前言
本篇介绍以Triton作为推理服务器,TensorRT作为推理后端,部署句嵌入向量模型m3e-base的工程方案和实现,句嵌入模型本质上是Bert结构,本案例可以推广到更一般的深度学习模型部署场景。
内容摘要
- 推理服务器和推理后端介绍
- TensorRT+Triton环境搭建
- Bert模型转化为ONNX中间表示
- ONNX中间表示编译为TensorRT模型文件
- Triton服务端参数配置
- Triton服务端代码实现
- Triton服务端启动
- HTTP客户端请求
- TensorRT前后压测结果对比
推理服务器和推理后端介绍
在Triton+TensorRT的组合中,Triton是推理服务器,TensorRT是推理后端,两者都是NVIDIA推出的推理部署服务组件,Triton原名TensorRT Inference Server,是专供于TensorRT后端的推理服务器,由于TensorRT Inference Server支持的后端越来越多,因此其改名为Triton,Triton+TensorRT一直是NVIDIA主推的部署方式。
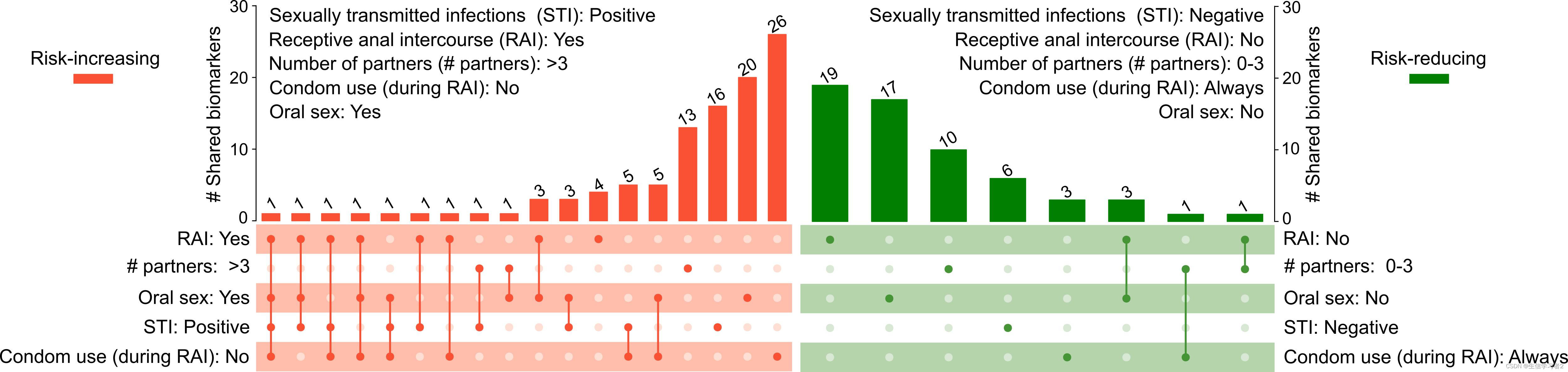
模型的推理服务由两块组件构成,分别是推理服务器和推理后端,推理服务器负责处理客户端的请求输送给推理后端,推理后端负责输出推理结果,经过推理服务器返回给客户端,两者的工作示意图如下

推理服务器和推理后端示意图
推理服务的优化需要推理服务器和推理后端的共同优化,其中推理后端的优化主要体现在推理引擎内核的优化使得推理的性能更高,延迟更低,推理服务器的优化主要体现在推理策略、调度策略的优化,通过辅助策略来协助后端更好地推理,提高吞吐量。
推理服务器接受客户端请求,并为后端推理提供必要的前提准备,包括
- 前处理:对请求的数据进行预先处理,使得服务后端模型的要求,例如NLP领域,对输入的自然语言使用tokenizer进行分词编码
- 后处理:对后端模型的推理结果做再加工,符合客户端的需求,比如对输出的矩阵进行reshape转换,label映射等
- 模型预热:在服务完全启动之前,提供一些样例数据给到模型推理,使得模型完全初始化
- 动态批处理:服务端自动将请求时间接近的所携带的数据进行合并,从而批量推理提高GPU的利用率,等待请求的合并会带来一定的延迟
- 并发多实例:推理服务器设置多个实例来共同处理请求,分配资源来处理模型的负载,提高并发请求下的服务吞吐量
推理后端又分别推理表示和推理引擎,其内容如下
- 推理表示:即模型格式,是模型训练后输出的模型文件,例如Tensorflow的冻结图,PyTorch的bin格式
- 推理引擎:即支持该类模型格式的推理计算组件,Tensorflow和PyTorch这样的训练框架本身自带推理引擎,也有其他的更加优化的推理引擎,比如ONNXRuntime等。
业界常用的推理服务器和推理后端罗列如下

推理服务器和推理后端选型
本文要介绍的是以Triton作为推理服务器,以TensorRT作为推理后端的部署方案,其中Triton中的后端程序由Python实现,模型格式为TensorRT,使用Python后端下的TensorRT包实现对模型推理。
TensorRT+Triton环境搭建
笔者的环境为NVIDIA显卡驱动driver版本为535.154.05,cuda版本为12.2。下载Triton的Docker镜像,到NVIDIA查看符合cuda版本的镜像。 下载23.08版本的Triton镜像,对应的TensorRT版本为8.6.1.6,该镜像提供了推理服务器环境,是模型服务的基础镜像,该镜像的Python3版本为3.10。
docker pull nvcr.io/nvidia/tritonserver:23.08-py3下载23.08版本的TensorRT镜像,该镜像的作用是使用trtexec将onnx模型格式转化为trt格式
docker pull nvcr.io/nvidia/tensorrt:23.08-py3手动下载8.6.1.6版本的TensorRT,下载的目的是手动安装TensorRT的Python包,在推理的时候需要TensorRT的Python API实现推理

TensorRT官网下载
解压
tar -xzvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-12.0.tar.gz下一步搭建基础镜像环境,需要在tritonserver镜像中安装如下Python包依赖,参考版本如下
torch 2.1.2+cu121
transformers 4.39.3
tensorrt 8.6.1
sentence-transformers 2.7.0
pycuda 2022.2.2手动下载torch gpu版本和cuda,和TensorRT解压后的文件夹到pip_package下,一起映射到容器
# docker启动Triton镜像
docker run --rm -it -v /home/pip_package/:/home nvcr.io/nvidia/tritonserver:23.08-py3 /bin/bash# 安装tensorrt
cd /home
pip install TensorRT-8.6.1.6/python/tensorrt-8.6.1-cp310-none-linux_x86_64.whl# 安装torch
pip install torch-2.1.2+cu121-cp310-cp310-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装transformers
pip install transformers -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装sentence-transformers
pip install sentence-transformers -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装pycuda
pip install pycuda -i https://pypi.tuna.tsinghua.edu.cn/simple将容器保存为一个新的镜像,至此环境搭建完毕
