Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA Triton | NVIDIA Technical Blog
Quick Start Guide — tensorrt_llm documentation (nvidia.github.io)
使用TensorRT-LLM的源码,来下载docker并在docker里编译TensorRT-LLM;
模型格式先Huggingface转为FasterTransformer;再用TensorRT-LLM将其compile为TensorRT engine;然后可用TensorRT-LLM的C++ runtime来跑推理(或者模型放到Triton Repo上,并指定TensorRT-LLM为backend)
Input的Tokenizing和Output的De-Tokenizing,视作前处理、后处理,创建"Python Model";整个流程用一个"Ensemble Model"来表示,包含以上两个"Model"以及真正的GPT-Model;
Best Practices for Tuning the Performance of TensorRT-LLM — tensorrt_llm documentation (nvidia.github.io)
LLama:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/examples/llama/README.md
TensorRT-LLM支持很多常用模型;例如:baichuan、internlm、chatglm、qwen、bloom、gpt、gptneox、llama;
convert_checkpoint.py,是每种模型用自己的;run.py,是所有模型共享;
每种模型,支持的技术完善程度不同。
支持LLama的以下功能:
- FP16
- FP8
- INT8 & INT4 Weight-Only
- SmoothQuant
- Groupwise quantization (AWQ/GPTQ)
- FP8 KV CACHE
- INT8 KV CACHE (+ AWQ/per-channel weight-only)
- Tensor Parallel
- STRONGLY TYPED
python convert_checkpoint.py
--tp_size 4 // Tensor-parallel
--pp_size 4 // Pipeline-parallel
Pipeline并行,在某一个GPU忙碌时,其他GPU是否在忙着处理别的batch?
量化相关:
Numerical Precision — tensorrt_llm documentation (nvidia.github.io)
9种量化,对每种模型只支持一部分:
| Model | FP32 | FP16 | BF16 | FP8 | W8A8 SQ | W8A16 | W4A16 | W4A16 AWQ | W4A16 GPTQ |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| BERT | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM-v2 | Y | Y | Y | . | . | . | . | . | . |
| ChatGLM-v3 | Y | Y | Y | . | . | . | . | . | . |
| GPT | Y | Y | Y | Y | Y | Y | Y | . | . |
| GPT-NeMo | Y | Y | Y | . | . | . | . | . | . |
| GPT-NeoX | Y | Y | Y | . | . | . | . | . | Y |
| InternLM | Y | Y | Y | . | Y | Y | Y | . | . |
| LLaMA | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| LLaMA-v2 | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| LLaMA-v3 | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| Qwen | Y | Y | Y | . | Y | Y | Y | Y | Y |
