Sec-Ch-Ua-Mobile': '?0','Sec-Ch-Ua-Platform': '"Windows"','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-site','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36','X-Ca-Key':'------','X-Ca-Nonce':'------','X-Ca-Signature':'------','X-Ca-Signature-Headers':'x-ca-key,x-ca-nonce'
}response = requests.get(url, headers=headers)
print(response.text)
data=json.loads(response.text)['data']
print("专栏名称:",data["category_info"]["title"])
print("专栏介绍:",data["category_info"]["desc"])
articles=data["category_article_list_unTop"]
for article in articles:print("文章id",article["id"],"文章标题", article["title"])
再结合json工具,即可看到请求数据了
专栏名称: 从java到python
专栏介绍: 从Java到Python专栏,旨在帮助那些已经掌握Java编程语言的开发者快速了解并过渡到Python编程语言。对于一个开发者,一定要有一门主攻并且精通的编程语言,这里,在学习新语言的时候,可以横向对比,加深加快对编程的认知。
文章id 44793029 文章标题 Python多线程编程
文章id 44792996 文章标题 Python包管理工具
文章id 44743210 文章标题 Python反射
文章id 44734516 文章标题 Python将Json转为对象
文章id 44718294 文章标题 Python面向对象
文章id 44718286 文章标题 Python多元赋值
文章id 44530690 文章标题 Python之推导式
文章id 44529667 文章标题 Python基本类型
文章id 44520951 文章标题 Python属于动态强类型语言
文章id 44520978 文章标题 第一个Python程序3、自动化登录
网站爬虫与反爬虫之间的对战是一场持续的技术较量。爬虫开发者试图尽可能多地从网站上抓取信息,而网站开发者则试图保护他们的数据不被非法或过度抓取。
本文所介绍的反爬虫策略只是用来演示和学习,而不会对网站进行破坏。因此,只提供一些伪代码,而隐藏真实网站的相关信息。
3.1、网站登录图片验证方式
网站登录的时候,除了输入账号密码之外,还可能需要进行一些图片验证,例如下图。
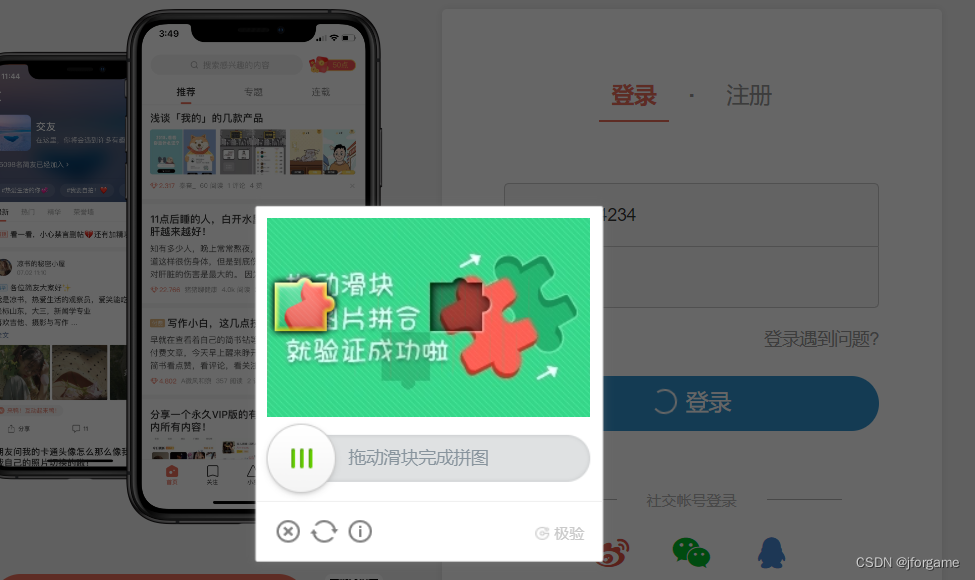
常见的验证方式有:
- 图片选择:要求用户在一组图片中选择特定的图片或者按照特定的要求进行图片排序,例如选择包含某个物体的图片、选择与某个图片相似的图片等。
- 图片拼图:要求用户拖动或旋转图片,将图片拼合成完整的图像。
- 图片识别:要求用户根据提供的图片中的验证码或文字进行识别,例如输入图片中显示的文字或数字。
- 逻辑判断:要求用户根据一组图片中的某种规律或者某种共同特征进行判断,例如选择与其他图片不同的图片、选择与指定要求相符的图片等。
对于这些验证方式,爬虫有两种方式进行处理。
第一种半自动化:爬虫工具自动拉取浏览器,自动输入账号密码之后,由用户手动输入验证码,拿到token后再进行数据爬取。
第二种全自动化:爬虫工具自动拉取浏览器,利用打码平台(平台自身使用ai训练或雇佣人工操作),由第三方进行验证返回识别结果,拿到token。
本文主要讲解第二种识别方法。
3.2、使用打码平台自动识别验证码
