目录
- 引言
- 上下文无关文法 CFG: Context-Free Grammar
- 定义
- 推导方法
- 最左推导和最右推导
- 分析树
- 分析树->抽象语法树
- 常见的上下文无关文法
- 文法设计
- 二义性文法
- 扩展巴科斯范式:EBNF extended Backus Normal Form
- 文法和语言分类
- 相关术语
- 直接推导
- +推导
- *推导
- 句型、句子、语言
- 短语、简单短语、句柄
- 正则文法
- DFA->正则文法
- 正则文法->DFA
- DFA->正则表达式
- 正则文法->正则表达式
- 正则表达式->正则文法
- 自顶向下分析方法(LL分析算法) top-down parsing
- 回溯分析方法backtracking parser
- 预测分析方法 predictive paeser
- 递归下降分析 recursive-descent parsing
- LL(1)分析法 ll(1) parsing (重点)
- First集合,Follow集合 (重点)
- 自底向上分析方法(LR分析算法)bottom-up parsing
引言
语法分析器的作用:token序列->分析树、抽象语法树
语法错误可能有:
- 关键字、标识符拼写错误,如intege
- 语法结构出错,少分号,begin/end不匹配
- 静态语义错误:类型不一致、参数不匹配,如需要传入double却传入了char
- 动态语义错误:无穷递归(这就是为什么有的编译器会报错whille(t){}里没有t–,即使你在块里写了它也找不到,因为它只看一开始有没有,很傻)、0作除数
处理目标:
- 正确报告错误以及地点(有一些明明是x行错误,却报y行错误)
- 迅速恢复(要么一直找,直到找到想要的记号,这样比较愚蠢;要么替换纠正,容易改不对,引发更多报错)
- 不影响源程序的分析速度
词法分析可以合并到文法当中
上下文无关文法 CFG: Context-Free Grammar
文法是对语言结构的定义和描述。即从形式上用于表述和规定语言的结构称为“文法”。如:“草吃羊”在文法上正确,但语义不正确。
定义
G=(T,N,P,S)
T 是终极符号集合,可以理解为token,一般用小写、黑体表示
N是非终结符号集合,一般用大写、小写斜体表示
P是产生式或文法规则A->a集合,其中A是非终结符,a是(TUN)*,如<句子>-><主语><宾语>
S是唯一的开始符号,是非终结符
另外,小写希腊字符表示文法符号串(可为空)
暂时没有自动生成上下文无关文法的工具,必须手动写
推导方法
给定文法G,从G的开始符号S开始推导,不断用相应规则的右部来替代规则的左部,每次仅用一条规则去推导,直到所有的非终结符都被终结符号替代为止。
依据上述过程,最终的串称为句子,所有句子的集合称为语言。定义如下: L ( G ) = { s ∣ S = > ∗ s } L(G)=\{s|S=>*s\} L(G)={s∣S=>∗s},其中,推出符号*表示经过0或多步推导出。
最左推导和最右推导
有若干语法成分同时存在时,总是从最左的语法成分进行推导,这称之为最左推导。(同理可以定义最右推导)
例:
文法:
exp->exp op exp|(exp)|**number**
op->+|-|\*
需要分析的字符串:(34-3)*42
推导过程:
exp=>exp op exp
=>exp op number
=>exp * number
=> (exp)*number
=>(exp op exp)*number
=>(exp op number)*number
=>(exp - number) * number
=>(number - number ) * number
上例是最右推导,最左推导如下:
(1) exp => exp op exp [exp -> exp op exp]
(2) => (exp) op exp [exp -> (exp)]
(3) => (exp op exp) op exp [exp -> exp op exp]
(4) => (number op exp) op exp [exp -> number]
(5) => (number - exp) op exp [ op -> - ]
(6) => (number - number) op exp [exp -> number]
(7) => (number - number) * exp [ op -> *]
(8) => (number - number) * number [exp -> number]
上下文无关文法举例:
- 文法G:E->(E)|a, 文法定义的语言是:L(G)={a,(a),((a)),…}={ ( n a ) n ∣ (^na)^n| (na)n∣n是>=0的整数}
- G:E->E+a|a,文法定义的语言是:L(G)={a,a+a,a+a+a,…}
- 正则式:a+,文法是G:A->Aa|a或者A->aA|a,语言是L(G)={ a n a^n an,n是>=1的整数}
- 正则式:a*,文法是G:A->Aa|ε或者A->aA|ε,语言是L(G)={ a n a^n an,n是>=0的整数}
- 文法G:E->(E) ,语言是L(G)={},没有终结符,没有句子,无限递归
分析树
以上例为例,
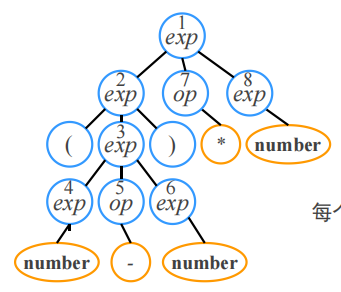
看序号可知是最左推导,与前序编号对应
下面是最右推导,与后序遍历对应
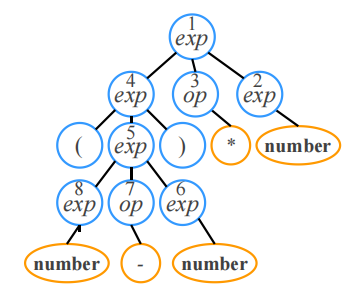
①父节点和子结点之间构成了一条文法规则
②叶节点都是终结符号,内部结点都是非终结符号
每个分析树只有唯一的一个最左推导和一个最右推导
分析树->抽象语法树

