Python学习从0开始——Kaggle时间序列002
- 一、作为特征的时间序列
- 1.串行依赖
- 周期
- 2.滞后序列和滞后图
- 滞后图
- 选择滞后
- 3.示例
- 二、混合模型
- 1.介绍
- 2.组件和残差
- 3.残差混合预测
- 4.设计混合模型
- 5.使用
- 三、使用机器学习进行预测
- 1.定义预测任务
- 2.为预测准备数据
- 3.多步骤预测策略
- 3.1 Multioutput模型
- 3.2 直接策略
- 3.3 递归策略
- 3.4 DirRec策略
- 4.使用
- 4.1 Multioutput模型
- 4.2 直接策略
一、作为特征的时间序列
1.串行依赖
在001研究了最容易建模为时间相关属性的时间序列的属性,也就是说,我们可以直接从时间索引中得出特征。然而,有些时间序列属性只能作为序列相关属性建模,也就是说,使用目标序列过去的值作为特征。随着时间的推移,这些时间序列的结构可能并不明显:然而,对比过去的值,结构就变得清晰了——如下图所示:
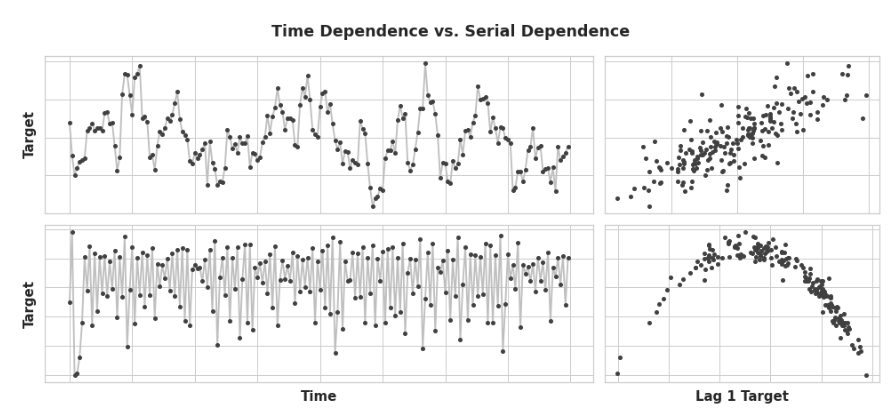
有了趋势和季节性,我们训练模型来拟合曲线,就像上图左边的图一样——模型是学习时间依赖性的。之后的目标是训练模型将曲线拟合到右边的图中——我们希望它们学习序列依赖。
周期
序列依赖的一种特别常见的表现形式是周期。周期是时间序列中增长和衰退的模式,与序列中某一时间的值如何依赖于之前时间的值有关,但不一定与时间步长本身有关。周期行为是那些能够影响自身或其反应随时间持续存在的系统的特征。经济、流行病、动物种群、火山爆发以及类似的自然现象通常表现出周期行为。
周期性行为与季节性行为的区别在于,周期不一定像季节那样依赖于时间。在一个周期中发生的事情与发生的特定日期关系不大,更多的是与最近发生的事情有关。与时间的(至少是相对的)独立性意味着周期性行为可能比季节性更不规律。
2.滞后序列和滞后图
为了研究时间序列中可能的序列依赖性(如周期),我们需要创建该序列的“滞后”副本。滞后时间序列意味着将其值向前移动一个或多个时间步,或者等价地,将其索引中的时间向后移动一个或多个时间步。在任何一种情况下,其结果都是滞后序列中的观测似乎发生在较晚的时间。这显示了美国的月度失业率(y)及其第一和第二滞后系列(分别为y_lag_1和y_lag_2)。注意滞后序列的值是如何在时间上向前移动的:
import pandas as pdreserve = pd.read_csv("../input/ts-course-data/reserve.csv",parse_dates={'Date': ['Year', 'Month', 'Day']},index_col='Date',
)y = reserve.loc[:, 'Unemployment Rate'].dropna().to_period('M')
df = pd.DataFrame({'y': y,'y_lag_1': y.shift(1),'y_lag_2': y.shift(2),
})df.head()
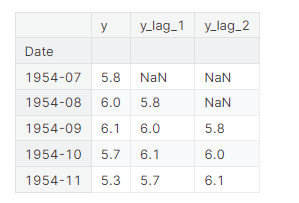
通过延迟时间序列,我们可以使其过去的值与我们试图预测的值同时出现(换句话说,在同一行)。这使得滞后序列作为建模序列依赖的有用特征。为了预测美国失业率序列,我们可以使用y_lag_1和y_lag_2作为特征来预测目标y。这将预测未来的失业率作为前两个月失业率的函数。
滞后图
时间序列的滞后图显示了它的值与滞后的关系。通过观察滞后图,时间序列中的序列依赖性通常会变得很明显。我们可以从美国失业率的滞后图中看到,当前失业率和过去的失业率之间存在着强烈而明显的线性关系。
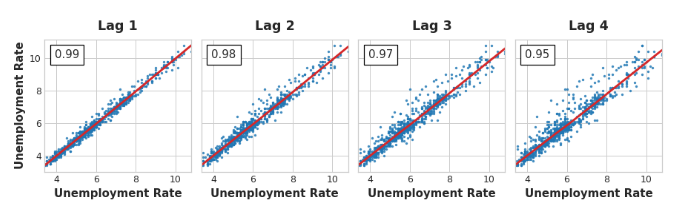
序列相关性最常用的度量方法是自相关,它是时间序列与其滞后之一的相关性。美国失业率在滞后1时的自相关性为0.99,滞后2时为0.98,以此类推。
选择滞后
当选择滞后作为特征使用时,通常没有必要将每个具有较大自相关性的滞后都包含在内。例如,在美国失业率中,滞后2的自相关可能完全来自滞后1的“衰减”信息——只是从前一步延续下来的相关性。如果滞后2不包含任何新内容,那么如果我们已经有了滞后1,就没有理由包含新内容。
部分自相关告诉你滞后与所有先前滞后之间的相关性——也就是说,滞后所贡献的“新”相关性的数量。绘制部分自相关可以帮助您选择要使用的滞后特征。在下面的图中,滞后1到滞后6超出了“不相关”的区间(蓝色),所以我们可以选择滞后1到滞后6作为美国失业率的特征。(滞后11很可能是误报。)

像上面这样的图被称为相关图。滞后特征的相关图本质上就像傅里叶特征的周期图一样。最后,我们需要注意,自相关和部分自相关是线性依赖的度量。
由于现实世界的时间序列通常具有大量的非线性依赖关系,因此在选择滞后特征时,最好查看滞后图(或使用一些更一般的依赖性度量,如互信息)。太阳黑子序列具有非线性依赖的滞后,我们可以用自相关来忽略它。
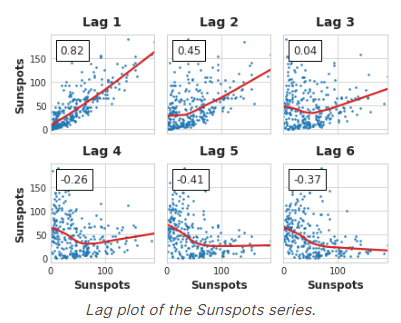
像这样的非线性关系可以转换成线性关系,或者通过适当的算法学习。
3.示例
使用flu数据集,我们将采取两种方法。首先,使用滞后特征来预测医生的就诊情况。然后利用另一组时间序列的滞后来预测医生的就诊情况。
from pathlib import Path
from warnings import simplefilterimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from scipy.signal import periodogram
