目录
- 一、基本概念
- 1. 定义
- 2. 作用
- 3. 原理
- 二、实验基本原则
- 三、实验步骤
- 四、实验步骤详解
- 1. 确定实验目的
- 2. 确定实验变量
- 3. 实验指标设计
- 3.1 实验指标类型(按作用区分)
- 3.1.1 核心指标
- 3.1.2 驱动指标(跟踪指标)
- 3.1.3 护栏指标
- 3.2 实验指标类型(按计算方式区分)
- 3.2.1 绝对值类指标
- 3.2.2 比率类指标
- 3.3 如何选择评价指标
- 3.3.1 根据当前所处阶段的目标
- 3.3.2 采用定性 + 定量相结合的方法
- 4. 样本选择
- 4.1 最小样本量计算公式(绝对值类指标,比率类指标通用)
- 4.2 样本标准差计算公式
- 4.2.1 绝对值类指标
- 4.2.2 比率类指标
- 4.3 实验周期计算公式(绝对值类指标,比率类指标通用)
- 4.4 样本量与实验周期注意事项
- 4.4.1 样本量不足问题
- 4.4.2 样本量过大问题
- 4.4.3 实验周期长短问题
- 4.5 AA 测试
- 4.5.1 定义
- 4.5.2 目的
- 4.5.3 举例
- 4.5.4 AA 测试时发现差异过大可能原因
- 4.5.5 实验指标波动性过大解决方法:CUPED
- 4.6 样本选择要避免的问题(辛普森悖论)
- 4.6.1 定义
- 4.6.2 产生原因
- 4.6.3 结构化梳理辛普森悖论触发原因
- 4.6.4 减少辛普森悖论的产生
- 4.7 学习效应
- 4.7.1 定义
- 4.7.2 分类1(新奇效应)
- 4.7.3 分类2(改变厌恶)
- 4.7.4 避免学习效应的方法
- 5. 流量设计
- 5.1 分流(互斥)实验
- 5.2 分层(正交)实验
- 5.3 圈层实验
- 6. 实验与评估
- 6.1 Z检验公式
- 6.1.1 绝对值类指标
- 6.1.2 比率类指标
- 6.2 第一类错误与第二类错误
- 6.3 实验评估流程
- 6.3.1 整体指标分析
- 6.3.2下钻指标维度
- 6.3.3 case 抽取分析
- 6.4 实验效果不显著的原因与解决方法
- 6.5 实验统计上显著,实际不显著可能原因
- 7. 实验放量
- 7.1 放量流程
- 7.1.1 第一阶段(小流量阶段)
- 7.1.2第二阶段(放量阶段)
- 7.1.3第三阶段(长期存放阶段)
- 五、相关代码实践
一、基本概念
1. 定义
有两个随机均匀的样本组 A、B,在同一个时间维度,对其中一个组B做出某种改动策略,实验结束后分析两组的数据。通过显著性检验,判断这个改动策略对于核心指标是否有显著的影响。
2. 作用
验证改动策略是否可行有效的方法。
3. 原理
1)大数定律(实验次数足够多时,随机事件发生的频率近似等于其概率)
2)中心极限定理(样本量很大时,样本均值近似服从给标准正态分布)
3)假设检验
二、实验基本原则
同期性: 同一时期对于 A、B组进行实验。
唯一性: 每一个实验样本都只存在于一个组里。
均衡性: 实验样本均衡分布在 A、B组(即 A、B组的实验样本量大致相同,A、B组的实验样本的比例占比大致相同)。
随机性: 实验样本随机分配到 A、B组。
样本量足够且独立: 实验样本量足够,同时实验样本间互不干扰。
三、实验步骤
1.确定实验目的
2.确定实验变量
3.实验指标设计: 除了核心指标(主指标),提出驱动指标、护栏指标。
4.样本选择: 选择实验群体,确定最少样本量、样本无关性。
5.流量设计: 分流(互斥)实验,分层(正交)实验,分流分层实验、圈层实验。
6.实验与评估: 线上实验,调整流量,分析数据,得到结论。
7.实验放量: 结论通过,灰度实验上线;不全量切换,先上线一部分。
四、实验步骤详解
1. 确定实验目的
1)明确是否有必要进行 AB 测试的线上验证,因为有一些问题通过数据分析方法也能解决。由于 AB 测试需要一定成本(如对用户体验的影响),所以要弄清目的,进行相关评估。