分析树复杂,但信息丰富,而抽象语法树简洁、抽象,用于语义分析
常见的上下文无关文法
- 算数表达式
exp->exp op exp|(exp)|**number**
op->+|-|\*
- if-else
下面这个文法,有重叠的部分,比较低效
G: statement -> if-stmt | other
if-stmt -> if ( exp ) statement |if ( exp ) statement else statement
exp -> 0 | 1
下面这个文法是有歧义的文法
G: statement -> if-stmt | other
if-stmt -> if ( exp ) statement else-part
else-part -> else statement | ε
exp -> 0 | 1
- 括号匹配文法
G: A ->(A)A|ε
- 带分号的文法
这个文法是错的,他的缺点是最后一个语句没有结束的分号
stmt-sequence -> stmt ; stmt-sequence | stmt
stmt -> s
下面这个文法可以,但是会推导出空语句:L(G’)= {ε, s;, s;s;, s;s;s;,…}
stmt-sequence -> stmt ; stmt-sequence | stmt | ε
stmt -> s
下面这个也是
stmt-sequence -> stmt-other1 stmt-other2
stmt-other1 -> stmt | ε
stmt-other2 -> ;stmt stmt-other2 | ;
stmt -> s
文法设计
二义性文法
可生成两个不同分析树的串的文法叫二义性文法。
如34-3*42的分析树与语法树可以有两种。
算术表达式文法存在二义性的根源是什么?有2条规则都能往下推导,没有考虑优先级。
消除二义性的方法:
1.不修改文法,指定正确的分析树(只需手动修改生成的代码)LL分析表有冲突时选择其中一条
2.修改文法,会改得很乱
1.算术表达式修改文法,确定乘法优先级于加法;
exp -> exp addop exp | term
addop -> + | -
term -> term mulop term| factor
mulop -> *
factor -> (exp) | number
在此基础上,确定乘法和加法都是左结合的
exp -> exp addop term | term
addop -> + | -
term -> term mulop factor | factor
mulop -> *
factor -> (exp) | number
下面这个文法的缺陷是,输入者必须输入带括号的表达式
exp factor op factor | factor
factor (exp) | number
op + | – | *
2.if-else,悬挂的else问题在这里插入代码片
最近嵌套规则用于解决悬挂else问题
statement matched-stmt | unmatched-stmt
matched-stmt if ( exp ) matched-stmt else matched-stmt | other
unmatched-stmt if ( exp ) statement | if ( exp ) matched-stmt else unmatched-stmt
exp 0 | 1
下面的文法是强制if加上end
if-stmt -> if condition then statement-sequence end if |if condition then statement-sequence else statement-sequence end if
3.无关紧要的二义性文法:分号结尾的语句
stmt-sequence -> stmt-sequence ; stmt-sequence | stmt
stmt -> s
扩展巴科斯范式:EBNF extended Backus Normal Form
{}表示重复