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from statsmodels.graphics.tsaplots import plot_pacfsimplefilter("ignore")# 设置Matplotlib默认值
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 4))
plt.rc("axes",labelweight="bold",labelsize="large",titleweight="bold",titlesize=16,titlepad=10,
)
plot_params = dict(color="0.75",style=".-",markeredgecolor="0.25",markerfacecolor="0.25",
)
%config InlineBackend.figure_format = 'retina'def lagplot(x, y=None, lag=1, standardize=False, ax=None, **kwargs):from matplotlib.offsetbox import AnchoredTextx_ = x.shift(lag)if standardize:x_ = (x_ - x_.mean()) / x_.std()if y is not None:y_ = (y - y.mean()) / y.std() if standardize else yelse:y_ = xcorr = y_.corr(x_)if ax is None:fig, ax = plt.subplots()scatter_kws = dict(alpha=0.75,s=3,)line_kws = dict(color='C3', )ax = sns.regplot(x=x_,y=y_,scatter_kws=scatter_kws,line_kws=line_kws,lowess=True,ax=ax,**kwargs)at = AnchoredText(f"{corr:.2f}",prop=dict(size="large"),frameon=True,loc="upper left",)at.patch.set_boxstyle("square, pad=0.0")ax.add_artist(at)ax.set(title=f"Lag {lag}", xlabel=x_.name, ylabel=y_.name)return axdef plot_lags(x, y=None, lags=6, nrows=1, lagplot_kwargs={}, **kwargs):import mathkwargs.setdefault('nrows', nrows)kwargs.setdefault('ncols', math.ceil(lags / nrows))kwargs.setdefault('figsize', (kwargs['ncols'] * 2, nrows * 2 + 0.5))fig, axs = plt.subplots(sharex=True, sharey=True, squeeze=False, **kwargs)for ax, k in zip(fig.get_axes(), range(kwargs['nrows'] * kwargs['ncols'])):if k + 1 <= lags:ax = lagplot(x, y, lag=k + 1, ax=ax, **lagplot_kwargs)ax.set_title(f"Lag {k + 1}", fontdict=dict(fontsize=14))ax.set(xlabel="", ylabel="")else:ax.axis('off')plt.setp(axs[-1, :], xlabel=x.name)plt.setp(axs[:, 0], ylabel=y.name if y is not None else x.name)fig.tight_layout(w_pad=0.1, h_pad=0.1)return figdata_dir = Path("../input/ts-course-data")
flu_trends = pd.read_csv(data_dir / "flu-trends.csv")
flu_trends.set_index(pd.PeriodIndex(flu_trends.Week, freq="W"),inplace=True,
)
flu_trends.drop("Week", axis=1, inplace=True)ax = flu_trends.FluVisits.plot(title='Flu Trends', **plot_params)
_ = ax.set(ylabel="Office Visits")
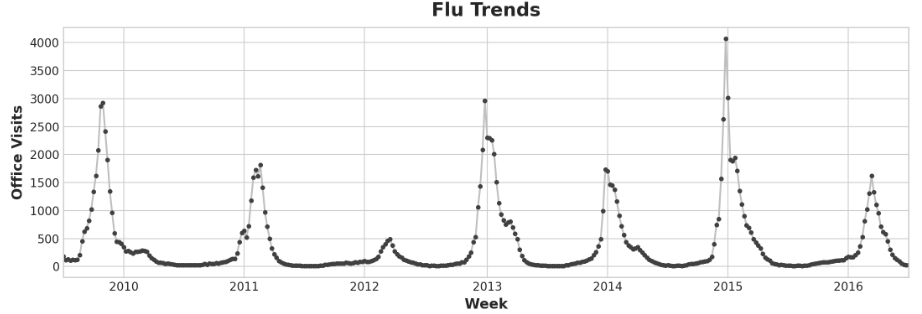
我们的流感趋势数据显示了不规则的周期,而不是正常的季节性:高峰往往发生在新年前后,但有时早或晚,有时大或小。用滞后特征对这些周期进行建模,将使我们的预报员能够对不断变化的条件做出动态反应,而不是像季节性特征那样受到精确日期和时间的限制。
滞后图和自相关图:
_ = plot_lags(flu_trends.FluVisits, lags=12, nrows=2)
_ = plot_pacf(flu_trends.FluVisits, lags=12)
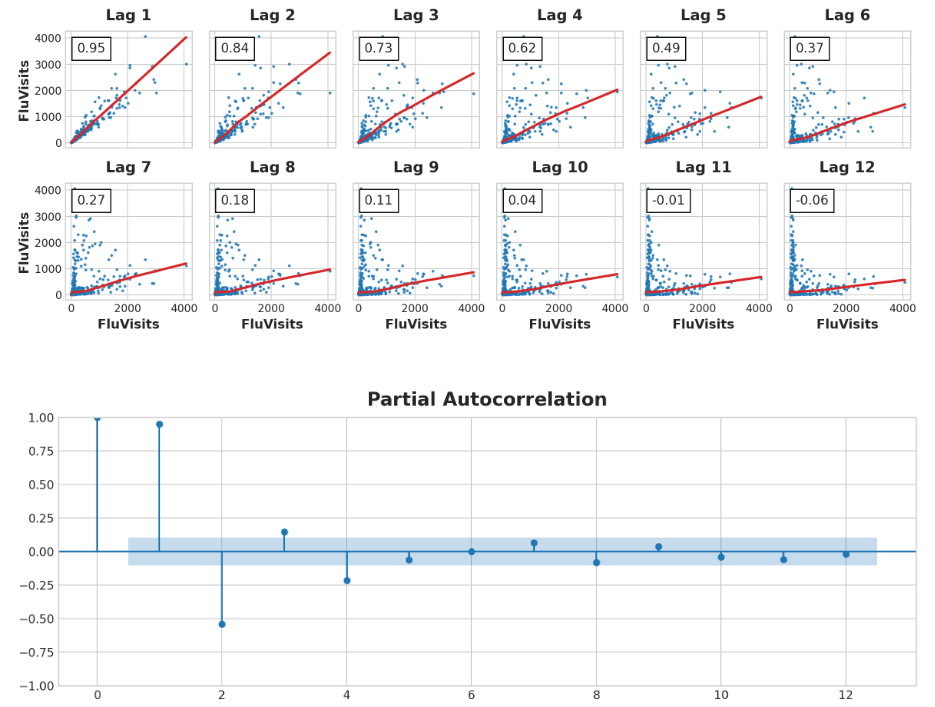
