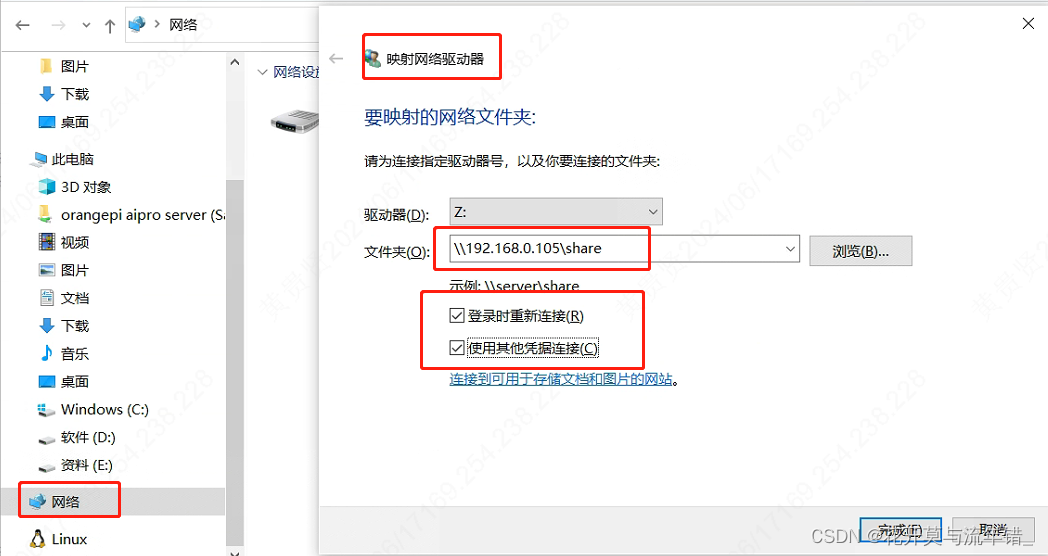
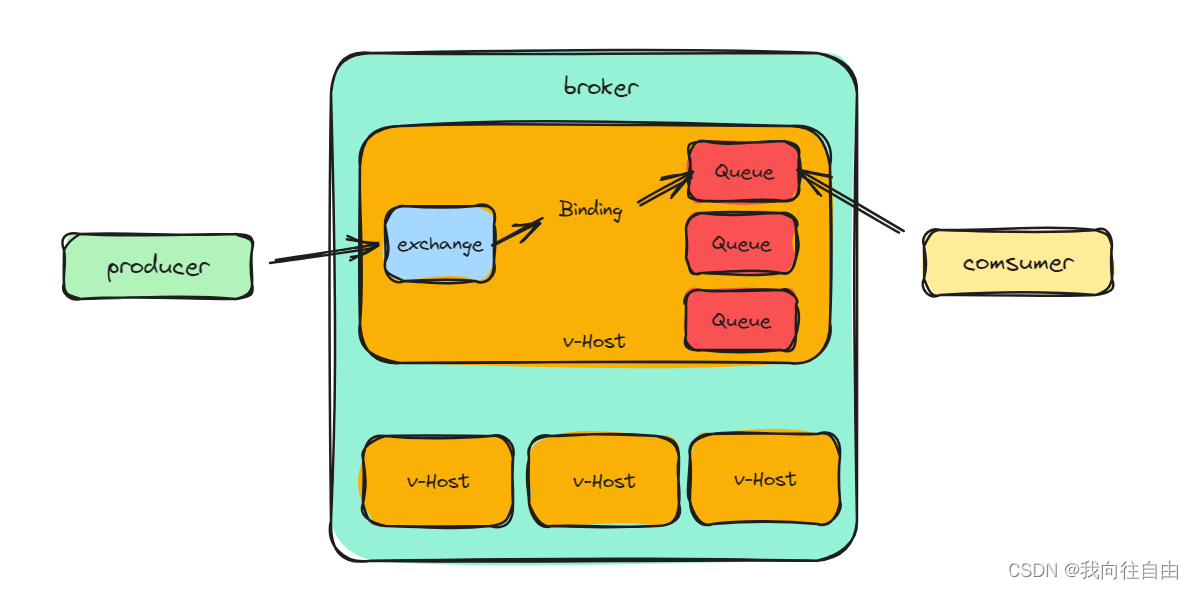
复制
定制的复制方案
分离功能
许多应用都混合了在线事务处理(OLTP)和在线数据分析(OLAP)的查询。OLTP查询比较短并且是事务型的。OLAP查询则通常很大,也很慢,并且不要求绝对最新的数据。这两种查询给服务器带来的负担完全不同,因此它们需要不同的配置,甚至可能使用不同的存储引擎或者硬件。
一个常见的办法是将OLTP服务器的数据复制到专门为OLAP工作负载准备的备库上。这些备库可以有不同的硬件、配置、索引或者不同的存储引擎。如果决定在备库上执行OLAP查询,就可能需要忍受更大的复制延迟或者降低备库的服务质量。这意味着在一个非专用的备库上执行一些任务时,可能会导致不可接受的性能,例如执行一条长时间运行的查询。无须做一些特殊的配置,除了需要选择忽略主库上的一些数据,前提是能获得明显的提升。即使通过复制过滤器过滤掉一小部分的数据也会减少IO和缓存活动。
数据归档
可以在备库上实现数据归档,也就是说可以在备库上保留主库上删除过的数据,在主库上通过delete语句删除数据是确保delete语句不传递到备库就可以实现。有两种通常的办法:一种是在主库上选择性地禁止二进制日志,另一种是在备库上使用replicate_ignore_db规则(是的,两种方法都很危险)
第一种方法需要先将SQL_LOG_BIN设置为0,然后再进行数据清理。这种方法的好处是不需要在备库进行任何配置,由于SQL语句根本没有记录到二进制日志中,效率会稍微有所提升。最大缺点也正因为是没有将在主库的修改记录下来,因此无法使用二进制日志来进行审计或者做按时间点的数据恢复。另外还需要SUPER权限。
第二种办法是在清理数据之前对主库上特定的数据库使用USE语句。例如,可以创建一个名为purge的数据库,然后在备库的my.cnf文件里设置replicate_ignore_db=purge并重启服务器。备库将会忽略使用了use语句指定的数据库。这种方法没有第一种方法的缺点,但有另一个小小的缺点:备库需要去读取它不需要的事件。另外,也可能有人在purge数据库上执行非清理查询,从而导致备库无法重放该事件.
Percona Toolkit中的pt-arciver支持以上两种方式
将备库用作全文检索
许多应用要求合并事务和全文检索。然而仅有MyISAM支持全文检索,但是MyISAM不支持事务(在MySQL5.6有一个实验室预览版本实现了InnoDB的全文检索,但尚未GA).一个普遍的做法是配置一台备库,将某些表设置为MyISAM存储引擎,然后创建全文索引并执行全文检索查询。这避免了在主库上同时使用事务型和非事务型存储引擎所带来的复制问题,减轻了主库维护全文索引的负担。
只读备库
x许多机构选择将备库设置为只读,以防止在备库进行的无意识修改导致复制中断。可以通过设置read_only选项来实现。它会禁止大部分写操作,除了复制线程和拥有超级权限的用户以及临时表操作。只要不给也不应该普通用户超级权限,这应该是很完美的方法。
模拟多主库复制


