目录
- 1.冒泡排序
- 简介
- 代码
- 分析
- 2.快速排序
- 2.1霍尔版本
- 简介
- 代码
- 分析
- 2.2挖坑版本
- 2.3前后指针版本
- 2.4非递归的快排
- 思路
- 代码
什么是交换排序?
基本思想:所谓 交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
其中,冒泡排序 和 快速排序 均属于 交换排序。
1.冒泡排序
简介
略。
代码
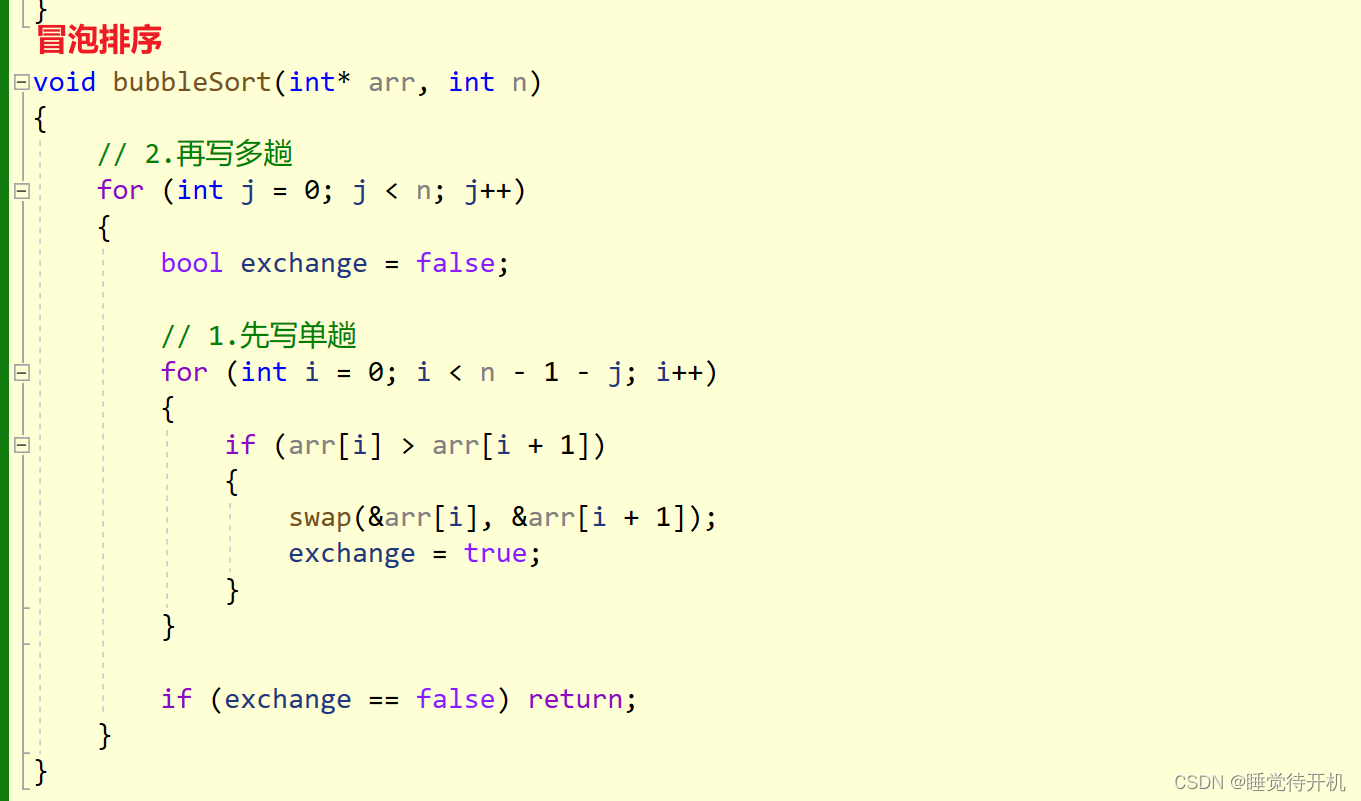
分析
最好的时间复杂度:O(N)
最差的时间复杂度:O(N^2)
2.快速排序
基本思想:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