滞后图表明fluvisitors与其滞后的关系主要是线性的,而部分自相关性表明可以使用滞后1、2、3和4来捕获相关性。我们可以用shift方法在Pandas中滞后一个时间序列。对于这个问题,我们将用0.0填充滞后创建的缺失值。
def make_lags(ts, lags):return pd.concat({f'y_lag_{i}': ts.shift(i)for i in range(1, lags + 1)},axis=1)X = make_lags(flu_trends.FluVisits, lags=4)
X = X.fillna(0.0)
在之前的内容中,我们能够在训练数据之外为尽可能多的步骤创建预测。然而,当使用滞后特征时,我们仅限于预测其滞后值可用的时间步长。使用星期一的滞后1特征,我们无法预测星期三的情况,因为需要的滞后1值是星期二,而星期二还没有发生。因此我们将使用测试集的值:
# 创建目标序列和数据分割
y = flu_trends.FluVisits.copy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=60, shuffle=False)# 拟合和预测
model = LinearRegression() # `fit_intercept=True` 因为我们没有使用DeterministicProcess
model.fit(X_train, y_train)
y_pred = pd.Series(model.predict(X_train), index=y_train.index)
y_fore = pd.Series(model.predict(X_test), index=y_test.index)ax = y_train.plot(**plot_params)
ax = y_test.plot(**plot_params)
ax = y_pred.plot(ax=ax)
_ = y_fore.plot(ax=ax, color='C3')
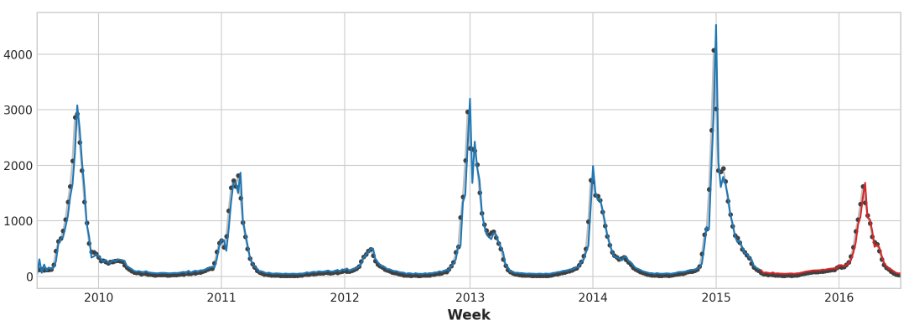
看看预测值,我们可以看到我们的模型如何需要一个时间步长来对目标序列中的突然变化做出反应。这是仅使用目标序列的滞后作为特征的模型的常见限制。
ax = y_test.plot(**plot_params)
_ = y_fore.plot(ax=ax, color='C3')
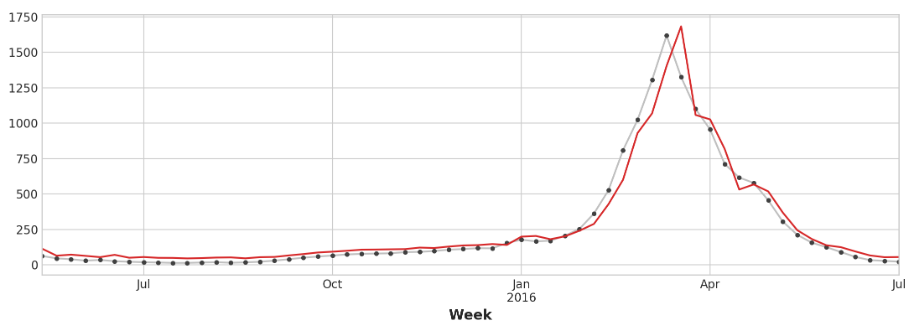
为了改善预测,我们可以尝试找到领先指标,时间序列,可以为流感病例的变化提供“早期预警”。对于我们的第二种方法,我们将在训练数据中添加一些由谷歌趋势测量的流感相关搜索词的流行度。
将搜索词“fluough”与目标词“flusearches”进行对比表明,这类搜索词可能是有用的先行指标:流感相关搜索往往在就诊前几周变得更多。
ax = flu_trends.plot(y=["FluCough", "FluVisits"],secondary_y="FluCough",
)
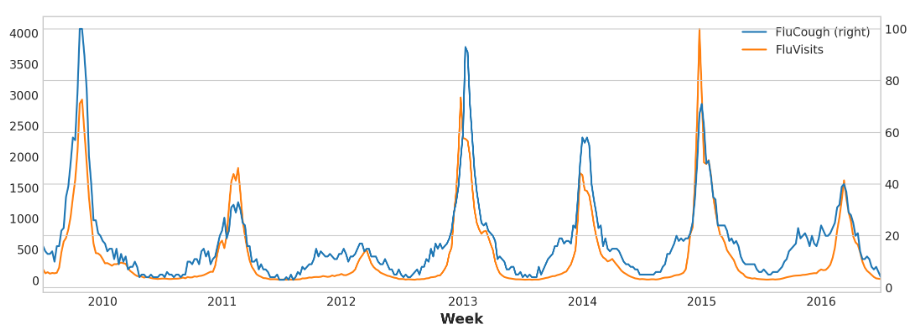
search_terms = ["FluContagious", "FluCough", "FluFever", "InfluenzaA", "TreatFlu", "IHaveTheFlu", "OverTheCounterFlu", "HowLongFlu"]# 为每个搜索词创建三个滞后
X0 = make_lags(flu_trends[search_terms], lags=3)
X0.columns = [' '.join(col).strip() for col in X0.columns.values]# 为目标创建四个滞后
X1 = make_lags(flu_trends['FluVisits'], lags=4)# 组合起来创建训练数据
X = pd.concat([X0, X1], axis=1).fillna(0.0)
我们的预测有点粗糙,但我们的模型似乎能够更好地预测流感访问量的突然增加,这表明搜索流行度的几个时间序列确实是有效的领先指标:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=60, shuffle=False)model = LinearRegression()
model.fit(X_train, y_train)
y_pred = pd.Series(model.predict(X_train), index=y_train.index)
y_fore = pd.Series(model.predict(X_test), index=y_test.index)ax = y_test.plot(**plot_params)
_ = y_fore.plot(ax=ax, color='C3')
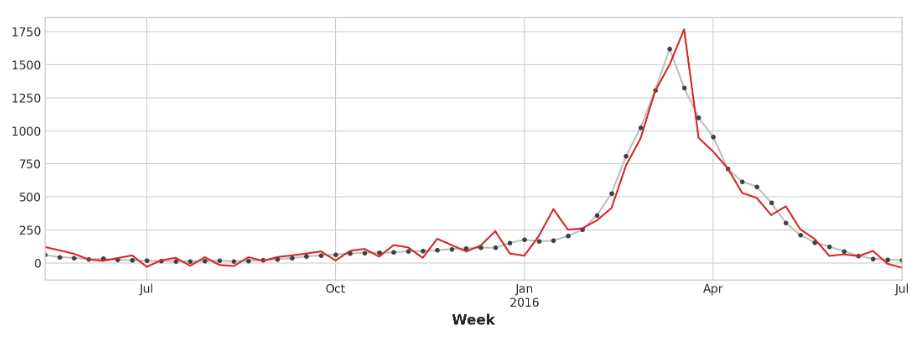
本节的时间序列可以称为“纯周期性”:它们没有明显的趋势或季节性。然而,时间序列同时拥有趋势、季节性和周期这三种成分的情况并不罕见。只需为每个组件添加适当的特征,就可以用线性回归对这样的序列进行建模。
二、混合模型
1.介绍
线性回归擅长推断趋势,但无法了解相互作用。XGBoost擅长学习互动,但不能推断趋势。接下来将学习如何创建“混合”预测器,将互补的学习算法结合起来,让一种算法的优点弥补另一种算法的缺点。
2.组件和残差