当前MySQL不支持多主库复制(一个备库拥有多个主库)。但是可以通过把一台备库轮流指向多台主库的方式来模拟这种结构。例如,可以先将备库指向主库A,运行片刻,再将其指向主库B并运行片刻,然后然后再次切换回主库A.这种办法的效果取决于数据以及两台主库导致备库所需完成的工作量。如果主库的负载很低,并且主库之间不会产生更新冲突,就会工作得很好。
需要做一些额外的工作来为每个主库跟踪二进制日志坐标。可能还需要保证备库的IO线程在每一次循环提取超过需要的数据,否则可能会因为每次循环反复地提取和抛弃大量数据导致主库地网络流量和开销明显增大。
还可以使用主-主(或者环形)复制结构以及使用blackhole存储引擎表地贝克来进行模拟,如图所示
在这种配置中,两台主库拥有自己的数据,但也包含了对方的表,但是对方的表使用blackhole存储引擎以避免在其中存储实际数据。备库和其中任意一个主库相连都可以,备库不适用blackhole存储引擎,因此其对两个主库而言都是有效的。
事实上并不一定需要主-主拓扑结构来是西安,可以简单地将server1复制到server2,再从server2复制到备库。如果在server2上为从server1复制的数据使用blackhole存储引擎,就不会包含任何server1的数据,如图所示.这些配置方法常常会碰到一些常见的问题,例如,更新冲突或建表时明确指定存储引擎。另外一个选择是使用Continuent的Tungsten Replicator
创建日志服务器
使用MySQL复制的另一种用途就是创建没有数据的日志服务器,它唯一的目的就是更加容易重放并且/或者过滤二进制日志事件。它对崩溃后重启复制很有帮助。同时对基于时间点的恢复也很有帮助。假设有一组二进制日志或终极日志——可能从备份或者一台崩溃的服务器上获取——希望能够重放这些日志中的事件,可以通过mysqlbinlog工具从其中提取出事件,但更加方便和高效的方法是配置一个没有任何数据的MySQL实例并使其认为这些二进制日志是它拥有的。如果只是临时需要,可以获得一个MySQL沙箱脚本来创建日志服务器。因为无须执行二进制日志,日志服务器也就不需要任何数据。它的目的仅仅是将数据提供给别的服务器(但复制账户还是需要的)。
我们来看看该策略是如何工作的.假设日志被命名为somelog-bin.000001、somelog-bin.000002,等等,将这些日志放到日志服务器的日志文件夹中,假设为/var/log/mysql。然后在启动服务器前编辑my.cnf文件,如下所示:
log_bin=/var/log/mysql/somelog-bin
log_bin_index=/var/log/mysql/somelog-bin.index
服务器不会自动发现日志文件,因此还需要更新日志的索引文件。下面这个命令可以在类UNIX系统上完成(明确地使用/bin/ls以避免启用通用别名,它们会为终端着色添加转义码):
/bin/ls -1 /var/log/mysql/somelog-bin.[0-9]* > /var/log/mysql/somelog-bin.index
确保运行MySQL的账户能够读写日志索引文件。现在可以启动日志服务器并通过SHOW MASTER LOGS命令来确保其找到日志文件。