验证码打码平台是一种在线服务,它可以帮助用户自动识别和解析各种形式的验证码。这些验证码通常是为了验证用户的真实性或防止恶意活动而设置的。打码平台通过使用机器学习和人工智能算法来识别和解析这些验证码,然后将结果返回给用户。用户可以通过API接口或者网站上传验证码图片,并获取解析结果。这些平台通常提供高度准确的解析结果和快速的响应时间,使用户能够更有效地处理验证码。
比如下面一款打码平台,可识别大部分验证码类型。

基本登录
对于自动输入账号,密码,我们可以使用Selenium工具。
Selenium是一个开源的自动化测试框架,用于测试Web应用程序的功能。它提供了一系列工具和库,可以让开发者模拟用户在浏览器中的操作,例如点击、输入文本、选择元素等。Selenium支持多种编程语言,包括Java、Python、C#等,使开发者能够根据自己的喜好和需求选择合适的语言进行测试脚本的编写。
示例代码如下:
# 指定 ChromeDriver 的路径
driver_path = 'chromedriver.exe'
# 创建 WebDriver 实例
driver = webdriver.Chrome()
driver.maximize_window()def login_form():# 打开一个网页driver.get('https://xxx.login')driver.implicitly_wait(5)driver.find_element(By.ID, 'username').send_keys('jforgame')driver.find_element(By.ID, 'pwd').send_keys('jforgame')
3.3、获取验证码图片
一般情况下,验证码图片比较容易获得,只需从chrome调试网络工具查看请求的地址,再根据这个url重新请求一下图片后进行本地保存即可。
部分网站提供了更加安全的措施,为了反爬虫,对于生成的图片是一次性的。每次请求图片的url,返回的图片内容都是不同的。如此很难拿到已经发送到客户端的图片了。但方法也是有的,大致有以下几种策略。
拦截一次性验证码图片策略:
- 网站连接到自己写的http代理服务器,每次请求,如果是图片则同时将网站返回的图片内容保存到本地。这种方式如果是网站使用了https方式,这种代理代码不好实现。
- 爬虫自动控制浏览器,定位到图片位置,使用右键进行保存。selenium只支持定位到图片位置,并点击右键,但无法继续触发右键的另存为操作,失败。
- 简单笨拙的方法,爬虫直接截取屏幕指定范围的图片,只需慢慢调整截图的位置坐标,可以实现。python有pyautogui工具库可以使用,示例代码如下:
# 定位到图片元素
imgEle = driver.find_element(By.XPATH, '//*[@id="capture"]/img')#顶点横坐标
left = 500
#顶点纵坐标
top = 400
width = 200
height = 150def save_screenshot():# 截取屏幕并保存为文件screenshot = pyautogui.screenshot(region=(left, top, width, height))screenshot.save('screenshot.jpeg')3.4、将图片发送到打码平台进行解析
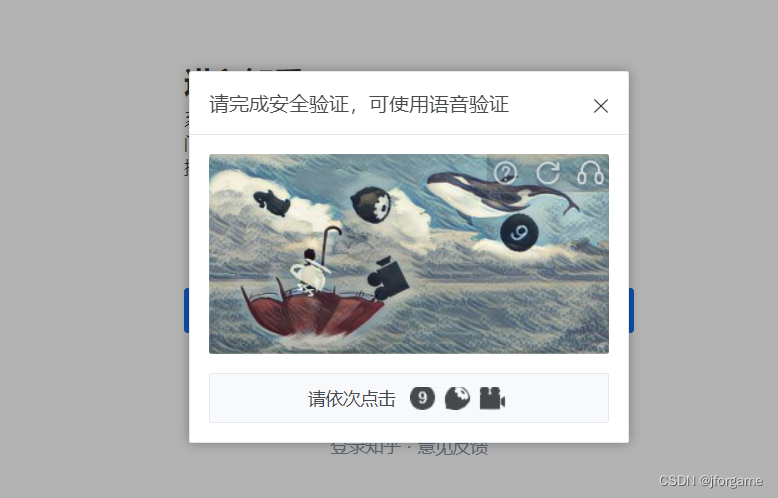
网上有很多打码平台,读者可自行选择,一般平台都提供测试积分,测试合适再进行选择。将返回结果封装成坐标元组即可。下面以点击类验证码做演示:
def ydm():url = 'http://api.xxxxx/analyze'image_path = "screenshot.jpeg" # 替换为实际图片路径image_data = image_to_base64(image_path)data = {'image': image_data,'token': 'copy your platform token here','type': 10086}# 发送请求response = requests.post(url, data=data)response_json = response.textobj = json.loads(response_json)if obj['msg'] == "succ":pos_data = obj['data']['data']print('识别成功')for _, e in enumerate(pos_data.split('|')):unit = e.split(",")pos_list.append((int(unit[0]), int(unit[1])))return pos_listelse:print(response_json)return None