为了设计有效的混合模型,我们需要更好地理解时间序列是如何构建的。到目前为止,我们研究了三种依赖模式:趋势、季节性和周期性。许多时间序列可以通过仅包含这三个组件的加性模型以及一些本质上不可预测、完全随机的误差来密切描述:
series = trend + seasons + cycles + error
我们把这个模型中的每一项称为时间序列的一个组件。
模型的残差是模型训练的目标与模型预测值之间的差异——即实际曲线与拟合曲线之间的差异。将残差与某个特征进行绘图,你会得到目标中“剩余”的部分,或者模型从该特征中未能学习到的关于目标的信息。
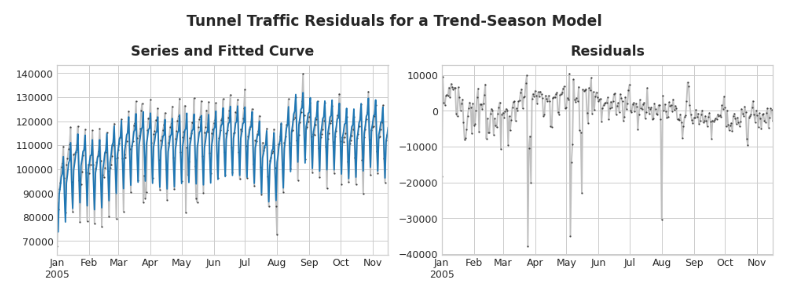
在上面的图左侧,是隧道交通量序列的一部分以及趋势-季节性曲线。通过减去拟合曲线,我们得到了右侧的残差。这些残差包含了隧道交通量中趋势-季节性模型没有学习到的所有内容。
我们可以将学习时间序列的组件想象为一个迭代过程:首先学习趋势并从序列中减去它,然后从去趋势的残差中学习季节性并减去季节性,接着学习周期性并减去周期性,最后只剩下不可预测的误差。
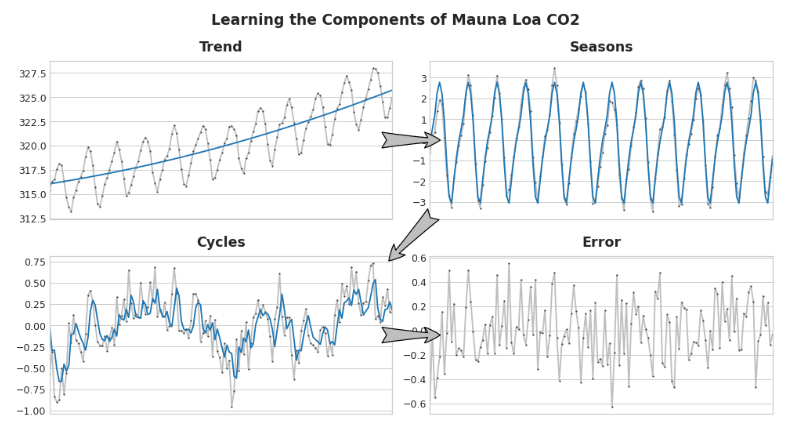
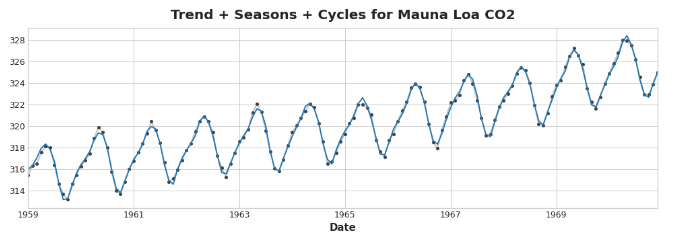
把我们学过的所有组成部分加在一起,我们就得到了完整的模型。如果你将线性回归训练在一组完整的特征上,对趋势、季节和周期进行建模,这基本上就是线性回归要做的事情。
3.残差混合预测
在之前的内容中,我们使用单一算法(线性回归)一次学习所有组件。但如果对某些组件使用一种算法,对其余部分使用另一种算法,这样我们就可以为每个组件选择最好的算法。为了做到这一点,我们使用一种算法来拟合原始序列,然后使用第二种算法来拟合残差序列。
# 1. 用第一个模型进行训练和预测
model_1.fit(X_train_1, y_train)
y_pred_1 = model_1.predict(X_train)# 2. 用第二种模型对残差进行训练和预测
model_2.fit(X_train_2, y_train - y_pred_1)
y_pred_2 = model_2.predict(X_train_2)# 3. 添加以获得总体预测
y_pred = y_pred_1 + y_pred_2
我们通常想要使用不同的特征集(X_train_1和X_train_2),这取决于我们想要每个模型学习什么。例如,如果我们使用第一个模型来学习趋势,我们通常不需要第二个模型的趋势特征。虽然可以使用两个以上的模型,但在实践中似乎并不是特别有用。
事实上,构建混合模型最常见的策略就是我们刚刚描述的:一个简单的(通常是线性的)学习算法,然后是一个复杂的、非线性的学习算法,比如gbdt或深度神经网络,这个简单的模型通常被设计成后面强大算法的“助手”。
4.设计混合模型
除了上述的方法外,还有很多种将机器学习模型组合起来的方式。然而,要成功地将模型组合起来,我们需要更深入地了解这些算法是如何运作的。
回归算法通常通过两种方式来进行预测:一种是转换特征,另一种是转换目标。特征转换算法学习某种数学函数,该函数以特征作为输入,然后结合并转换这些特征以产生与训练集中的目标值相匹配的输出。线性回归和神经网络就属于这种类型。
目标转换算法使用特征对训练集中的目标值进行分组,并通过计算组内的平均值来进行预测;一组特征只是指示要平均的组。决策树和最近邻算法就属于这种类型。
重要的是:特征转换器通常可以在给定适当的特征作为输入时,对训练集之外的目标值进行外推,但目标转换器的预测结果始终会受限于训练集的范围。如果时间哑变量继续计数时间步长,线性回归就会继续绘制趋势线。给定相同的时间哑变量,决策树将永远预测训练数据最后一步所指示的趋势到未来。决策树无法外推趋势。随机森林和梯度提升决策树(如XGBoost)是决策树的集合,因此它们也无法外推趋势。
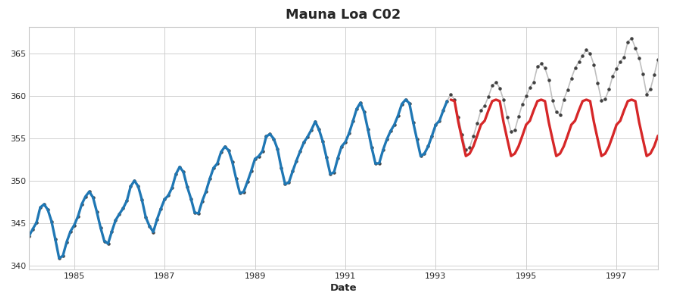
这种差异是促使混合设计的原因:使用线性回归来外推趋势,转换目标以去除趋势,然后将XGBoost应用于去趋势后的残差。要将神经网络(一个特征转换器)混合化,你可以将另一个模型的预测作为特征纳入其中,神经网络随后会将其作为自身预测的一部分。拟合残差的方法实际上是梯度提升算法使用的方法,因此我们将其称为增强型混合;将预测用作特征的方法称为“堆叠”,因此我们将这些称为堆叠型混合。
5.使用
使用US Retail Sales数据集,除了创建线性回归+ XGBoost的混合体之外,我们还将看到如何设置用于XGBoost的时间序列数据集。
基本设置:
from pathlib import Path
from warnings import simplefilterimport matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from statsmodels.tsa.deterministic import CalendarFourier, DeterministicProcess
from xgboost import XGBRegressorsimplefilter("ignore")# 设置Matplotlib默认值
plt.style.use("seaborn-whitegrid")
plt.rc("figure",autolayout=True,figsize=(11, 4),titlesize=18,titleweight='bold',
)
plt.rc("axes",labelweight="bold",labelsize="large",titleweight="bold",titlesize=16,titlepad=10,