用[]表示可选,比如:
G: statement if-stmt | other
if-stmt if ( exp ) statement [ else statement ]
exp 0 | 1
文法和语言分类
0型、1型、2型、3型(乔姆斯基层次)
| - | 产生式 | 左部范围 | 右部范围 | 左部 | 右部 | 备注 |
|---|---|---|---|---|---|---|
| 0型 | u->v | (TUN)+ | (TUN)* | >=1 | >=0 | 可计算枚举语言,短语结构文法 |
| 1型 | xUy->xuy | (TUN)+ | (TUN)* | >=1 | >=0 | 上下文相关文法 |
| 2型 | U->v | N | (TUN)* | =1 | >=0 | 上下文无关文法 |
| 3型 | U->t,U->Wt | N | TUN | =1 | <=2 | 正则文法、线性文法 |
越往高级,限制越多,高级的语言符合低级
(左线性) P:U -> t 或 U -> Wt 其中 U、W∈N t∈T
(右线性) P:U -> t 或 U -> tW 其中 U、W∈N t∈T
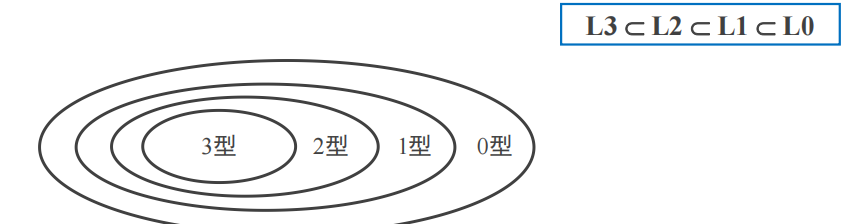
这一分类的研究意义在于模型的可解释性,但是它的描述能力较弱
相关术语
直接推导

+推导

等于说是通过一步或多步推导出来的
*推导

通过0步或多步推导
句型、句子、语言
文法G = (T, N, P, S),S =>* a ,
如果a是(TUN)*,那么a是句型 (存在非终结符号。即分析树的剖面);
如果a是T*,那么a是句子(全部是终结符号,也就是叶子节点)(句子属于句型)
文法G产生的语言是L(G[S]) = {a | S =>* a ,a ∈ T* }
短语、简单短语、句柄
G = (T, N, P, S),w = xuy ∈ (TUN)* 为文法的句型
若:S => xUy ,且 U =>+ u,则u是句型w相对于U的短语(子树)
若:S => xUy, 且 U => u,则u是句型w相对于U 的简单短语;
U是非终结符,u是一步或多步的TUN,xy都是0步或多步的TUN
任一句型的最左简单短语称为该句型的句柄。
例子:

黄色是剖面(句型)

可以发现,这种话的说法就是“u是句型xx相对于U的短语”,其中句型是固定的,因为这是题里给的,u是黄色的结点,U是他们规约以后蓝色的结点

简单短语也就是一步可以得出的,最左的简单短语是句柄
正则文法
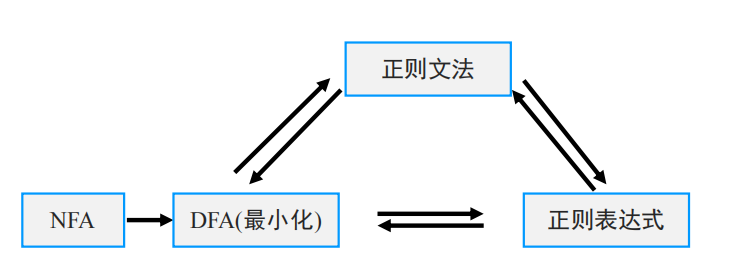
DFA->正则文法