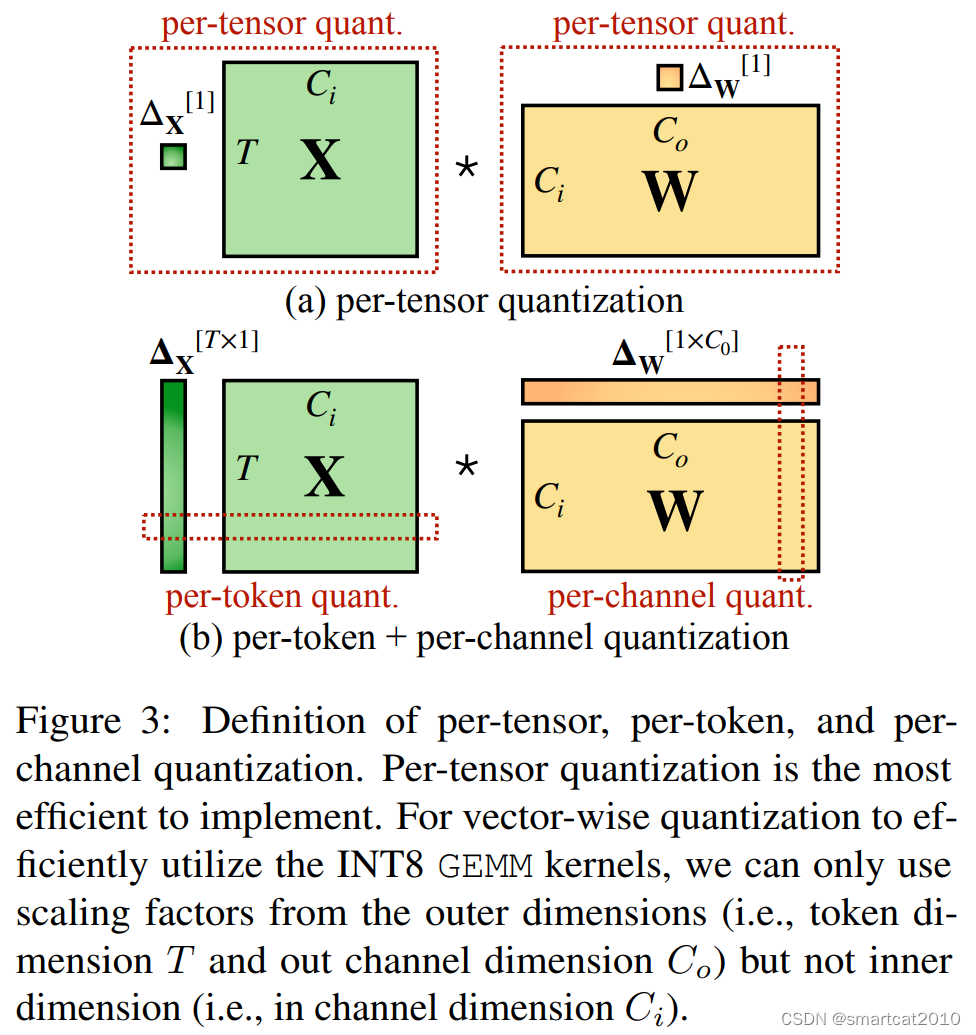
W8A16、W4A16:
Activation都是FP16(或BF16); Weight是INT8、INT4,在计算前反量化为FP16(或BF16),FP16*FP16-->FP16;
只是使显卡里塞入了size更大的模型;
并没有加快计算(反而因为dequantize weight从INT到FP16,变慢些)
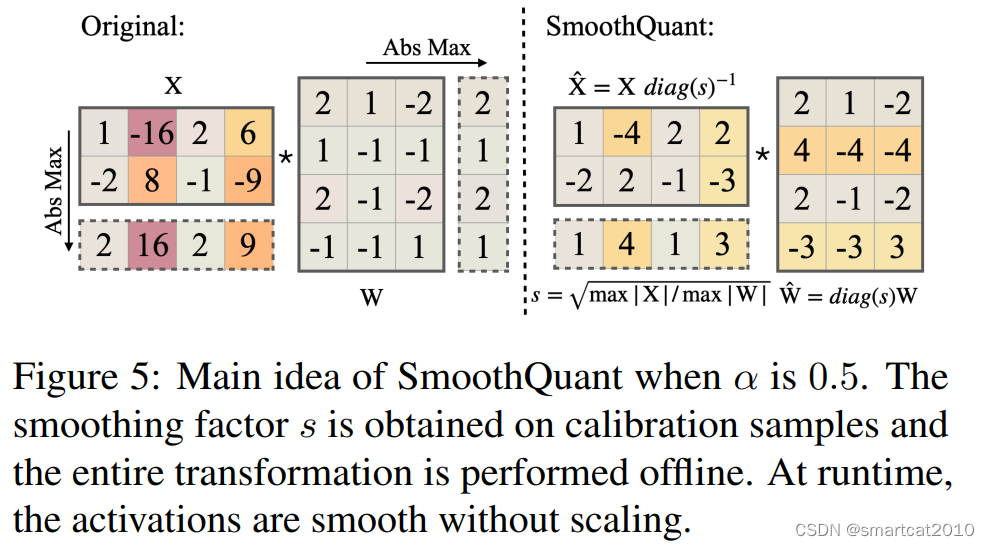
SmoothQuant: (W8A8)
--smoothquant 0.5
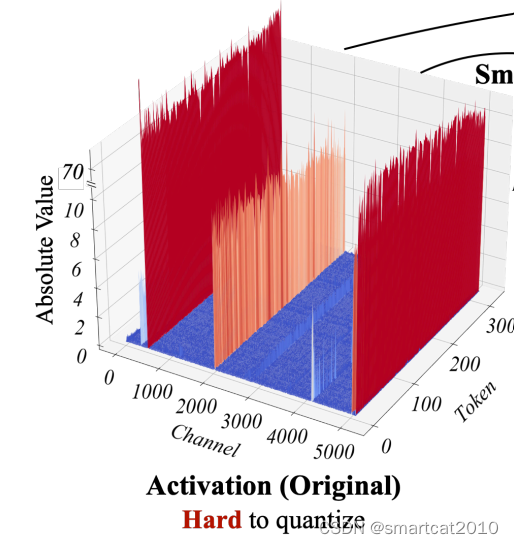
惯例做法,是对Activation的行(Token)和Weight的列(Output channel),进行量化;
观察到的现象:weights矩阵,没有尖刺;activation矩阵,某几列(channel)是尖刺,而且明显能区分尖刺列和非尖刺列,尖刺列所有行(token)的值都大,非尖刺列所有行的值都小;
如果按照Activation的列进行量化,Gemm矩阵乘法不支持;
解决方案:对Activation的“尖刺”列,缩小N倍,对Weight的相应行,增大N倍;二者仍分别用老的Per-Token、Per-Channel来量化;
--gemm_plugin int8 : 使用指定的dtype去计算矩阵乘法,用的是加速库;
--gpt_attention_plugin int8 (默认开启): 优化key-value cache;"use of efficient CUDA kernels for computing attention scores and values, reducing computation and memory overhead compared to the standard implementation." 看不懂:"It allows in-place update of the key-value (KV) cache used for attending to previous tokens, eliminating the need for explicit concatenation operations and further reducing memory consumption"
--remove_input_padding (默认开启)
input batch里,较短句子们,末尾的padding,在正常推理阶段被浪费了。
优化:使用别的句子(下一个batch的),填充这些padding;
--paged_kv_cache (默认开启)
把一部分放不下的keys、values,换出到CPU memory,用的时候再换入;
有选项可以配置kv-cache最大占用的GPU memory比例,建议设为0.95
--context_fmha (默认开启)
"Enabling the fused multi-head attention, during the context phase, will trigger a kernel that performs the MHA/MQA/GQA block using a single kernel"
LLM推理,分为context阶段和generate阶段;context阶段,用一个融合的kernel去执行MHA/MQA/GQA;
--use_fused_mlp
适用于Gated MLP层(将mlp-mixer跟门控机制结合起来。即将输入沿着特征维度分为两半,然后将其中一半传入mlp-mixer,作为另一半的gate);原本是计算gate是一个矩阵乘法,MLP是一个矩阵乘法;这个优化把2个矩阵乘法融合为1个矩阵乘法;
--multi_block_mode
batch_size * heads_count,小于GPU Stream Multiprocessor数目的一半时,且context input tokens较长(>1000),则使用这个,可以增加GPU SM的利用率。(似乎是每个SM负责解决1个sample和1个head的乘法,同时无法利用所有SM时,就把其他token的计算也并行?)
