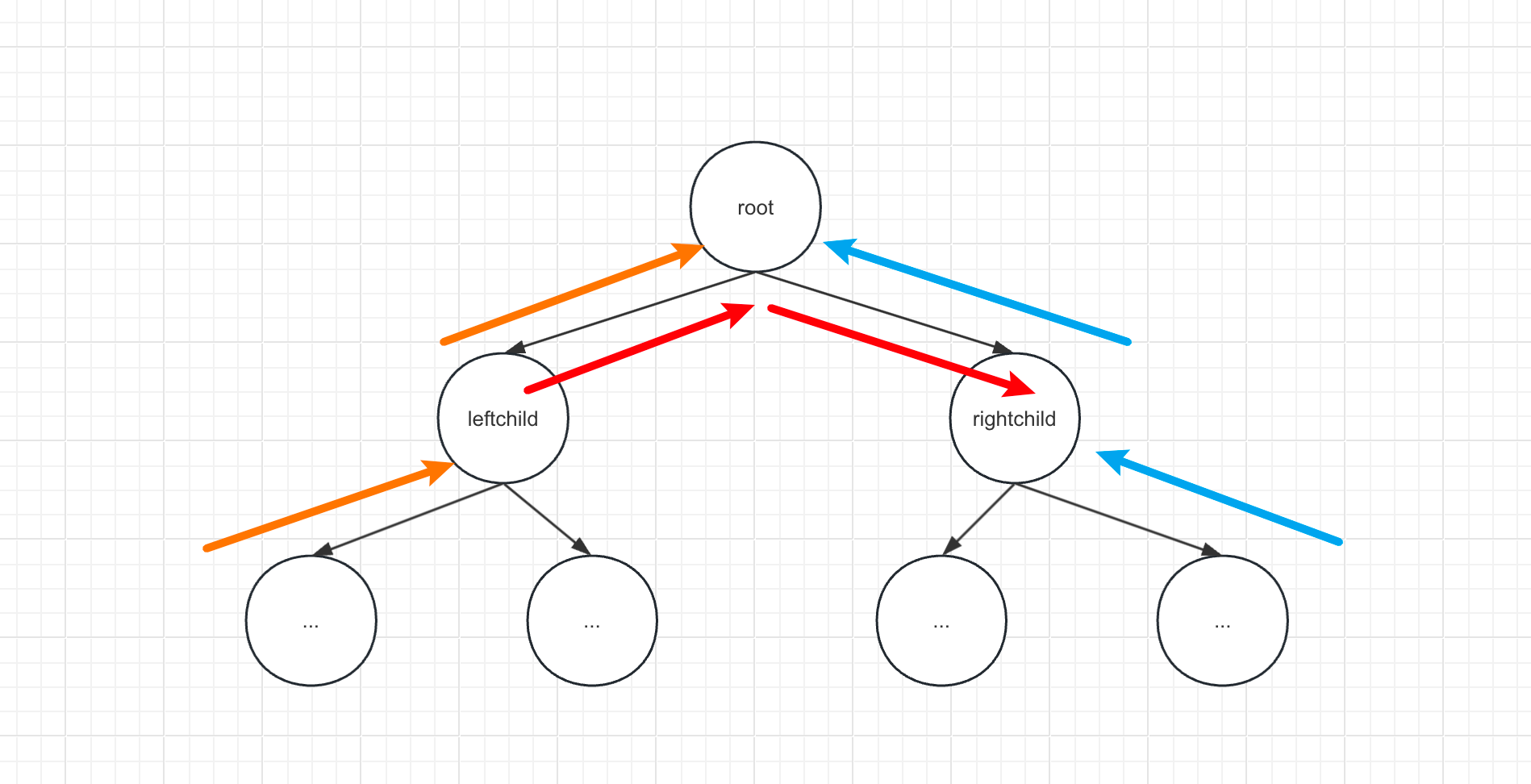
一、Transformer模型架构图
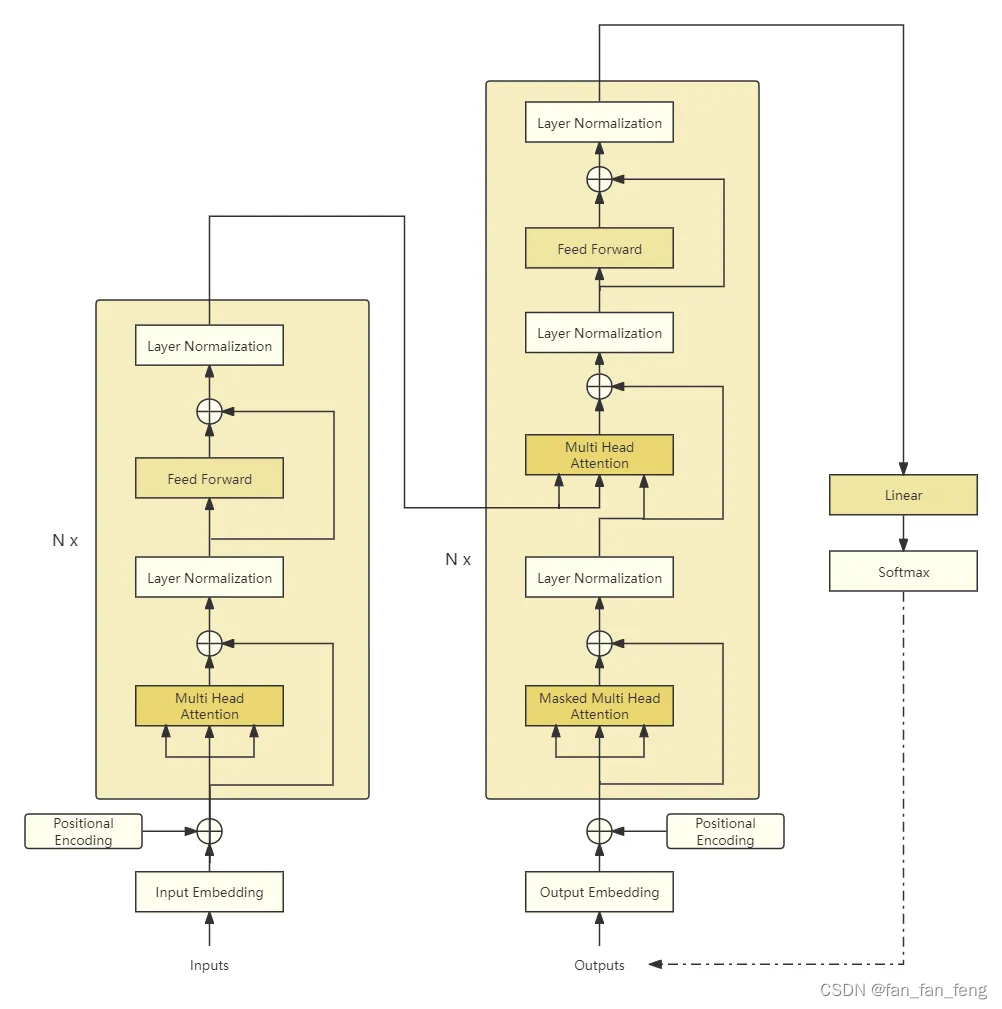
主要模块:
embedding层:
Input/Output Embedding: 将每个标记(token)转换为对应的向量表示。
Positional Encoding:由于没有时序信息,需要额外加入位置编码。
N个 block堆叠:
Multi-Head Attention: 利用注意力机制对输入进行交互,得到具有上下文信息的表示。根据其所处的位置有不同的变种:邻接解码器嵌入位置是掩码多头注意力,特点是当前位置只能注意本身以及之前位置的信息;掩码多头注意力紧接的多头注意力特点是Key和Value来自编码器的输出,而Query来自底层的输出,目的是在计算输出时考虑输入信息。
Layer Normalization: 作用于Transformer块内部子层的输出表示上,对表示序列进行层归一化。
Residual connection :作用于Transformer块内部子层输入和输出上,对其输入和输出进行求和。
Position-wise Feedforward Network: 通过多层全连接网络对表示序列进行非线性变换,提升模型的表达能力。
二、分词器BPE
2.1 原理
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。
BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
BPE训练算法的步骤如下:
-
初始化语料库
-
将语料库中每个单词拆分成字符作为子词,并在单词结尾增加一个
</w>字符 -
将拆分后的子词构成初始子词词表
-
在语料库中统计单词内相邻子词对的频次
-
合并频次最高的子词对,合并成新的子词,并将新的子词加入到子词词表
-
重复步骤4和5直到进行了设定的合并次数或达到了设定的子词词表大小
2.2 tokenize实现
from collections import defaultdict
import jieba
from typing import *class BPETokenizer:def __init__(self,special_tokens=[]) -> None:''':param sepcial_tokens: 额外添加的特殊token,'''self.word_freqs = defaultdict(int)self.merges = {}self.token_to_id = {}self.id_to_token = {}if special_tokens is None:special_tokens = []special_tokens = ['<PAD>', '<UNK>', '<BOS>', '<EOS>'] + special_tokensfor token in special_tokens:self._add_token(token)self.unk_token = "<UNK>"self.unk_token_id = self.token_to_id.get(self.unk_token)def _add_token(self,token:str) -> None:'''将token添加到词表中:param token::return:'''# 新添加的token添加到最后,所以idx默认是当前词表的长度if token not in self.token_to_id:idx = len(self.token_to_id)self.token_to_id[token] = idxself.id_to_token[idx] = token@propertydef vobcab_size(self) -> int:return len(self.token_to_id)## 以下是训练bpe相关函数 startdef _learn_vocab(self,corpus: list[str]) -> None:'''统计词频:param corpus::return:'''for sentence in corpus:sentence = sentence.lower()# 分词统计词频words = [w for w in jieba.cut(sentence) if w != " "]for word in words:self.word_freqs[word] += 1def _compute_pair_freqs(self,splits) -> dict[Tuple, int]:'''统计相邻字符的共现频率:param