docker commit xxxxxxx triton_tensorrt_py_23.08:v1Bert模型转化为ONNX中间表示
使用TensorRT作为后端推理模型必须将模型转化为trt格式,目前众多模型都支持转化为trt,但是支持程度层次不起,其中TensorRT对模型中间表示ONNX支持的最好,因此一般的做法是将tensorflow,pytorch的模型文件先转化为ONNX,再从ONNX转化为trt格式。
首先将m3e-base模型转化为ONNX格式,PyTorch API支持直接转化
from transformers import BertModelmodel = BertModel.from_pretrained("./m3e-base").eval()import torch
onnx_path = "./m3e-base.onnx"input_ids = torch.LongTensor([[1, 2, 3], [2, 3, 4]])
attention_mask = torch.LongTensor([[1, 1, 1], [1, 1, 1]])torch.onnx.export(model,(input_ids, attention_mask),onnx_path,verbose=False,opset_version=11,input_names=['input_ids', 'attention_mask'],output_names=['output'],dynamic_axes={"input_ids": {0: "batch_size", 1: "max_seq_len"},"attention_mask": {0: "batch_size", 1: "max_seq_len"},"output": {0: "batch_size"}})其中input_names和output_names取名可以自定义,输入的顺序必须和模型forward顺序一致,dynamic_axes代表不定长的动态维度,指定维度索引和一个自定义命名,本例中input_ids,attention_mask的0,1维度都是不定长,output的0维度是不定长
ONNX中间表示编译为TensorRT模型文件
下一步将ONNX文件转化为trt格式,将m3e-base.onnx(/home/model_repository/目录下)映射到tensorrt容器内,使用trtexec进行转换,需要将宿主机的gpu挂入容器内
docker run --gpus=all --rm -it -v /home/model_repository/:/home nvcr.io/nvidia/tensorrt:23.08-py3 /bin/bash
trtexec --onnx=m3e-base.onnx \
--workspace=10000 \
--saveEngine=m3e-base.trt \
--minShapes=input_ids:1x1,attention_mask:1x1 \
--optShapes=input_ids:16x512,attention_mask:16x512 \
--maxShapes=input_ids:64x512,attention_mask:64x512若日志显示PASSED代表转化成功,若显示空间不足报错请适当增大workspace,其中saveEngine代表模型输出的文件命中,minShapes,optShapes,maxShapes代表支持动态输入,指定最小尺寸和最大尺寸。转化完成后输出trt文件m3e-base.trt,将其映射到triton_tensorrt_py_23.08:v1容器中,测试是否能够正常被tensorrt的Python API读取
docker run --rm -it --gpus=all -v /home/model_repository:/home triton_tensorrt_py_23.08:v1 /bin/bash用容器内的Python3来读取trt文件
root@a10830d0aeec:/home# python3
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorrt as trt
>>> TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
>>> def get_engine(engine_file_path):
... print("Reading engine from file {}".format(engine_file_path))
... with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
... engine = runtime.deserialize_cuda_engine(f.read())
... return engine
...
>>> engine_model_path = "m3e-base.trt"
>>> engine = get_engine(engine_model_path)
Reading engine from file m3e-base.trt
>>>若没有报错则表示trt模型转化成功
Triton服务端参数配置
Triton部署模型的服务端有严格的文件目录和文件形式要求,首先创建一个模型目录命名为m3e-base-trt,本例的文件格式如下
(base) [root@localhost m3e-base-trt]# tree
.
├── 1
│ ├── m3e-base-trt
│ │ ├── m3e.trt
│ │ └── vocab.txt
│ ├── model.py
│ ├── __pycache__
│ │ ├── model.cpython-310.pyc
│ │ ├── model.cpython-38.pyc
│ │ ├── trtutils.cpython-310.pyc
│ │ └── trtutils.cpython-38.pyc
│ ├── trtutils.py
│ └── work
│ └── version.txt