例子:
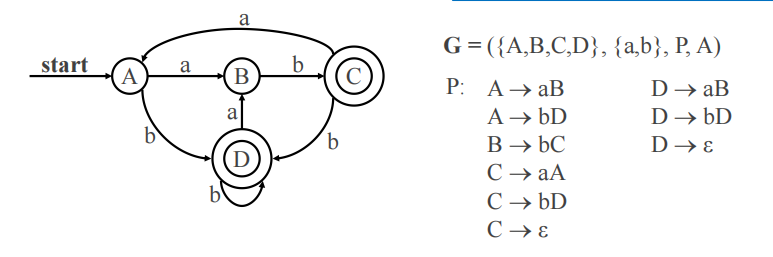
普通的转移直接把吃进的字符和到达的状态连起来当右部,出发点当左部;可接收的状态再加一条可以推出epsilon
正则文法->DFA

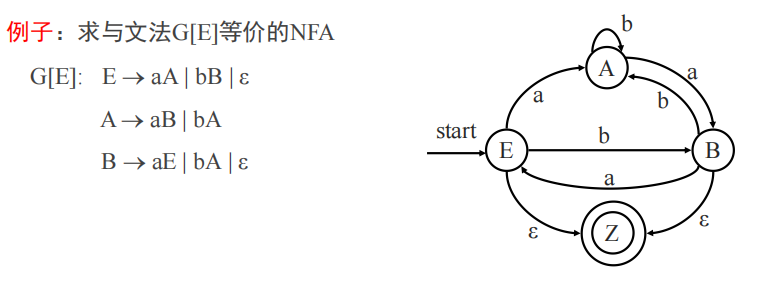
先按反过程画出来DFA,画完所有的以后加一个终态Z,把那些可以推出epsilon的状态都指向Z,把那些直接推出终结符的语句,也指向Z
DFA->正则表达式
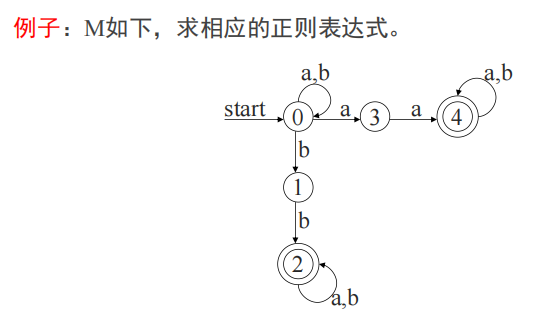
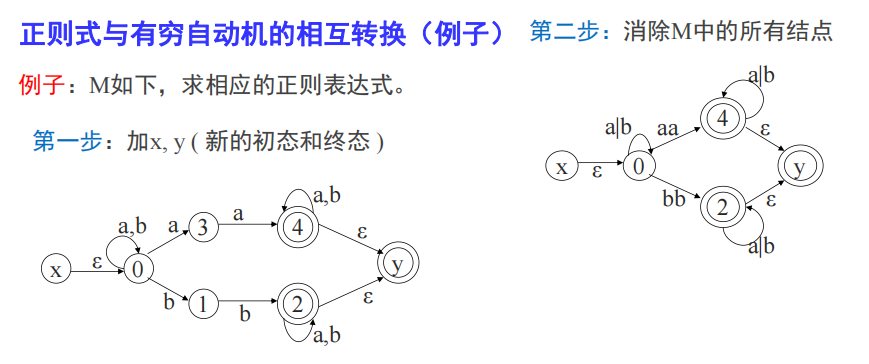
将词法分析的流程反向做一遍
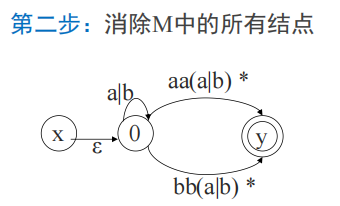
r = ( a ∣ b ) ∗ ( a a ∣ b b ) ( a ∣ b ) ∗ r = (a|b)*(aa|bb)(a|b)* r=(a∣b)∗(aa∣bb)(a∣b)∗
正则文法->正则表达式
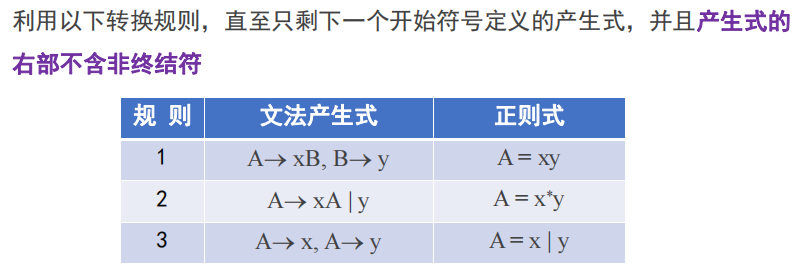
递归即闭包

