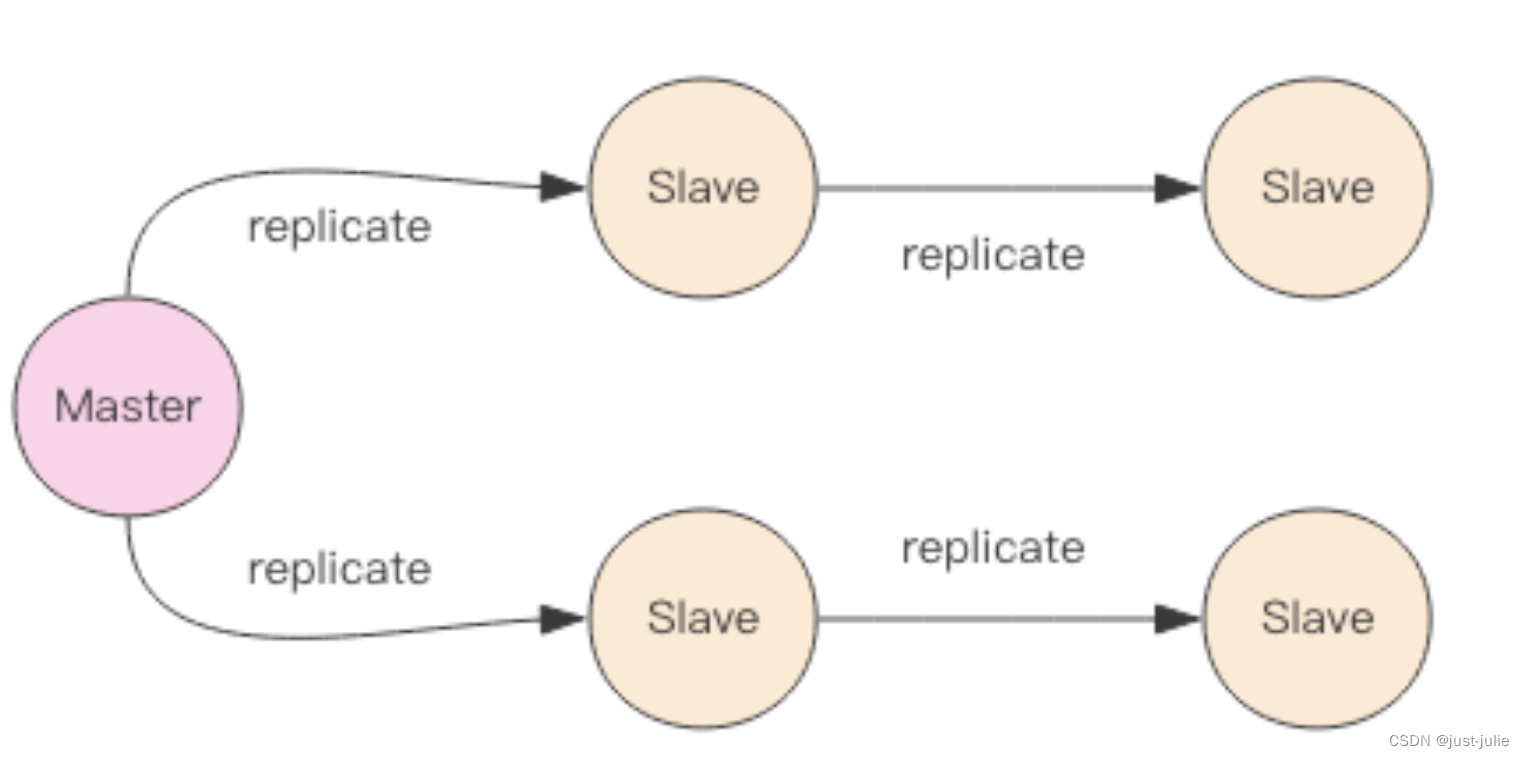
主从同步
很多企业没有使用Redis的集群,但是至少都做了主从。有了主从,当master挂掉的时候,运维让从库过来接管,服务就可以继续,否则master需要经过数据恢复和重启的过程,可能会拖很长时间,影响业务持续服务。
CAP原理——现代分布式理论基石
- C-Consistent,一致性
- A-Availability,可用性
- P-Partition tolerance 分区容错性
一句话概括CAP原理:在网络分区发生时,一致性和可用性难两全。
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会用网络断开的风险,这个网络断开的场景就叫【网络分区】。
在网络分区发生时,两个分布式节点之间无法进行通信,我们对一个节点进行修改操作无法同步到另一个节点,所以数据的【一致性】将无法满足。因为 两个分布式节点数据不再保持一致,除非我们牺牲【可用性】,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复再继续对外提供服务。
BASE理论
BASE理论是分布式系统设计中的另一个重要概念,他的核心是,在分布式环境中,完全一致性往往难以实现,因此可以采用柔性的一致性模型来提高系统的可用性和扩展性。
-
基本可用(Basically Available):系统在分布式环境中可能会出现部分故障,但保证核心功能可用,尽可能避免全面崩溃。
-
软状态(Soft State):系统的状态不需要时刻保持一致,允许存在中间状态,最终通过异步的方式达到一致性。
-
最终一致性(Eventually Consistent):系统保证在没有新的更新的情况下,最终所有的复制数据会达到一致的状态。
Redis的最终一致即Base理论
Redis的主从数据是异步同步的,所以分布式的Redis系统并不满足【一致性】要求。当客户端在Redis的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供服务,所以Redis满足【可用性】。
Redis保证【最终一致性】,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态保持一致。如果网络断开了,主从节点的数据将会出现大量不一致。一旦网络恢复,从节点会采取多种策略努力追赶上落后的数据,继续尽力保持和主节点的一致。
主从同步
Redis同步支持主从同步和从从同步,从从同步是Redis后续版本增加的功能,为了减轻主库的同步负担。
增量同步
Redis同步的是指令流,主节点会将那些对自己的状态产生修改性影响的指令记录在本地的内存buffer中,然后异步将buffer中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一样的状态,一边向主节点反馈自己同步到哪里了(偏移量)。
