前段时间其实我们已经部署了大模型,并开放了对外的web接口。不过由于之前某几轮微调实验的大模型在对话时会有异常表现(例如响应难以被理解),因此我在项目上线后,监控了数据库里存储的对话记录。确定了最近一段时间部署的大模型回复一切正常后,着手写这篇有关大模型微调记录的博客。
1. 数据汇总
之前我们采用人工编写、从非结构化的文本中提取、self-instruct生成和self-QA生成的方式,搜集并生成了微调训练所需的数据集。在微调前,我们先对这些数据进行了聚合,把它整理成一个微调软件/程序能够接受的格式。格式如:
{
"instruction": xxx,
"input": xxx,
"output": xxx
}
并非每条指令都有instruction和input的内容,这部分之前的博客也说了,instruction和input的界限不是很明显。如果是分类问题的话,两者都是必须的,其他问题并非必须都要有。
数据集如下图所示:

经整理,共有如下来源:
- 《周易》古经:64卦的卦辞、爻辞原文、译文。卦爻辞分词。
- 《易传》(十翼)原文、译文。
- 现代资料:《周易译注》、《易学百科全书》卦爻辞词条。
- 经典易学典籍:《周易注》、《周易正义》、《周易本义》、《周易集解》等。
- 《周易研究》期刊1988-2023共36年的文章数据。平均一年6期,一期10篇,36年共1800篇文章。
2. lora微调:L40+LLaMA-Factory
2.1. 软硬件环境说明
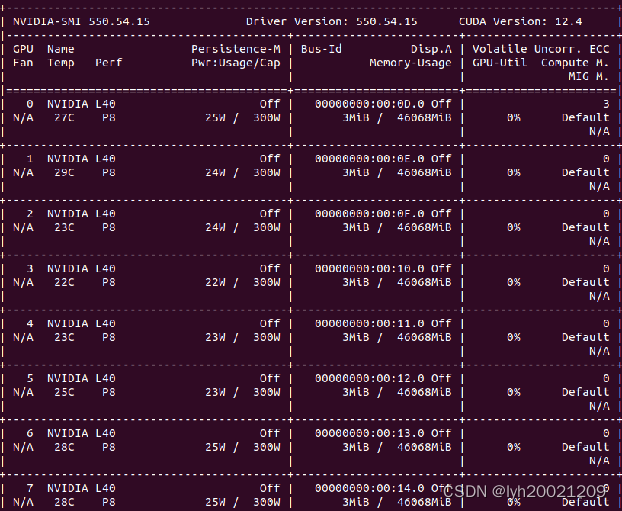
对于glm3-6b这个超参数量比较小的大模型,我们采用了学院的带有八张L40显卡的机器(导师申请的)以及开源微调软件LLaMA-Factory进行微调。
软件环境
微调工具:LLaMA-Factory

LLaMA-Factory开源软件仓库地址:
hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100+ LLMs (github.com)![]() https://github.com/hiyouga/LLaMA-Factory这个项目提供了命令行和GUI的微调工具,尤其是GUI,非常适合超参数数量在小型和中等规模参数的大模型进行微调。可以手动选择参数以及微调方式(Lora,RHLF等)
https://github.com/hiyouga/LLaMA-Factory这个项目提供了命令行和GUI的微调工具,尤其是GUI,非常适合超参数数量在小型和中等规模参数的大模型进行微调。可以手动选择参数以及微调方式(Lora,RHLF等)