2)若确定要进行 AB 测试,要弄清本次实验的目的是什么,是验证个性化推荐功能对于客单价的提升与否还是其它方面。实验目的明确了,才能决定后续的实验变量、相关实验指标、分流维度、实验类型以及如何综合评估实验的效果。
2. 确定实验变量
实验目的明确后,也就确定了实验变量。如不同的优惠券类型、是否添加个性化推荐功能、产品包装样式是否更改、小红书发笔记是否添加封面等。
3. 实验指标设计
3.1 实验指标类型(按作用区分)
3.1.1 核心指标
其能最直接反应改动策略对用户行为的影响。 例如,你的产品是把一个按钮从红色改为了蓝色,AB 测试的目的就是看这种改动策略是否能让更多的用户点击进入页面,那么核心指标就可以选 CTR(Click Through Rate,即用户点击率)。核心指标的个数不宜太多,一般不超过三个。同时,核心指标的是否成功必须是能在短时间内被验证,并能够指示长期影响的指标。
3.1.2 驱动指标(跟踪指标)
其不能直接衡量改动策略是否有效,但是能帮助检测改动策略如何影响核心指标。 如果核心指标有异动,那么驱动指标能帮忙分析改动策略是如何导致核心指标发生变化的。比如在新界面上线后:
① 用户购买量下降了(核心指标),同时用户浏览量和在线时长都减少了。说明新的 UI 设计不合理,使用户的体验变差了,提前关闭 APP,导致了购买下降。
② 用户购买量下降了(核心指标),但是用户浏览量和在线时长都提高了。说明新的 UI 设计让用户愿意花更多时间浏览 APP。因为浏览时间变长了,用户发现了很多喜欢的商品,但是由于选择过多,反而让用户更难下定决心购买。
3.1.3 护栏指标
其用来检测AB实验是否对整体产品产生了负面影响。 例如,在测试抖音是否可以开启给博主打赏这个功能的时候,我们并不希望抖音的日活数下降。护栏指标能帮助理解 AB 测试是否设置正确,以及 AB 测试是否对整体产品造成伤害。
① 护栏指标可以是产品的性能指标。 例如测试新的搜索引擎,一般也会对其性能进行衡量,例如:多少搜索成功完成,平均耗时多少?虽然这些度量并不完全决定是否发布新的搜索引擎,但是如果其表现很差,即使核心指标(搜索相关性)有一定提高,往往也不会发布新的产品。
② 护栏指标也可以是不直接影响的商业价值指标。 例如在做用户增长实验时,可以将用户体验作为护栏指标。虽然大部分的新产品和新功能都不应该影响用户体验, 但是将它们加入护栏指标可以对实验结果更有信心。
3.2 实验指标类型(按计算方式区分)
3.2.1 绝对值类指标
其是直接通过计算就能得到的单个指标,不需要多个指标计算得到。 一般都是统计该指标在一段时间内的总值或者均值,例如 DAU,平均停留时长等。这类指标一般较少作为 AB 测试的观测指标。
3.2.2 比率类指标
其不能直接通过计算得到,而是通过多个指标计算得到。 例如某页面的点击率,我们需要先计算页面的点击数和展现数,两者相除才能得到该指标。类似的,还有转化率、复购率等。AB 测试的大部分指标都是比率类指标。
3.3 如何选择评价指标
3.3.1 根据当前所处阶段的目标
产品初期,公司通常以拉新作为主要业务目标。在这一阶段,我们可以选择点击率、转化率作为评价指标;在产品的发展期和成熟期,则会关注留存情况,我们可以选择平均使用时间和频率、留存率作为评价指标。
3.3.2 采用定性 + 定量相结合的方法
对于一些较为抽象的指标(例如用户满意度),我们可以使用一些定性的方法,例如问卷调查、用户调研等进行定量的数据分析,来了解用户的使用行为。把定性的用户调研结果和定量的用户使用行为分析结合起来,找出哪些用户使用行为和和用户满意度有较强的关系。
4. 样本选择
4.1 最小样本量计算公式(绝对值类指标,比率类指标通用)
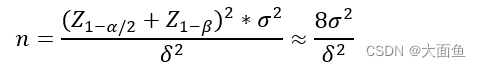
一般情况下:
置信水平:α = 0.05,Z1 - α/2 = 1.96
统计功效:1 - β = 0.8(β = 0.2),Z1 - β = 0.84
σ 代表的是样本标准差,衡量的是整体样本的波动性
