What is Model Stealing?
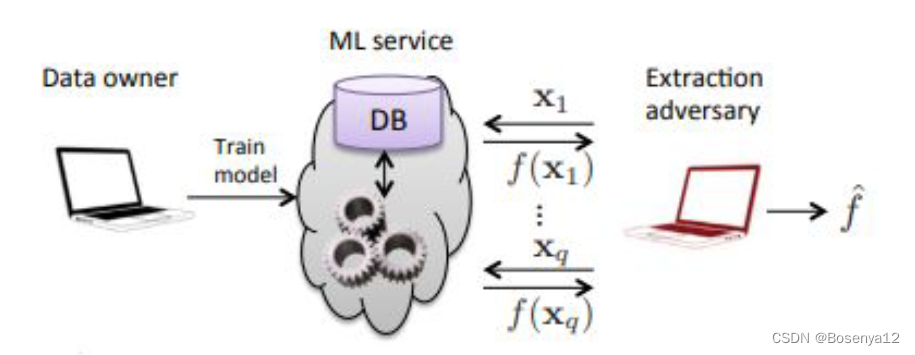
Extract an approximation that of the target model that “closely matches” the original
Accuracy?
Fidelity?
Funtional equivalence?
Threat Models
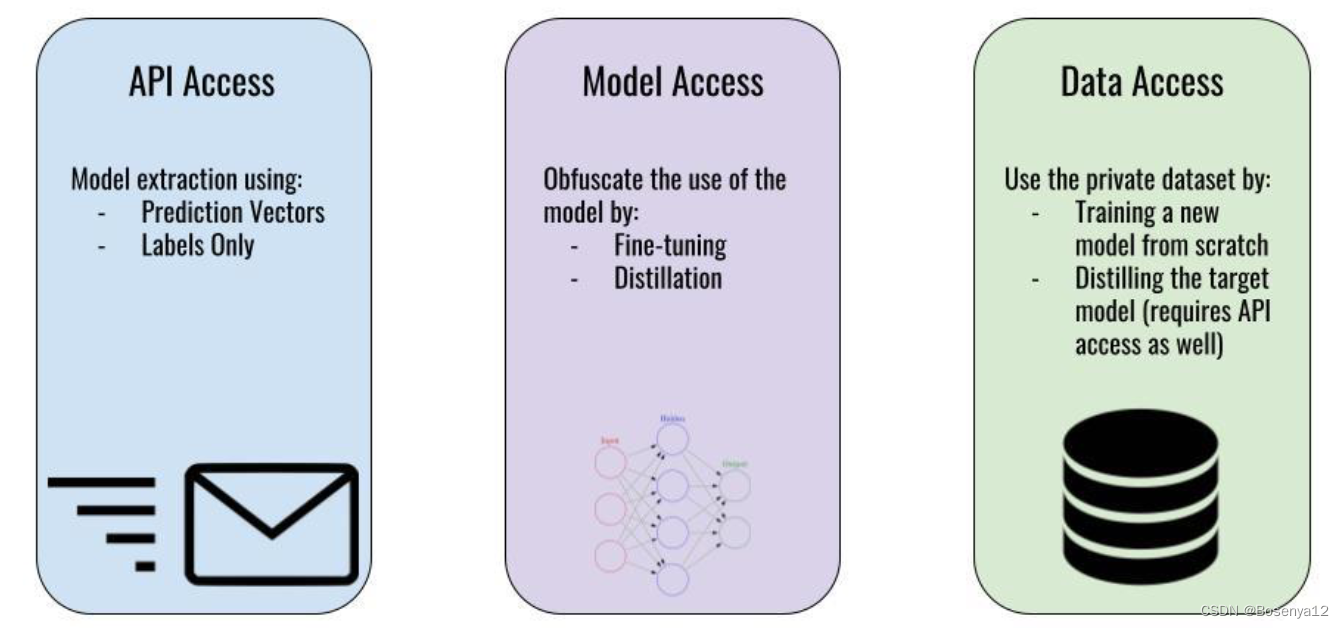
API Access
Model extraction using:
Prediction Vectors
Labels Only
Model Access
Obfuscate the use of the model by:
Fine-tuning
Distillation
Data Access
Use the private dataset by:
Training a new model from scratch
Distilling the target mode(requires API access as well)
My Model was Stolen:So What?
Why
Machine learning models may require a very large amount of resource to create:
Research and Development
Creating Private Datasets
Compute Costs
| Model | Cost |
|---|---|
| GPT2 | $256/hour |
| XLNET | $245,000 |
| GPT3 | $4.6 Million |
Having your model stolen can create new vulnerabilities for it:
Data privacy issues through model-inversion/membership inference(模型反演/成员推理)