)
plot_params = dict(color="0.75",style=".-",markeredgecolor="0.25",markerfacecolor="0.25",
)data_dir = Path("../input/ts-course-data/")
industries = ["BuildingMaterials", "FoodAndBeverage"]
retail = pd.read_csv(data_dir / "us-retail-sales.csv",usecols=['Month'] + industries,parse_dates=['Month'],index_col='Month',
).to_period('D').reindex(columns=industries)
retail = pd.concat({'Sales': retail}, names=[None, 'Industries'], axis=1)retail.head()

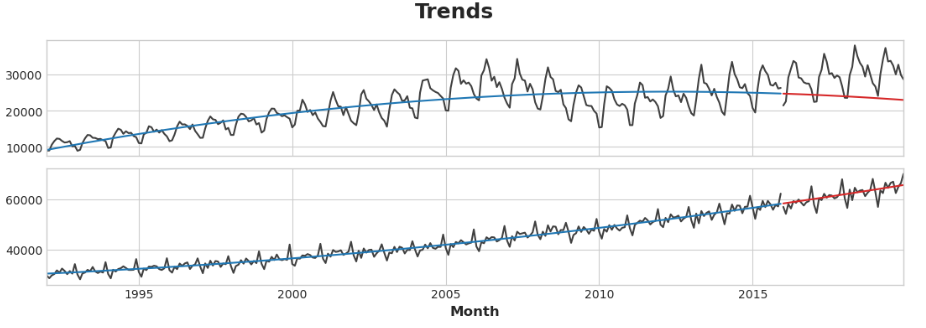
首先,让我们使用线性回归模型来了解每个系列的趋势:
y = retail.copy()# 创建趋势特征
dp = DeterministicProcess(index=y.index, # 来自训练数据的日期constant=True, # 拦截order=2, # 二次趋向drop=True, # 省略项以避免共线性
)
X = dp.in_sample() # 训练数据的特征# 测试2016-2019年。如果我们拆分日期索引,而不是直接拆分数据框,稍后会更容易。
idx_train, idx_test = train_test_split(y.index, test_size=12 * 4, shuffle=False,
)
X_train, X_test = X.loc[idx_train, :], X.loc[idx_test, :]
y_train, y_test = y.loc[idx_train], y.loc[idx_test]# 拟合趋势模型
model = LinearRegression(fit_intercept=False)
model.fit(X_train, y_train)# 做出预测
y_fit = pd.DataFrame(model.predict(X_train),index=y_train.index,columns=y_train.columns,
)
y_pred = pd.DataFrame(model.predict(X_test),index=y_test.index,columns=y_test.columns,
)# 绘制
axs = y_train.plot(color='0.25', subplots=True, sharex=True)
axs = y_test.plot(color='0.25', subplots=True, sharex=True, ax=axs)
axs = y_fit.plot(color='C0', subplots=True, sharex=True, ax=axs)
axs = y_pred.plot(color='C3', subplots=True, sharex=True, ax=axs)
for ax in axs: ax.legend([])
_ = plt.suptitle("Trends")
线性回归算法能够进行多输出回归,而XGBoost算法则不能。为了使用XGBoost一次预测多个序列,我们将把这些序列从宽格式(每列一个时间序列)转换为长格式(按类别按行索引):
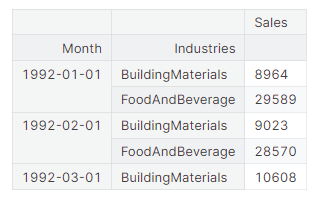
# ' stack '方法将列标签转换为行标签,从宽格式转向长格式
X = retail.stack() # 从宽到长透视数据集
display(X.head())
y = X.pop('Sales') # 抓取目标序列
因此,XGBoost可以学习区分我们的两个时间序列,我们将把“Industries”的行标签转换为带有标签编码的分类特征。我们还将通过从时间指数中提取月份数字来创建一个年度季节性特性:
# 使用标签编码将行标签转换为分类特征列
X = X.reset_index('Industries')
# “Industries”特性的标签编码
for colname in X.select_dtypes(["object", "category"]):X[colname], _ = X[colname].factorize()# 每年季节性的标签编码
X["Month"] = X.index.month # values are 1, 2, ..., 12# 创建分割
X_train, X_test = X.loc[idx_train, :], X.loc[idx_test, :]
y_train, y_test = y.loc[idx_train], y.loc[idx_test]
现在我们将把之前的趋势预测转换成长格式,然后从原始序列中减去它们。这将给我们提供XGBoost可以学习的去趋势(残差)序列:
# 从宽转向长(堆栈)并将数据帧转换为系列(挤压)
y_fit = y_fit.stack().squeeze() # 训练集趋势
y_pred = y_pred.stack().squeeze() # 来自测试集的趋势# 从训练集创建残差(去趋势序列的集合)
y_resid = y_train - y_fit# 训练XGBoost的残余