└── config.pbtxt该目录下的1代表模型版本,可以取任意数字id作为文件名代表模型版本,默认情况下Triton以最大的那个模型版本作为服务。config.pbtxt为模型的服务端配置文件,配置如下
(base) [root@localhost m3e-base-trt]# cat config.pbtxt
name: "m3e-base-trt"
backend: "python"max_batch_size: 32
input [{name: "text"dims: [ -1 ]data_type: TYPE_STRING}
]
output [{name: "embeddings"dims: [ 768 ]data_type: TYPE_FP32}
]instance_group [
{count: 2kind: KIND_GPUgpus: [ 0 ]
}
]
dynamic_batching {max_queue_delay_microseconds: 2000
}该文件决定了模型的输入输出的维度,服务策略等内容,重点内容如下
- backend:推理后端,本例采用Python实现的自定义客户端,在Python中使用了tensorrt的API,因此本质上是tensorrt的后端
- max_batch_size:一次推理的最大批次,超过该值会报错,max_batch_size通常和动态批处理dynamic_batching一起使用,max_batch_size会作为停止合并的一个条件
- input/output:输入和输入的定义,变量名自定义,但是必须和Python后端脚本一致,dims代表维度,-1代表不定长,data_type代表类型,具体使用请参考Triton的教程
- instance_group:多实例设置,kind代表设备,KIND_GPU为GPU设备,也可以指定CPU,gpus指定GPU设备号,多个id就是指定多gpu,count代表实例数,具体是每个GPU/CPU下的实例数,本例中代表0号GPU启2个实例
- dynamic_batching:动态批处理,服务端会自动合并请求,从而尽量以批量推理的方式来代替单条请求推理,提高吞吐量,因此服务端会主动等待max_queue_delay_microseconds时间,在这段时间内服务端会将所有请求合并,合并完成后再输送给推理后端,推理完成后合并的结果会再拆成单条请求的形式,因此对客户端无感。默认情况下如果不设置dynamic_batching,Triton不会进行动态批处理
自定义Python客户端需要在版本号文件夹下设置一个model.py文件,该文件内部实现了后端推理逻辑,work目录为服务运行过程中自动生成,不需要理会。
Triton服务端代码实现
服务端代码实现在model.py中,具体的在其中实现trt文件的读取,客户端数据的获取,模型推理,响应返回,本例如下
import os# 设置显存空闲block最大分割阈值
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:32'
# 设置work目录os.environ['TRANSFORMERS_CACHE'] = os.path.dirname(os.path.abspath(__file__)) + "/work/"
os.environ['HF_MODULES_CACHE'] = os.path.dirname(os.path.abspath(__file__)) + "/work/"import json
import triton_python_backend_utils as pb_utils
import sys
import gc
import time
import logging
from transformers import BertTokenizer
import tensorrt as trt
import numpy as np
import torchimport trtutils as trtugc.collect()logging.basicConfig(format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s',level=logging.INFO)
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)class TritonPythonModel:def initialize(self, args):# You must parse model_config. JSON string is not parsed hereself.model_config = json.loads(args['model_config'])output_config = pb_utils.get_output_config_by_name(self.model_config, "embeddings")# Convert Triton types to numpy typesself.output_response_dtype = pb_utils.triton_string_to_numpy(output_config['data_type'])# trt enginedef get_engine(engine_file_path):print("Reading engine from file {}".format(engine_file_path))with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:engine = runtime.deserialize_cuda_engine(f.read())return engineengine_model_path = os.path.dirname(os.path.abspath(__file__)) + "/m3e-base-trt"self.engine = get_engine(engine_model_path + "/m3e-base.trt")self.context = self.engine.create_execution_context()self.context.active_optimization_profile = 0self.tokenizer = BertTokenizer.from_pretrained(engine_model_path + "/vocab.txt")logging.info("model init success")def execute(self, requests):responses = []# TODO 记录下每个请求的数据和数据batch大小batch_text, batch_len = [], []for request in requests:text = pb_utils.get_input_tensor_by_name(request, "text").as_numpy().astype("S")text = np.char.decode(text, "utf-8").squeeze(1).tolist()batch_text.extend(text)batch_len.append(len(text))# 日志输出传入信息in_log_info = {"text": batch_text,}logging.info(in_log_info)# tokenizerencode = self.tokenizer.batch_encode_plus(batch_text, max_length=512, truncation=True, padding=True)input_ids, attention_mask = np.array(encode["input_ids"]).astype(np.int32), np.array(encode["attention_mask"]).astype(np.int32)origin_input_shape = self.context.get_binding_shape(0)origin_input_shape[0], origin_input_shape[1] = input_ids.shapeself.context.set_binding_shape(0, origin_input_shape)self.context.set_binding_shape(1, origin_input_shape)inputs, outputs, bindings, stream = trtu.allocate_buffers_v2(self.engine, self.context)inputs[0].host = input_idsinputs[1].host = attention_masktrt_outputs = trtu.do_inference_v2(self.context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)token_embeddings = trt_outputs[0].reshape(input_ids.shape[0], input_ids.shape[1], 768)# mean poolattention_mask = torch.LongTensor(attention_mask)token_embeddings = torch.tensor(token_embeddings)input_mask_expanded = (attention_mask.unsqueeze(-1).expand(token_embeddings.size()).to(token_embeddings.dtype))sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)sum_mask = input_mask_expanded.sum(1)sum_mask = torch.clamp(sum_mask, min=1e-9)token_embeddings = sum_embeddings / sum_mask# 归一化token_embeddings = torch.nn.functional.normalize(token_embeddings, p=2, dim=1)token_embeddings = token_embeddings.detach().cpu().numpy().tolist()# 日志输出处理后的信息out_log_info = {"embeddings": token_embeddings}#logging.info(out_log_info)# TODO 响应数要和请求数一致start = 0for i in range(len(requests)):end = start + batch_len[i]out_tensor = pb_utils.Tensor("embeddings",np.array(token_embeddings[start:end]).astype(self.output_response_dtype))start += batch_len[i]final_inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor])responses.append(final_inference_response)return responsesdef finalize(self):print('Cleaning up...')其中tensorrt只支持int32,因此需要手动将numpy数据类型转化为int32否则推理报错,trtu.do_inference_v2完成了模型推理。注意从客户端拿到的text和返回的embeddings命名都是要和config.pbtxt保持一致的。
trtutils为现成的推理工具方法,直接使用即可,代码如下
import argparse
import os
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trttry:# Sometimes python does not understand FileNotFoundErrorFileNotFoundError