δ 代表的是预期实验组和对照组两组数据的差值,比如说我们希望点击率从20% 提升到 25%,那么δ = 5%
4.2 样本标准差计算公式
4.2.1 绝对值类指标
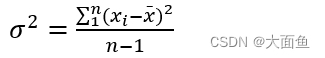
4.2.2 比率类指标
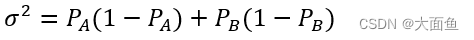
PA、PB 分别为对照组和实验组的观测数据。例如,我们希望点击率从 20% 提升到 25%,那么 PA = 20%,PB = 25%
4.3 实验周期计算公式(绝对值类指标,比率类指标通用)
 每日实验用户量 = 用户日活数(或者日均订单数等指标)* 每日流量分配占比
每日实验用户量 = 用户日活数(或者日均订单数等指标)* 每日流量分配占比
每日流量分配占比(一般情况):百万级 → 3%,千万级 → 1%,亿级 → 0.1%
4.4 样本量与实验周期注意事项
4.4.1 样本量不足问题
① 偶然误差: 样本量较小时,测试结果可能会受到偶然误差的影响。例如,如果某一天的用户行为发生异常,可能会对测试结果产生较大影响。
② 缺乏代表性: 如果实验样本不能很好地反映总体用户群体的特点,那么测试结果可能无法推广到所有用户。
4.4.2 样本量过大问题
可能造成实验资源的浪费,同时可能影响迭代效率。
4.4.3 实验周期长短问题
① 实验周期果断可能导致测试结果不稳定,在短时间内,用户行为可能会发生变化。例如,节假日与促销活动等都可能导致用户行为出现波动,较长的实验周期可以确保测试结果更加稳定。
② 一个实验周期要尽量覆盖用户或者业务的一个周期性规律。
4.5 AA 测试
4.5.1 定义
AA 测试是指比较同一变量同一个版本的测试(例如新版本)。
4.5.2 目的
一般来说,AA测试用来检验AB测试结果的波动性、AB测试的用户分流设计是否合理等。 如果 AB 测试设计合理,那么预期 AA 测试将得出实验组与对照组没有显著差异的结论。但是如果 AA 测试结果差异显著,说明本次实验变量本身的效果波动就很大,原来 AB 测试的结果也不够置信。
4.5.3 举例
AA 测试比较两个一模一样按钮的点击率,测试流程与 AB 测试相同。如果最终结果显示两个按钮的点击率有统计意义上的显著差异,那么有两种可能:
① 出现了第一类错误: 这种可能性无法避免,因为假设检验本身预设了第一类错误的概率,通常为 5%,因此由于这种可能性而出现显著性差异的概率是 5%。
② 测试在至少一个步骤上出现了问题: 这种可能性是最常见的,往往是测试对象分流的随机性不够,使得实验组和对照组的测试对象有内在的差异,或者是指标的波动性过大。因此,需要对测试对象进行再随机分组,重新进行统计检验,这个过程可能需要重复若干次,直到检验不出现显著性差异,接下来则可以基于这一分组进行 AB 测试。
4.5.4 AA 测试时发现差异过大可能原因
样本量不足,出现第一类错误,实验观测周期短,分流不科学,观测指标本身不合理,组间均值差异过大,指标波动性大。
4.5.5 实验指标波动性过大解决方法:CUPED
定义: 其是一种利用 AB 测试前的数据来缩减实验指标方差,进而提高实验灵敏度的方法,让实验指标更容易显著,进而让有效的改动策略上线,避免第二类错误(错误地接受策略上线前后没有差异的原假设)的发生。
本质:对 X,Y 进行二维线性回归,利用 AB 测试前的数据对实验指标进行修正,在保证实验指标均值估计无偏的情况下, 得到方差更低的新实验指标,再对新实验指标进行统计检验,这样就可以得到更显著的结果。
目的:在不增加样本量的情况下,降低方差,使得实验指标越可能显著。
公式:
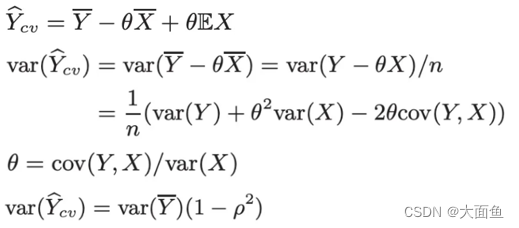
假设Y是我们实验想观察的实验指标,现在用另一个变量 X 和常数 θ 构造一个新实验指标,如图(1)所示,为了让其方差最小化,可以取常数 θ 为图(4)所示。由此可以得出三个结论:
① 新实验指标是 Y 的均值的无偏估计,其均值和Y的均值是一致的
② 新实验指标的方差比 Y 的方差小,且影响大小的正是 X 和 Y 的协方差。