服务器:Linux ubuntu发行版
CUDA:12.4
驱动版本:550.54.15
硬件环境
学院服务器,八张L40显卡。
2.2. LLaMA-Factory微调工具安装部署
根据Github仓库上的README,我们可以快速部署LLaMA-Factory
这个软件对依赖环境有所要求,如下图:
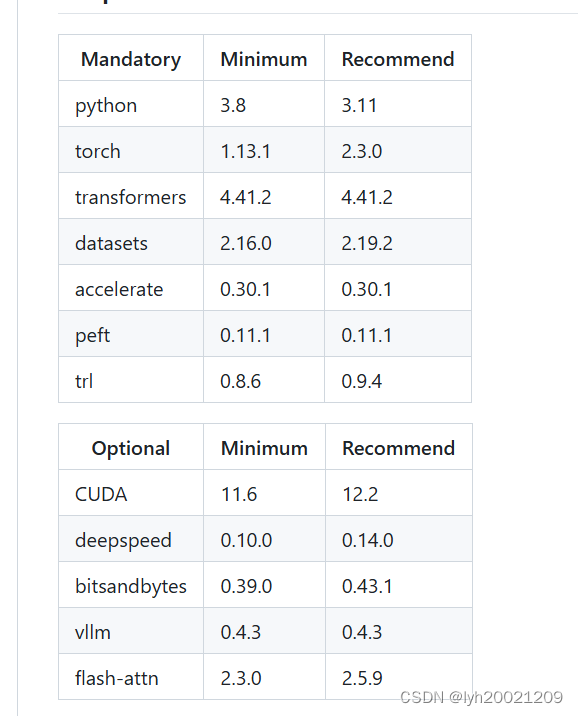
在部署软件前,我已经保证了本地的依赖环境是符合上述表格的:python 311,torch 230
拉取代码安装依赖
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
部署微调用的训练集
把之前按照Alpaca格式风格的数据集放置到data文件夹下(以json格式保存)
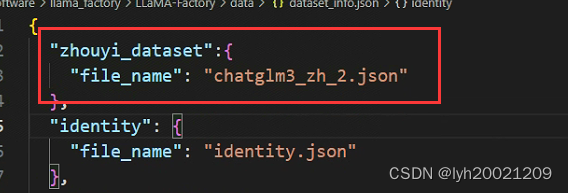
随后再到dataset_info中编辑这个新的数据集(webui和脚本都会读取这个配置文件,以获取数据集)
利用web gui微调
LLaMA-Factory提供了一套web界面来进行微调,这样我们只需要再选项卡中选择自己需要的参数就可以了,不用再在命令行拼接一堆参数选项启动脚本进行微调了。
web gui启动命令:
llamafactory-cli webui
随后你就能看到微调的gui界面,在这个界面中,我们可以选择数据集,微调方式,各种参数。
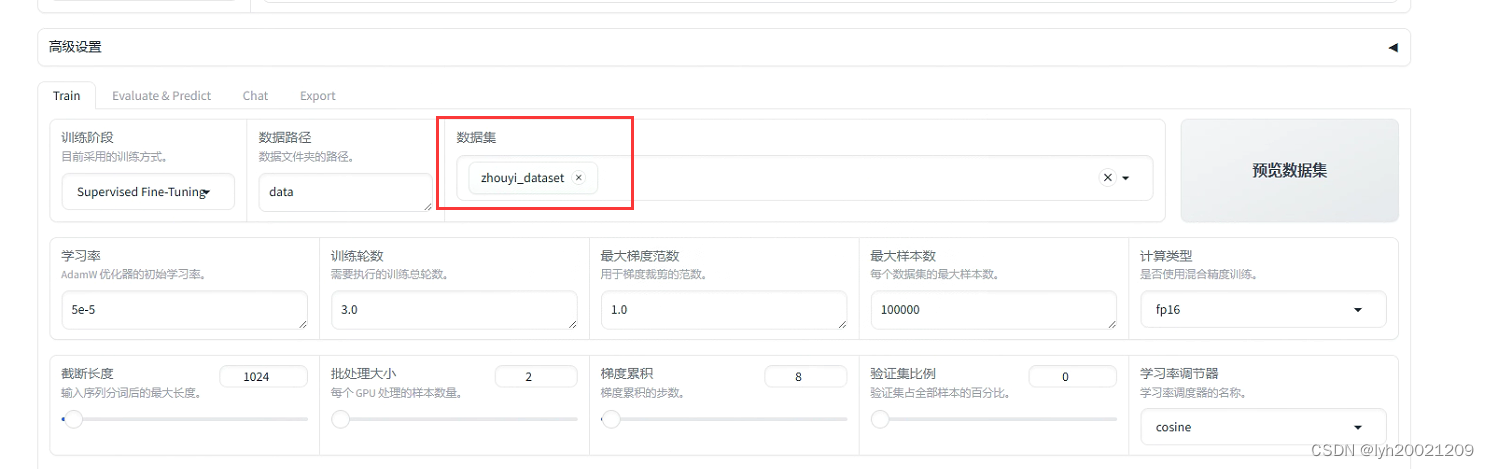
此处我就使用了我们之前配置好的数据集,同时还有其他参数需要选择。这里我用表格记录下来了。
| 微调参数/微调模型 | glm3-6b | glm3-6b | glm3-6b | glm3-6b | glm3-6b | glm3-6b |
| 学习率 | 5e-5 | 5e-5 | 5e-5 | 5e-5 | 5e-5 | 5e-5 |
| 训练轮数 | 3 | 3 | 3 | 30 | 50 | 100 |
| 批处理大小 | 4 | 4 | 4 | 10 | 10 | 4 |
| 最大梯度范数 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 最大样本数 | 100000 | 100000 | 100000 | 100000 | 100000 | 100000 |
| 计算类型 | fp16 | fp16 | fp16 | fp16 | fp16 | fp16 |