except NameError:FileNotFoundError = IOErrorEXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)def GiB(val):return val * 1 << 30def add_help(description):parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)args, _ = parser.parse_known_args()def find_sample_data(description="Runs a TensorRT Python sample", subfolder="", find_files=[], err_msg=""):'''Parses sample arguments.Args:description (str): Description of the sample.subfolder (str): The subfolder containing data relevant to this samplefind_files (str): A list of filenames to find. Each filename will be replaced with an absolute path.Returns:str: Path of data directory.'''# Standard command-line arguments for all samples.kDEFAULT_DATA_ROOT = os.path.join(os.sep, "usr", "src", "tensorrt", "data")parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)parser.add_argument("-d", "--datadir",help="Location of the TensorRT sample data directory, and any additional data directories.",action="append", default=[kDEFAULT_DATA_ROOT])args, _ = parser.parse_known_args()def get_data_path(data_dir):# If the subfolder exists, append it to the path, otherwise use the provided path as-is.data_path = os.path.join(data_dir, subfolder)if not os.path.exists(data_path):if data_dir != kDEFAULT_DATA_ROOT:print("WARNING: " + data_path + " does not exist. Trying " + data_dir + " instead.")data_path = data_dir# Make sure data directory exists.if not (os.path.exists(data_path)) and data_dir != kDEFAULT_DATA_ROOT:print("WARNING: {:} does not exist. Please provide the correct data path with the -d option.".format(data_path))return data_pathdata_paths = [get_data_path(data_dir) for data_dir in args.datadir]return data_paths, locate_files(data_paths, find_files, err_msg)def locate_files(data_paths, filenames, err_msg=""):"""Locates the specified files in the specified data directories.If a file exists in multiple data directories, the first directory is used.Args:data_paths (List[str]): The data directories.filename (List[str]): The names of the files to find.Returns:List[str]: The absolute paths of the files.Raises:FileNotFoundError if a file could not be located."""found_files = [None] * len(filenames)for data_path in data_paths:# Find all requested files.for index, (found, filename) in enumerate(zip(found_files, filenames)):if not found:file_path = os.path.abspath(os.path.join(data_path, filename))if os.path.exists(file_path):found_files[index] = file_path# Check that all files were foundfor f, filename in zip(found_files, filenames):if not f or not os.path.exists(f):raise FileNotFoundError("Could not find {:}. Searched in data paths: {:}\n{:}".format(filename, data_paths, err_msg))return found_files# Simple helper data class that's a little nicer to use than a 2-tuple.
