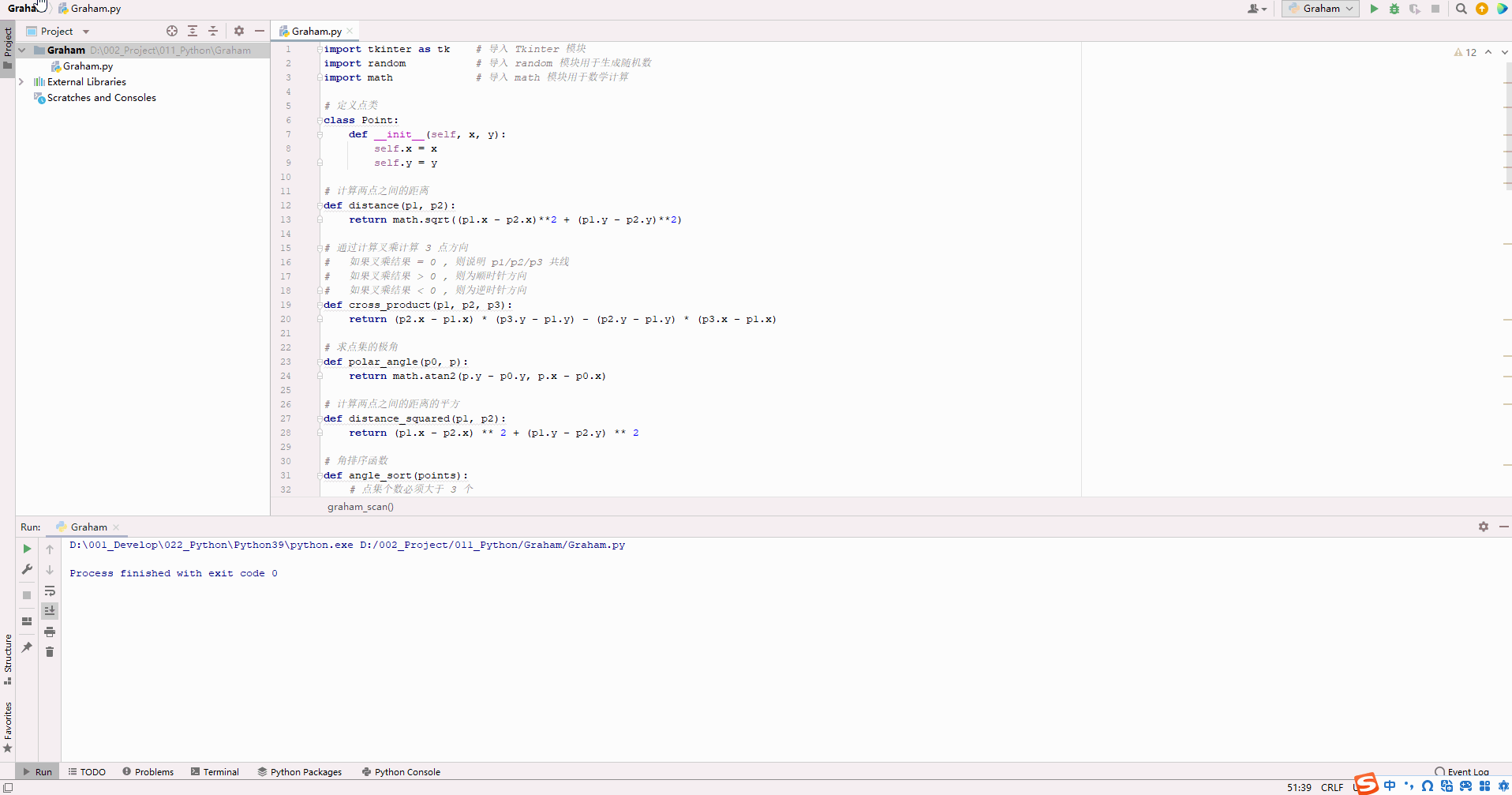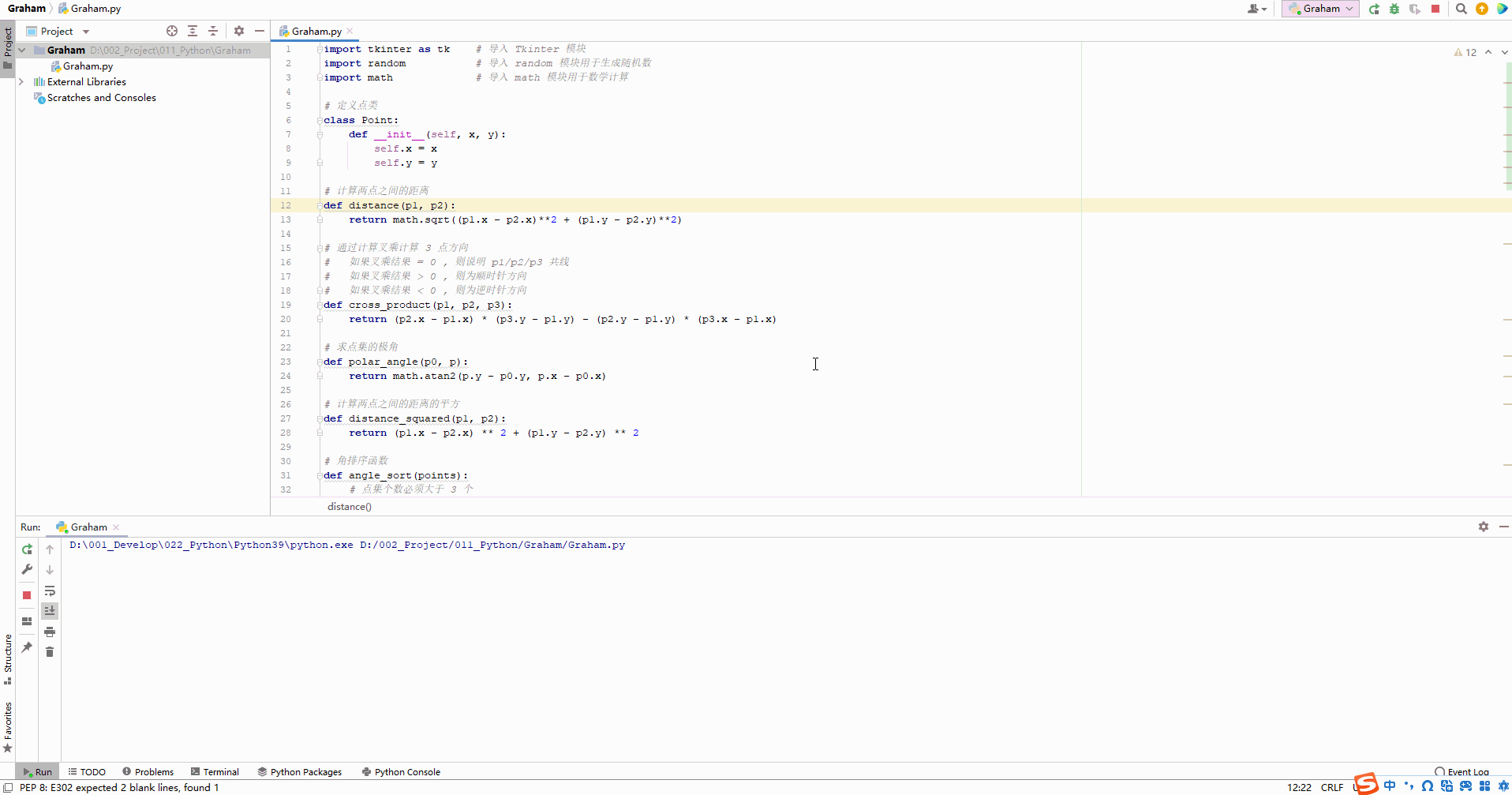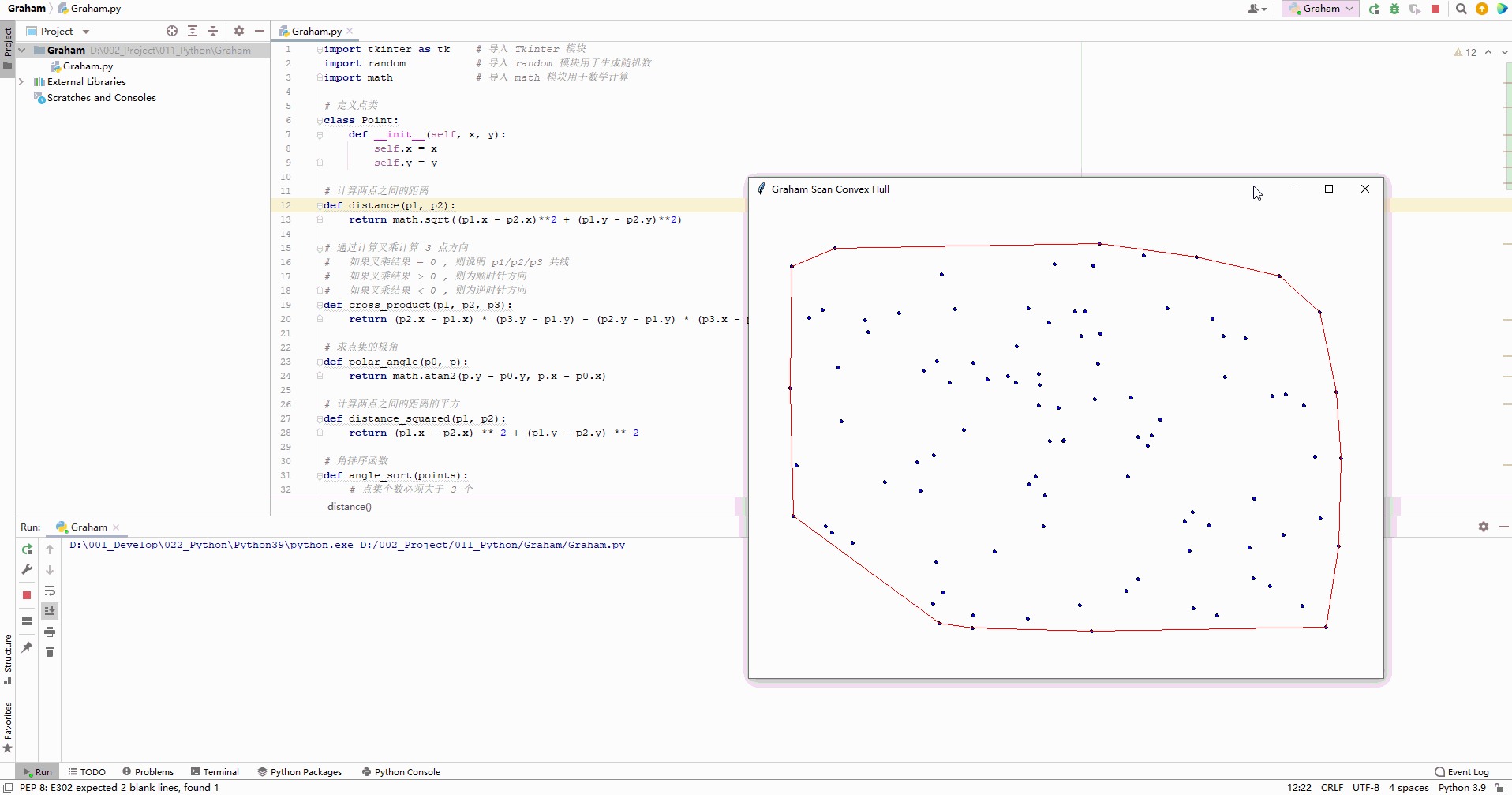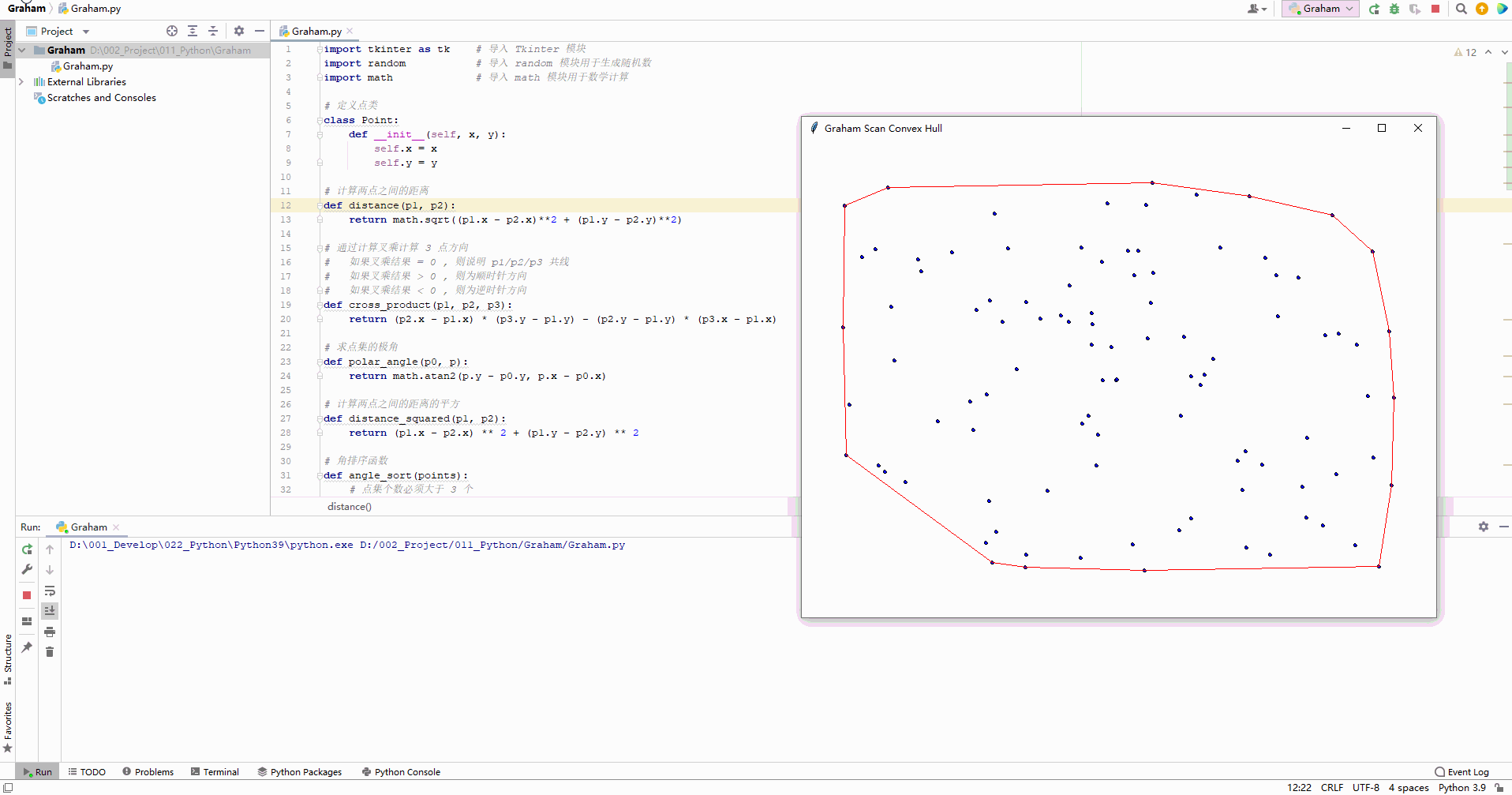
在我们的学习过程中,会阅读很多的文档,例如jdk的API文档,但是在这样的大型文档中,如果没有搜索功能,我们是很难找到我们想查阅的内容的,于是我们可以实现一个搜索引擎来帮助我们阅读文档。
1. 实现思路
1.1 获取文档
第一点,要搜索指定内容,首先要先获取到内容,我们以实现Java API文档搜索引擎来说,我们要先获取到Java的API文档,我们可以在Oracle的官网找到:Overview (Java SE 17 & JDK 17) (oracle.com)
Oracle官网提供了在线和离线两种文档,我们可以下载离线文档,通过离线文档来实现。
离线文档下载地址:Java 开发工具包 17 文档 (oracle.com)
下载好后解压缩,在 jdk-17.0.11_doc-all\docs\api 目录和子目录下的所有html文件就是所有的api文档
1.2 通过关键词查询
获取到了文档,我们还需要能够通过关键词定位到相关的文档,这里需要用到索引
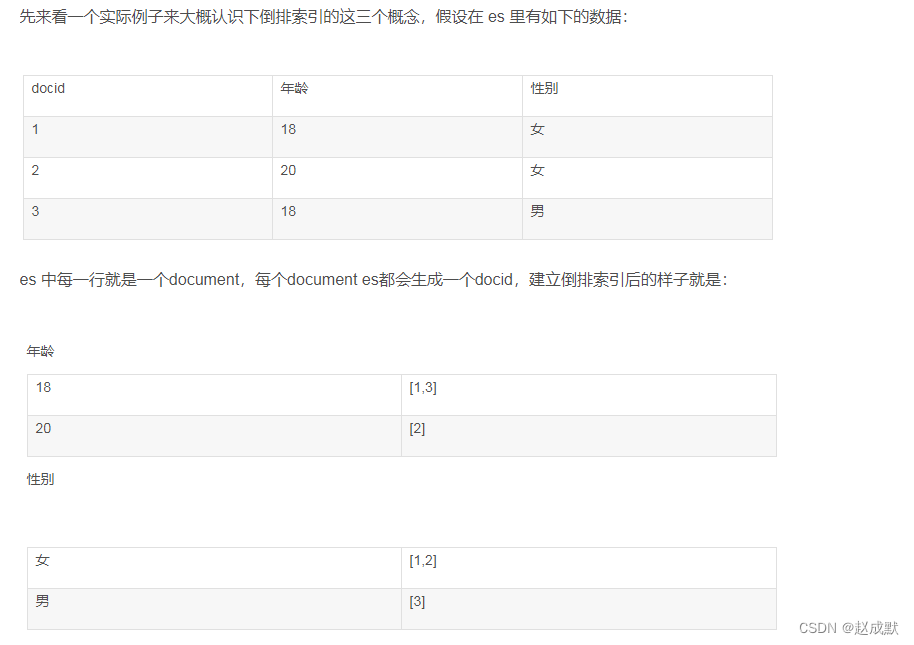
- 正排索引: 给每个文档引入一个文档id,文档id是每个文档的身份标识,不能重复,通过文档id快速获取到对应文档就叫正排索引。
- 倒排索引:通过一个或几个关键词查询到与之有关的所有文档的文档id,这种方式就叫到排索引。
于是要实现关键词查询,我们只需要给下载好的Java API文档实现一个正排索引和倒排索引,通过到排索引查询到相关的文档的id,要查看某个文档时再用查询到的id使用正排索引查询到对应文档。
1.3 如何返回查询到的结果
查询到对应的api文档之后,如何返回给用户,这里我的想法是返回一个在线文档的url,当用户想要查看某个文档时,返回Oracle官方的在线文档对应的页面的url。
那么此种方式就需要我们把在线文档的url和离线文档联系起来:
我们观察某个文档的url和在线文档的本地路径:
在线文档:

离线文档:
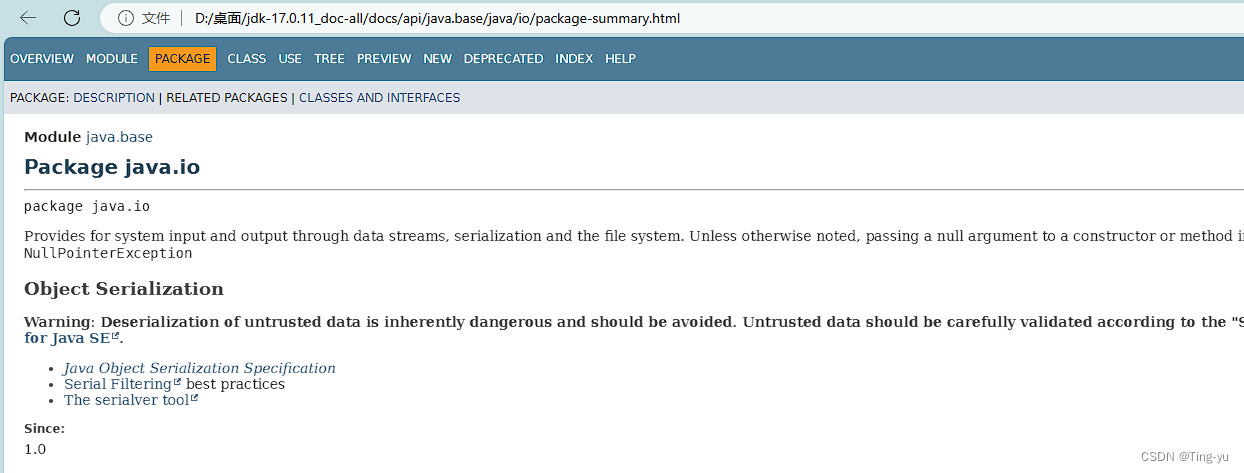

我们发现相同api文档的在线版本的url和离线版本路径,它们的后半部分是相同的,所有我们只需要通过一些字符串拼接操作,就可以通过离线文档的文件路径得到在线文档的url。
1.4 模块划分
通过上面的叙述,我们可以对我们的程序进行一个模块划分:
- 索引模块:扫描并解析所有的本地文档并构建出索引;提供一些API实现查正排/到排的功能
- 搜索模块:调用索引模块通过关键词查询到相关文档信息,并处理后返回
- Web模块:实现一个简单的Web程序,能通过网页的形式和用户交互
2. 索引模块实现
创建一个Spring项目
2.1 实现Parser类
实现一个Parser类用于扫描并解析本地的离线文档:
package org.example.docsearcher.config;@Configuration
public class Parser {//指定文档文件的路径private static final String FILE_PATH = "D:/桌面/jdk-17.0.11_doc-all/docs/api";//解析文档private void parser() {//1.找出所有html文件List<File> fileList = new ArrayList<>();enumFile(FILE_PATH, fileList);//2.对每个HTML文件进行解析for(File f : fileList) {parserHTML(f);}}//枚举出所有的html文件private void enumFile(String filePath, List<File> fileList) {}//解析出html文件的内容private void parserHTML(File file) {}
}实现enumFile方法:
private void enumFile(String filePath, List<File> fileList) {File file = new File(filePath);//获取目录下的文件列表File[] files = file.listFiles();for(File f : files) {if(f.isDirectory()) {//如果f是目录则递归添加文件enumFile(f.getAbsolutePath(), fileList);}else if(f.getName().endsWith(".html")){//如果f是html文件则添加到fileList中fileList.add(f);}}}实现parserHTML方法:
要实现parserHTML方法我们要先理清楚,html文件中有什么和我们需要什么:
- 标题:返回查询结果时,可以展示给用户以供选择
- 正文:用于提取关键词构建倒排索引
- url:用户点击时通过url跳转到对应页面