③ 如果能选取和Y高度相关的协变量X,那么新实验指标的方差相比Y将会小很多。 大多数情况下最相关的还是原来这个指标。例如实验要比较的是司机在线时长的差异,即 Y 为实验中司机的在线时长数据,那么 X 就选司机在实验前的在线时长数据。实验前数据一般选取一周到两周的周期。
4.6 样本选择要避免的问题(辛普森悖论)
4.6.1 定义
一般情况下,在进行分组研究并计算分项的比例(例如各种各样的率)数据时,A 组的每一分项的数据都比 B 组数据要高,但是把各分项汇总起来计算总体数据时,A 组数据却比 B 组数据低的现象。

4.6.2 产生原因
AB实验中,两组在不同细分领域中的数据分布不均衡造成的。
| 城市 | 对照组(一百万用户,点击率) | 实验组(一百万用户,点击率) | 总体 |
|---|---|---|---|
| 北京 | 19710 / 900000 = 2.13% | 1010 / 100000 = 1.01% | 2.02% |
| 上海 | 2560 / 100000 = 2.56% | 11790 / 900000 = 1.31% | 1.44% |
例如上表中,北京对照组中的用户数量占 90%,因此其总体的用户转化率受对照组影响最大。上海实验组中的用户数量占 90%,因此其总体的用户转化率受实验组影响最大。但是上海实验组的用户转化率要低于北京对照组的用户转化率,导致上海总体的用户转化率低于背景总体的用户转化率。
4.6.3 结构化梳理辛普森悖论触发原因
| 统计对象 | 分项1指标 | 分项2指标 | 总体 |
|---|---|---|---|
| 统计对象1 | q1 / p1 | q3 / p3 | (q1 + q3) / (p1 + p3) |
| 统计对象2 | q2 / p2 | q4 / p4 | (q2 + q4) / (p2 + p4) |
基于上表,当出现以下 3 个数字特征的时候,即使统计对象1在两个分项指标都高于(或低于)统计对象2,那么也有较大的概率,使得汇总数据出现反转:
① 关注同一统计对象分母的大小比较:统计对象1中,分项1指标和分项2指标的分母 p1 和 p3 不是一个数量级(例如 p1 是百万级,而 p3 是万级)。
② 关注同一统计对象在不同分项指标中,比例值的比较:统计对象1中,分项1指标的比例值(q1 / p1)显著高于(或低于)分项2指标的比例值(q3 / p3)(例如 65% vs 35%)。
③ 关注两个统计对象在不同分项指标中,分母比例分布的比较:统计对象2的分母 p2 和 p4,与统计对象1的分母 p1 和 p3 的分布明显不同(例如统计对象1的分母 p1 和 p3 的比例是 9:1,但统计对象2的分母 p2 和 p4 的比例是 6:4)。
4.6.4 减少辛普森悖论的产生
① 分析测试结果前,做好合理性检验。如果没有进行合理性检验,最好的解决办法就是重新跑实验,看两组在不同细分领域的分布不均衡会不会消失。如果分布不均衡的情况没有消失,就说明这很可能不是偶然事件,这时就要检查是否是工程或者实施层面出现了问题,由此造成了分布的不均衡。
② 进行合理正确的流量分割,保证实验组和对照组的用户特征是一致的,并且都具有代表性,可以代表总体用户特征。
③ 在实验设计上,如果我们觉得两个变量对实验结果都有影响,那就应该把这两个变量放在同一层进行互斥实验,不要让一个变量的实验动态影响另一个变量的实验。
④ 在实验实施上,我们要对实验结果进行多维度的细分分析。除了总体对比,也要看看细分受众群体的实验结果,不要以偏概全。一个实验版本提升了总体活跃度,但可能降低了年轻用户群体的活跃度,那么这个实验版本可能算不上好版本。一个实验版本提升了总体营收 0.1%,似乎不起眼,但是上海地区的年轻男性用户群体的购买率提升了 20%,这个实验版本就很有价值。
4.7 学习效应
4.7.1 定义
当我们想通过AB测试检验非常明显的变化时,比如改变产品的交互界面和功能,老用户往往适应了之前的交互界面和功能,对他们来说需要一段时间来适应和学习新产品,所以老用户在适应阶段的行为跟平时有些不同。
