在MySQL的索引世界中,性能优化一直是开发者们关注的焦点。而索引,作为提升查询速度的关键技术之一,是非常重要的。索引根据存储类型可以分为聚簇索引(聚集)与非聚簇索引(非聚集),它们决定了数据在磁盘上的存储方式和查询时的访问路径。本文将带你深入了解这两种索引类型,用最简单的语言解释它们的工作原理和应用场景。
聚簇索引:

想象一下,你有一个书架,上面按照书名的字母顺序排列了所有的书籍。当你想找到某本书时,你只需要按照字母顺序查找,很快就能找到。这个书架就相当于数据库中的聚簇索引。
在聚簇索引中,数据实际上就是按照索引的顺序存储在磁盘上的。也就是主键与数据在一起并存储在磁盘上。类似书本就是数据、书名类似主键,它们在一起并放置在书架上。当然这里的主键更准确应该是书的编号。
工作原理:
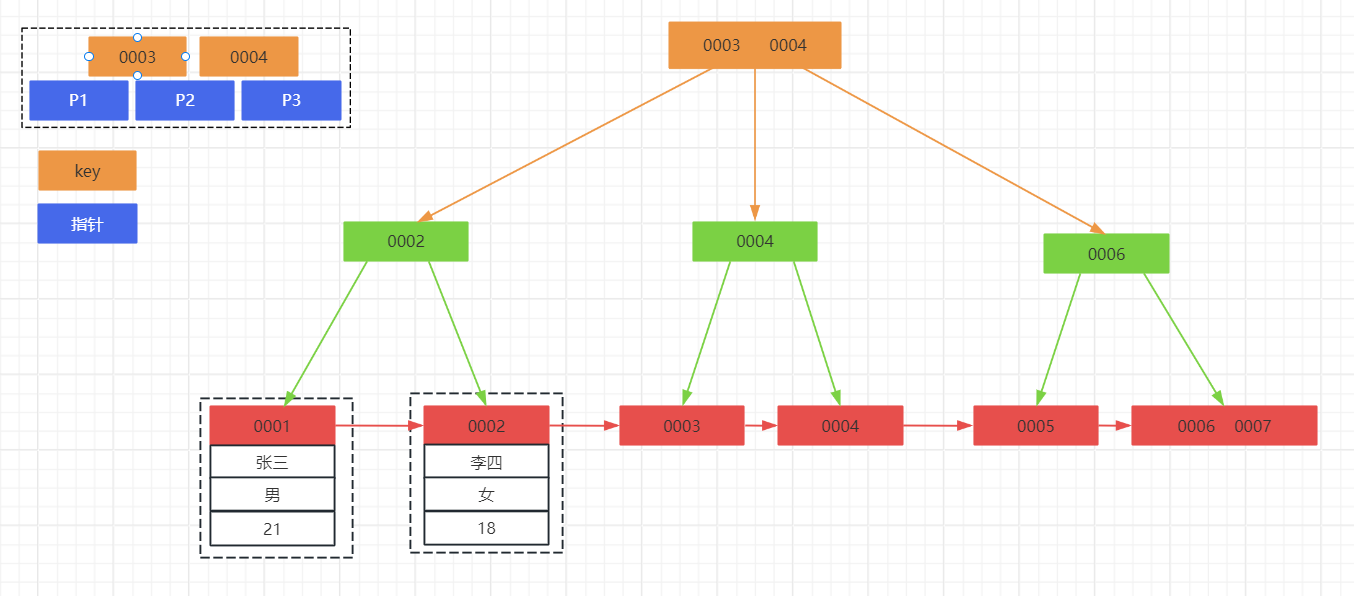
聚集索引的叶子节点直接存储表的实际数据行,也就是数据行的物理存储顺序与索引的逻辑顺序是一致的。因此,当你通过主键进行查询时,MySQL可以直接定位到数据行所在的物理位置,大大提高了查询效率。
- 关键字(Keys):用于维护树中数据顺序的标识符。