Enables the use of white-box(白盒) adversarial example(对抗样本) creation
If a model extraction attack(模型提取攻击) is successful, the victim loses the information asymmetry advantage that is integral in defences for several other kinds of attacks.
Outline
First Paper: Black-box techniques for extracting a model using a query API(使用查询API提取模型的黑盒技术)
Second Paper: Detect model extraction by characterizing behaviour specific to the victim model(通过对受害者模型特有的行为特征进行检测模型提取)
Third Paper: Detecting model extraction by characterizing behaviour specific to the victim’s training set(通过对受害者训练集的特定行为进行特征化来检测模型的提取)
Stealing Machine Learning Models via Prediction APIs
Tramèr et al., 2016 paper link
Contributions
- Show the effectiveness of simple equation solving extraction attacks.
- Novel algorithm for extracting decision trees from non-boolean features.
- Demonstrate that extraction attacks still work against models that output only class labels.
- Application of these methods to real MLaaS interfaces.
Threat Model & Terminology
Focus on proper model extraction(模型提取)
Attacker has “black-box” access
This includes any info and statistics provided by the ML API

Equation Solving Attacks
方程求解攻击
 What about more complicated models?
What about more complicated models?
The paper shows that these attacks can extend to all model classes with a “logistic” layer

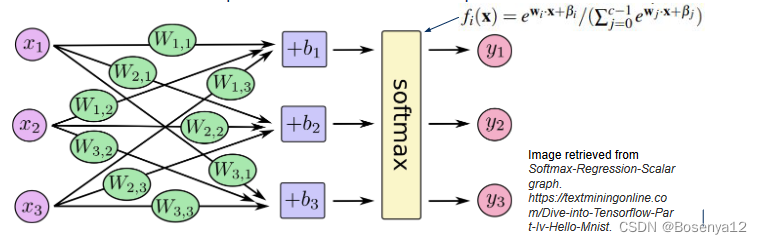
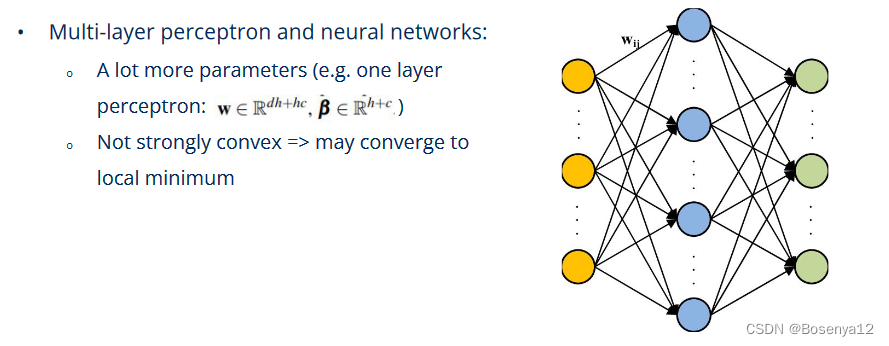

Is this attack feasible on DNN given the number of queries?
Are “random” inputs good enough to learn an accurate model for inputs with high dimensional feature space?

Case study: Amazon Web Services
Feature extraction takes extra reverse engineering which means more queries!<
![[C++][数据结构][B-树][下]详细讲解](https://img-blog.csdnimg.cn/direct/0090930d3c0c4f86afd9d12bf4f871f7.png)