4.7.2 分类1(新奇效应)
在AB测试中,由于用户对于新变化有很强的好奇心,愿意去尝试,进而导致测试初期的结果偏离常态。这种现象通常会在新版本或新功能推出的一段时间内发生,随着时间的推移,用户的新奇感逐渐消退,行为才会恢复到正常状态。
4.7.3 分类2(改变厌恶)
在AB测试中,由于用户对于新变化比较困惑,产生抵触心理,例如,电商网站的购物车功能原本在屏幕的右下方,交互界面改变后,购物车功能的位置变味了屏幕的左上方,用户可能需要一点时间才能找到,导致其可能受负面情绪影响提前关闭了界面,这时短时期内的指标就会下降。
4.7.4 避免学习效应的方法
① 观察实验组的指标随时间(以天为单位)的变化情况: 没有学习效应的情况下,实验组的指标随时间的变化是相对稳定的。但是有学习效应时,因为学习效应是短期的,长期来看会慢慢消退,那么实验组的指标就会有一个随时间慢慢变化的过程,直到稳定。
② 只关注实验组与对照组的新用户: 学习效应是老用户为了适应新的变化产生的。那么可以现在两组中找出老用户,只在两组的新用户中分别计算实验指标,最后再比较这两个实验指标。如果在新用户的比较中没有得出显著结果(样本量充足的情况下),但是在总体的比较中得出了显著结果,那么就说明这个新变化对于新用户没有影响,但是对于老用户有影响。
③ 延长测试时间: 等到实验组的学习效应消退,再比较两组的结果。
5. 流量设计
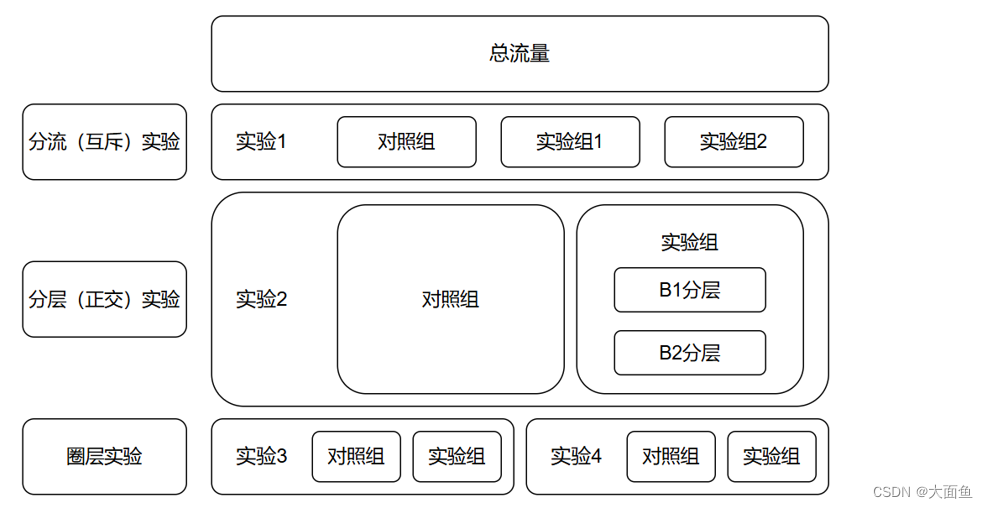
5.1 分流(互斥)实验
用户分流(互斥)是指按照地域、性别、年龄等把用户均匀地分为几个组,1 个用户只能出现在 1 个组中。但是实际情况中,往往会同时上线多个实验,拿广告来说,有针对样式形态的实验,有针对广告位置策略的实验,有针对预估模型的实验。如果只是按照这种分流模式来,在每组实验放量 10% 的情况下,整体的流量只能同时开展 10 个实验。这个实验的效率是非常低的。为了解决这个问题,提出了用户分层、流量复用的方法。例如上图中,对照组、实验组1、实验组2 通过分流的方式分为 3 组流量,此时对照组、实验组1、实验组2 是互斥的,即对照组流量 + 实验组1流量 + 实验组2流量 = 100% 试验流量。
5.2 分层(正交)实验
同一份流量可以分布在多个实验层,也就是说同一批用户可以出现在不同的实验层,前提是各个实验层之间无业务关联,保证这一批用户都均匀地分布到所有的实验层里,达到用户正交的效果就可以。所谓的正交分层,就是每一层用完的流量进入下一层时,一定均匀的重新分配。第一层中每个实验的流量会重新分组进入到第二层中的每个试验中。所以整个流量有一个分散,合并,再分散的过程,保证第二层中的每个实验分配的流量雨露均沾,这就是所谓的流量正交,从而实验流量复用的效果。例如上图中,流量流过实验组中的B1分层、B2分层时,B1分层、B2 分层的流量都与实验组的流量相等,相当于对实验组的流量进行了复用,即 B1 分层流量 = B2 分层流量 = 实验组流量(其实这一部分的图是同时互斥与正交的,此处为了方便而单独解释了正交)。
5.3 圈层实验
通常手中比较大的增长点做完了,更多的会去做用户的精细化运营,满足某些用户群体没有被很好满足到的需求,以带来业务上的增长。例如多日无播放行为的用户做一个圈层,做做引导。例如下载页无内容的用户做一个圈层,做做优质内容的推荐。例如某一兴趣标签的用户做一个圈层,提供更匹配的服务等。
6. 实验与评估
6.1 Z检验公式
6.1.1 绝对值类指标
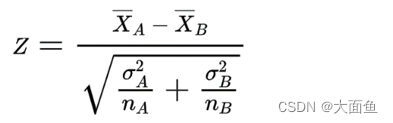
6.1.2 比率类指标
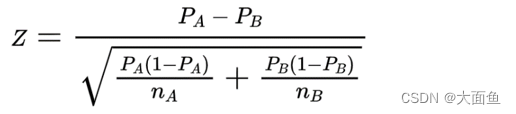
6.2 第一类错误与第二类错误
① 第一类错误: 其表示一个功能的改动,本来不能带来任何收益,但是我们误以为它能给我们带来收益。
② 第二类错误: 其表示一个好的产品,本来可以带来收益,但是由于统计误差,导致我们误以为它不能给我们带来收益。