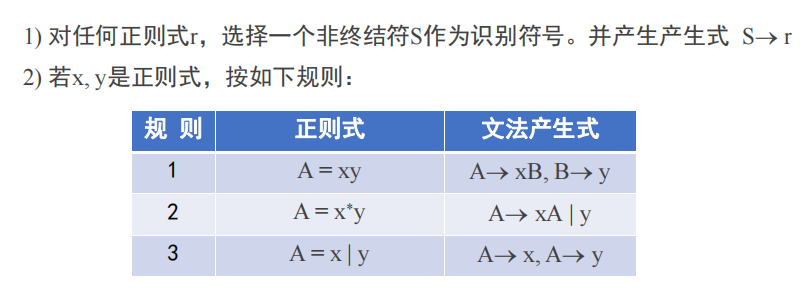
正则表达式->正则文法
上表反过来
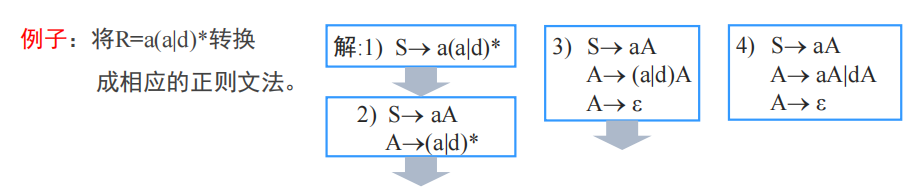
自顶向下分析方法(LL分析算法) top-down parsing
从文法G的开始符号S开始推导得出句子t,遍历所有t,如果t==给定的句子s,那么s可以由G推导出来。
回溯分析方法backtracking parser
思想就是往下推导,如果不匹配就回溯,效率非常低,不聪明。没人用。
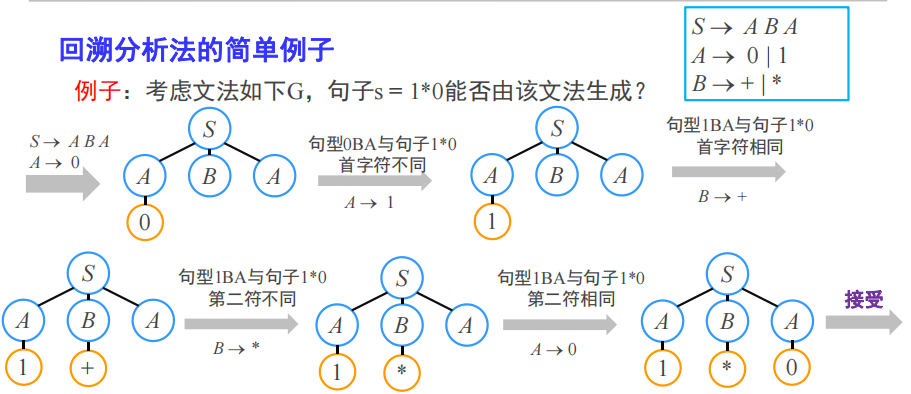
tokens[ ]; /* 词法分析得到的单词列表 */
int i = 0;
stack = [S]; /* 栈内放文法的开始符号 */
while ( stack != [] )if (stack[top] 是终结符号 t )if ( t == tokens[i] ) { i++; pop(); }else { backtrack( ) }else if (stack[top] 非终结符号 T )pop( ); push( 关于非终结符号T的下一条规则的右部 )
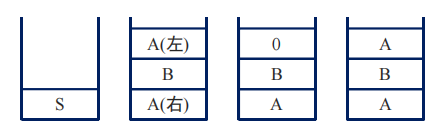

压栈的时候,是从右往左压,一旦栈顶是终结符就去匹配:不匹配就回溯,匹配就消掉