splits::return:'''pair_freqs = defaultdict(int)## 遍历word里面的相关的子字符,统计共现频率for word,freq in self.word_freqs.items():split = splits[word]if len(split) == 1:continuefor i in range(len(split) - 1):pair = (split[i], split[i + 1])pair_freqs[pair] += freqreturn pair_freqsdef _merge_pair(self,a:str,b:str,splits):'''合并字符并跟新split里面word对应的字符组成比如 splits里面有个单词是 “hello”:['h','e','l','l','o']如果合并了字符h和字符e,那么就要变成“hello”:['he','l','l','o']:param a::param b::param splits::return:'''for word in self.word_freqs:split = splits[word]if len(split) == 1:continuei = 0while i < len(split) -1:if split[i] == a and split[i+1] == b:split = split[:i] + [a + b] + split[i+2:]else:i += 1splits[word] = splitreturn splitsdef _merge_vocab(self,vocab_size,splits):''':param vocab_size: 预期的词表的大小,当达到词表大小,bpe算法就结束:param splits::return:'''merges = {}while self.vobcab_size < vocab_size:# 先统计共现频率pari_freqs = self._compute_pair_freqs(splits)best_pair = Nonemax_freq = 0for pair,freq in pari_freqs.items():if max_freq < freq:best_pair = pairmax_freq = freq# 合并新词splits = self._merge_pair(*best_pair,splits)# 将新词加入词表merges[best_pair] = best_pair[0] + best_pair[1]self._add_token(best_pair[0] + best_pair[1])return mergesdef train(self,corpus,vocab_size):'''bpe训练代码:param corpus: 文本语料:param vocab_size: 期望的词表大小:return:'''self._learn_vocab(corpus)splits = {word: [c for c in word] for word in self.word_freqs.keys()}for split in splits.values():for c in split:self._add_token(c)self.merges = self._merge_vocab(vocab_size, splits)## 训练bpe相关函数 enddef tokenize(self,text):'''bpe分词:param text::return:'''text = text.lower()words = [w for w in jieba.cut(text) if w != " "]splits = [[c for c in word] for word in words]for pair,merge in self.merges.items():for idx,split in enumerate(splits):i = 0while i < len(split) -1:if split[i] == pair[0] and split[i+1] == pair[1]:split = split[:i] + [merge] + split[i + 2:]else:i += 1splits[idx] = splitreturn sum(splits,[])def _convert_token_to_id(self,token:str):'''将token转换为具体的id:param token::return:'''return