| 截断长度 | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 |
| 梯度累计 | 8 | 8 | 8 | 8 | 8 | 8 |
| 验证集比例 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 学习率调节器 | cosine | cosine | cosine | cosine | cosine | cosine |
| 日志间隔 | 5 | 5 | 5 | 5 | 5 | 5 |
| 保存间隔 | 100 | 100 | 100 | 100 | 100 | 100 |
| 优化器 | adamw | adamw | adamw | adamw | adamw | adamw |
| LoRA秩 | 8 | 8 | 8 | 8 | 8 | 8 |
| LoRA缩放系数 | 16 | 16 | 16 | 16 | 16 | 16 |
| LoRA随机丢弃 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| GPU | L40*1 | L40*4 | L40*8 | L40*4 | L40*4 | L40*8 |
| Tran_sample/s | 1.979 | 3.876 | 14.039 | 7.032 | 9.632 | 13.948 |
| Train_step/s | 0.062 | 0.03 | 0.055 | 0.055 | 0.12 | 0.054 |
| 运行时间 | 4:48:02 | 2:27:03 | 0:37:26 | 12:10:00 | 16:26:00 | 20:26:00 |
可以看到大部分时间都是比较长的(即便用上所有8个核心),这也是后来转战华为昇腾服务器的原因之一。
这里我贴一下部分训练的epoch-loss图像:
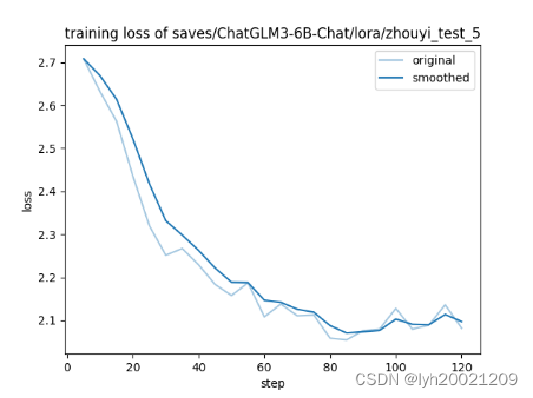
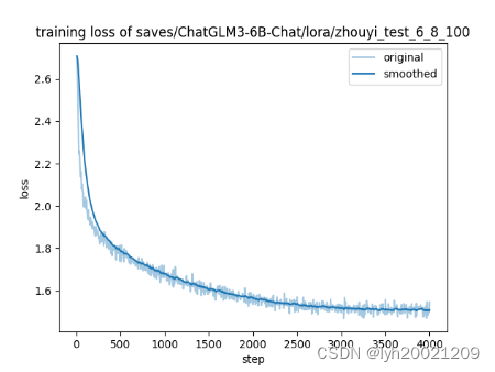
这边LLaMA-Factory是做了数据平滑去噪,在微调的指令中有个是否绘制损失函数图像的参数,选择true后绘制出来的图像就是这样,平滑的代码应该已经写到求损失函数的部分中了。loss不至于像原来那样那么震荡。同时可以看到我们的loss其实并没有降到最低就停止了epoch,所以模型有点欠拟合,这导致部分模型在基线测试是性能不够好。