③ 关注重点: 往往在实际的工作中,第一类错误是我们更加不能接受的。 也就是说,我们宁愿砍掉几个好的产品,也绝对不能让一个坏的产品上线。因为一个坏的产品上线会给用户体验带来极大的负面影响,而这个负面影响会非常大程度的影响到用户日活数以及留存率。在现实生活中,我们把留存或者把日活提升一个百分点都已经是一个非常了不起的优化了。但是通常要实现 1% 的留存率,都需要花费很长时间,但是如果想要留存率下降 1% 的话,可能就是一瞬间的事情。
④ 避免两类错误的方法
增加样本量: 较大的样本量可以提供更准确的总体估计和更高的统计功效。
控制显著性水平(α),考虑统计功效(1 - β)
多次独立重复实验: 可以减小随机误差的影响,提供更稳定一致的结果。
仔细选择样本: 样本的选择应该尽可能代表总体,避免选择偏倚。采用随机抽样的方法,并确保样本特征与分布与总体一致,可以减小偏差的风险。
6.3 实验评估流程
6.3.1 整体指标分析
通过实验指标的点估、区间估计、P 值、实验指标趋势等,评估改动策略效果是否显著。
6.3.2下钻指标维度
当实验重点关注部分群体时,分析中往往对用户进行下钻,聚焦用户评判效果;或者当实验效果不及预期时,会下钻维度分析原因。
6.3.3 case 抽取分析
当实验正负向较明显时,可以将极端 case 单拎出来,分析可能的原因。
6.4 实验效果不显著的原因与解决方法
实验效果不显著的原因
① 第一类:线上改动策略不佳,无明显差异。
② 第二类:实验灵敏度不够高。
针对第二类问题的解决方法
① 增加样本量: 只要实验组和对照组的差值及样本方差不变的情况下,样本量足够大,总是可以得到显著性的结果。
② 减少样本的方差: 减少离群值的影响,可以采用CUPED的方法。
③ 更换为方差更小的实验指标: 例如购物平台的实验指标一开始是用户购买的平均金额,我们可以更换为用户是否购买。对于同一批样本,用户是否购买服从0-1分布,样本的方差要比用户购买的平均金额小很多。
6.5 实验统计上显著,实际不显著可能原因
可能的原因是我们在AB测试当中所选取的样本量过大,导致和总体数据量差异很小,这样的话即使我们发现一个细微的差别,它在统计上来说是显著的,在实际的案例当中可能会变得不显著了。 举个例子,对应到我们的互联网产品实践当中,我们做了一个改动,APP的启动时间的优化了0.001秒,这个数字可能在统计学上对应的P值很小,也就是说统计学上是显著的,但是在实际中用户0.01秒的差异是感知不出来的。那么这样一个显著的统计差别,其实对我们来说是没有太大的实际意义的。所以统计学上的显著并不意味着实际效果的显著。
7. 实验放量
7.1 放量流程
实验放量阶段,需要综合考虑三个因素:效率、质量、风险。 对于一个实验,我们希望在评估正向的前提下,尽快上线。但往往由于策略bug、新功能不符合预期、用户体感不好等问题,使得在放量阶段需要更加谨慎,以下为一个标准的放量流程。
7.1.1 第一阶段(小流量阶段)
此阶段衔接在小流量评估后,整体放量比例控制在5%以下,评估实验是否对产品北极星指标有负向影响。同时验证策略的触发,以及排查是否存在潜在风险。在无风险的前提下,建议持续3-5日左右,进入下一个阶段。
7.1.2第二阶段(放量阶段)
在这个阶段,随着样本量的逐渐放开,实验的结果也会更加精准。同时,可能会出现流量压力等问题,因此在此阶段需要跟进放量,观察是否有出现问题。逐级放量建议持续至少一周,以观测周中和周末的影响。
7.1.3第三阶段(长期存放阶段)
针对部分实验,如果希望长期观测实验效果,可以保留5%以下的原始策略,作为反转桶。
五、相关代码实践
kaggle 数据集链接:https://www.kaggle.com/datasets/zhangluyuan/ab-testing
import numpy as np
import pandas as pd
from scipy.stats import normdf = pd.read_csv('ab_data.csv')