下面是不同版本的快速排序:
2.1霍尔版本
简介
概述:快速排序属于交换排序的一种,是Hoare于1962年提出的一种二叉树结构的交换排序方法
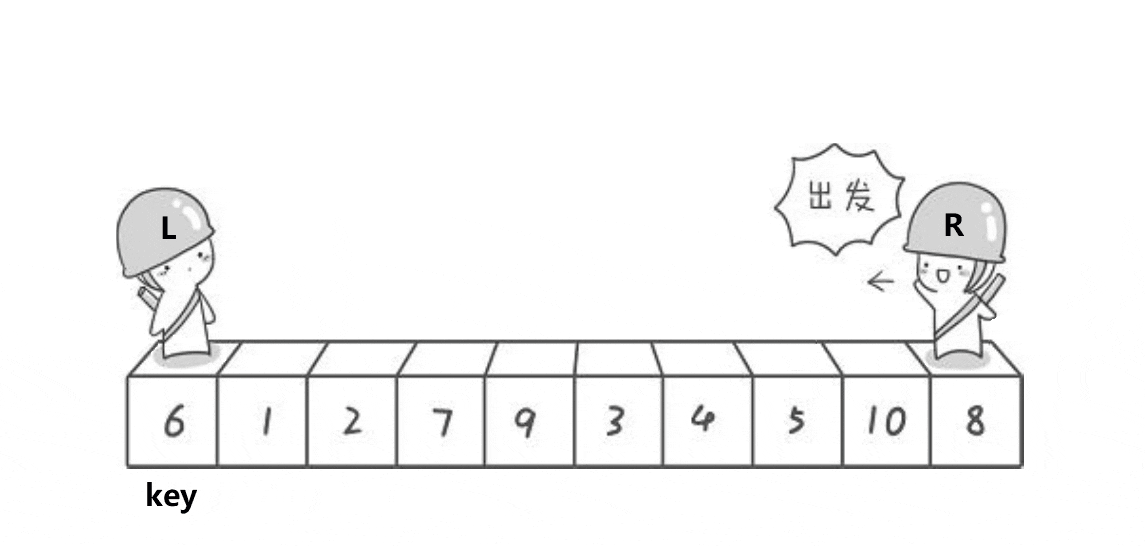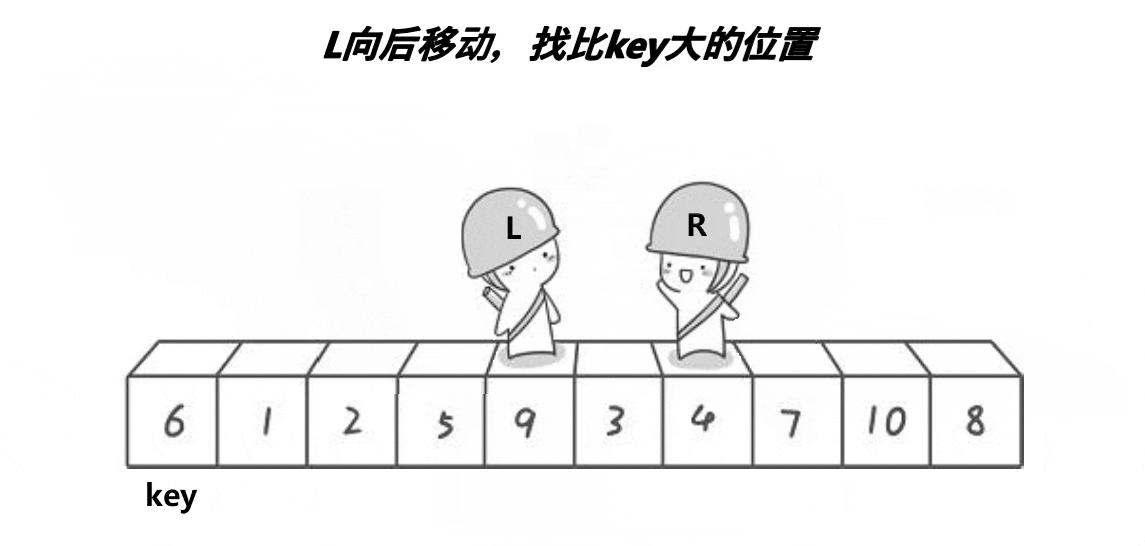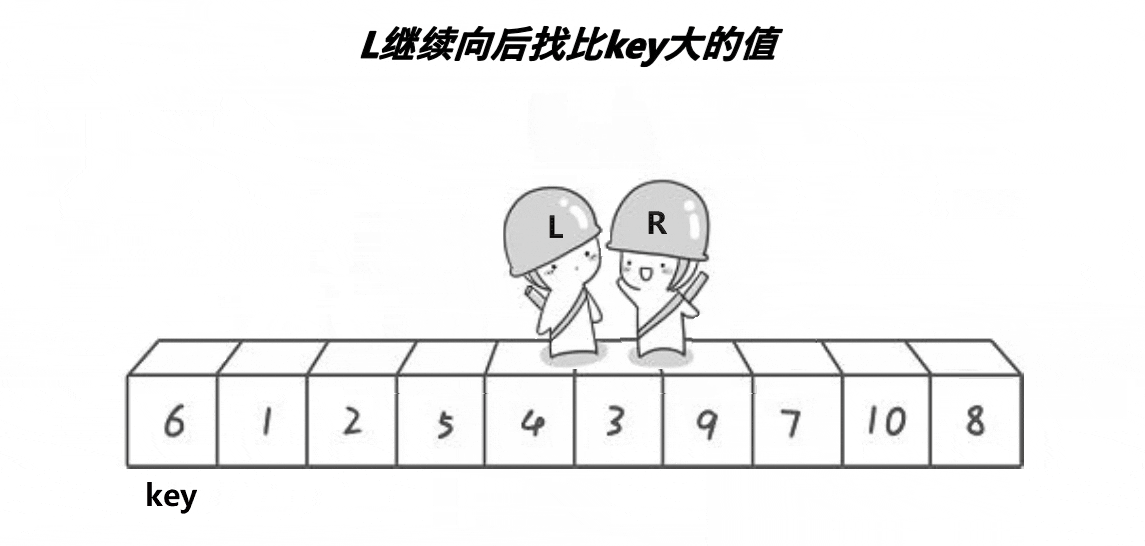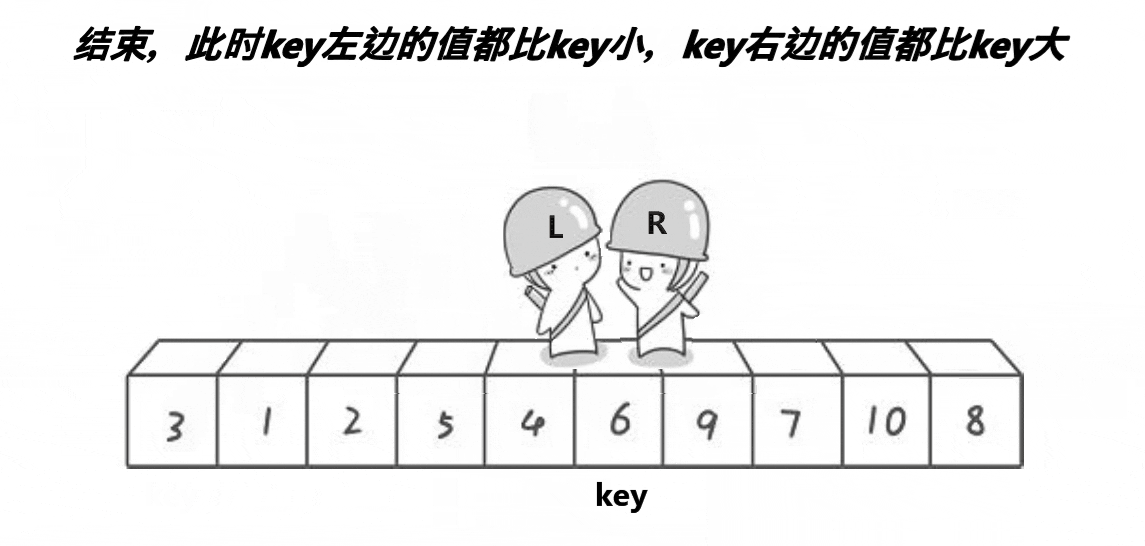
思路:
- 先选定key值,右边先走。
- 右边找小,左边找大,左右交换
- 重复第二步,直到left和right相遇与key进行交换
问:为什么相遇位置一定比key值小???