private void parserHTML(File file) {//a.解析出标题String title = parserTitle(file);//b.解析出urlString url = parserUrl(file);//c.解析出正文String content = parserContent(file);}private String parserContent(File file) {StringBuilder content = new StringBuilder();//按字节读,这里使用BufferedReader 提高速度try(BufferedReader bufferedReader = new BufferedReader(new FileReader(file), 1024 * 1024)) {while(true) {int ch = bufferedReader.read();if(ch == -1) {//文件读完了break;}content.append((char)ch);}} catch (IOException e) {throw new RuntimeException(e);}String ret = content.toString();//使用正则表达式替换掉js代码ret = ret.replaceAll("<script.*?>.*?</script>", "");//使用正则表达式替换html标签ret = ret.replaceAll("<.*?>", "");//把换行符和连续的多个空格替换为一个空格使内容更美观ret = ret.replaceAll("\\s+", " ");}private String parserUrl(File file) {//拼接出在线文档对应的urlString s1 = "https://docs.oracle.com/en/java/javase/17/docs/api";String s2 = file.getAbsolutePath().substring(FILE_PATH.length()).replace("\\", "/");return s1 + s2;}private String parserTitle(File file) {String fileName = file.getName();return fileName.substring(0, fileName.length() - ".html".length());}注意:FileReader的read方法是每次从磁盘里读取一个字符到内存中,BuferedReader 内部带有一个缓存区,会一次把多个字符加载到缓存区中,调用read方法时会从缓存区中读取字符,减少直接访问磁盘的次数提高了速度,构造方法中的第二个参数就是设置缓冲区的大小,单位是字节
2.2 实现Index类
实现Index类用于创建索引和通过关键词和索引查询相关文档:
前排索引由文档id和文档组成,要求能够通过文档id快速查询到文档,索引我们可以使用一个List来储存前排索引,即通过数组下标当作文档id,数组的内容即为文档的信息,于是我们创建一个DocInfo类用于存储文档信息:
package org.example.docsearcher.model;import lombok.Data;@Data
public class DocInfo {//储存一个文档的相关信息private int docId;private String title;private String url;private String content;public DocInfo() {}public DocInfo(String title, String url, String content) {this.title = title;this.url = url;this.content = content;}
}
于是前排索引的形式就是:
List<DocInfo> forwardIndex;后排索引要求由关键词查询到文档id,索引我们可以使用哈希表来关联关键词和文档id:
Map<String, List<Integer>> invertedIndex;但是只存储一个文档id无法表示不同文档和某一个关键词的相关程度,于是这里我们可以实现一个Relate类,用于存储一个关键词和一个文档直接的关联程度:
package org.example.docsearcher.model;import lombok.Data;@Data
public class Relate {//存储某个关键词和文档的相关程度//关键词private String key;//文档idprivate int docId;//权重,该值越大说明相关性越高private int weight;public Relate() {}public Relate(String key, int docId, int weight) {this.key = key;this.docId = docId;this.weight = weight;}
}
这里的权重我们可以以该关键词在该文档中出现的次数来表示
于是最后的后排索引的形式是:
Map<String, List<Relate>> invertedIndex;Index实现:
package org.example.docsearcher.config;@Configuration
public class Index {//前排索引public static List<DocInfo> forwardIndex = new ArrayList<>();//后排索引public static Map<String, List<Relate>> invertedIndex = new HashMap<>();//通过docId,在正排索引中查询文档信息public DocInfo getDocInfoById(int docId) {return forwardIndex.get(docId);}//通过一个关键词在倒排索引中查看相关文档public List<Relate> getDocInfoByKey(String key) {return invertedIndex.get(key);}//在索引中新增一个文档public void addDoc(String title, String url, String content) {//增加前排索引DocInfo docInfo = addForward(title, url, content);//增加后排索引addInverted(docInfo);}private DocInfo addForward(String title, String url, String content) {}private void addInverted(DocInfo docInfo) {}
}实现addForward:
private DocInfo addForward(String title, String url, String content) {DocInfo docInfo = new DocInfo(title, url, content);docInfo.setDocId(forwardIndex.size());forwardIndex.add(docInfo);return docInfo;}实现addInverted:
实现该方法我们需要找出该文档中的所有词,并统计每个词出现的次数,我们可以使用 ansj 库来实现分词操作:
在pom文件中添加对应依赖:
<dependency><groupId>org.ansj</groupId><artifactId>ansj_seg</artifactId><version>5.1.6</version></dependency> private void addInverted(DocInfo docInfo) {//通过分词统计每个词在文章中出现的次数来作为相关性权重Map<String, Integer> countMap = new HashMap<>();//统计标题中的词 权重为10String title = docInfo.getTitle();//分词,Term是ansj中的库,用于储存一个词的信息//parse()方法用于分词,getTerms把parse的返回结果转为一个List<Term>List<Term> terms = ToAnalysis.parse(title).getTerms();for(Term term : terms) {String key = term.getName();int count = countMap.getOrDefault(key, 0) + 10;countMap.put(key, count);}//统计正文中的词 权重为1String content = docInfo.getContent();terms = ToAnalysis.parse(content).getTerms();for(Term term : terms) {String key = term.getName();int count = countMap.getOrDefault(key, 0) + 1;countMap.put(key, count);}//添加到invertedIndexfor(Map.Entry<String, Integer> entry : countMap.entrySet()) {String key = entry.getKey();int weight = entry.getValue();List<Relate> relates = invertedIndex.get(key);Relate relate = new Relate(key, docInfo.getDocId(), weight);if(relates == null) {relates = new ArrayList<>();relates.add(relate);invertedIndex.put(key, relates);}else {relates.add(relate);}}}由于制作索引的速度是非常慢的,所有我们可以把制作好的索引存储在磁盘里,使用时再从磁盘加载到内存中,避免每次使用都要制作索引:
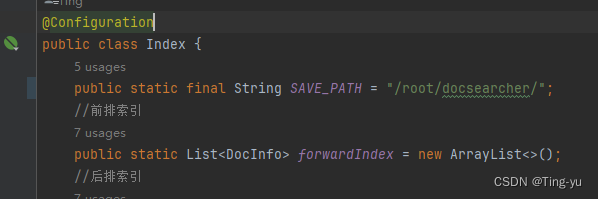
