支持向量机(SVM)是一种用于分类和回归分析的监督学习模型。SVM通过找到一个超平面来将数据点分开,从而实现分类。
1. 理解基本概念和理论:
- 超平面(Hyperplane):在高维空间中,将数据分成不同类别的决策边界。
- 支持向量(Support Vectors):离超平面最近的数据点,决定了超平面的位置和方向。
- 间隔(Margin):支持向量到超平面的距离,SVM最大化这个间隔。
2. 两种向量机
2.1 线性支持向量机(Linear SVM)
线性SVM用于线性可分的数据集。它通过找到一个决策边界(超平面),将数据点分为不同的类别。目标是找到最大化两类数据点之间间隔的超平面。
2.1.1. 问题描述
给定一个训练数据集 (x1,y1),(x2,y2),…,(xn,yn),其中 xi 是 d维特征向量,yi∈{−1,1} 是标签,线性SVM的目标是找到一个超平面 w⋅x+b=0 将数据点分开。
2.1.2. 超平面方程
超平面可以表示为:
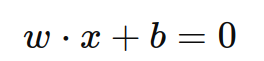
其中,w是法向量,b 是偏置项。
2.1.3. 最大化间隔
为了最大化支持向量到超平面的间隔,我们需要优化以下目标函数:
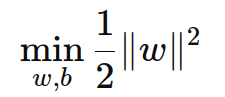
其中,∥w∥2是 w 的二范数平方。这个目标函数中的 1/2 是为了在后续计算中方便取导数。
2.1.4. 约束条件
为了确保数据点被正确分类,并且支持向量到超平面的距离为1,添加以下约束条件:
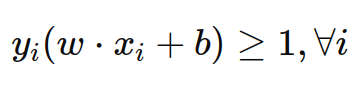
示意图:
Category A: o
Category B: xo o oo oo
-----------(Hyperplane)xx xx xx x x x2.2 非线性支持向量机(Non-linear SVM)
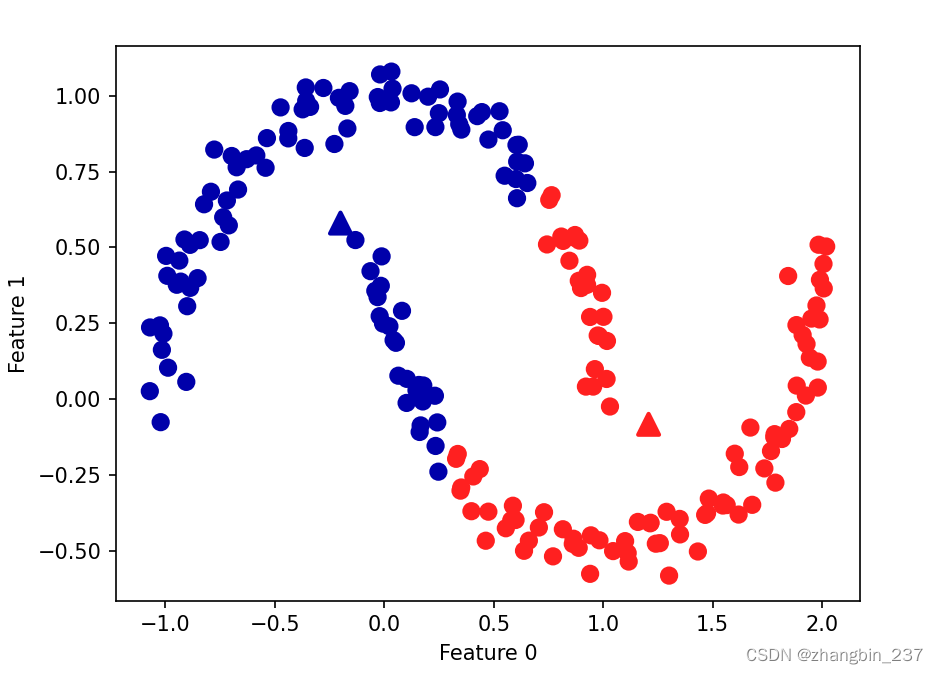
非线性支持向量机旨在处理数据在原始特征空间中不可线性分离的情况。通过使用核函数(Kernel Function),非线性SVM将数据映射到高维空间,在高维空间中找到一个线性超平面来实现分类。
2.2.1. 问题描述
给定一个训练数据集 (x1,y1),(x2,y2),…,(xn,yn) ,其中 xi 是 d 维特征向量,yi∈{−1,1} 是标签,非线性SVM的目标是找到一个高维空间中的超平面将数据点分开。
2.2.2. 核函数(Kernel Function)
核函数 K(xi,xj) 用于将数据从原始特征空间映射到高维空间:
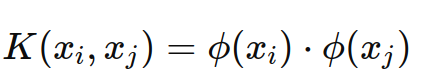
其中,ϕ 是隐式的映射函数,K(xi,xj) 是两个向量在高维空间中的内积。
常见的核函数包括:
- 线性核(Linear Kernel):
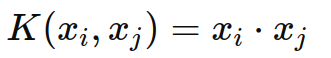
- 多项式核(Polynomial Kernel):
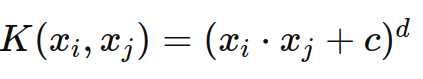
- 高斯径向基函数核(RBF Kernel):
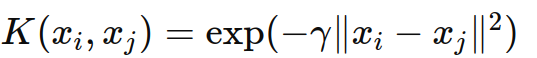 对于非线性SVM,目标函数和约束条件与线性SVM相同,只是在高维空间中进行计算。
对于非线性SVM,目标函数和约束条件与线性SVM相同,只是在高维空间中进行计算。
示意图(低维空间中的数据点,不可线性分离):
Category A: o
Category B: xo xo xox ox o3. 应用场景中的具体优势:
图像分类:在高维特征空间中,SVM可以有效地找到分离不同类别图像的超平面,尤其在边界不明显或重叠的情况下表现良好。
文本分类:SVM可以处理高维稀疏特征(如词袋模型或TF-IDF),并能有效地处理大规模文本数据,且不易过拟合。
生物信息学:在基因表达数据等高维度生物数据中,SVM通过选择合适的核函数,可以高效地分离不同类别的生物样本。
金融领域:在股票预测和信用评分中,SVM能够处理复杂的非线性关系,并在高维金融数据中找到重要的决策边界。
tensorflow实现svm





![[实践篇]13.29 再来聊下Pass Through设备透传](https://img-blog.csdnimg.cn/direct/366e3cedee694a05932e96fff4cbe72f.png)