文章目录
- 1 动机
- 2 方法
- 3 实验
1 动机
使用灵活的文本控制可以实现一些特定的概念的注入从而实现个性化的图片生成。
最经典的比如一些好玩的动漫人物的概念,SD大模型本身是不知道这些概念的,但是通过概念注入是可以实现的从而生成对应的动漫人物
两个主要的传统的实现方式
(1) Textual Inversion:容易出现过拟合概念的情况(即只看到概念,而忽视其他的prompt) 对于text embedding做注入
(2)DreamBooth:容易忽视概念(即可以看到其他prompt,不能看到概念)对于原本的扩散模型做微调
作者归因为概念嵌入对齐的错误学习,因而提出了AttnDreamBooth去解决上述的问题
2 方法
提出了AttnDreamBooth
(1)通过分别学习嵌入对齐、注意力图和不同训练阶段的主题身份来解决这些问题
(2)作者还引入了一个交叉注意力图正则化项来增强注意力图的学习。
通过结合两种方式,一个即 Textual Inversion,另一个即DreamBooth
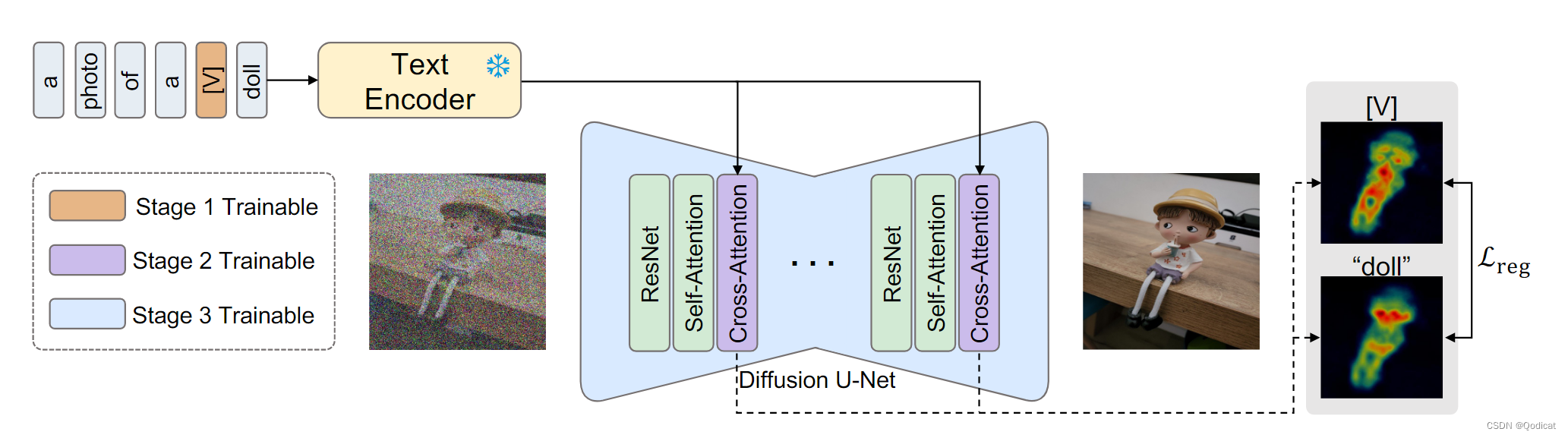
方法由三个训练阶段组成。
在第 1 阶段,优化了新概念的文本嵌入,使其嵌入与现有标记对齐。
在第 2 阶段,对交叉注意力层进行微调以细化注意力图。
在第 3 阶段,对整个 U-net 进行微调以捕获主题身份。引入了一个交叉注意力图正则化项来指导注意力图的学习。
3 实验
之后通过用户体验问卷
复杂概念评估