在Index类中增加一个存储索引的文件夹路径的常量:SAVE_PATH
实现save 和 load 方法用于保存和加载索引:
由于我们的索引是以对象的形式存在的,所以我们先需要把对象序列化再存入磁盘中,我们可以使用jackson库来完成这个操作
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.17.0</version></dependency>public void save() {//jacksonObjectMapper mapper = new ObjectMapper();File file = new File(SAVE_PATH);//判断目录是否存在,不存在则创建目录if(!file.exists()) {file.mkdirs();}//使用两个文件分别保存正排索引和倒排索引File forward = new File(SAVE_PATH + "forward.txt");File inverted = new File(SAVE_PATH + "inverted.txt");try {//写入到文件mapper.writeValue(forward, forwardIndex);mapper.writeValue(inverted, invertedIndex);} catch (IOException e) {throw new RuntimeException(e);}}public void load() {ObjectMapper mapper = new ObjectMapper();File forward = new File(SAVE_PATH + "forward.txt");File inverted = new File(SAVE_PATH + "inverted.txt");try {//加载到内存forwardIndex = mapper.readValue(forward, new TypeReference<List<DocInfo>>() {});invertedIndex = mapper.readValue(inverted, new TypeReference<Map<String, List<Relate>>>() {});} catch (IOException e) {throw new RuntimeException(e);}}2.3 联系Parser和Index
在上面的代码中,Parser类主要负责解析html文件,Index负责通过解析出的信息来生成索引,所以需要把Parser类解析出来的信息传给Index生成索引,我们可以在parserHTML()方法的最后调用Index类的addDoc()方法,让文件一解析就传给addDoc()开始添加索引,我们给Parser类添加一个Index类的成员变量,通过这个对象来调用addDoc()方法:
parserHTML()方法:
private void parserHTML(File file) {//a.解析出标题String title = parserTitle(file);//b.解析出urlString url = parserUrl(file);//c.解析出正文String content = parserContent(file);//d.添加索引index.addDoc(title, url, content);}到现在我们的索引模块的功能就已经实现了,调用Parser类的parser方法即可开始解析文件并制作索引。
2.4 速度优化
当我们完成这部分代码,开始制作索引时,发现制作索引的速度是非常慢的,我们添加一些代码统计制作索引的过程消耗的时间:
![]()
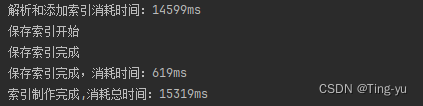
可以看到,我们制作索引的时间大概消耗了15秒,这只是相对于Java文档来说,要是是更大的文档时间会更长,要想提高速度,我们要先找到代码的那一步影响的速度,显而易见,解析和田间索引消耗的时间最多即parser()方法包含的代码,我们可以考虑优化这部分代码,该部分的代码主要包含三个操作:
- 解析文件
- 生成正排索引
- 生成到排索引
要优化这部分操作的速度我们可以考虑使用多线程,使用多个线程来并发完成这个操作:
实现一个parserByThread()方法使用多线程完成索引制作:
private void parserByThread() throws InterruptedException {//1.找出所有html文件List<File> fileList = new ArrayList<>();enumFile(FILE_PATH, fileList);//2.使用线程词并发对每个HTML文件进行解析并制作索引CountDownLatch countDownLatch = new CountDownLatch(fileList.size());ExecutorService executorService = Executors.newFixedThreadPool(4);for(File f : fileList) {executorService.submit(new Runnable() {@Overridepublic void run() {System.out.println("开始解析:" + f.getAbsolutePath());parserHTML(f);countDownLatch.countDown();}});}//等待所有任务执行完成countDownLatch.await();//3.把索引文件保存到磁盘index.save();}
