一、前言
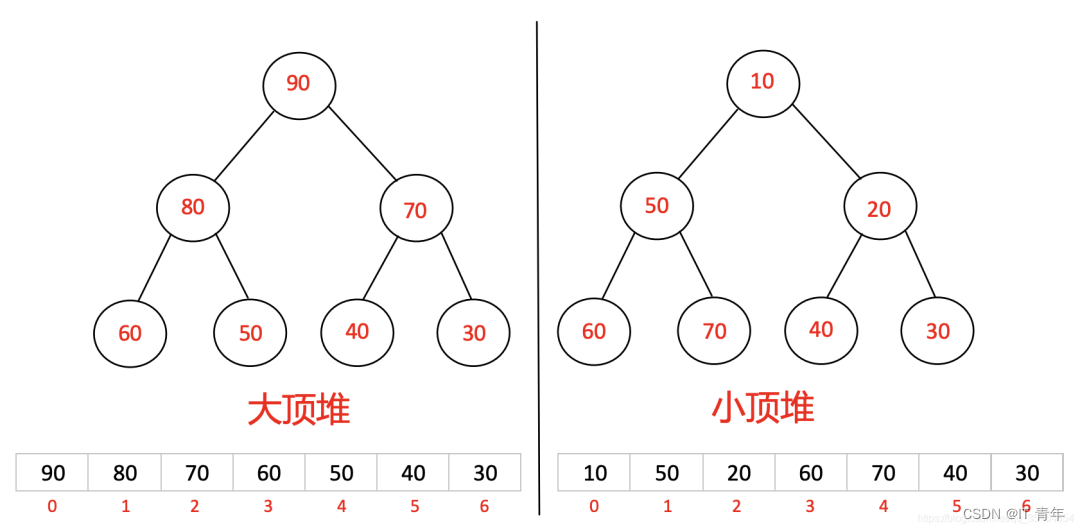
1.1、概念
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法 。堆是一个近似 完全二叉树 的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
1.2、排序步骤
构建最大堆(或最小堆):将待排序的数组构建为一个最大堆(或最小堆)。这可以通过从数组末尾开始,依次将每个节点调整到合适的位置来实现。调整的方法是将当前节点与其父节点比较,如果当前节点大于(或小于)父节点,则交换它们的位置,并重复这个过程直到当前节点符合最大堆(或最小堆)的性质。
交换堆顶和末尾元素:将最大堆(或最小堆)的堆顶元素与数组的最后一个元素交换位置。
破坏堆性质:将数组末尾的元素从堆中移除,即将数组的长度减一,并且将堆的根节点进行一次调整,使得剩余元素仍然满足最大堆(或最小堆)的性质。
重复步骤2和步骤3,直到堆的大小为1,即只剩下一个元素。
排序完成:最后得到的数组就是一个有序序列。
二、方法分析
堆排序是一种基于堆数据结构的比较排序算法。堆是一种完全二叉树,分为最大堆和最小堆。在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。堆排序通常使用最大堆进行升序排序。堆排序分为两个主要步骤:构建堆和排序。
三、举例说明
对数组 `[4, 10, 3, 5, 1]` 进行堆排序
#### 步骤 1:构建最大堆
将数组视为一个完全二叉树,然后从最后一个非叶子节点开始,向前调整每个节点,使其符合最大堆的性质。
1. 初始数组: `[4, 10, 3, 5, 1]`
- 二叉树表示:4/ \10 3/ \5 12. 从最后一个非叶子节点开始调整(节点 `10`,索引 `1`)。
- 节点 `10` 已经大于它的子节点,所以不需要调整。3. 调整节点 `4`(索引 `0`)。
- 节点 `4` 的子节点为 `10` 和 `3`。由于 `10` 最大,将 `4` 和 `10` 交换。
- 调整后数组: `[10, 4, 3, 5, 1]`
- 二叉树表示:10/ \4 3/ \5 1- 继续调整节点 `4`。它的子节点为 `5` 和 `1`,将 `4` 和 `5` 交换。
- 调整后数组: `[10, 5, 3, 4, 1]`
- 二叉树表示:
10/ \5 3/ \4 1现在,我们已经构建了一个最大堆。
#### 步骤 2:排序
将堆顶元素(最大值)与堆的最后一个元素交换,然后将剩余元素重新调整为最大堆,重复该过程直到所有元素有序。
1. 交换 `10` 和 `1`,并调整剩余部分为最大堆。
- 调整后数组: `[1, 5, 3, 4, 10]`
- 重新调整:1/ \5 3/4- 节点 `1` 的子节点为 `5` 和 `3`,将 `1` 和 `5` 交换。
- 调整后数组: `[5, 1, 3, 4, 10]`
- 继续调整节点 `1`,将 `1` 和 `4` 交换。
- 调整后数组: `[5, 4, 3, 1, 10]`
- 二叉树表示:5/ \4 3/12. 交换 `5` 和 `1`,并调整剩余部分为最大堆。
- 调整后数组: `[1, 4, 3, 5, 10]`
- 重新调整:1/ \4 3- 节点 `1` 的子节点为 `4` 和 `3`,将 `1` 和 `4` 交换。