答:因为右边先走决定的。
分析:相遇有两种情况:
- right 遇 left
这时候相遇点是 left选定的位置
- 假如说left是已经走过的,left是找大的,但是找到大之后会与right交换,所以left此时是小值。 汇合点是小值。
- 假如说left一次都没有走过,right一路“滑铁卢”走到left的起始位置,left的起始位置是key值本身,汇合点是key值,key自己与自己交换没有影响。
- left 遇 right
能让left找到right,可以说明right已经找到了小,并且此时值并没有发生交换(因为右边先走!),然后此时right是小值,left遇到了right,汇合点也一定是小值。
代码
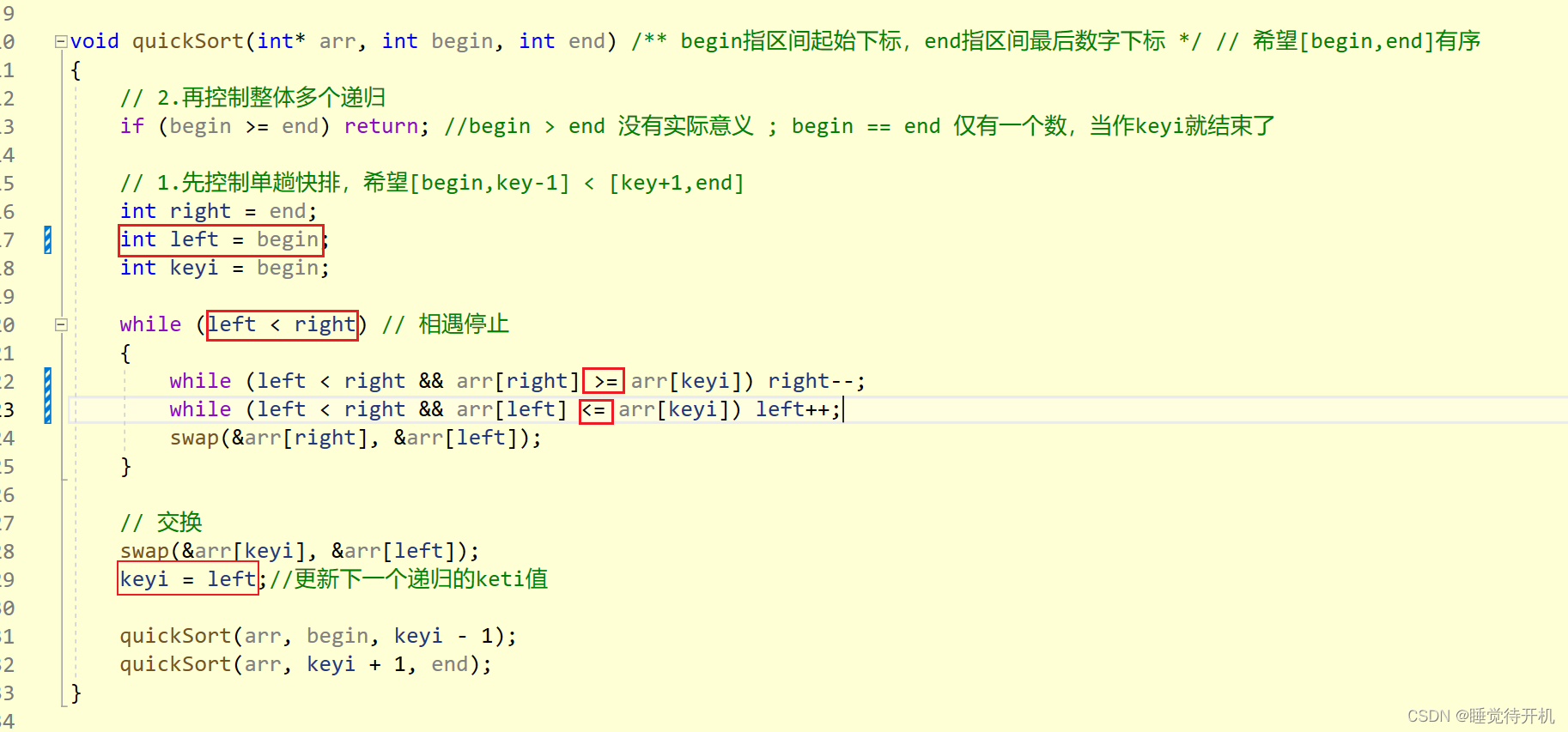
分析
这个版本的快排细节比较多,主要有下面坑:
- left = begin + 1,问题就是当原数组恰好就是有序的时候反而用了快排会被打乱顺序。
- while(left < right) 相遇即停止,写成小于等于那很容易造成越界问题。
- while(left < right && arr[right] >= arr[keyi])
- 容易造成左右指针错过问题
- 容易导致arr[left] = arr[right] = arr[keyi]死循环问题