df = df.drop('landing_page', axis=1)
df# 对 group 进行分组,再对每组中 converted 列中的值分别进行计数
df.groupby('group')['converted'].value_counts()# 以上代码的运行结果
group converted
control 0 1294791 17723
treatment 0 1297621 17514
Name: count, dtype: int64# 先按照 group 列进行分组,然后对 converted 列进行求和,最后取出 control 组的求和结果
x_control = df.groupby('group')['converted'].sum().loc['control']
# 统计 group 列中为 control 的数据的数量
n_control = df[df['group'] == 'control'].shape[0]
# 先按照 group 列进行分组,然后对 converted 列进行求和,最后取出 treatment 组的求和结果
x_treatment = df.groupby('group')['converted'].sum().loc['treatment']
# 统计 group 列中为 treatment 的数据的数量
n_treatment = df[df['group'] == 'treatment'].shape[0]
print(f'Number of convertion in the control group: {x_control}')
print(f'Number of total data in the control group: {n_control}')
print(f'Number of convertion in the treatment group: {x_treatment}')
print(f'Number of total data in the treatment group: {n_treatment}')
# 计算对照组与实验组中的转化率
# 方法1
control_conversion_rate = x_control / n_control
treatment_conversion_rate = x_treatment / n_treatment
print(f'\nConversion rate of the control group: {control_conversion_rate:.6f}')
print(f'Conversion rate of the treatment group: {treatment_conversion_rate:.6f}')
# 方法2 (推荐,因为方便):按照 group 列进行分组,然后选择 converted 列,并对该列应用均值聚合函数。最后,从聚合结果中分别提取出 control 组和 treatment 组的均值,即两组的转化率。
p_control_conversion_rate = df.groupby('group')['converted'].agg(np.mean).loc['control']
p_treatment_conversion_rate = df.groupby('group')['converted'].agg(np.mean).loc['treatment']
print(f'\nConversion rate of the control group: {p_control_conversion_rate:.6f}')
print(f'Conversion rate of the treatment group: {p_treatment_conversion_rate:.6f}')# 以上代码的运行结果
Number of convertion in the control group: 17723