因为内存的buffer是有限的,所以Redis主库不能将所有的指令都记录在内存buffer中。Redis的复制内存buffer是一个定长的环形数组,如果数组内容满了,就会从头开始覆盖前面的内容。
如果因为网络状况不好,从节点在短时间内无法和主节点进行同步,那么当网络状况恢复时,Redis的主节点中那些没有同步的指令在buffer中有可能已经被后续的指令覆盖掉了,从节点将无法直接通过指令流来进行同步,这个时候就需要用到更加复杂的同步机制——快照同步。
快照同步
快照同步是一个非常耗费资源的操作,他 1. 首先需要在主库上进行一次bgsave将当前内存的数据全部快照到磁盘文件,2.然后再将快照文件的内容全部传送到从节点,3. 从节点将快照接收完毕后,立即执行一次全量加载,加载之前先要将当前内存的数据清空。加载完毕后通知主节点继续进行增量同步。
在整个快照同步进行的过程中,主节点的复制buffer还在不停的往前移动,如果快照同步的时间过长或者复制buffer太小,都会导致同步期间的增量指令在buffer中被覆盖,这样就会导致快照同步完成后无法进行增量复制,然后会再次发起快照同步,如此极有可能会陷入快照同步的死循环。

所以, 务必配置一个合适的复制buffer大小参数,避免快照复制的死循环。
增加从节点
当从节点刚刚加入集群时,需要先进行一次快照同步,同步完成后在继续进行增量同步。
无盘复制
主节点在进行快照同步时,会进行很重的IO文件操作,特别是对于非SSD磁盘存储时,快照会对系统的负载产生较大影响。特别是 当系统正在进行AOF的fsync操作时如果发生快照,fsync将会被推迟执行,这就会严重影响主节点的服务效率。
Redis的无盘复制是一种优化主从复制过程的技术,旨在减少主节点在进行复制时对磁盘的依赖,从而提高复制速度并减轻主节点磁盘IO压力。
工作原理
- 在无盘复制模式下,Redis主节点不会像传统复制那样先将数据保存为RDB文件到本地磁盘,然后再由从节点下载该文件。相反,主节点会直接在内存中创建RDB文件,并通过网络socket直接将RDB数据流发送到从节点,整个过程绕过了磁盘操作。
- 这个过程涉及主节点创建一个子进程,该子进程负责将内存中的数据序列化并通过网络发送,而无需写入磁盘。
wait指令
Redis的复制是异步进行的,wait指令可以让异步复制变为同步复制,确保系统的强一致性(不严格)。
> set key value
OK
> wait 1 0
(integer) 1
wait提供两个参数,第一个参数是从库数量N,第二个参数是时间t,以毫秒为单位。他表示等待wait指令之前的所有写操作同步到N个从库,最多等待t时间,如果t为0,表示无限等待直到N个从库同步达到一致。
假设此时出现了网络分区,wait指令第二个参数时间t=0,主从同步无法进行,wait指令会永远阻塞,Redis服务器将丧失可用性。