class HostDeviceMem(object):def __init__(self, host_mem, device_mem):self.host = host_memself.device = device_memdef __str__(self):return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)def __repr__(self):return self.__str__()# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):inputs = []outputs = []bindings = []stream = cuda.Stream()for binding in engine:size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size # max_batch_size=1dtype = trt.nptype(engine.get_binding_dtype(binding))# Allocate host and device buffershost_mem = cuda.pagelocked_empty(size, dtype)device_mem = cuda.mem_alloc(host_mem.nbytes) # # nbytes表示数组中的所有数据消耗掉的字节数# Append the device buffer to device bindings.bindings.append(int(device_mem))# Append to the appropriate list.if engine.binding_is_input(binding):inputs.append(HostDeviceMem(host_mem, device_mem))else:outputs.append(HostDeviceMem(host_mem, device_mem))return inputs, outputs, bindings, stream# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers_v2(engine, context):"""Allocates host and device buffer for TRT engine inference.This function is similiar to the one in ../../common.py, butconverts network outputs (which are np.float32) appropriatelybefore writing them to Python buffer. This is needed, sinceTensorRT plugins doesn't support output type description, andin our particular case, we use NMS plugin as network output.Args:engine (trt.ICudaEngine): TensorRT engineReturns:inputs [HostDeviceMem]: engine input memoryoutputs [HostDeviceMem]: engine output memorybindings [int]: buffer to device bindingsstream (cuda.Stream): cuda stream for engine inference synchronization"""inputs = []outputs = []bindings = []stream = cuda.Stream()for i, binding in enumerate(engine):# binding:input_ids,input_mask,output# print(context.get_binding_shape(i)) # (input_ids,input_mask,output).shape (1,105)size = trt.volume(context.get_binding_shape(i)) # 1*105# dims = engine.get_binding_shape(binding)# if dims[1] < 0:# size *= -1dtype = trt.nptype(engine.get_binding_dtype(binding)) # DataType.FLOAT# print(dtype) # <class 'numpy.float32'># Allocate host and device buffershost_mem = cuda.pagelocked_empty(size, dtype)device_mem = cuda.mem_alloc(host_mem.nbytes)# Append the device buffer to device bindings.bindings.append(int(device_mem))# Append to the appropriate list.if engine.binding_is_input(binding):inputs.append(HostDeviceMem(host_mem, device_mem))else:outputs.append(HostDeviceMem(host_mem, device_mem))return inputs, outputs, bindings, stream# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):# Transfer input data to the GPU.[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]# Run inference. batch_size = 1context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)# Transfer predictions back from the GPU.[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]# Synchronize the streamstream.synchronize()# Return only the host outputs.return [out.host for out in outputs]# This function is generalized for multiple inputs/outputs for full dimension networks.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference_v2(context, bindings, inputs, outputs, stream):# Transfer input data to the GPU.[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]# Run inference.context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)# Transfer predictions back from the GPU.[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]# Synchronize the streamstream.synchronize()# Return only the host outputs.return [out.host for out in outputs]由于m3e模型的特殊性,需要对模型推理结果做后处理,本例增加了mean pool和归一化操作,代码摘自sentence_transformers的源码,由于在模型转换阶段只对原生的Bert模型进行了转化,因此后处理需要额外补充进来。
Triton服务端启动
Triton存在三种启动方式none,poll,explicit,详情见官网文档。本例采用explicit模式启动,该模式下启动服务和关闭服务都需要手动指定,启动docker脚本如下
docker run --rm --gpus=all \
-p18999:8000 -p18998:8001 -p18997:8002 \
--shm-size=1g \
-e PYTHONIOENCODING=utf-8 \
-v /home/model_repository/:/models \
triton_tensorrt_py_23.08:v1 \
--model-repository=/models \
--model-control-mode explicit \
--load-model m3e-base-trt宿主机暴露三个端口承接容器内的8000,8001,8002,其中8000是客户端请求推理的端口。–load-model指定了在Triton启动的时候加载m3e-base-trt模型为服务,该名称和模型文件夹要保持一致。宿主机/home/model_repository下的目录结构如下所示,一个模型一个服务(实际上可以多个服务,即多版本),一个服务一个模型文件
(base) [root@localhost model_repository]# tree
.