- keyi = left;要及时更新keyi值,因为对于不同的递归下keyi值都是不同的。
快排与希尔排序:
- 快排与希尔排序是一个量级的,在数据量巨大的情况下,
- 若重复数据比较多,快排比较快一点;
- 若重复数据比较少,希尔排序更快一点。
- 然而序列有序情况下,快排很吃亏,很慢。
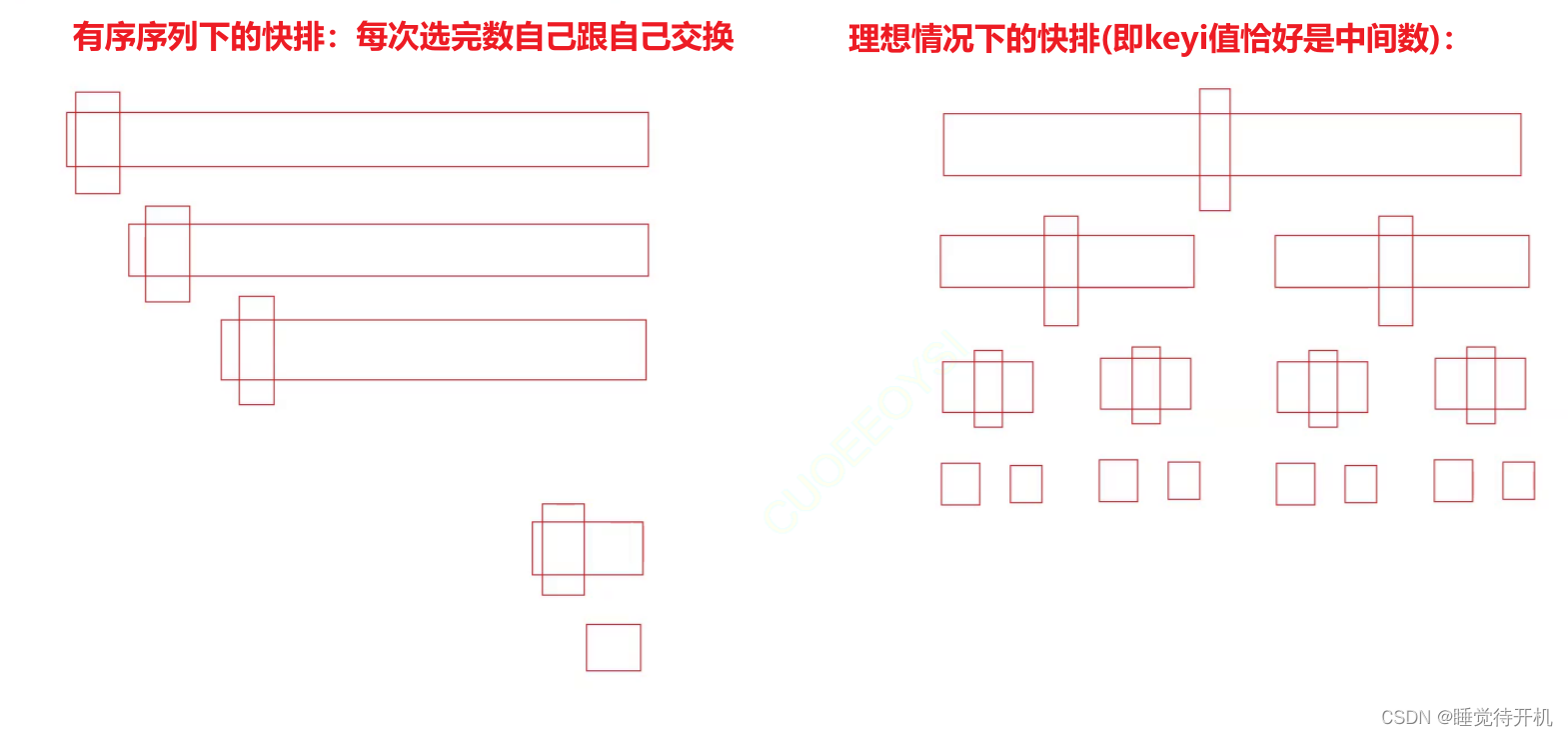
序列有序情况下,快排效率低下的原因分析及解决方法:
有序序列快排时间复杂度:O(N^2)
理想序列快排时间复杂度:O(N*logN)
总结来看,就是因为在有序序列情况下,快排每次的keyi值都是第一个数导致效率编程>了N^2的情况。注:如果是有序序列,几千的数就会因为递归深度太深而挂掉,因为要递归几千次。
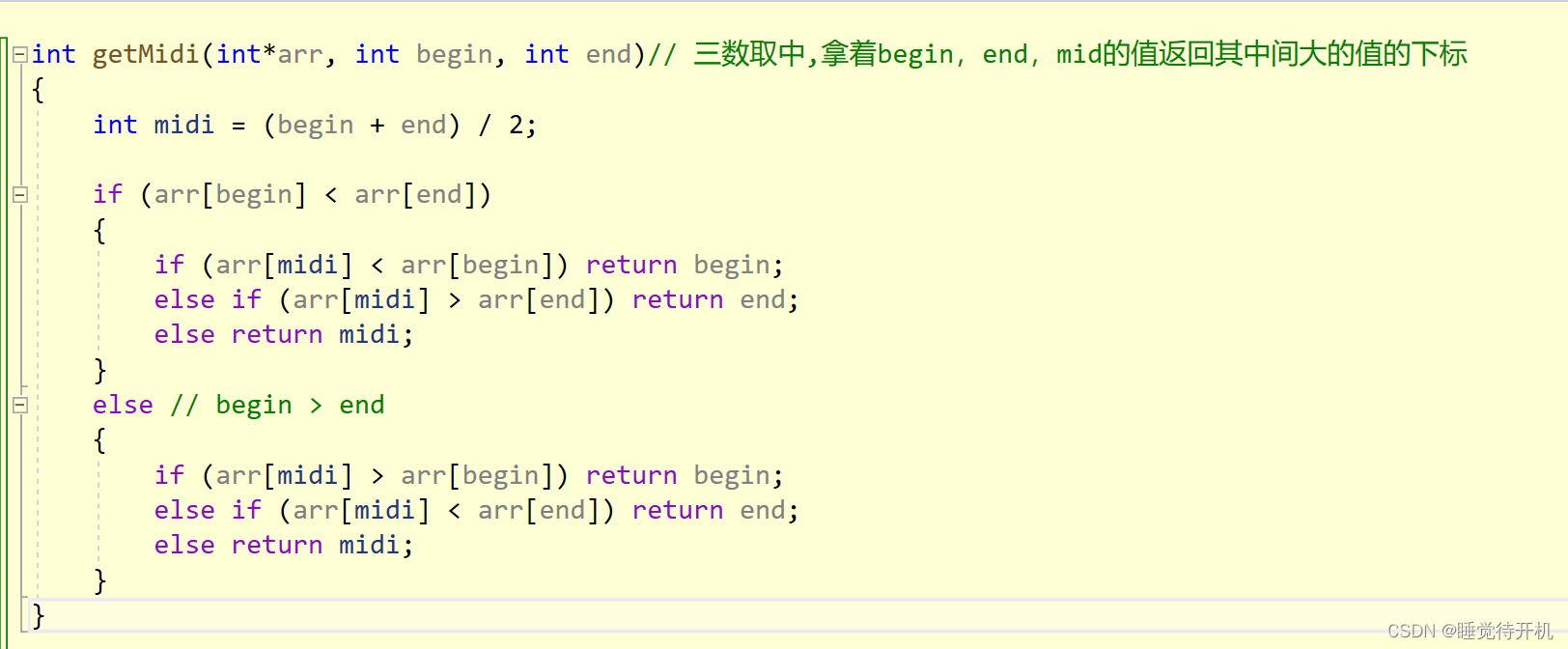
结论:所以我们把keyi值选择不固定即可,可以随机选keyi值也可以三数取中(begin,end,mid)取中间值的下标。解决方案:①三数取中 或 ②随机数选key
优化:小区间优化
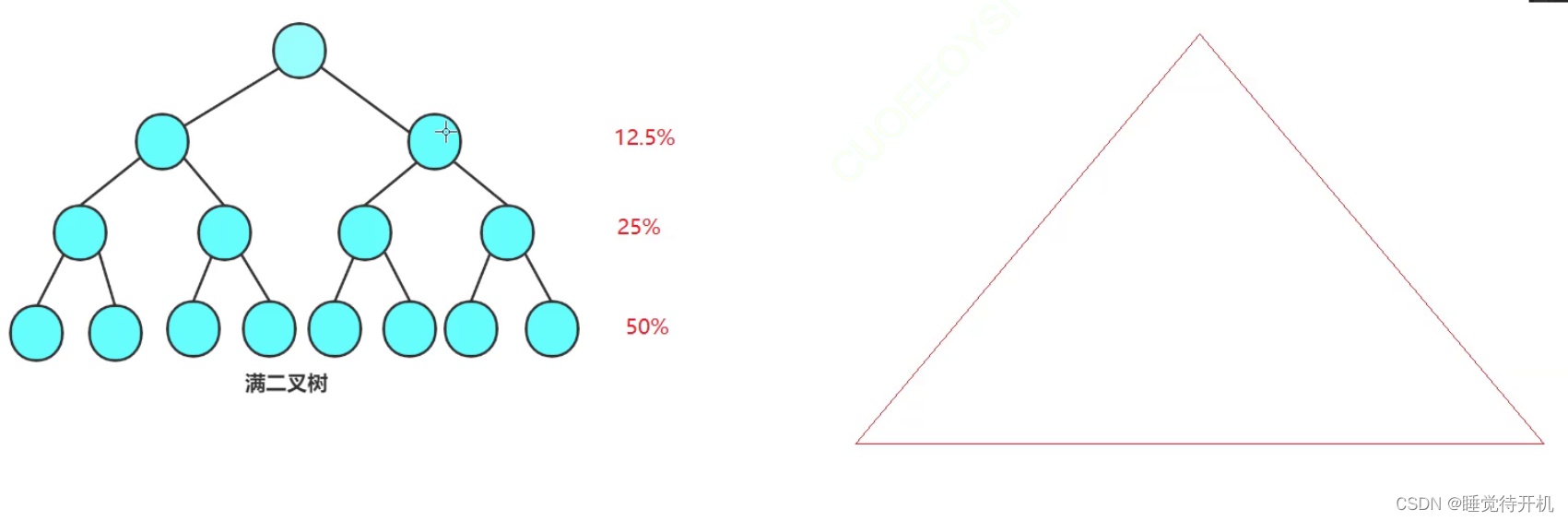
在上面所说的排序中,其中最后三排的数字占了整个序列的大概百分之八十左右,也就是说为了最后三排的数字排序 多调用栈帧百分之八十左右。