- 子节点指针(Child Pointers):指针指向节点的子节点。在B+树中,每个非叶子节点的子节点指针数量总是比关键字的数量多一个。
非聚簇索引:
再想象一下,你有一个目录,类似的里面记录了书架上每本书的位置哪一排、哪一层。当你想找到某本书时,你先查找目录,找到书的实际位置,然后去书架上取书。这个笔记本就相当于数据库中的非聚簇索引。
其实还有个例子也非常形象,就是新华字典。

新华字典是按照拼音或部首来组织汉字的,每个字都有一个对应的索引项,告诉你这个字在字典中的具体页码。当你想要查找一个字时,你可以先查看字典的目录,找到这个字的页码,然后直接翻到那一页查找。在这个过程中,索引项并不包含字的完整解释,只是提供了一个指向字典正文中字的位置的“指针”。
在MySQL中,非聚簇索引就是这样的“新华字典”,它的叶子节点存储的是索引列的值和对应数据行的指针,而不是数据行本身。
工作原理:
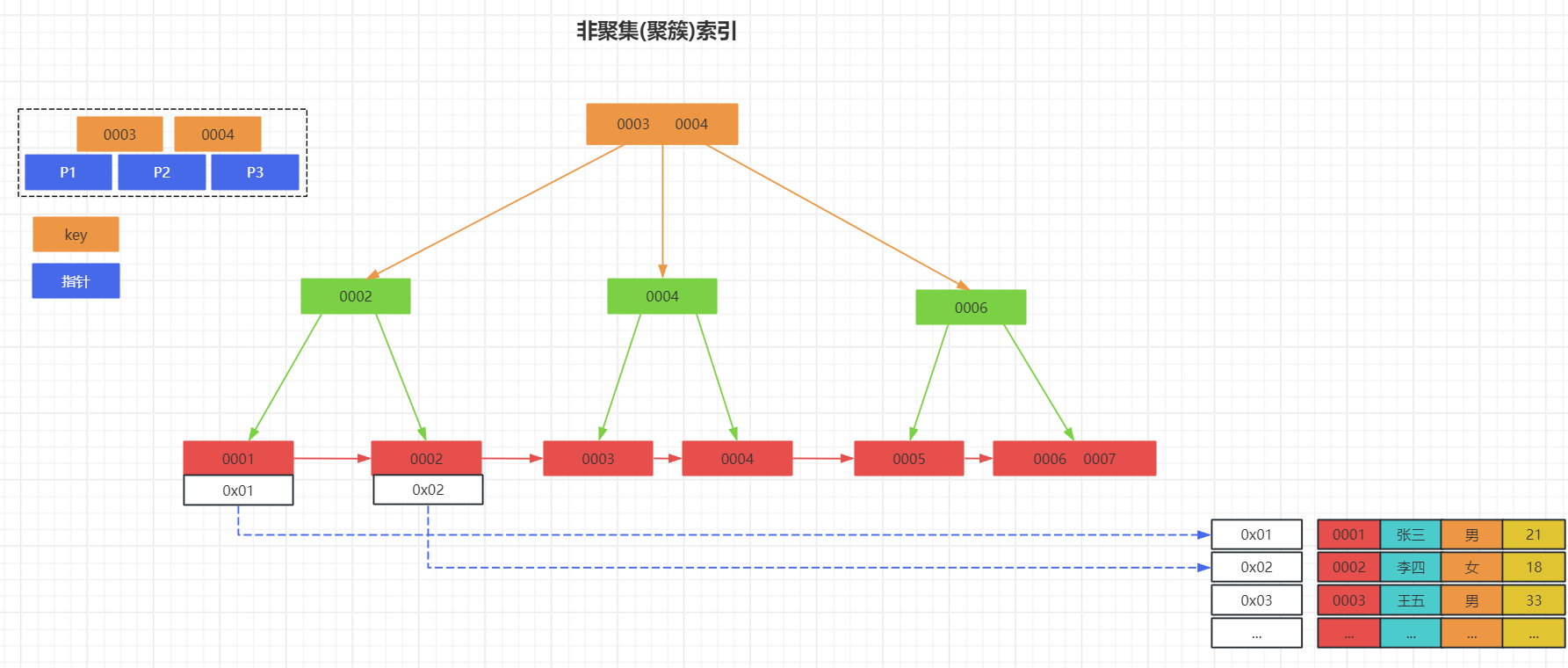
非聚集索引的叶子节点不直接存储数据行,而是存储索引键值和指向数据行位置的逻辑指针。当你通过非聚簇索引进行查询时,MySQL首先在索引中找到匹配的索引项,然后根据索引项中的指针去数据表中获取完整的数据行。这个过程通常被称为“回表”。
MySQL是如何实现聚簇/非聚簇索引的?