在得到了模型权重文件后,我们就可以把它部署到服务器了,例如:
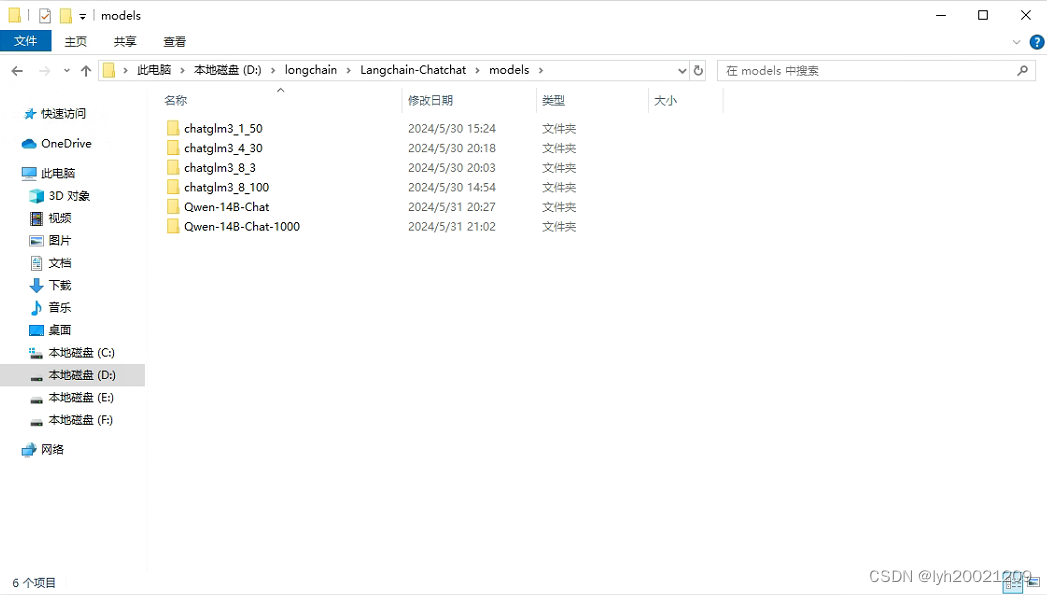
我在服务器上存放了我们微调过的大模型,每个都形如:
 其中包括了所有的权重文件与配置文件。
其中包括了所有的权重文件与配置文件。
这样我们在带着大模型启动时,选择其中一个进行启动即可,一般我都选的L40*8微调100轮的那个(虽然在之前基线测试时,表现最好的是Qwen微调1000轮的,但是我们4090显卡就24G显存,Qwen14B权重模型一个就20多G了,带不动)
lora微调原理
参考:大模型高效微调-LoRA原理详解和训练过程深入分析 - 知乎 (zhihu.com)
LoRA(Low-Rank Adaptation of LLMs),即LLMs的低秩适应,是参数高效微调最常用的方法。
LoRA的本质就是用更少的训练参数来近似LLM全参数微调所得的增量参数,从而达到使用更少显存占用的高效微调。
LoRA的核心思想是,在冻结预训练模型权重后,将可训练的低秩分解矩阵注入到的Transformer架构的每一层中,从而大大减少了在下游任务上的可训练参数量。
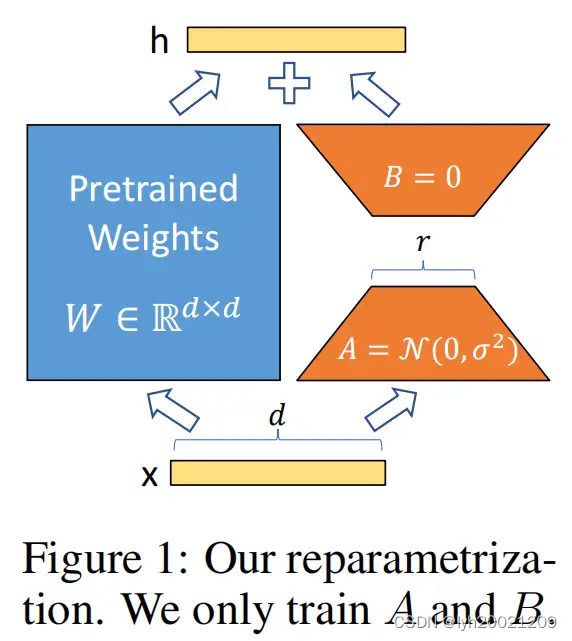
We propose Low-Rank Adaptation(LoRA), which freezes the pre trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
通常,冻结预训练模型权重,再额外插入可训练的权重是常规做法,例如Adapter。可训练的权重学习的就是微调数据的知识。但它们的问题在于,不仅额外增加了参数,而且还改变了模型结构。这会导致模型训练、推理的计算成本和内存占用急剧增加,尤其在模型参数需在多GPU上分布式推理时(这越来越常见)。
深度网络由大量Dense层构成,这些参数矩阵通常是满秩的。
相关工作表明,When adapting to a specific task, 训练学到的过度参数化的模型实际上存在于一个较低的内在维度上(高维数据实际是在低维子空间中)

LoRA就假设LLM在下游任务上微调得到的增量参数矩阵Δ𝑊是低秩的(肯定不是满秩),即存在冗余参数或高度相关的参数矩阵,但实际有效参数是更低维度的。LoRA遂设想,对全参数微调的增量参数矩阵Δ𝑊进行低秩分解近似表示(即对参数做降维)。
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach.