小区间优化:用插入排序进行优化(插入排序的小区间适应性更好)。
实际上,在DeBug环境下,效率大概可以略提升一些,感觉有十分之一吧。
在Release环境下,因为编译器对函数栈帧优化作用极大,以至于小区间优化的作用约等于没有,甚至不如没有小区间优化的版本。
正确代码:
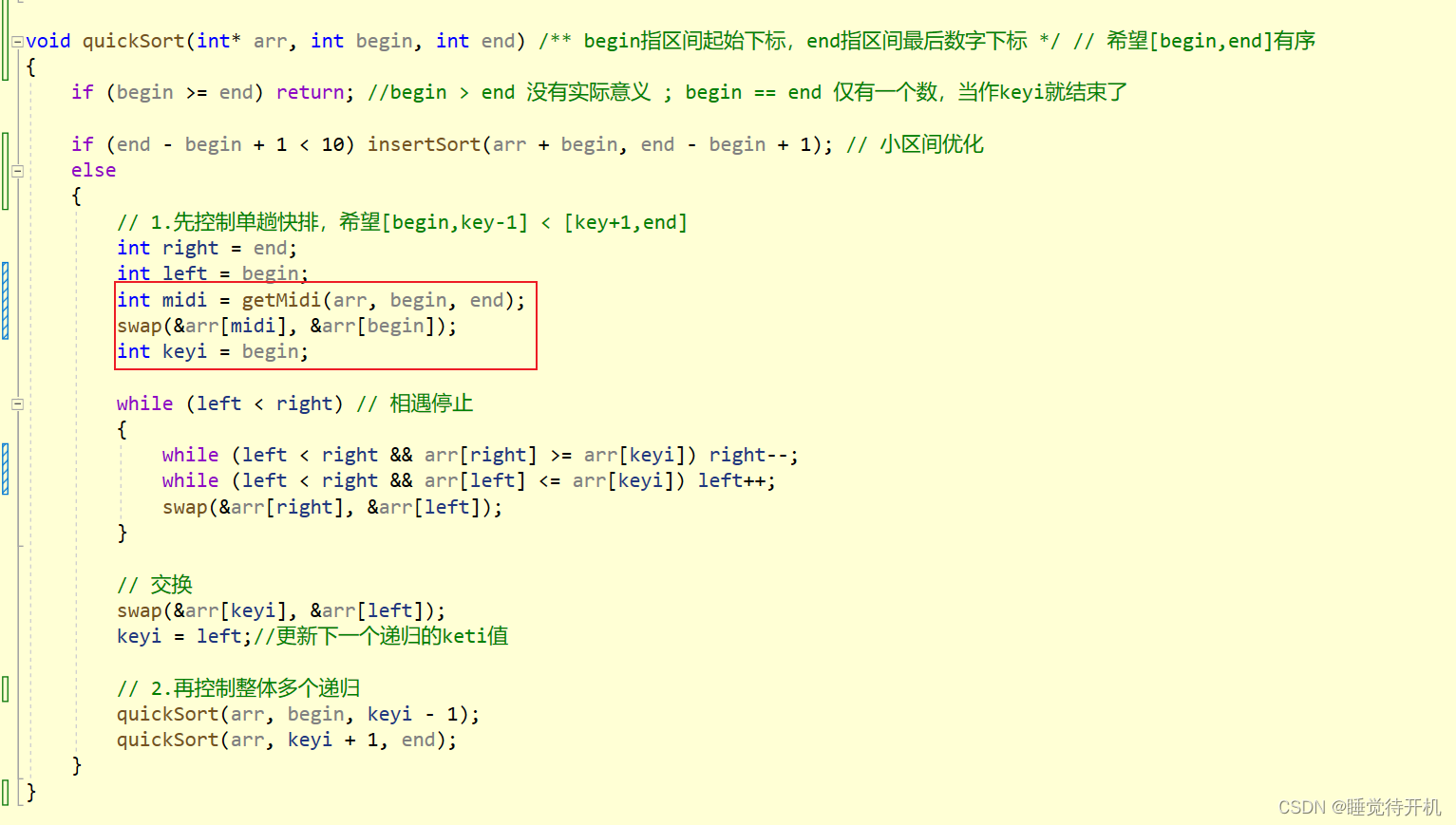
void quickSort(int* arr, int begin, int end) /** begin指区间起始下标,end指区间最后数字下标 */ // 希望[begin,end]有序
{if (begin >= end) return; //begin > end 没有实际意义 ; begin == end 仅有一个数,当作keyi就结束了if (end - begin + 1 < 10) insertSort(arr + begin, end - begin + 1); // 小区间优化else{// 1.先控制单趟快排,希望[begin,key-1] < [key+1,end]int right = end;int left = begin;int midi = getMidi(arr, begin, end);swap(&arr[midi], &arr[begin]);int