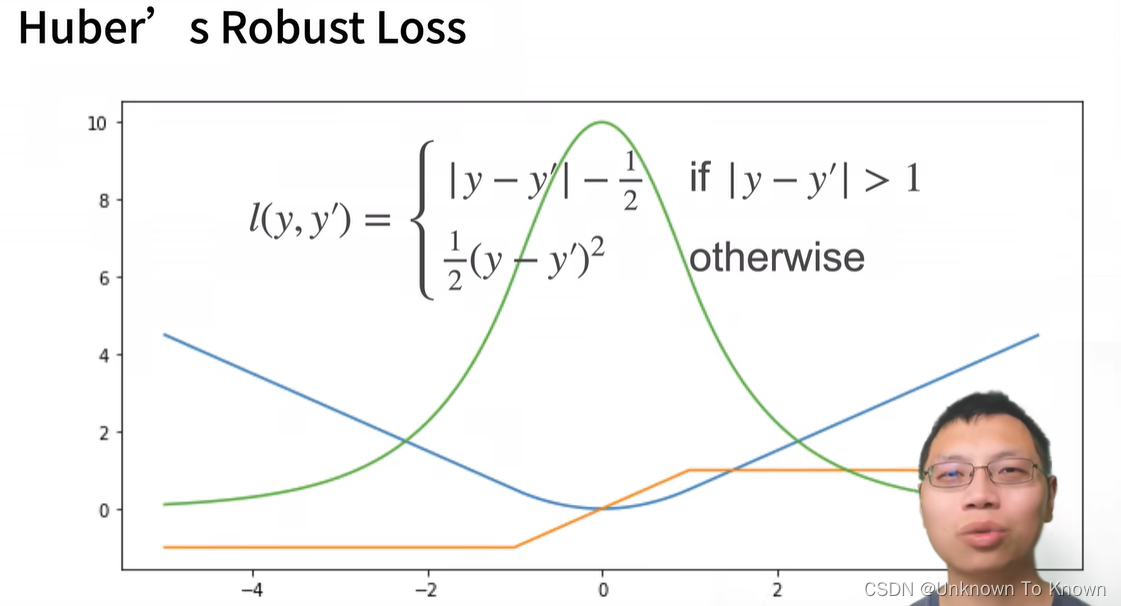
代码较为简单,算法结构如下:
from scipy.io import loadmat
import numpy as np
import os
from sklearn import preprocessing # 0-1编码
import torch
from torch.utils import data as da# 用训练集标准差标准化训练集以及测试集
def scalar_stand(data_x):scalar = preprocessing.StandardScaler().fit(data_x)data_x = scalar.transform(data_x)return data_x# one-hot编码
# def one_hot(data_y):
# data_y = np.array(data_y).reshape([-1, 1])
# encoder = preprocessing.OneHotEncoder()
# encoder.fit(data_y)
# data_y = encoder.transform(data_y).toarray()
# data_y = np.asarray(data_y, dtype=np.int32)
# return data_y# 构建文件读取函数capture,返回原始数据和标签数据
def capture(original_path): # 读取mat文件,返回一个属性的字典filenames = os.listdir(original_path) # 得到负载文件夹下面的10个文件名Data_DE = {}Data_FE = {}for i in filenames: # 遍历10个文件数据# 文件路径file_path = os.path.join(original_path, i) # 选定一个数据文件的路径file = loadmat(file_path) # 字典file_keys = file.keys() # 字典的所有key值for key in file_keys:if 'DE' in key: # 只获取DEData_DE[i] = file[key].ravel() # 将数据拉成一维数组if 'FE' in key: # 只获取DEData_FE[i] = file[key].ravel() # 将数据拉成一维数组return Data_DE, Data_FE# 划分训练样点集和测试样点集
def spilt(data, rate): # [[N1],[N2],...,[N10]]keys = data.keys() # 10个文件名tra_data = []te_data = []val_data = []for i in keys: # 遍历所有文件夹slice_data = data[i] # 选取1个文件中的数据# slice_data = scalar_stand(slice_data)all_length = len(slice_data) # 文件中的数据长度# print('数据总数为', all_length)tra_data.append(slice_data[0:int(all_length * rate[0])])# print("训练样本点数", len(tra_data))val_data.append((slice_data[int(all_length * rate[0]):int(all_length * (rate[0]+rate[1]))]))te_data.append(slice_data[int(all_length * (rate[0]+rate[1])):])# print("测试样本点数", len(te_data))return tra_data, val_data, te_datadef sampling(data_DE, data_FE, step, sample_len):sample_DE = []sample_FE = []label = []lab = 0for i in range(len(data_DE)): # 遍历10个文件all_length = len(data_DE[i]) # 文件中的数据长度# print('采样的训练数据总数为', all_length)number_sample = int((all_length - sample_len)/step + 1) # 样本数# print("number=", number_sample)for j in range(number_sample): # 逐个采样sample_DE.append(data_DE[i][j * step: j * step + sample_len])sample_FE.append(data_FE[i][j * step: j * step + sample_len])label.append(lab)j += 1lab = lab + 1sample = np.stack((np.array(sample_DE), np.array(sample_FE)), axis=2)return sample, labeldef get_data(path, rate, step, sample_len):data_DE, data_FE = capture(path) # 读取数据train_data_DE, val_data_DE, test_data_DE = spilt(data_DE, rate) # 列表[N1,N2,N10]train_data_FE, val_data_FE, test_data_FE = spilt(data_FE, rate)x_train, y_train = sampling(train_data_DE, train_data_FE, step, sample_len)# y_train = F.one_hot(torch.Tensor(y_train).long(), num_classes=10)x_validate, y_validate = sampling(val_data_DE, val_data_FE, step, sample_len)x_test, y_test = sampling(test_data_DE, test_data_FE, step, sample_len)return x_train, y_train, x_validate, y_validate, x_test, y_testclass Dataset(da.Dataset):def __init__(self, X, y):self.Data = Xself.Label = ydef __getitem__(self, index):txt = self.Data[index]label = self.Label[index]return txt, labeldef __len__(self):return len(self.Data)if __name__ == "__main__":path = r'data\5HP'rate = [0.7, 0.15, 0.15]step = 210sample_len = 420x_train, y_train, x_validate, y_validate, x_test, y_test = get_data(path, rate, step, sample_len)print(x_train.shape) # (5267, 420, 2)print(x_validate.shape) # (1117, 420, 2)print(x_test.shape) # (1117, 420, 2)# sample = tf.data.Dataset.from_tensor_slices((x_train, y_train)) # 按照样本数进行切片得到每一片的表述(400,2)# sample = sample.shuffle(1000).batch(10) # 打乱分批量(10,400,2)# sample_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))# sample_test = sample_test.shuffle(1000).batch(10) # 打乱分批量(10,400,2)Train = Dataset(torch.from_numpy(x_train).permute(0, 2, 1), y_train)Test = Dataset(torch.from_numpy(x_test).permute(0, 2, 1), y_test)train_loader = da.DataLoader(Train, batch_size=10, shuffle=True)test_loader = da.DataLoader(Test, batch_size=10, shuffle=False)工学博士,担任《Mechanical System and Signal Processing》《中国电机工程学报》《控制与决策》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。