├── bert-base-chinese
├── chatglm3-6b
├── m3e-base
├── m3e-base-trt
│ ├── 1
│ │ ├── m3e-base-trt
│ │ │ ├── m3e.trt
│ │ │ └── vocab.txt
│ │ ├── model.py
│ │ ├── model.py.bak
│ │ ├── __pycache__
│ │ │ ├── model.cpython-310.pyc
│ │ │ ├── model.cpython-38.pyc
│ │ │ ├── trtutils.cpython-310.pyc
│ │ │ └── trtutils.cpython-38.pyc
│ │ ├── trtutils.py
│ │ └── work
│ │ └── version.txt
│ └── config.pbtxt
├── Qwen1.5-1.8B-Chat
└── Qwen1.5-4B-Chatdocker启动后显示以下日志代表启动成功
I0422 10:35:54.844803 1 grpc_server.cc:2451] Started GRPCInferenceService at 0.0.0.0:8001
I0422 10:35:54.845428 1 http_server.cc:3558] Started HTTPService at 0.0.0.0:8000
I0422 10:35:54.888419 1 http_server.cc:187] Started Metrics Service at 0.0.0.0:8002可以使用curl请求来关停模型服务
curl -X POST http://0.0.0.0:18999/v2/repository/models/m3e-base-trt/unload同样也可以再启动
curl -X POST http://0.0.0.0:18999/v2/repository/models/m3e-base-trt/load注意可以在模型服务中进行load,此时Triton会检查模型目录下是否有变动,如果有变动此时load相当于reload,如果没有变动则load没有任何反应。
另外可以通过以下HTTP请求查看模型仓库下的所有模型,和已经准备就绪服务的模型
curl -X POST http://10.2.13.11:18999/v2/repository/index
[{"name":"Qwen1.5-1.8B-Chat"},{"name":"Qwen1.5-4B-Chat"},{"name":"bert-base-chinese"},{"name":"chatglm3-6b"},{"name":"m3e-base"},{"name":"m3e-base-trt","version":"1","state":"READY"},{"name":"onnx_trt"}]其中只有m3e-base-trt为READY状态,代表Triton目前只有一个模型在服务。
HTTP客户端请求
Triton暴露的服务支持HTTP和GRPC,本例采用更加通用的HTTP,请求的无如下
import json
import requestsif __name__ == '__main__':import timet1 = time.time()data = ["酒店很好", "pip清华源 清华大学的镜像", "源这篇文章主要为大家介绍了如何", "关内容,包含IT学习相关文档"]for d in data:url = "http://10.2.13.11:18999/v2/models/m3e-base-trt/infer"raw_data = {"inputs": [{"name": "text","datatype": "BYTES","shape": [1, 1],"data": [d]}],"outputs": [{"name": "embeddings","shape": [1, 768],}]}res = requests.post(url, json.dumps(raw_data, ensure_ascii=True), headers={"Content_Type": "application/json"},timeout=2000)print(res.text)返回如下
/usr/bin/python3.8 /home/myproject/bisai/m3e_trt_client.py
{"model_name":"m3e-base-trt","model_version":"1","outputs":[{"name":"embeddings","datatype":"FP32","shape":[1,768],"data":[0.014592116698622704,-0.020276973024010659,0.046606432646512988,-0....]Process finished with exit code 0注意一个请求带有多个数据,返回的结果会被Flatten为一行,所以需要后处理reshape。