self.token_to_id.get(token,self.unk_token_id)def _convert_id_to_token(self,index:int) -> str:return self.id_to_token.get(index,self.unk_token)def _convert_ids_to_tokens(self,token_ids: list[int]) -> list[str]:return [self._convert_id_to_token(index) for index in token_ids]def _convert_tokens_to_ids(self, tokens: list[str]) -> list[int]:return [self._convert_token_to_id(token) for token in tokens]def encode(self, text: str) -> list[int]:tokens = self.tokenize(text)return self._convert_tokens_to_ids(tokens)def clean_up_tokenization(self, out_string: str) -> str:out_string = (out_string.replace(" .", ".").replace(" ?", "?").replace(" !", "!").replace(" ,", ",").replace(" ' ", "'").replace(" n't", "n't").replace(" 'm", "'m").replace(" 's", "'s").replace(" 've", "'ve").replace(" 're", "'re"))return out_stringdef decode(self, token_ids: list[int]) -> str:tokens = self._convert_ids_to_tokens(token_ids)return self.clean_up_tokenization(" ".join(tokens))if __name__ == '__main__':corpus = ["This is the Hugging Face Course.","This chapter is about tokenization.","This section shows several tokenizer algorithms.","Hopefully, you will be able to understand how they are trained and generate tokens.",]tokenizer = BPETokenizer()tokenizer.train(corpus, 50)print(tokenizer.tokenize("This is not a token."))print(tokenizer.vobcab_size)token_ids = tokenizer.encode("This is not a token.")print(token_ids)# this is not a token.#由于分词的时候没有 对单词的尾部/w处理,导致decode的时候不知道单词是否结束print(tokenizer.decode(token_ids))三. Embedding层
import math
from torch import nn,Tensor
class Embedding(nn.Module):def __init__(self,vocab_size:int, d_model:int) -> None:''':param vocab_size: 词库大小:param d_model: embedding的向量维度'''super().__init__()self.embed = nn.Embedding(vocab_size,d_model)self.sqrt_d_model = math.sqrt(d_model)def forward(self,x:Tensor) -> Tensor:''':param x: 输入的Tensor,(batch_size,seq_length):return: Tensor,shape为:(batch_size,seq_length,d_model)'''## 论文里面,初始化以后要乘以 d_model的平方根return self.embed(x) * self.sqrt_d_model