存储引擎
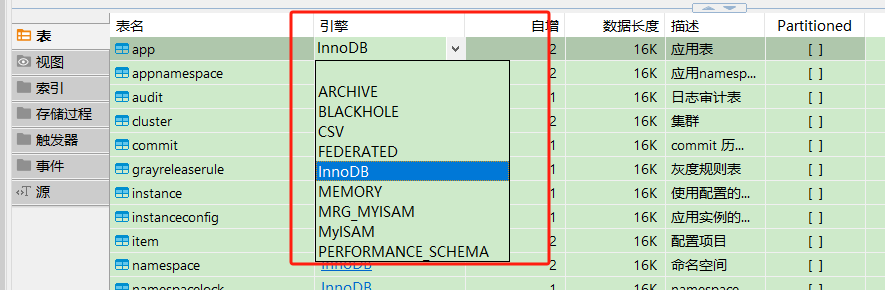
聚簇索引和非聚簇索引的实现依赖于存储引擎。不同的存储引擎有不同的实现方式。最常用的存储引擎是InnoDB和MyISAM,它们分别实现了聚簇索引和非聚簇索引。当然除了最常用的存储引擎外MySQL还支持其它的存储引擎。
数据结构
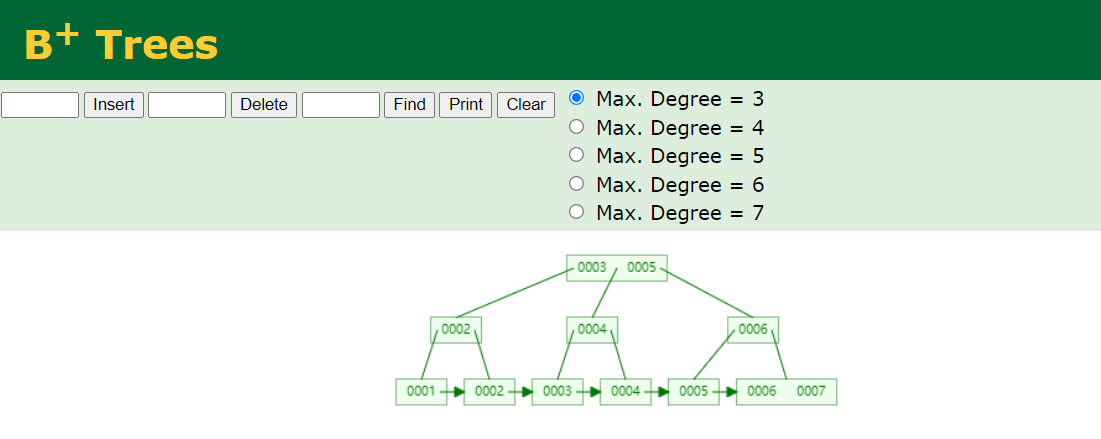
- InnoDB存储引擎
InnoDB是MySQL默认的存储引擎之一,它使用B+树作为索引结构。InnoDB的聚簇索引(Clustered Index)实际上是表数据本身,它的叶节点包含了行数据。
- MyISAM存储引擎
MyISAM是MySQL的另一个存储引擎,它同样使用B+树作为索引结构。MyISAM的索引文件和数据文件是分开的,索引仅包含指向数据的指针。

![[图解]建模相关的基础知识-12](https://img-blog.csdnimg.cn/direct/58c970fd961f4a1ea528b85fc52fd422.png)