- 调整后数组: `[4, 1, 3, 5, 10]`
- 二叉树表示:4/ \1 33. 交换 `4` 和 `3`,并调整剩余部分为最大堆。
- 调整后数组: `[3, 1, 4, 5, 10]`
- 重新调整:3/ 1- 节点 `3` 的子节点为 `1`,不需要调整。
4. 交换 `3` 和 `1`。
- 调整后数组: `[1, 3, 4, 5, 10]`
- 重新调整:没有需要调整的部分。最终,数组变为有序的 `[1, 3, 4, 5, 10]`。
通过上述步骤,堆排序成功地对数组进行了升序排列。
四、编码实现
下面是用Java实现的堆排序算法:
public class HeapSort {public static void main(String[] args) {int[] arr = {4, 10, 3, 5, 1};heapSort(arr);System.out.println("排序后的数组:");for (int num : arr) {System.out.print(num + " ");}}public static void heapSort(int[] arr) {// 构建大顶堆for (int i = arr.length / 2 - 1; i >= 0; i--) {adjustHeap(arr, i, arr.length);}// 调整堆结构+交换堆顶元素与末尾元素for (int j = arr.length - 1; j > 0; j--) {swap(arr, 0, j);adjustHeap(arr, 0, j);}}public static void adjustHeap(int[] arr, int i, int length) {int temp = arr[i]; // 先取出当前元素ifor (int k = i * 2 + 1; k < length; k = k * 2 + 1) { // 从i结点的左子结点开始,也就是2i+1处开始if (k + 1 < length && arr[k] < arr[k + 1]) { // 如果左子结点小于右子结点,k指向右子结点k++;}if (arr[k] > temp) { // 如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)arr[i] = arr[k];i = k;} else {break;}}arr[i] = temp; // 将temp值放到最终的位置}public static void swap(int[] arr, int a, int b) {int temp = arr[a];arr[a] = arr[b];arr[b] = temp;}
}五、方法评价
时间复杂度:堆排序的时间复杂度是O(nlogn),其中n是待排序数组的长度。构建堆的时间复杂度是O(n),每次调整堆的时间复杂度是O(logn),共需要进行n-1次调整。因此,总的时间复杂度为O(nlogn)。
空间复杂度:堆排序的空间复杂度为O(1),即不需要额外的空间进行排序。
稳定性:堆排序是一种不稳定的排序算法。在交换堆顶和末尾元素的过程中,可能会改变相同元素的相对顺序。
原地排序:堆排序是一种原地排序算法,即不需要额外的辅助空间。
 结语
结语
容易实现的那不叫梦想
轻言放弃的算不上努力
想成功,先发疯,不顾一切向前冲
!!!