上面代码中我们使用了线程池,用4个线程来完成解析和制作索引的工作,使用CountDownLatch类来保证所有任务执行完再开始执行save方法,CountDownLatch构造方法传入的参数是执行任务的个数,每个任务执行完后需调用countDown方法,执行到await方法时如果调用countDown方法的次数小于实例CountDownLatch时传入的参数就会阻塞等待,直到调用countDown方法次数等于传入参数。
接下来我们还需要考虑线程安全问题,当多个线程操作同一块内存时就会出现线程安全问题 :
在我们的代码中有添加索引时存在这种情况,也就是addForward方法和addInverted方法,我们需要给访问内存的代码加锁来保证线程安全问题:
private DocInfo addForward(String title, String url, String content) {DocInfo docInfo = new DocInfo(title, url, content);synchronized (locker1) {docInfo.setDocId(forwardIndex.size());forwardIndex.add(docInfo);}return docInfo;} private void addInverted(DocInfo docInfo) {//通过分词统计每个词在文章中出现的次数来作为相关性权重Map<String, Integer> countMap = new HashMap<>();//统计标题中的词 权重为10String title = docInfo.getTitle();List<Term> terms = ToAnalysis.parse(title).getTerms();for(Term term : terms) {String key = term.getName();int count = countMap.getOrDefault(key, 0) + 10;countMap.put(key, count);}//统计正文中的词 权重为1String content = docInfo.getContent();terms = ToAnalysis.parse(content).getTerms();for(Term term : terms) {String key = term.getName();int count = countMap.getOrDefault(key, 0) + 1;countMap.put(key, count);}//添加到invertedIndexfor(Map.Entry<String, Integer> entry : countMap.entrySet()) {String key = entry.getKey();int weight = entry.getValue();synchronized (locker2) {List<Relate> relates = invertedIndex.get(key);Relate relate = new Relate(key, docInfo.getDocId(), weight);if(relates == null) {relates = new ArrayList<>();relates.add(relate);invertedIndex.put(key, relates);}else {relates.add(relate);}}}}注意两个方法操作的内存不是同一块,所有可以使用不同的的对象来加锁。
运行代码:
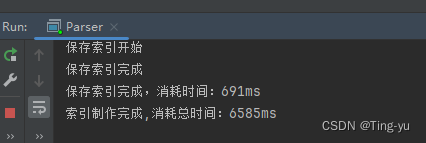
可以看到速度的提升非常明显 ,不过这里我们发现当索引制作完成我们的代码还没有提示运行结束,这是因为,我们通过线程池创建的线程模式是非守护线程,非守护线程会阻止进程的结束,我们可以在任务执行完时调用ExecutorService类的shutdown()方法来销毁线程,从而让进程顺利结束:
3. 搜索模块实现
搜索模块的功能是调用索引模块的代码,通过用户输入的关键词查询到相关文档信息,处理后返回
查询操作只需要调用索引模块的方法,这里我们重点关注如何处理查询到的信息。
首先我们先思考,需要返回什么信息,首先能想到的有文档标题,和文档描述(这两项需要展示给用户),所以需要在返回结果中包含这两项信息,其次,用户如果想要查看文档的具体信息,那么需要url来跳转到在线文档界面,所以还需要url,最后,如果我们是用户,我们肯定希望能更快的找到想要查询的文档,所以我们还可以对查询结果按和关键词的相关性做一个降序排序。
定义一个Result类用于充当返回结果的类型:
package org.example.docsearcher.model;import lombok.Data;@Data