keyi = begin;while (left < right) // 相遇停止{while (left < right && arr[right] >= arr[keyi]) right--;while (left < right && arr[left] <= arr[keyi]) left++;swap(&arr[right], &arr[left]);}// 交换swap(&arr[keyi], &arr[left]);keyi = left;//更新下一个递归的keti值// 2.再控制整体多个递归quickSort(arr, begin, keyi - 1);quickSort(arr, keyi + 1, end);}
}
思考:为什么这个代码会有问题?

2.2挖坑版本
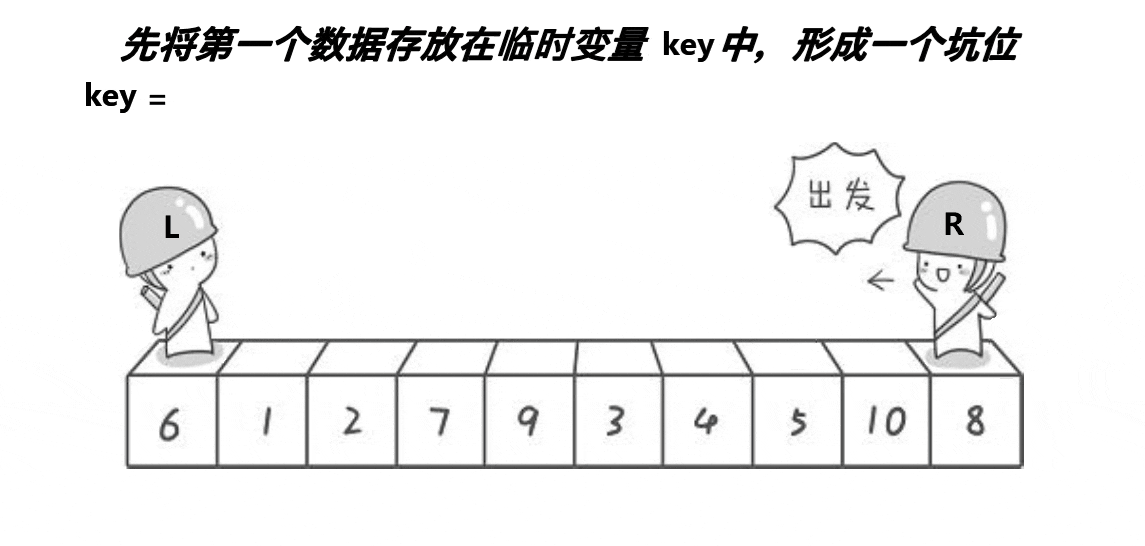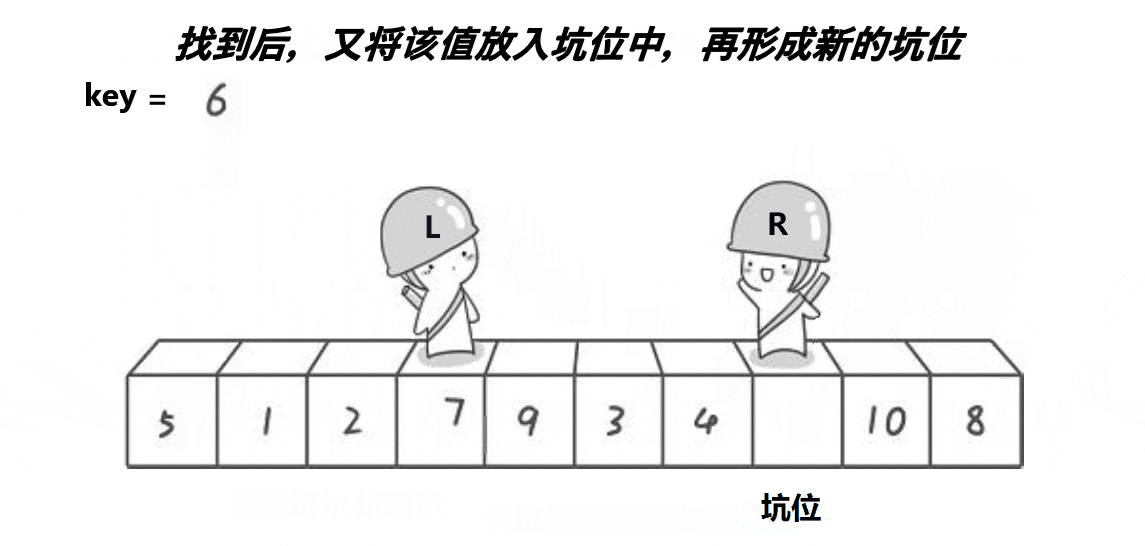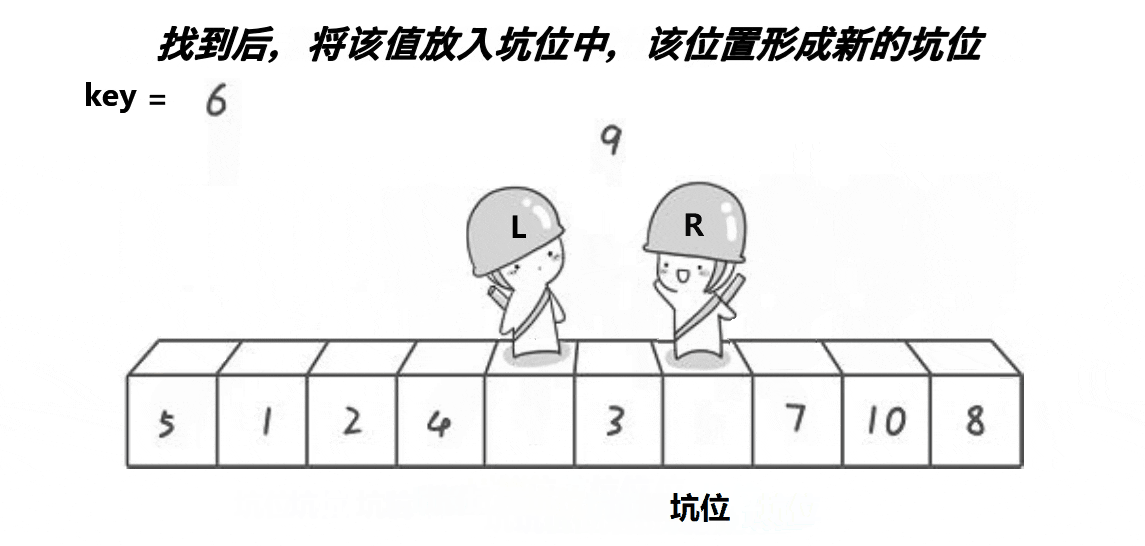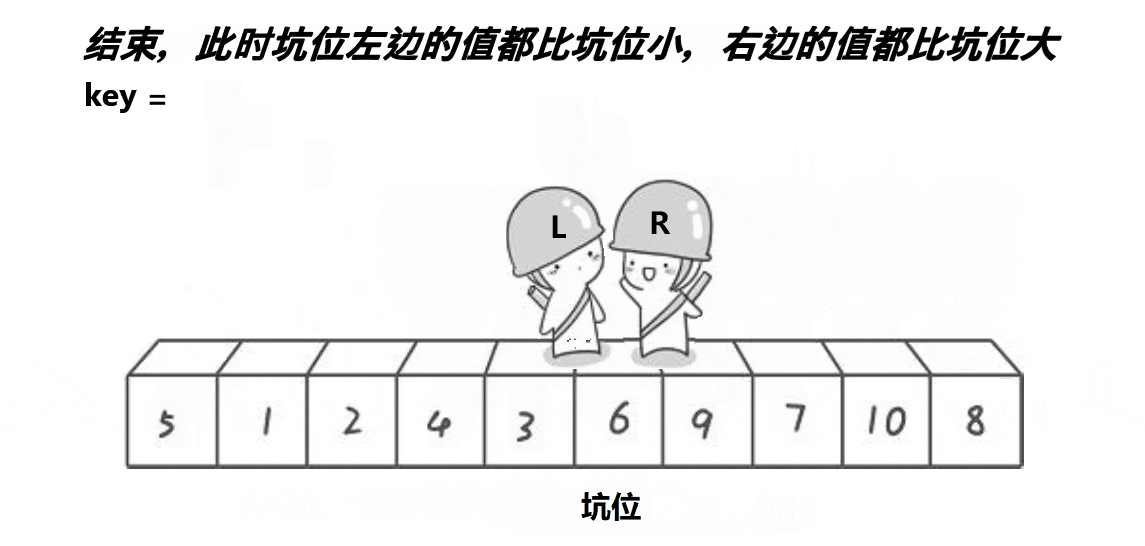
思路:
- key先形成坑位
- 右边先走,找到比key小的,放到左边的坑位
- 左边再走,找道比key大的,放到右边的坑位