xgb = XGBRegressor()
xgb.fit(X_train, y_resid)# 将预测的残差添加到预测的趋势上
y_fit_boosted = xgb.predict(X_train) + y_fit
y_pred_boosted = xgb.predict(X_test) + y_pred
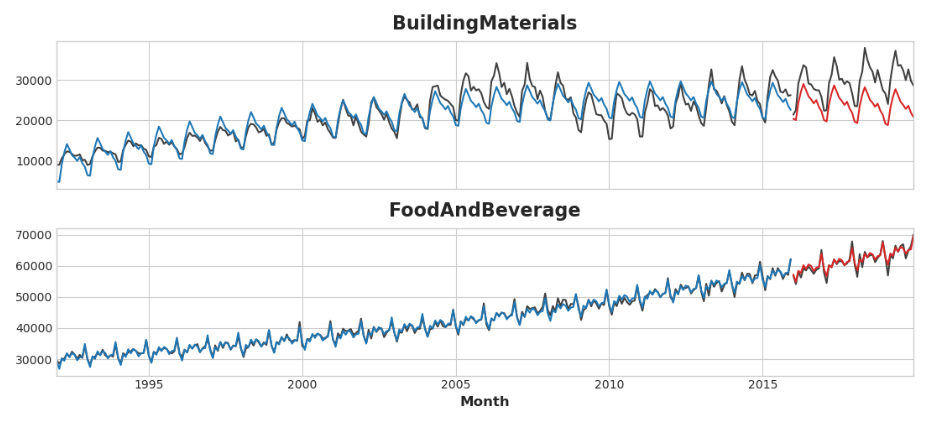
拟合看起来相当好,尽管我们可以看到XGBoost学习的趋势如何仅与线性回归学习的趋势一样好-特别是,XGBoost无法补偿’BuildingMaterials’系列中的不良拟合趋势:
axs = y_train.unstack(['Industries']).plot(color='0.25', figsize=(11, 5), subplots=True, sharex=True,title=['BuildingMaterials', 'FoodAndBeverage'],
)
axs = y_test.unstack(['Industries']).plot(color='0.25', subplots=True, sharex=True, ax=axs,
)
axs = y_fit_boosted.unstack(['Industries']).plot(color='C0', subplots=True, sharex=True, ax=axs,
)
axs = y_pred_boosted.unstack(['Industries']).plot(color='C3', subplots=True, sharex=True, ax=axs,
)
for ax in axs: ax.legend([])
三、使用机器学习进行预测
我们将预测视为一个简单的回归问题时,所有的特征都来自于一个单一的输入,即时间指数。我们可以很容易地通过生成我们想要的趋势和季节特征来预测未来的任何时间。然而,当我们添加延迟特性时,问题的性质发生了变化。滞后特征要求滞后的目标值在预测时是已知的。滞后特征使时间序列向前移动1步,这意味着你可以预测未来1步,但不能预测未来2步。在一中,我们只是假设我们总是可以产生滞后,直到我们想要预测的时期(换句话说,每次预测都只是向前迈出一步)。现实世界的预测通常需要更多的东西,现在,我们将学习如何对各种情况进行预测。
1.定义预测任务
在设计预测模型之前,需要确定两件事:
- 进行预测时可用的信息(特征)
- 需要预测值的时间段(目标)
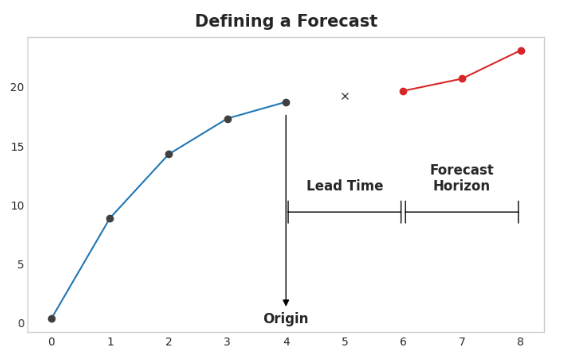
预测的原点是你进行预测的时间点。实际上,你可能将预测原点视为当前预测的最后一个时间点的训练数据。直到预测原点之前的所有数据都可以用来创建特征。
预测期限是你进行预测的时间段。我们常用预测期限中的时间步数来描述一个预测,例如“1步”预测或“5步”预测。预测期限描述了目标。
从起点到地平线之间的时间是预报的提前时间(有时是延迟时间)。预报的提前期由从起点到地平线的步数来描述:比如“提前一步”或“提前三步”预报。在实践中,由于数据采集或处理的延迟,预报可能需要在起源之前多个步骤开始。
2.为预测准备数据
要使用机器学习算法预测时间序列,我们需要将序列转换成一个数据框(DataFrame),以便与这些算法一起使用。(当然,除非你只使用确定性特征,如趋势和季节性。)
在一中,我们看到了这个过程的前半部分,即我们从滞后项中创建了一个特征集。后半部分是准备目标变量。我们如何做到这一点取决于预测任务。
在数据框中,每一行代表一个单独的预测。行的时间索引是预测期限中的第一个时间点,但我们在同一行中安排了整个期限的值。对于多步预测,这意味着我们需要模型产生多个输出,每个步骤一个输出。
import numpy as np
import pandas as pdN = 20
ts = pd.Series(np.arange(N),index=pd.period_range(start='2010', freq='A', periods=N, name='Year'),dtype=pd.Int8Dtype,
)# 滞后特性Lag features
X = pd.DataFrame({'y_lag_2': ts.shift(2),'y_lag_3': ts.shift(3),'y_lag_4': ts.shift(4),'y_lag_5': ts.shift(5),'y_lag_6': ts.shift(6),
})# 多步的目标
y = pd.DataFrame({'y_step_3': ts.shift(-2),'y_step_2': ts.shift(-1),'y_step_1': ts,
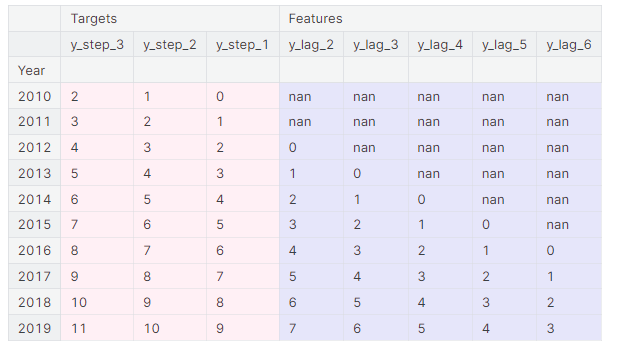
})data = pd.concat({'Targets': y, 'Features': X}, axis=1)data.head(10).style.set_properties(['Targets'], **{'background-color': 'LavenderBlush'}) \.set_properties(['Features'], **{'background-color': 'Lavender'})
上图说明了如何准备一个类似于定义预测图的数据集:一个三步预测任务,前置时间为两步,使用五个滞后特征。原始时间序列是y_step_1。我们可以填充或删除缺失的值。
3.多步骤预测策略
有许多策略可用于生成预测所需的多个目标步骤。我们将概述四种常见策略,每种策略都有优缺点。
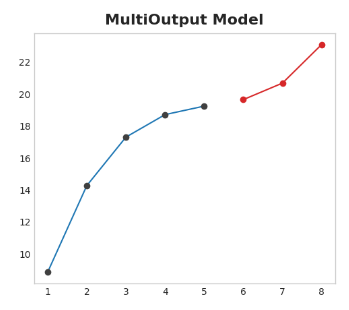