public class Result {private String title;private String url;//描述private String desc;
}
定义DocSearcher类完成搜索模块的主要功能:
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Locale;@Configuration
public class DocSearcher {//用于调用索引模块接口private Index index = new Index();public List<Result> search(String query) {//1.对用户输入结果进行分词//2.通过用户输入的关键词在倒排索引中查询相关文档//3.对查询到的结果按相关性降序排序//4.通过正排索引查询文档相关信息并做返回处理}}
这里对用户输入结果处理时还需要考虑一个问题:用户输入的词一定都是关键词吗?显然不是,例如用户输入:What is HashMap? ,显然里面的what 和 is 都不是关键词,并且这样的词在文档里会出现很多,就可能会导致用户想要看到的结果被挤到下方去了,这样的词称为暂停词,我们在对用户输入进行分词时要去掉暂停词,我们可以在网络上下载一个现成的暂停词表,运行程序时把它加载到内存中,用一个Set存储,用于排除分词结果中的暂停词。

这里我放在一个txt文件中。
@Configuration
public class DocSearcher {public Index index = new Index();private static final String STOP_WORD_PATH = "D:/桌面/stopWords.txt";private Set<String> stopWords = new HashSet<>();public DocSearcher() {//加载索引index.load();//加载停用词loadStopWord();}public List<Result> search(String query) {//1.对用户输入结果进行分词List<Term> terms = ToAnalysis.parse(query).getTerms();//2.通过用户输入的关键词在倒排索引中查询相关文档List<Relate> allDocs = new ArrayList<>();for(Term term : terms) {String key = term.getName();//判断是否是暂停词,或者空格if(!stopWords.contains(key) && !key.equals(" ")) {List<Relate> docs = index.getInverted(key);//判断是否有相关文章if(docs == null) {continue;}//添加到查询结果allDocs.addAll(docs);}}//3.对查询到的结果按相关性降序排序allDocs.sort(new Comparator<Relate>() {@Overridepublic int compare(Relate o1, Relate o2) {return o2.getWeight() - o1.getWeight();}});//4.通过正排索引查询文档相关信息并做返回处理List<Result> results = new ArrayList<>();for(Relate relate : allDocs) {DocInfo docInfo = index.getForward(relate.getDocId());Result result = new Result();result.setTitle(docInfo.getTitle());result.setUrl(docInfo.getUrl());result.setDesc(genDesc(relate.getKey(), docInfo.getContent()));results.add(result);}return results;}private void loadStopWord() {try(BufferedReader bufferedReader = new BufferedReader(new FileReader(STOP_WORD_PATH))) {while(true) {String line = bufferedReader.readLine();if(line == null) {//读取完毕break;}stopWords.add(line);}} catch (IOException e) {throw new RuntimeException(e);}}private String genDesc(String key, String content) {//通过关键词和正文生成摘要//在正文中查找第一次出现关键词的位置,使用正则表达式确保找到的的是单独的一个单词//注意ansj分词结果会转为小写,所以需要把content也转为小写再匹配content = content.toLowerCase().replaceAll("\\b" + key + "\\b", " " + key + " ");int firstPos = content.indexOf(" " + key + " ");//取该位置前后各150个字符作为摘要int begPos = Math.max(firstPos - 150, 0);int endPos = Math.min(firstPos + 150, content.length());String desc = content.substring(begPos, endPos) + "...";//给关键词加上<i>标签,(?i)表示不区分大小写替换desc = desc.replaceAll("(?i)" + " " + key + " ", " <i>" + key + "</i> ");return desc;}}
4. Web模块实现
基本的功能已经实现,现在只需提供一个接口供用户访问即可
package org.example.docsearcher.controller;import org.example.docsearcher.model.Result;
import org.example.docsearcher.service.SearcherService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequestMapping("/searcher")
public class SearcherController {@AutowiredSearcherService service;@RequestMapping("/getInfo")public List<Result> getInfo(String query) {return service.getInfo(query);}
}package org.example.docsearcher.service;import org.example.docsearcher.config.DocSearcher;
import org.example.docsearcher.model.Result;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;@Service
public class SearcherService {@AutowiredDocSearcher searcher;public List<Result> getInfo(String query) {return searcher.search(query);}
}5. 前端页面实现
现在后端代码已经全部完成,接下来实现一个简单的页面调用后端的接口即可:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Java文档搜索</title><style>* {margin: 0;padding: 0;box-sizing: border-box;}html, body {height: 100%;background-image: url(image/image.png);background-repeat: no-repeat;background-position: center center;background-size: cover;}.container {width: 70%;height: 100%;margin: 0 auto;background-color: rgba(255, 255, 255, 0.8);border-radius: 20px;padding: 20px;overflow: auto;}.header {display: flex;align-items: center;padding: 30px;background-color: #f8f9fa;border-radius: 8px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);}#search-input {width: 90%;padding: 12px;font-size: 16px;border: 2px solid #dee2e6;border-radius: 5px;transition: border-color 0.3s ease;}#search-input:focus {border-color: #495057;outline: none;}#search-btn {margin-left: 5px;padding: 12px 20px;background-color: #007bff;color: white;border: none;border-radius: 5px;cursor: pointer;}#search-btn:active {background-color: #007bbf;}.item {width: 100%;margin-top: 20px;}.item a{display: block;height: 40px;font-size: 22px;line-height: 40px;font-weight: 700px;color: #007bff;}.item desc{font-size: 18px;}.item .url {font-size: 18px;color: rgb(0, 200, 0);}</style>
