论文链接:https://arxiv.org/pdf/2406.12182
开源链接:https://huggingface.co/BAAI/AquilaMed-RL
http://open.flopsera.com/flopsera-open/details/AquilaMed_SFT
http://open.flopsera.com/flopsera-open/details/AquilaMed_DPO
近年来,闭源大语言模型(LLMs)和开源社区在通用领域取得了显著进展,甚至在某些方面超越了人类。然而,在专业领域,特别是医学领域,语言模型的表现仍然不足。为了支持语言模型在行业领域的发展,智源研究院提出了IndustryCorpus行业数据集,并在今年的智源大会上发布了1.0版本,其中就包含了医疗模型的训练数据,同时也提出了从通用模型到行业模型的训练范式。为了验证我们的训练范式和数据集的有效性,智源研究院基于上述数据和范式训练了Aquila-Med,一种基于Aquila的大规模双语医疗语言模型,也是第一个全流程开源持续预训练、监督微调(SFT)以及强化学习(RLHF)技术的医疗语言模型。
IndustryCorpus行业数据集链接:
http://open.flopsera.com/flopsera-open/details/BAAI-IndustryCorpus
一、简介
Aquila-Med是智源研究院针对医疗领域复杂性提出的解决方案,通过构建大规模的中英双语医疗数据集进行持续预训练,并开发高质量的SFT和DPO数据集,以提升模型在单轮、多轮对话以及医疗选择题中的表现。目前,智源研究院开源了Aquila-Med的模型权重,数据集和整个训练过程,旨在为研究社区提供有价值的资源。
二、方法
Aquila-Med的训练分为三个阶段:持续预训练、监督微调(SFT)和从人类反馈中强化学习(RLHF)。每个阶段都包括数据构建和模型训练的详细过程。

2.1 持续预训练
2.1.1 数据收集与去污染
为了构建持续预训练数据集Aquila-Med-cpt,智源从大规模通用预训练数据库中收集医学相关语料,包括从通用预训练语料库中提取医学相关的内容,并采用基于规则和大模型的语料质量过滤技术。
2.1.2 训练策略
持续预训练分为两个阶段。阶段一使用规则过滤的医学领域数据和一定比例的通用数据进行训练,数据量约为60B tokens。阶段二使用LLM质量模型过滤的高质量医学领域数据和开源医学SFT合成数据,数据量约为20B tokens。
2.1.3 训练细节
我们基于Aquila-7B模型进行训练,该模型具有70亿参数,最大长度为4096。第一阶段使用3*8 NVIDIA A100-40G GPU,batch size为768,学习率为1e-4,训练一个epoch。第二阶段保持其他设置不变,将batch size减少到384,学习率减少到1e-5,训练一个epoch。
2.2 监督微调(SFT)
为了提高语言模型的自然对话能力,首先进行监督微调(SFT),使预训练的LLM适应聊天风格的数据。SFT数据集包括多种问题类型,如医疗考试选择题、单轮疾病诊断、多轮健康咨询等。
2.2.1 数据构建
SFT数据集来自六个公开可用的数据集,包括Chinese Medical Dialogue Data、Huatuo26M、MedDialog、ChatMed Consult Dataset、CMB-exam和ChatDoctor。我们采用Deita方法 [1] 对数据进行自动过滤,确保从大量数据中筛选出高质量单轮数据。同时在Deita的基础上创新性地使用Context Relevance来筛选高质量多轮对话数据。
2.2.2 训练细节
Aquila-Med训练过程的超参数包括序列长度为2048,batch size为128,峰值学习率为2e-6,使用cosine learning rate scheduler。我们使用8个NVIDIA Tesla A100 GPU进行训练,AdamW优化器,bf16精度和ZeRO-3,并保留10%的训练集用于验证。
2.2.3 数据集统计
通过以上数据过滤方法,我们选择了320,000个高质量的SFT医疗数据集,其中中文和英文的比例为86%:14%。数据集包括单轮中文医疗对话、单轮英文医疗对话、多轮中文医疗对话和医疗主题知识选择题。
2.3 强化学习(RLHF)
在SFT阶段后使用RLHF算法(DPO) [2] 进一步增强模型的能力。为了确保模型输出与人类偏好一致,同时保证模型在预训练和SFT阶段获得的基础能力,我们构建了主观偏好数据和客观偏好数据。
2.3.1 数据构建
我们构建了12,727个DPO偏好对,其中包括9,019个主观数据和3,708个客观数据样本。主观偏好数据通过GPT-4生成和评估,客观偏好数据通过已知的正确答案构建。
2.3.2 训练细节
我们在8个NVIDIA Tesla A100 GPU上训练模型,设置学习率为2e-7,batch size为64,并使用cosine learning rate scheduler进行优化。
三、评估
我们在多个开源中英医疗基准测试上评估了模型的性能,包括单轮对话、多轮对话和医疗选择题。
3.1 医疗知识基准
我们从MMLU和C-Eval基准中提取了医疗相关的问题,并利用CMB-Exam、MedQA、MedMCQA和PubMedQA测试集评估模型的医疗知识水平。
3.2 医疗对话基准
我们评估了模型解决实际患者问题的能力,涵盖单轮对话场景如Huatuo MedicalQA和多轮对话场景如CMtMedQA和CMB-Clin。
四、实验结果
4.1 持续预训练的结果
实验结果表明,Aquila-Med在多个基准测试上表现良好,特别是在MMLU上的表现显著提升。

4.2 模型对齐的结果
在对齐效果方法,我们从医学主题问题和医生-患者咨询两个方面进行评估。结果显示,Aquila-Med-Chat在指令跟随能力方面表现出色,Aquila-Med-Chat (RL)在C-Eval上以及单轮多轮对话能力的表现尤为突出。