3.1 Multioutput模型
使用自然产生多个输出的模型。线性回归和神经网络都可以产生多个输出。这种策略简单而有效,但并非适用于你可能想要使用的每种算法。例如,XGBoost就不能做到这一点。
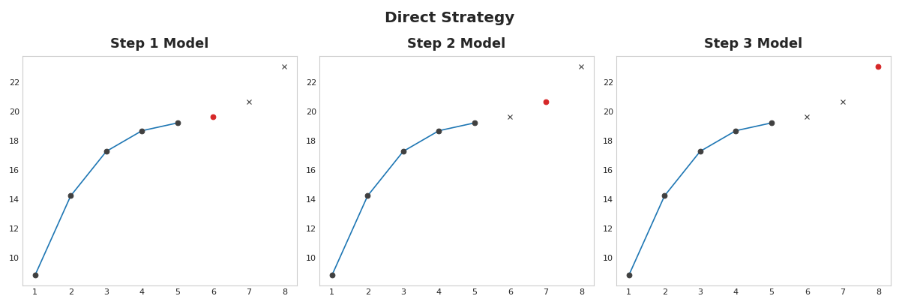
3.2 直接策略
为视界中的每一步训练一个单独的模型:一个模型预测提前一步,另一个预测提前两步,以此类推。提前一步预测和提前两步(以此类推)是不同的问题,所以用不同的模型对每一步进行预测是有帮助的。缺点是训练大量的模型在计算上很昂贵。
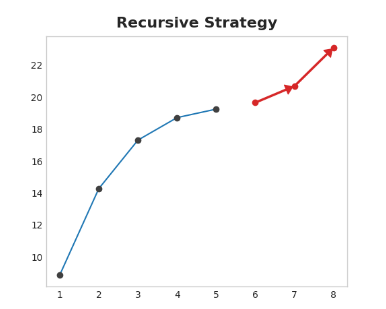
3.3 递归策略
训练一个单步模型,并使用它的预测来更新下一个步骤的滞后特征。使用递归方法,我们将模型的1步预测反馈到相同的模型中,作为下一个预测步骤的滞后特征。我们只需要训练一个模型,但由于误差会一步一步地传播,所以长期预测可能是不准确的。
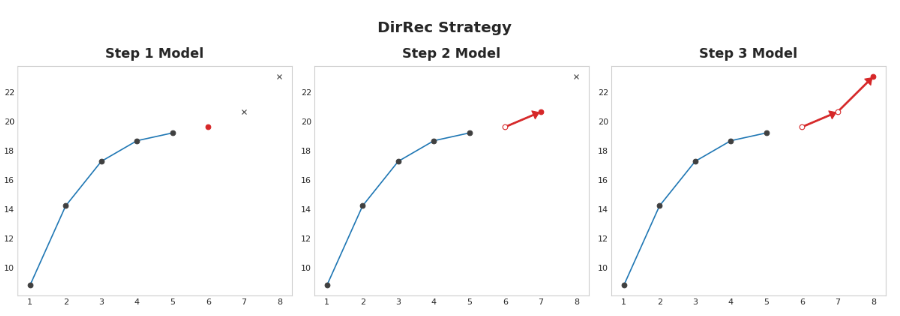
3.4 DirRec策略
直接和递归策略的结合:为每一步训练一个模型,并使用前一步的预测作为新的滞后特征。每一步,每个模型都会得到一个额外的滞后输入。由于每个模型总是有一组最新的滞后特征,因此DirRec策略可以比Direct更好地捕获串行依赖性,但它也可能像递归一样受到错误传播的影响。
4.使用
在本例中,我们将把MultiOutput和Direct策略应用于一的流感趋势数据,这一次,我们将对超过训练期的数周进行真实的预测。我们将预测任务定义为8周的周期和1周的提前期。换句话说,我们将预测从下周开始的八周流感病例。
基础设置:
from pathlib import Path
from warnings import simplefilterimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressorsimplefilter("ignore")# 设置Matplotlib默认值
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True, figsize=(11, 4))
plt.rc("axes",labelweight="bold",labelsize="large",titleweight="bold",titlesize=16,titlepad=10,
)
plot_params = dict(color="0.75",style=".-",markeredgecolor="0.25",markerfacecolor="0.25",
)
%config InlineBackend.figure_format = 'retina'def plot_multistep(y, every=1, ax=None, palette_kwargs=None):palette_kwargs_ = dict(palette='husl', n_colors=16, desat=None)if palette_kwargs is not None:palette_kwargs_.update(palette_kwargs)palette = sns.color_palette(**palette_kwargs_)if ax is None:fig, ax = plt.subplots()ax.set_prop_cycle(plt.cycler('color', palette))for date, preds in y[::every].iterrows():preds.index = pd.period_range(start=date, periods=len(preds))preds.plot(ax=ax)return axdata_dir = Path("../input/ts-course-data")
flu_trends = pd.read_csv(data_dir / "flu-trends.csv")
flu_trends.set_index(pd.PeriodIndex(flu_trends.Week, freq="W"),inplace=True,
)
flu_trends.drop("Week", axis=1, inplace=True)
首先,我们将为多步骤预测准备我们的目标系列(针对流感的每周办公室访问)。一旦完成,训练和预测将非常简单:
def make_lags(ts, lags, lead_time=1):return pd.concat({f'y_lag_{i}': ts.shift(i)for i in range(lead_time, lags + lead_time)},axis=1)# 4周的延迟功能
y = flu_trends.FluVisits.copy()
X = make_lags(y, lags=4).fillna(0.0)def make_multistep_target(ts, steps):return pd.concat({f'y_step_{i + 1}': ts.shift(-i)for i in range(steps)},axis=1)# 八周的预测
y = make_multistep_target(y, steps=8).dropna()# 移位造成了索引不匹配。只保留我们既有目标又有特征的时间
y, X = y.align(X, join='inner', axis=0)
4.1 Multioutput模型
我们将使用线性回归作为多输出策略。一旦我们为多个输出准备好了数据,训练和预测就和往常一样了。