为什么使用日志服务器比用mysqlbinlog来实现恢复更好呢?有以下几个原因:
- 1.复制作为应用二进制日志的方法已经被大量的用户所测试,能够证明是可行的。mysqlbinlog并不能确保像复制那样工作,并且可能无法正确生成二进制日志中的数据更新
- 2.复制的速度更快,因为无须将语句从日志导出来并传送给MySQL
- 3.可以很容易观察到复制过程
- 4.能够更方便处理错误。例如,可以跳过执行失败的语句
- 5.更方便过滤复制事件
- 6.有时候mysqlbinlog会因为日志记录格式更改而无法读取二进制日志
复制和容量规划
x写操作通常是复制的瓶颈,并且河南使用复制来扩展写操作。当计划为系统增加复制容量时,需要确保进行了正确的计算,否则很肉感一犯一些复制相关的错误。例如,假设工作负载为20%的写以及80%的读。为了计算简单,假设有以下前提:
- 1.读和写查询包含同样的工作量。
- 2.所有的服务器是等同的,每秒能进行1 000次查询
- 3.备库和主库有同样的性能特征
- 4.可以把所有的读操作转移到备库
如果当前有一个服务器能支持每秒1 000次查询,那么应该增加多少备库才能处理当前两倍的负载,并将所有的读查询分配给备库?
看上去应该增加两个备库并将1 600次读操作平分给它们。但是不要忘记,写入负载同样增加到了400次每秒,并且无法在主备服务器之间进行分摊。每个备库每秒必须处理400次写入,这意味着每个备库写入占了40%,只能每秒为600次查询提供服务。因此,需要三台而不是两台备库来处理双倍负载。如果负载再增加已被呢?将有每秒800次写入,这时候主库还能处理,但备库的写入同样也提升到80%,这样就需要16台备库来处理每秒3 200次读查询。并且如果再增加一点负载,主库也会无法承担。
这远远不是线性扩展,查询数量增加4倍,却需要增加17倍的服务器。这说明当为单台服务器增加备库时,将很快达到投入远高于回报的地步。这仅仅是基于上面的假设,还忽略了一些事情,例如单线程的基于语句的复制常常导致备库容量小于主库。真实的复制配置比我们的理论计算还要更差。
为什么复制无法扩展写操作
糟糕的服务容量比例的根本原因是不能像分发读操作那样把写操作等同地分发到更多服务器上。换句话说,复制只能扩展读操作,无法扩展写操作。
你可能想知道到底有没有办法使用复制来增加写入能力。答案是否定的,根本不行。对数据进行分区是唯一可以扩展写入的方法。
一些人可能会想到使用主-主拓扑结构(主动-主动模式下的主-主复制)并为两个服务器执行写操作。这种配置比主备结构能支持稍微多一点的写入,因为可以再两台服务器之间共享串行化带来的开销。如果每台服务器上执行50%的写入,那复制的执行量也只有50%需要串行化。理论上讲,这比在一台机器上(主库)对100%的写入并发执行,而在另外一台机器上(备库)上对100%的写入做串行化更优。
这可能看起来很吸引人,然而这种配置还比不上单台服务器能支持的写入。一个有50%的写入被串行化的服务器性能比一台全部写入都并行化的服务器性能要低。这是这种策略不能扩展写入的原因。它只能在两台服务器间共享串行化写入的缺点。所以"链中最弱的一环"并不是那么弱,它只提供了比主动-被动复制稍微好点的性能。但是增加了很大的风险。通常不能带来任何好处