Triton的HTTP采用KServe的协议,更多请求方式请看KServe官网
TensorRT前后压测结果对比
本次压测考察推理服务在一段时间不间断不同并发数的请求下,推理成功的吞吐量和95%响应时间,具体解释如下
- 并发数:分别取并发数为1, 2, 4, 16, 32
- 一段时间:取1分钟,1分钟连续不间断请求
- 吞吐量:单位为每秒能推理成功的请求数,
infer / s - 95%延迟时间:所有返回请求的响应时间的
95%分位数,就是说95%的请求响应时间应该小于这个值
并发测试脚本如下
import os
import time
import json
import threading
from typing import List
from concurrent.futures import ThreadPoolExecutorimport requestsclass InterfacePressureTesting:def __init__(self, concurrency, percent=0.95, duration=60):self.concurrency = concurrencyself.percent = percentself.duration = durationself.lock = threading.RLock()self.finished = 0self.delay = []def decorator(self, func):def wrapper(d: str):t = time.time()func(d)self.lock.acquire()self.delay.append(time.time() - t)self.finished += 1self.lock.release()return wrapperdef start(self, job, data: List[str]):executor = ThreadPoolExecutor(self.concurrency)for d in data * 10000:executor.submit(self.decorator(job), d)time.sleep(self.duration)executor.shutdown(wait=False)print(self.finished / self.duration)print(sorted(self.delay)[int(len(self.delay) * self.percent)])os.kill(os.getpid(), 9)if __name__ == '__main__':import sysapi_test = InterfacePressureTesting(concurrency=int(sys.argv[1]))# 定义接口请求逻辑job函数,["xxx", "xxx", "xxx", "xxx"]是造的请求数据文本api_test.start(job, ["xxx", "xxx", "xxx", "xxx", ...])笔者的环境是一块gtx 1080Ti的GPU,推理服务为m3e-base embedding服务,其本质是一个bert-base的推理,分别对比PyTorch作为后端部署和TensorRT作为后端部署的各项压测指标,推理服务器采用Triton。
- 第一组:一块GPU,一个实例

一块GPU,一个实例性能测试
在没有并发的情况下(并发为1),TensorRT的推理延迟比PyTorch降低48%,吞吐量提高82%将近一倍,随着并发的增大,TensorRT对性能的提升更加明显,基本稳定提升PyTorch一倍。由于只有一个实例,并发高了之后吞吐也基本饱和了。
- 第二组:一块GPU,两个实例

第二组:一块GPU,两个实例性能测试
因为有两个实例来分摊请求,PyTorch和TensorRT的推理性能差距被缩小,推理服务器的多实例策略微弥补了PyTorch推理性能的不足。在多实例和并发场景下,TensorRT性能稳定超过PyTorch的60%。
- 第三组:一块GPU,两个实例,允许服务端动态批处理,最大批次32, 合并请求允许最大等待0.002秒,就是说服务端会等待2ms,将2ms以内的所有请求合并进行批量推理,或者请求提前达到最大批次32直接推理。

第三组:一块GPU,两个实例,带有动态批处理
随着服务端批处理策略的加入,吞吐量有巨量的提升,相比于没有动态批处理提升了3倍(152 -> 468),开启动态批处理之后,PyTorch和TensorRT的差距再次缩小,且并发越大,批处理越明显,差距越小,TensorRT推理性能稳定超越Pytorch。虽然推理后端不行,但是合理的推理服务器优化也可以提高吞吐量。
最终结论:在没有任何服务端策略优化的情况下,裸预测性能TensorRT是PyTorch的2倍(gtx 1080ti),如果在推理服务器增加策略优化,比如动态批处理,多实例部署,则在高并发场景下,TensorRT和PyTorch的性能差异会被缩小,仅从后端这个角色上来说TensorRT稳定且可观超越PyTorch。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