Number of total data in the control group: 147202
Number of convertion in the treatment group: 17514
Number of total data in the treatment group: 147276Conversion rate of the control group: 0.120399
Conversion rate of the treatment group: 0.118920Conversion rate of the control group: 0.120399
Conversion rate of the treatment group: 0.118920# 不计算合并方差
variance_control = p_control_conversion_rate * (1 - p_control_conversion_rate) * 1 / n_control
variance_treatment = p_treatment_conversion_rate * (1 - p_treatment_conversion_rate) * 1 / n_treatment
variance = variance_control + variance_control
print(f'Variance: {variance}')
# 计算合并方差
p_pooled = (x_control + x_treatment) / (n_control + n_treatment)
pooled_variance = p_pooled * (1 - p_pooled) * (1/n_control + 1/n_treatment)
print(f'\nP pooled: {p_pooled:.6f}')
print(f'Pooled variance: {pooled_variance}')# 以上代码的运行结果
Variance: 1.4388828544267224e-06P pooled: 0.119659
Pooled variance: 1.4308828178078735e-06# 计算标准误差
SE = np.sqrt(variance)
print(f'SE value: {SE}')
# 计算 Z 检验的值
Z_test = (abs(p_treatment_conversion_rate - p_control_conversion_rate)) / SE
print(f'\nTest statistics of Z test: {Z_test}')
# 计算在标准正态分布图上,对应的 x 轴的分位点的值
alpha = 0.05
Z_critical_value = norm.ppf(1-alpha/2)
print(f'\nValue on the standard normal distribution: {Z_critical_value}')
# 计算 p 值时,单侧检验不用乘 2,双侧检验要乘 2
p_value = norm.sf(Z_test)
print(f'\nP value: {p_value}')
if p_value <= alpha:print('There is a statistical significance.')
else:print('There is no statistical significance.')# 以上代码的运行结果
SE value: 0.0011995344323639577Test statistics of Z test: 1.233478384744372Value on the standard normal distribution: 1.959963984540054P value: 0.10869866814352241
There is no statistical significance.