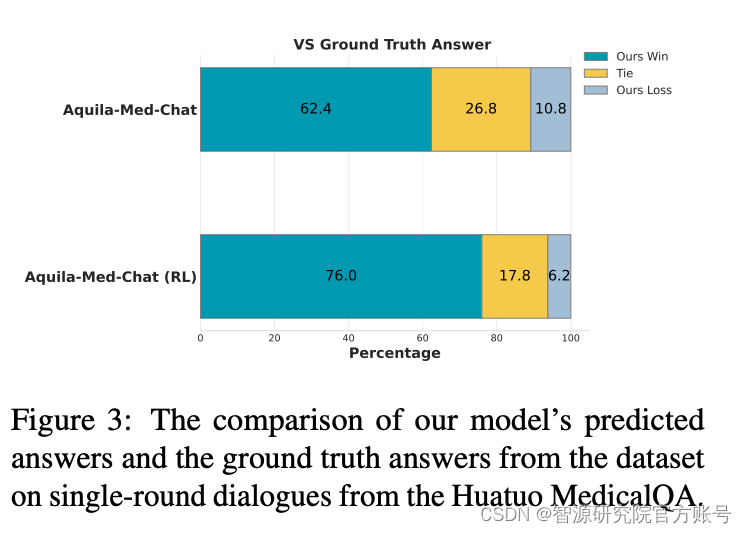
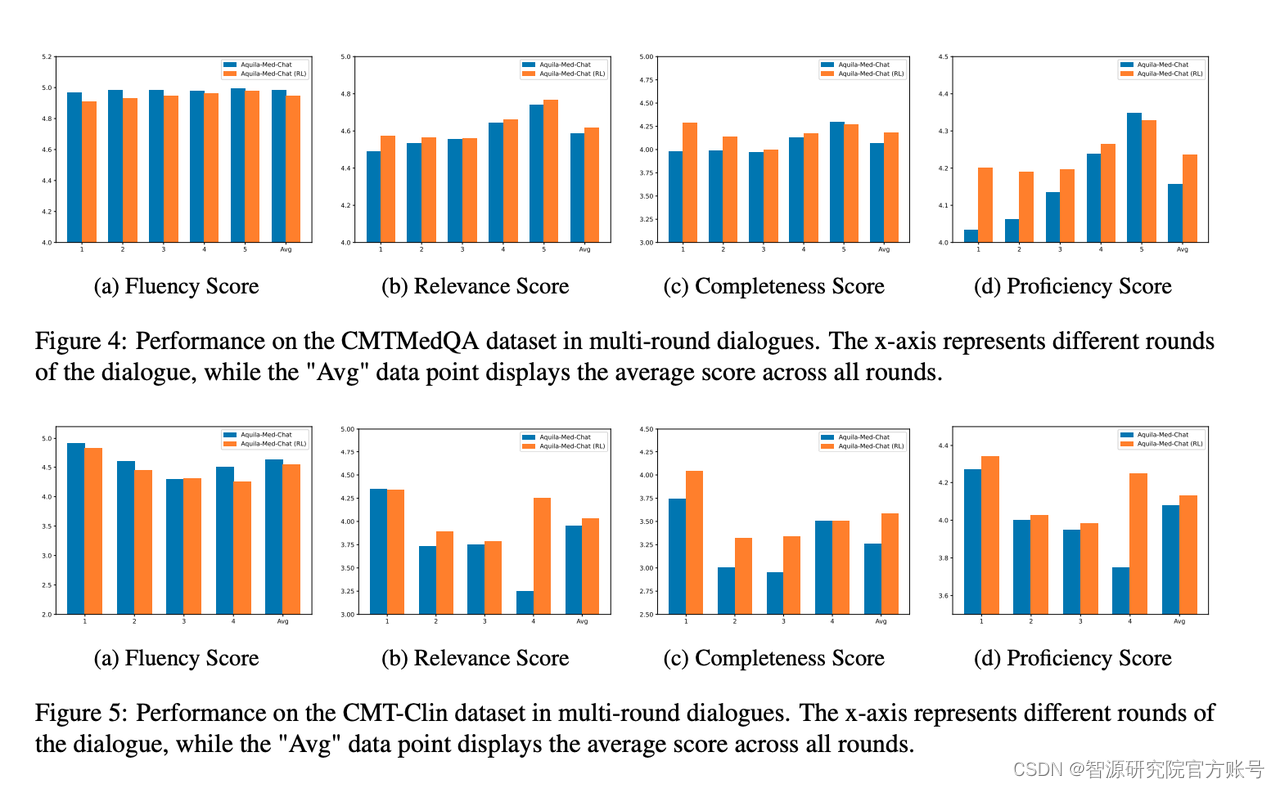
五、结论
本文提出了Aquila-Med,这是一种双语医疗LLM,旨在通过持续预训练、SFT和RLHF应对医学领域的挑战。我们的数据集构建和训练过程显著提升了模型处理单轮和多轮医疗咨询以及医疗选择题的能力。Aquila-Med在多个基准测试上的强大表现验证了方法的有效性。通过开源数据集和训练过程,智源希望推动医疗LLM的发展,为研究社区提供更多支持。后续我们会持续进行数据和模型迭代,研究更高效的数据策略,在更多的基础模型进行验证,请持续关注我们的发布。
Reference:
[1] Liu W, Zeng W, He K, et al. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning[J]. arXiv preprint arXiv:2312.15685, 2023.
[2] Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. Advances in Neural Information Processing Systems, 2024, 36.



![[C++][数据结构][B-树][下]详细讲解](https://img-blog.csdnimg.cn/direct/0090930d3c0c4f86afd9d12bf4f871f7.png)