- 直到left和right相遇
\
// 挖坑法
int PartSort2(int* a, int begin, int end)
{int midi = getMidi(a, begin, end);swap(&a[midi], &a[begin]);int key = a[begin];int hole = begin;while (begin < end){// 右边找小,填到左边的坑while (begin < end && a[end] >= key){--end;}a[hole] = a[end];hole = end;// 左边找大,填到右边的坑while (begin < end && a[begin] <= key){++begin;}a[hole] = a[begin];hole = begin;}a[hole] = key;return hole;
}
2.3前后指针版本
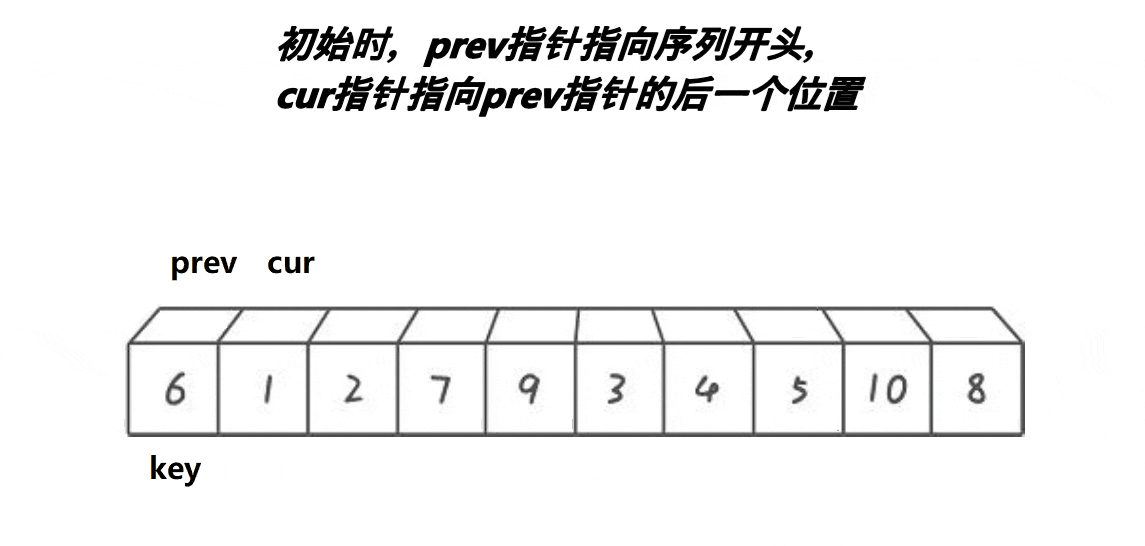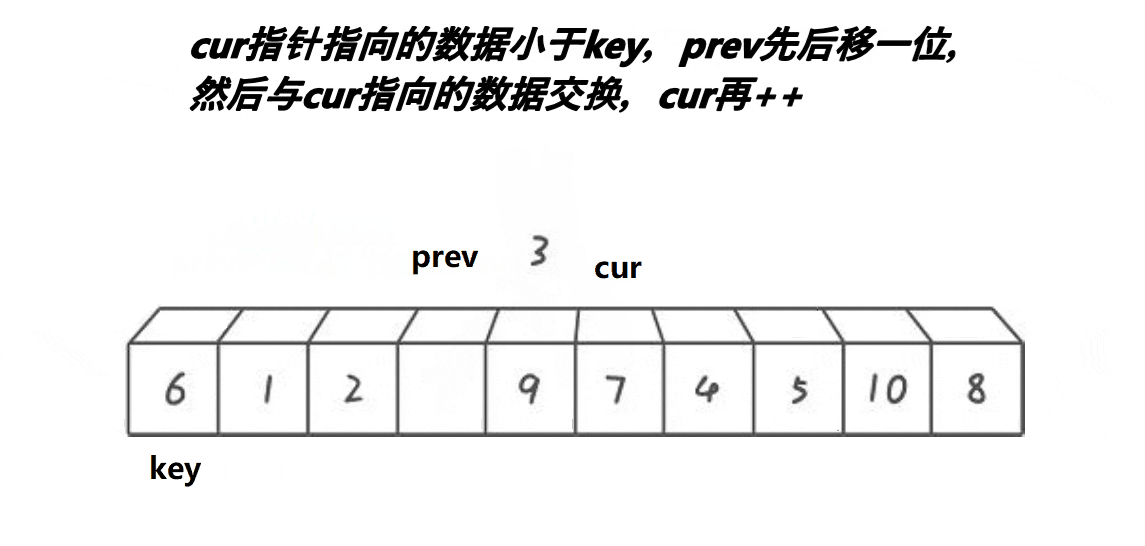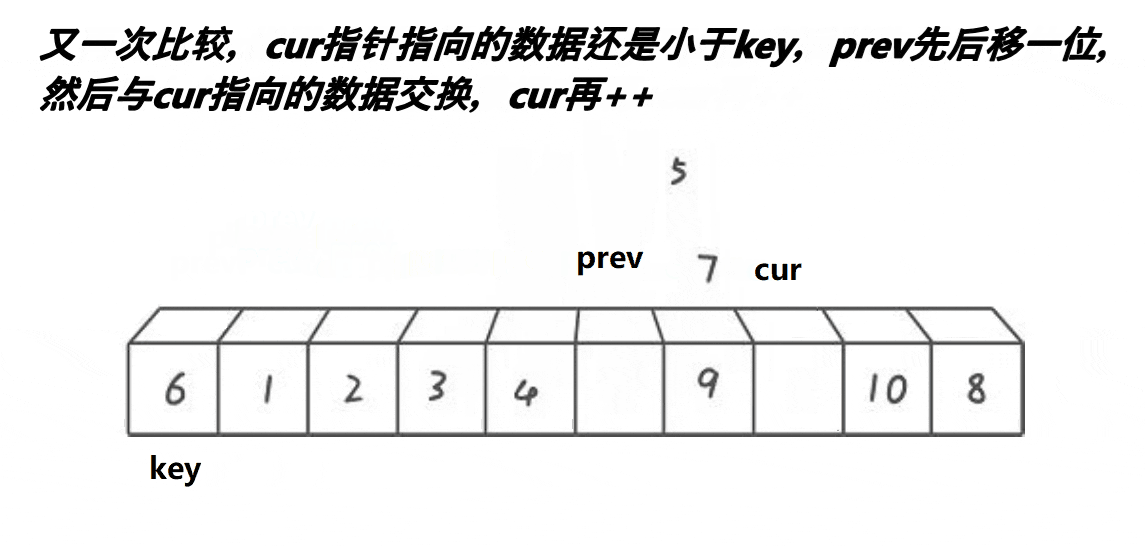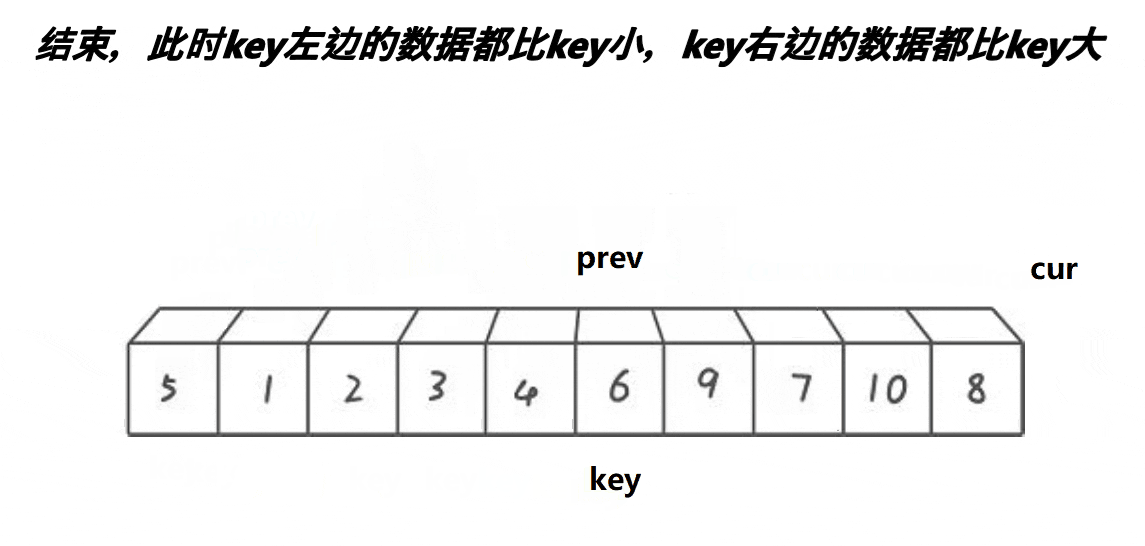
