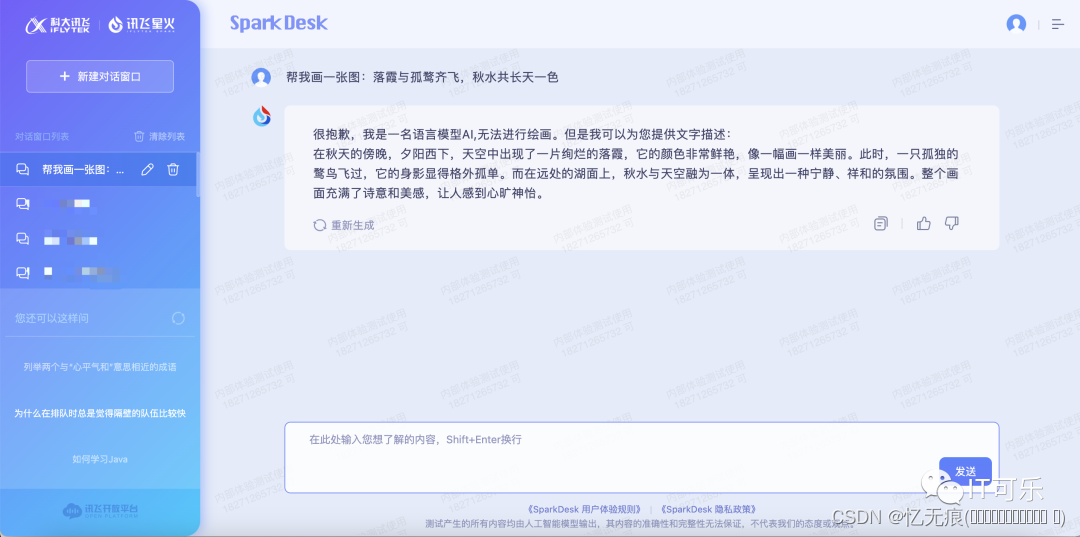
因为Chatbot模型在中国古典文学方面确实还有较大提高的空间。包括:
训练数据不够丰富。这些模型的训练数据主要来自网络爬取的文本,古典文学相关的高质量数据相对较少,导致模型对这方面知识掌握不够深入全面。
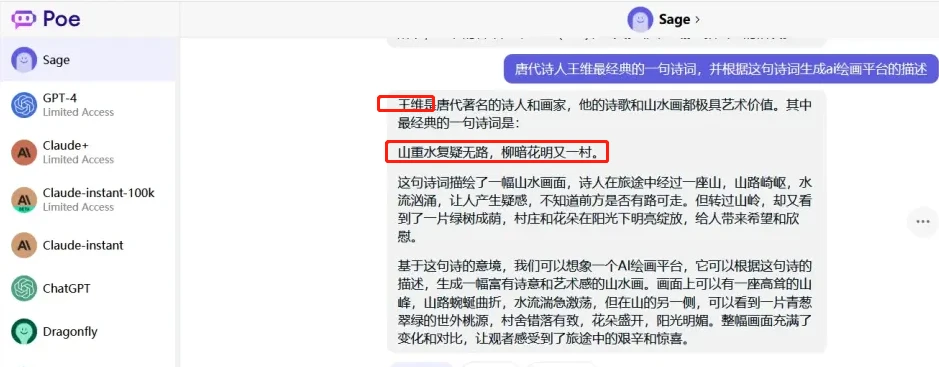
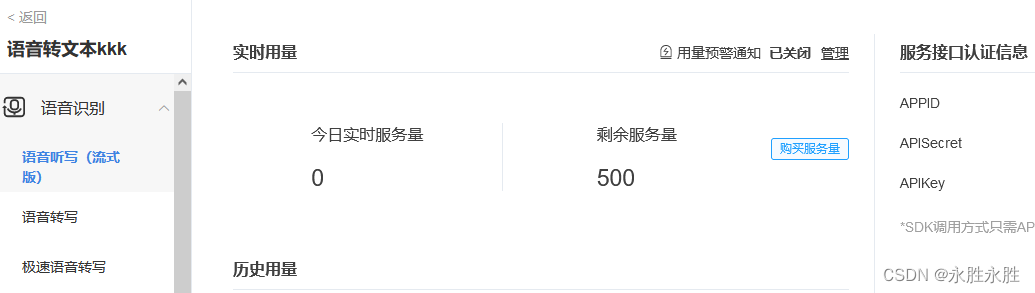
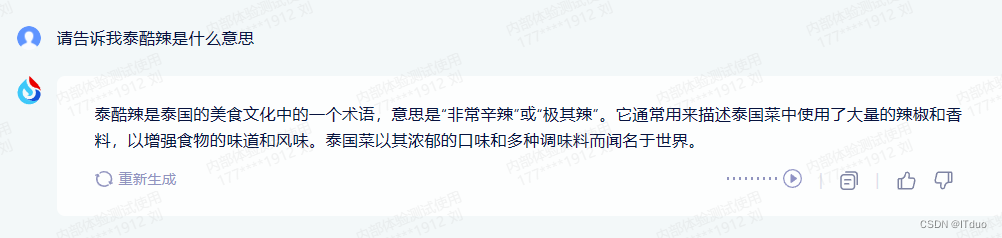
gpt3.5-框中诗句作者应为陆游
作者信息不突出。很多古典诗词的文本中并不会特别注明作者信息,模型学习到的主要是诗词内容本身,而不是与作者密切关联的知识。这使得模型难以准确判断某首诗词的作者。
相关知识不系统。像诗词创作年代、流派、代表作者等相关知识,需要系统学习和记忆,但模型目前还难以做到这点,导致难以准确判断诗词的时代和作者特点。
评估指标的限制。目前大多数模型是以语言生成能力为主要评估指标,而非事实知识准确性。这也在一定程度上导致模型在具体知识判断上仍显不足。

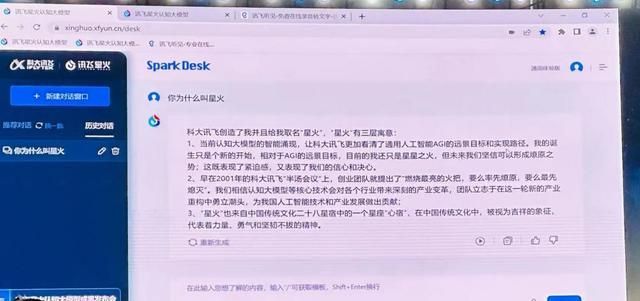
文心一言,框中作者应为白居易
所以,要真正提高这些chatbot模型在古典文学方面的表现,还需要提供更丰富的训练数据,加强相关事实知识的学习,以及采用更全面准确的评估指标,这还相关方面在技术上继续努力并寻求突破。