3.5、根据解析坐标向平台发送登录请求。
拿到点击坐标之后,还没完成目标。一些网站对坐标的输入进行加密,只有把坐标信息经过加密后服务器才认可。虽然浏览器代码是裸奔的,但要解读加密算法需要一定功力。我们可以换个思维——无招胜有招。
既然验证码加密了,我们也无需解密。直接祭上我们的selenium工具,利用自动化测试工具,模拟用户进行点击,由于selenium直接操作浏览器,由浏览器客户端代码自行发送请求,就无需解密了。
def auto_click_capture():try_counter = 0while try_counter < max_try:pos_list = ydm()for _, pos in enumerate(pos_list):time.sleep(1)ActionChains(driver).move_to_element_with_offset(imgEle, pos[0],pos[1]).click().perform()try:# 如果页面检测到登录按钮,则脚本成功login_btn = driver.find_element(By.ID, 'loginBtn')login_btn.click()returnexcept Exception:try_counter = try_counter + 1print(f"第{try_counter}次尝试,未找到")time.sleep(1)由于网站有些图片尺寸比较小,或者图片加了旋转,打码平台返回的坐标不是很精准。一次性成功的机率不高,我们可以加多一次重试。
3.6、自动获取网站登录token
登录成功之后,我们希望自动获取到网站的登录token,而不是通过网络工具手动复制参数。selenium对此无能为力,我们可以使用selenium的增强版seleniumwire。seleniumwire增加了拦截http请求响应的功能,并完全兼容selenium。下载之后只需修改import的webdriver路径即可。
not_found = True
token = ''while not_found:for request in driver.requests:if request.response and request.url.find("xxyy/loginIn"):# print( request.url,request.response.headers)for i, item in enumerate(request.response.headers.items()):if item[0] == 'set-cookie' and item[1].find('JWT_SESSION') != -1:JWT_SESSION= match_inner_characters(r"JWT_SESSION=(.*?);", item[1])print("JWT_SESSION", JWT_SESSION)matchContent = match_inner_characters(r"___TOKEN=(.*)", JWT_SESSION)if matchContent:not_found = Falsetoken = matchContent.replace("; Path=/", "")cookies = '自行封装其他额外token信息'time.sleep(3)print('Cookies ', cookies)
print('token', token)拿到token和cookies信息,大功告成!