这样训练Δ𝑊的低秩分解近似参数矩阵,效果上相比其他PEFT方法不会打什么折扣,而且还能在推理时不增加额外开销。
LoRA allows us to train some dense layers in a neural network indirectly by optimizing rank decomposition matrices of the dense layers’change during adaptation instead, while keeping the pre-trained weights frozen
3. 华为昇腾服务器微调:MindFormers+ModelLink
华为提供了一套一体化的、全流程的大模型微调工具MindFormers+ModelLink
- MindFormers(MindSpore): 华为自家提供的一个构建大模型训练、微调、评估、推理、部署的全流程开发套件
- ModelLink(Pytorch+Megatron) ModelLink旨在为华为昇腾芯片上的大语言模型提供端到端的解决方案, 包含模型,算法,以及下游任务。
ModelLink也是开源的:
ModelLink: 昇腾大模型仓库 (gitee.com)![]() https://gitee.com/ascend/ModelLinkModelLink对于不同大模型的微调步骤,专门分门别类地出了一套教程,这里我以Qwen1-14B为例:
https://gitee.com/ascend/ModelLinkModelLink对于不同大模型的微调步骤,专门分门别类地出了一套教程,这里我以Qwen1-14B为例:
首先克隆仓库到本地服务器:
git clone https://gitee.com/ascend/ModelLink.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../ModelLink/ cd .. cd ModelLink mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt
随后搭建基本环境(首先保证有conda环境,安装conda网上很多教程了,我就不多写一遍了)
# python3.8 conda create -n test python=3.8 conda activate test# 安装 torch 和 torch_npu pip install torch-2.1.0-cp38-cp38m-manylinux2014_aarch64.whl pip install torch_npu-2.1.0*-cp38-cp38m-linux_aarch64.whl pip install apex-0.1_ascend*-cp38-cp38m-linux_aarch64.whl# 安装加速库 git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed git checkout 2b0edd2 pip install -r requirements.txt pip install -e . cd ..# 安装其余依赖库 pip install -r requirements.txt
下载预训练权重和词表:
mkdir ./model_from_hf/Qwen-14B/ cd ./model_from_hf/Qwen-14B/ wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/cache_autogptq_cuda_256.cpp wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/cache_autogptq_cuda_kernel_256.cu wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/config.json wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/configuration_qwen.py wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/cpp_kernels.py wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/generation_config.json wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00001-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00002-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00003-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00004-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00005-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00006-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00007-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00008-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00009-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00010-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00011-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00012-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00013-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00014-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model-00015-of-00015.safetensors wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/model.safetensors.index.json wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/modeling_qwen.py wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/qwen.tiktoken wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/qwen_generation_utils.py wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/tokenization_qwen.py wget https://huggingface.co/Qwen/Qwen-14B/resolve/main/tokenizer_config.json cd../../
修改modelling_qwen.py文件第39行,将:
SUPPORT_FP16 = SUPPORT_CUDA and torch.cuda.get_device_capability(0)[0] >= 7
改为:
SUPPORT_FP16 = True
数据集我们有,直接拉到服务器上就可以,放到./dataset(相对路径)下即可
随后利用华为ModelLink提供的process_data.py脚本进行数据处理
python ./tools/preprocess_data.py \ --input ./dataset/datasetQA_final.jsonl \ --tokenizer-name-or-path ./model_from_hf/Qwen-14B-Chat/ \ --output-prefix ./dataset/Qwen-14B-Chat-modelling/alpaca \ --tokenizer-type PretrainedFromHF \ --workers 4 \ --log-interval 1000 \ --handler-name GeneralInstructionHandler \ --append-eod \ --tokenizer-kwargs 'eos_token' '<|endoftext|>' 'pad_token' '<|extra_0|>'
![]()
随后利用其提供的预训练脚本进行训练
最后,将训练结束后的权重格式从megatron转换为safetensors格式(不然不能用)
python ./tools/checkpoint/convert_ckpt.py --model-type GPT --loader megatron --saver megatron --save-model-type save_huggingface_qwen --target-tensor-parallel-size 8 --target-pipeline-parallel --load-dir ./ckpt/Qwen-14B-Chat-JuDou/ --save-dir ./model_from_hf/Qwen-14B-Chat/ --add-qkv-bias
最终得到最后训练完的权重文件

3.2. 微调环境
软件环境
华为服务器宿主机OS:kylinSP3
容器:ubuntu22.04
cann:8,0RC1
驱动版本:24.1.rc1
硬件环境
Atlas800T A2(910b)*8

3.3. 微调参数
Epoch:1000
Time:11422s(3:10:22)
Time/epoch(每轮时长):大概11000ms
速度等性能方面相较L40和H800有较大提升,并且Qwen14B 1000轮全微调是我们微调出来性能最优秀的大模型(唯一美中不足的就是实在太大了没法部署到仅搭载1块4090的服务器上去)