# 创建分组
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=False)model = LinearRegression()
model.fit(X_train, y_train)y_fit = pd.DataFrame(model.predict(X_train), index=X_train.index, columns=y.columns)
y_pred = pd.DataFrame(model.predict(X_test), index=X_test.index, columns=y.columns)
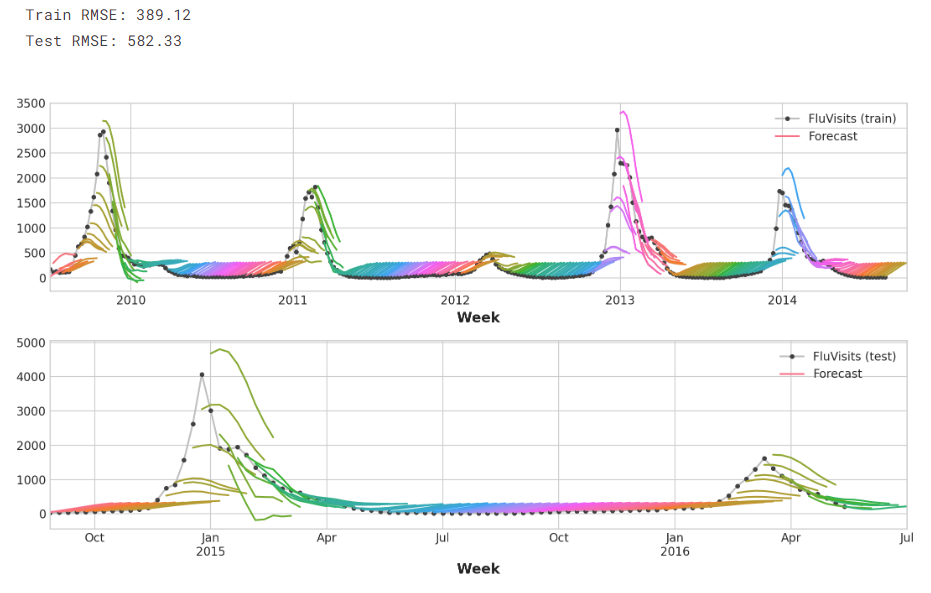
请记住,多步骤模型将为用作输入的每个实例生成完整的预测。训练集中有269周,测试集中有90周,我们现在对每一周都有一个8步预测:
train_rmse = mean_squared_error(y_train, y_fit, squared=False)
test_rmse = mean_squared_error(y_test, y_pred, squared=False)
print((f"Train RMSE: {train_rmse:.2f}\n" f"Test RMSE: {test_rmse:.2f}"))palette = dict(palette='husl', n_colors=64)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(11, 6))
ax1 = flu_trends.FluVisits[y_fit.index].plot(**plot_params, ax=ax1)
ax1 = plot_multistep(y_fit, ax=ax1, palette_kwargs=palette)
_ = ax1.legend(['FluVisits (train)', 'Forecast'])
ax2 = flu_trends.FluVisits[y_pred.index].plot(**plot_params, ax=ax2)
ax2 = plot_multistep(y_pred, ax=ax2, palette_kwargs=palette)
_ = ax2.legend(['FluVisits (test)', 'Forecast'])
4.2 直接策略
XGBoost不能为回归任务产生多个输出。但是通过应用直接约简策略,我们仍然可以用它来产生多步预测。这与使用scikit-learn的MultiOutputRegressor包装它一样简单。
from sklearn.multioutput import MultiOutputRegressormodel = MultiOutputRegressor(XGBRegressor())
model.fit(X_train, y_train)y_fit = pd.DataFrame(model.predict(X_train), index=X_train.index, columns=y.columns)
y_pred = pd.DataFrame(model.predict(X_test), index=X_test.index, columns=y.columns)
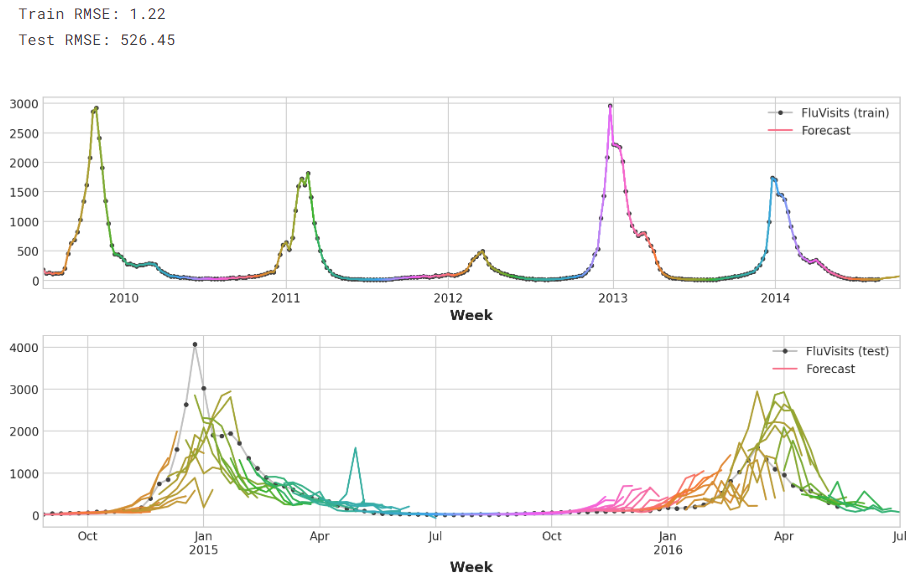
这里的XGBoost显然是训练集上的过拟合。但在测试集上,它似乎能够比线性回归模型更好地捕捉流感季节的一些动态。如果进行一些超参数调优,它可能会做得更好:
train_rmse = mean_squared_error(y_train, y_fit, squared=False)
test_rmse = mean_squared_error(y_test, y_pred, squared=False)
print((f"Train RMSE: {train_rmse:.2f}\n" f"Test RMSE: {test_rmse:.2f}"))palette = dict(palette='husl', n_colors=64)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(11, 6))
ax1 = flu_trends.FluVisits[y_fit.index].plot(**plot_params, ax=ax1)
ax1 = plot_multistep(y_fit, ax=ax1, palette_kwargs=palette)
_ = ax1.legend(['FluVisits (train)', 'Forecast'])
ax2 = flu_trends.FluVisits[y_pred.index].plot(**plot_params, ax=ax2)
ax2 = plot_multistep(y_pred, ax=ax2, palette_kwargs=palette)
_ = ax2.legend(['FluVisits (test)', 'Forecast'])
要使用DirRec策略,只需要用另一个scikit-learn包装器RegressorChain替换MultiOutputRegressor。递归策略需要我们自己编写代码。




![[linux]如何跟踪linux 内核运行的流程呢](https://img-blog.csdnimg.cn/direct/c4396f3d66e74b6e84e46fd5fe839747.png)