</head>
<body><!-- 整个页面元素的容器 --><div class="container"><!-- 搜索框和搜索按钮 --><div class="header"><input type="text" id="search-input" placeholder="请输入搜索内容..."><button id="search-btn" onclick="getInfo()">搜索</button></div><!-- 搜索结果 --><div class="result"><!-- <div class="item"><a href="#">我是标题</a><div class="desc">我是描述</div><div class="url">www.baidu.com</div></div> --></div></div><script src="js/jquery.min.js"></script><script><-- 点击搜索按钮后调用该方法 -->function getInfo() {$(".result").empty();var query = $("#search-input").val();$.ajax({url: "/searcher/getInfo?query=" + query,type: "get",success: function(results) {var html = "";for(var result of results) {html += '<div class="item"><a href="'+result.url+'" target="_blank">'+result.title+'</a>';html += '<div class="desc">'+result.desc+'</div>';html += '<div class="url">'+result.url+'</div></div>';}$(".result").html(html);}}); }</script>
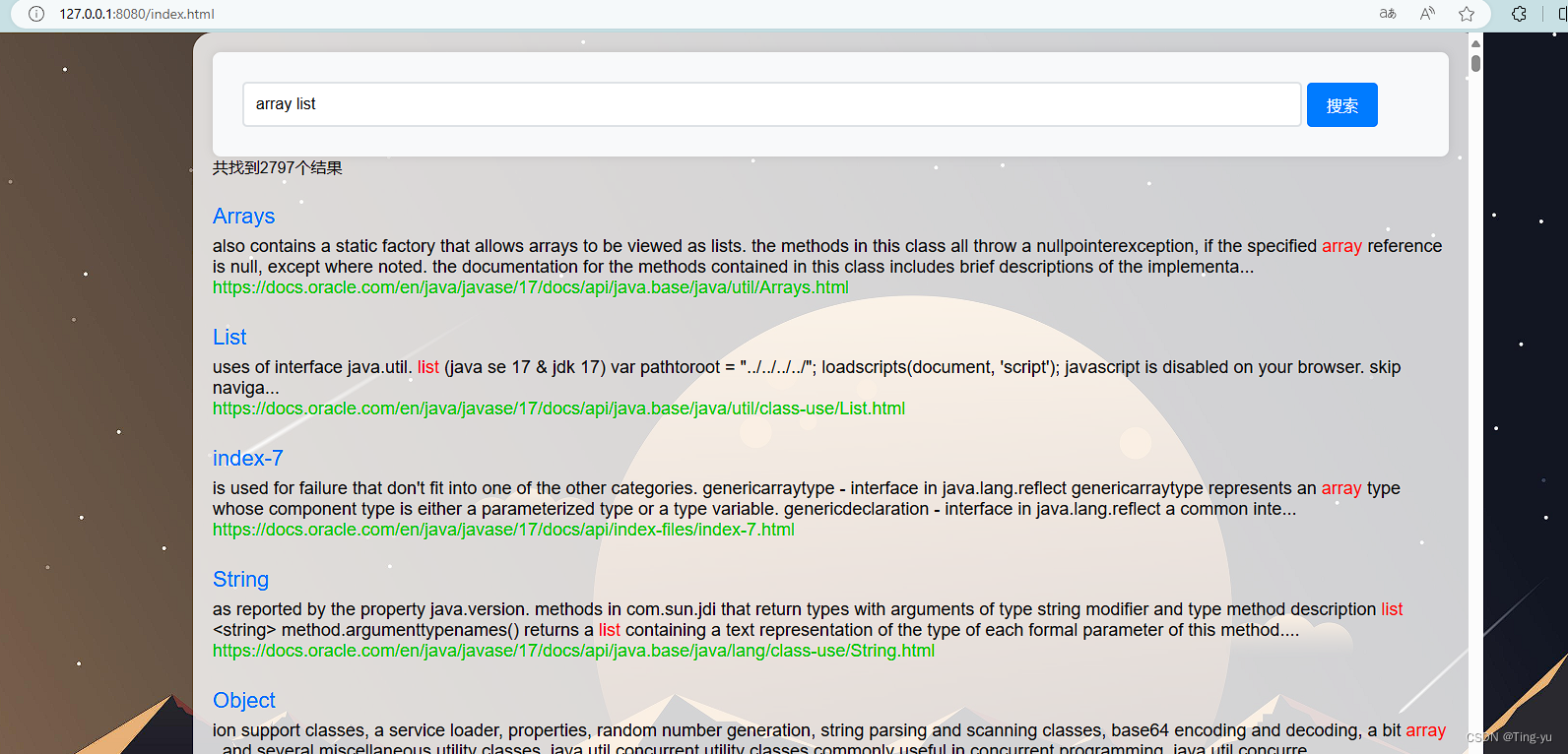
</body></html>启动服务器在前端界面搜索:

可以看到成功的弹出了搜索结果。这里我们还可以做一个优化,当我们使用浏览器搜索某个关键词时,浏览器的搜索结果中会把我们所输入的关键词标红:

我们也可以实现一个同样的功能。
这里我们通过前后端配合的方式实现,在后端生成每个搜索结果的描述的时候,我们给描述中的关键词都加上一个<i>标签,再通过前端设置样式来调整字体颜色:
修改 genDesc方法:
private String genDesc(List<Term> terms, String key, String content) {//通过关键词和正文生成摘要//在正文中查找第一次出现关键词的位置,使用正则表达式确保找到的的是单独的一个单词//注意ansj分词结果会转为小写,所以需要把content也转为小写再匹配content = content.toLowerCase().replaceAll("\\b" + key + "\\b", " " + key + " ");int firstPos = content.indexOf(" " + key + " ");//取该位置前后各150个字符作为摘要int begPos = Math.max(firstPos - 150, 0);int endPos = Math.min(firstPos + 150, content.length());String desc = content.substring(begPos, endPos) + "...";//给关键词加上<i>标签,(?i)表示不区分大小写替换for(Term term : terms) {String word = term.getName();desc = desc.replaceAll("(?i)" + " " + word + " ", " <i>" + word + "</i> ");}return desc;}在前端的代码中添加对<i>标签的样式:
.item .desc i {color: red;font-style: normal;}重新启动程序:
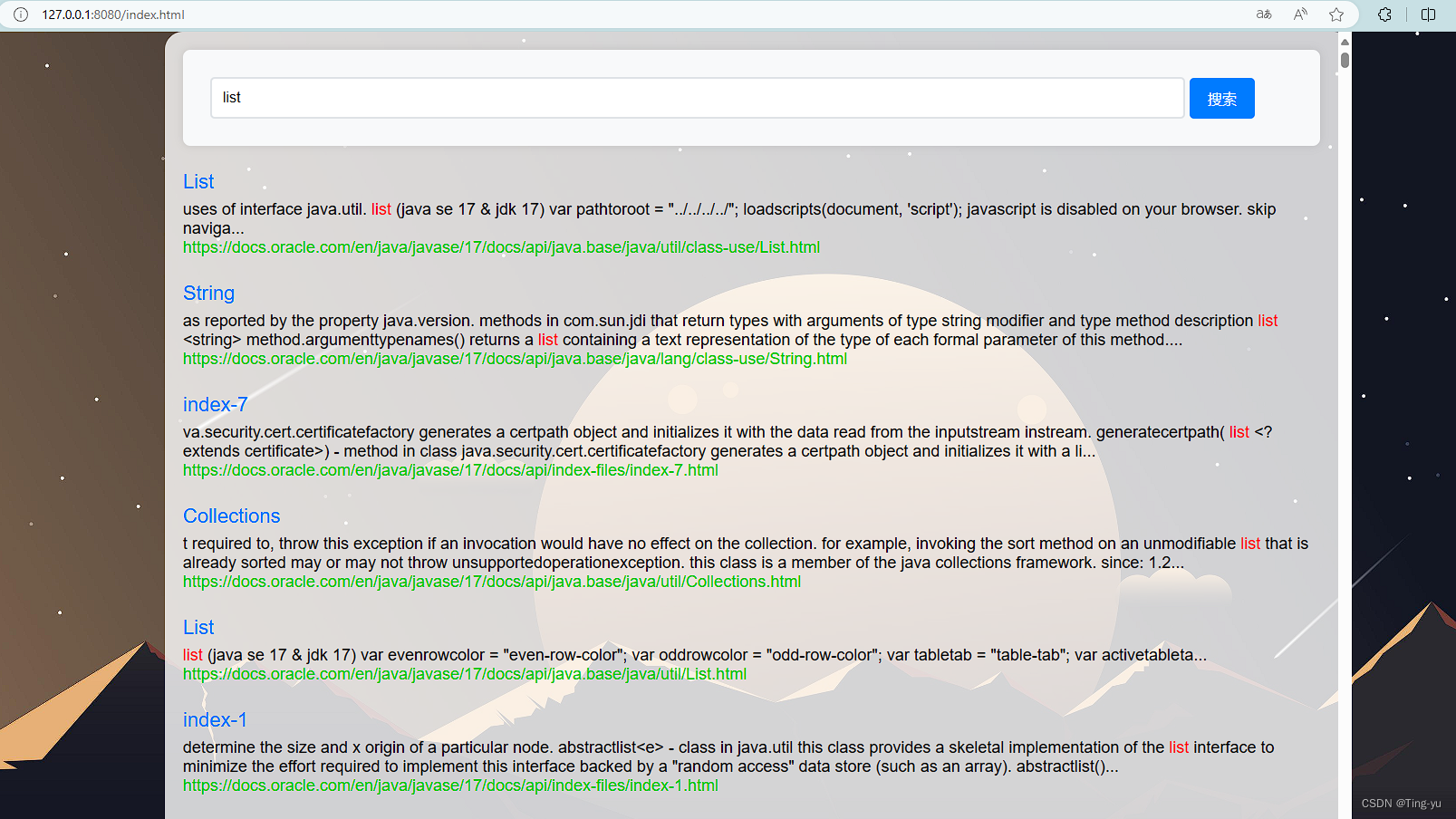
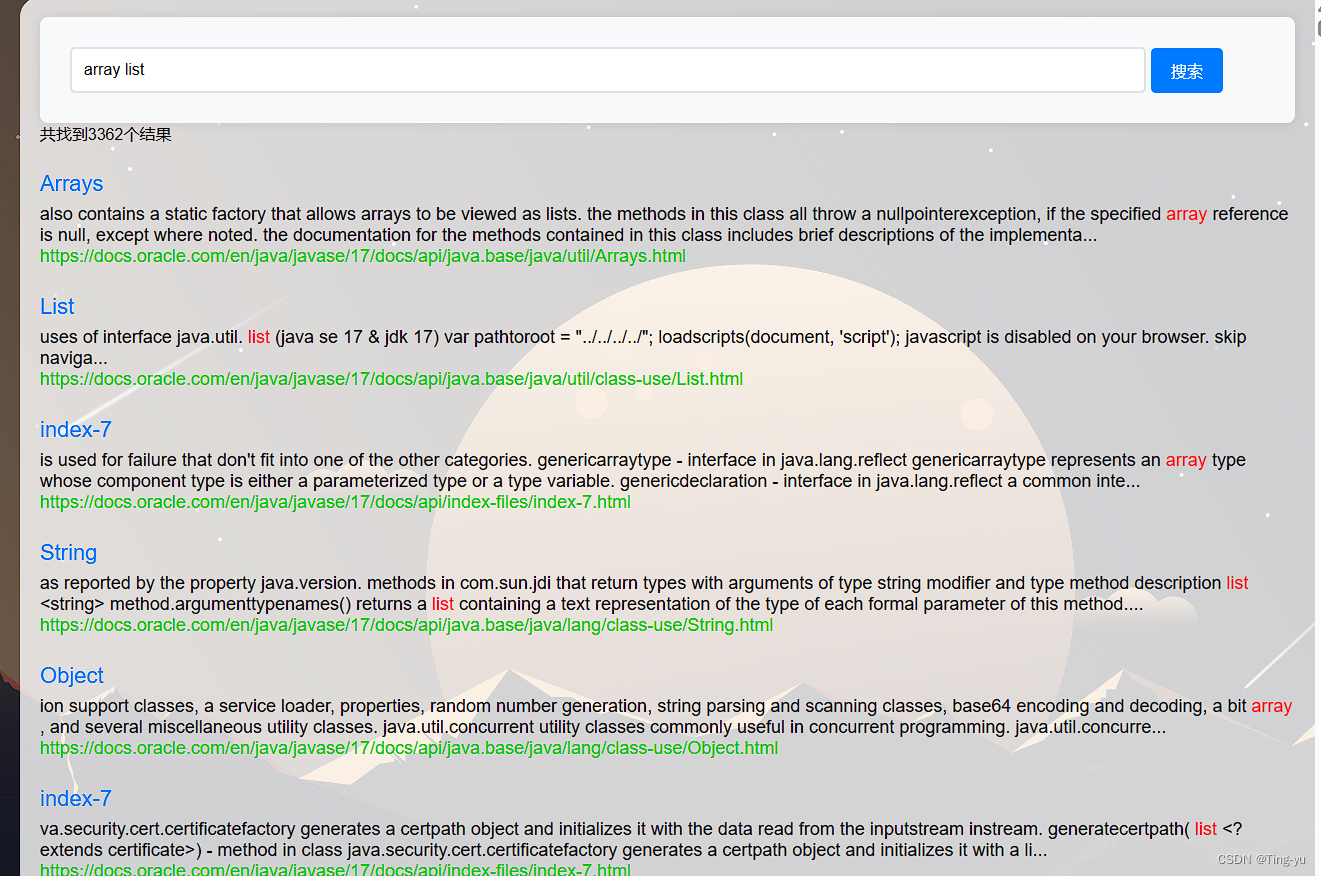
可以看到关键词成功被标红 , 这里我们还可以在前端代码中添加一个显示搜索结果数量的功能:
6. 部署程序
到此位置我们 api文件搜索引擎的所有功能都实现了,接下来就可以部署到云服务器上,在此之前我们需要把在本地制作好的索引文件和暂停词文件拷贝到云服务器上:
然后把代码中的路径改为云服务器中对应的路径:

打包程序:
双击package:
把生成的jar包拷贝到云服务器上,输入指令:
nohup java -jar jar包名称.jar &
即部署完毕

接下来就可以支持用户使用公网id访问 我们的程序。