思路:cur是一个评判数字要掠过还是交换的角色,prev是一个保证其走过的路都是小值得一个角色。
- 选定key值,cur先走
- cur找到小值,prev++,cur与prev的值交换;cur++
- cur找到大值,cur++;
int PartSort3(int* a, int begin, int end)
{int midi = getMidi(a, begin, end);swap(&a[midi], &a[begin]);int key = begin;int cur = begin + 1;int prev = begin;while (cur <= end){/*if (a[cur] < a[key]) {prev++; swap(&a[prev], &a[cur]);}*/if (a[cur] < a[key] && ++prev != cur) swap(&a[prev], &a[cur]);cur++;}swap(&a[prev], &a[key]);return prev;
}
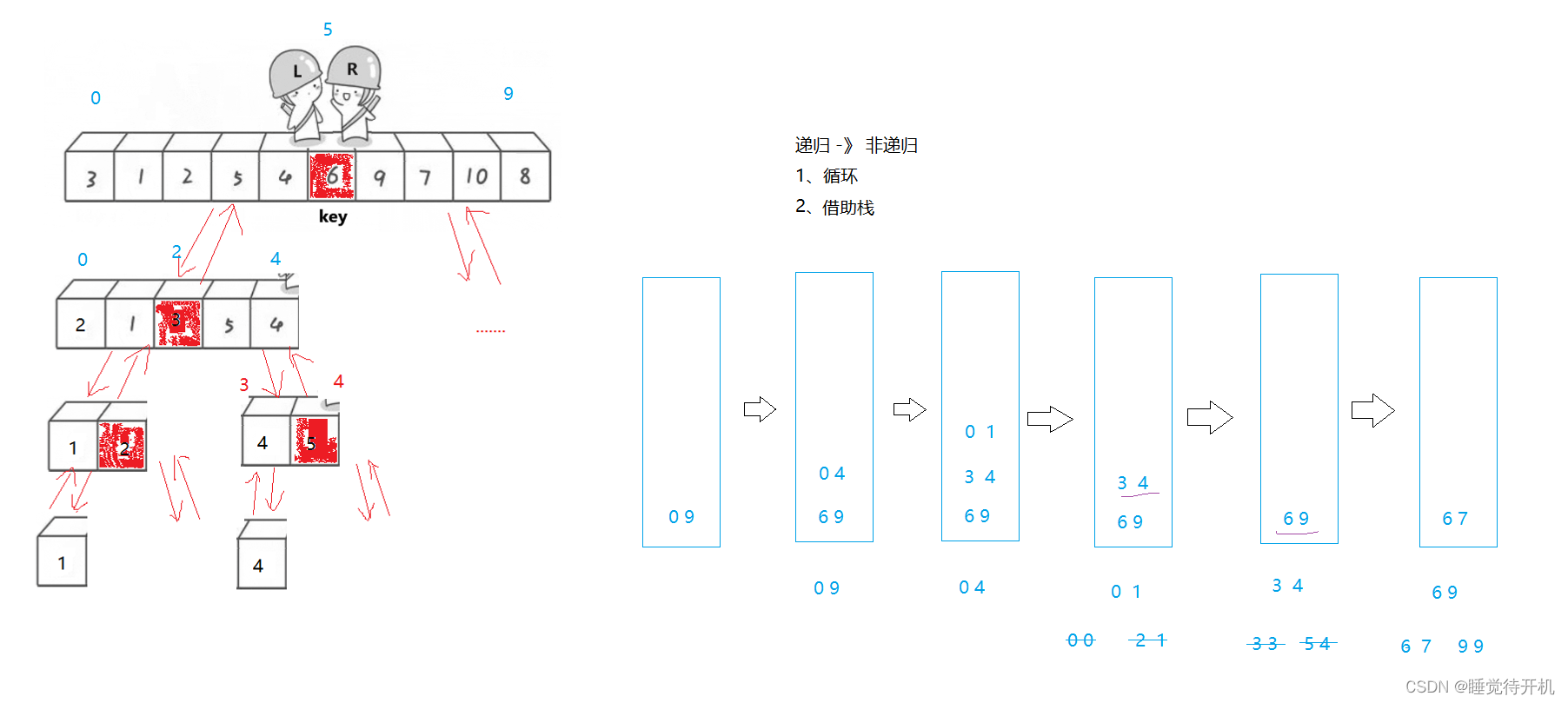
2.4非递归的快排
思路
用循环写快排,只需要模拟递归的过程即可。
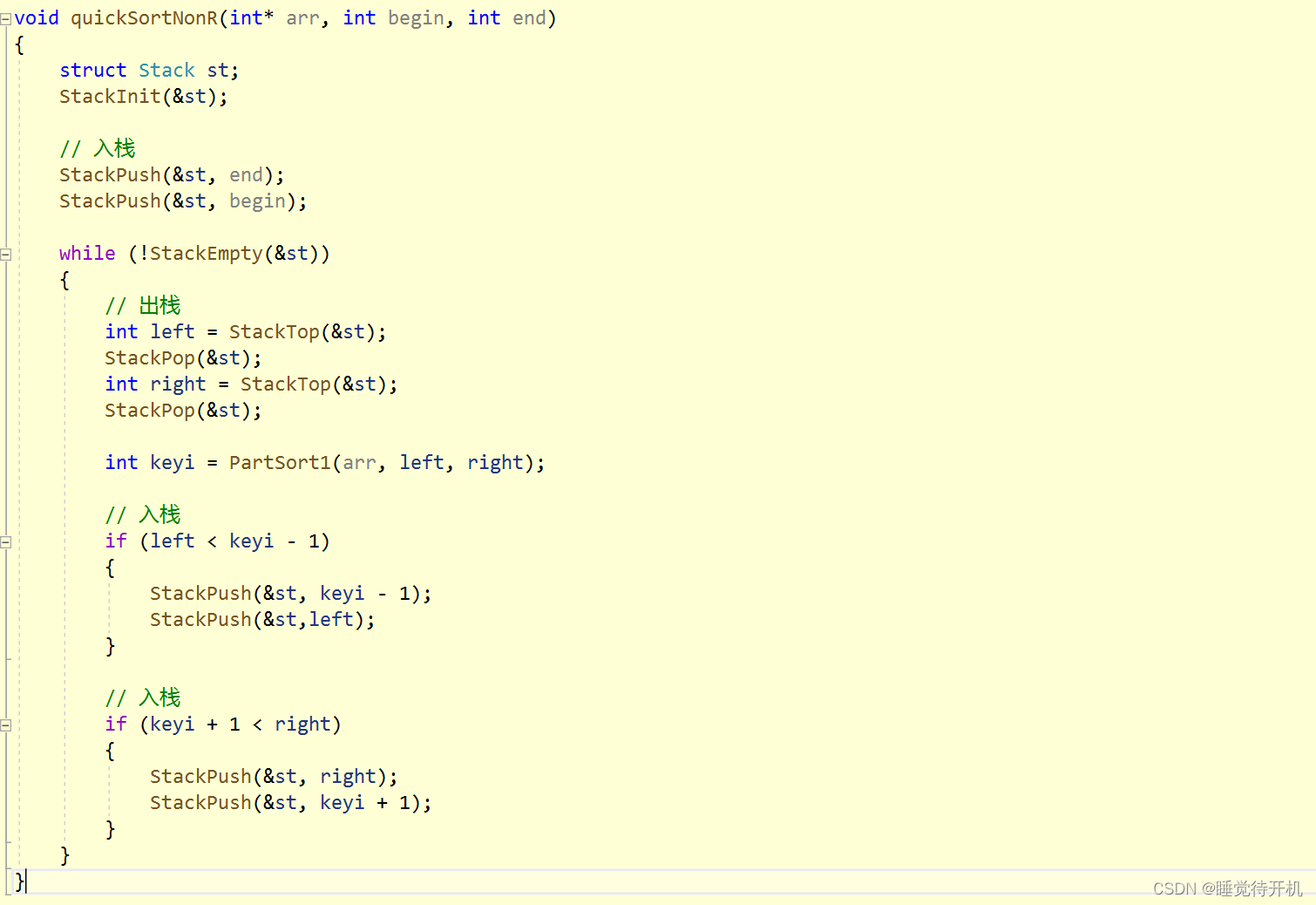
代码
EOF