类似资料:Flash-Decoding for Long-Context Inference | Princeton NLP Group (princeton-nlp.github.io)
--use_paged_context_fmha
在"--context_fmha"的基础上,允许context kv-cache在GPU和CPU memory之间offload;适合长input context的推理;
Memory footprint计算:
Note that if engine is built with contiguous KV cache (i.e., without the flag
--paged_kv_cache), you may need to reduce the max batch size (--max_batch_size) to fit the whole model and the KV cache in the GPU memory. The ballpark estimate for runtime memory consumption is given byTotal memory = (Model size + KV cache size + Activation memory) / Parallelismwhere
- The model size is
the number of parameters * the size of data type.- The KV cache size is
the total number of tokens * the size of KV cache data type * the number of layers * the KV hidden dimension- The activation memory is determined by TRT engine, which can be a few GBs regardless of the degree of parallelism used
For LLaMA v2 70B FP16 weights + FP8 KV cache, the model size is 70B parameters * 2 bytes = 140GB. The KV cache size is 32K tokens * 1 bytes * 80 layers * 2048 KV hidden dimension = 5GB per 32K tokens. We have 145GB spread across 8 GPUs. The end result is ~18GB per GPU plus some GBs of flat scratch/activation memory allocated by TRT engine and the TRT-LLM runtime.
Note that the KV hidden dimension is derived by the number of KV heads times hidden dimension of each head. LLaMA v2 70B has hidden dimension of 8192, and uses grouped-query attention where 8 key heads and 8 value heads are associated with 64 query heads. Each head has hidden dimension of 8192/64 = 128. So the hidden dimension for KV in total is 128 * 8 * 2 = 2048.
The total number of tokens is determined by beam width, batch size, and maximum sequence length.
LLama2-70B使用了Grouped Query Attention:
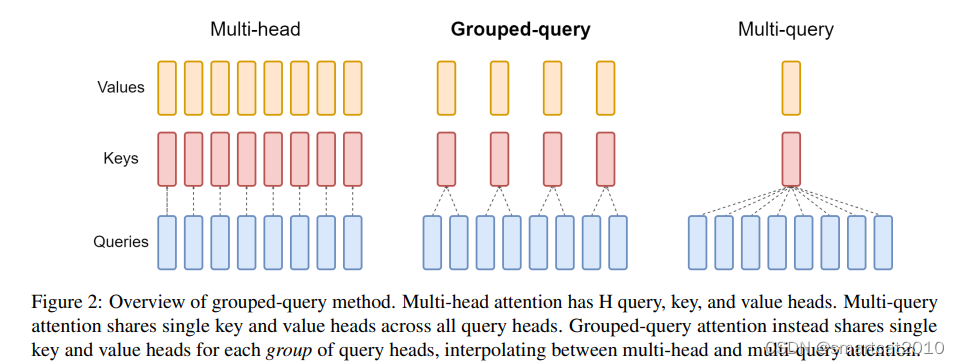
减少了显存占用量;从activation乘以变换矩阵,计算得到Key和Value,只计算N组,减少了计算量;
--int8_kv_cache
KV cache使用INT8量化,来存放;节约显存;
会使用一部分输入数据,来试跑(calibrate the model);从而得到Key、Value的取值范围,拿到Scaling factor;
For example, to build LLaMA 70B for 2 nodes with 8 GPUs per node, we can use 8-way tensor parallelism and 2-way pipeline parallelism:
python convert_checkpoint.py --model_dir ./tmp/llama/70B/hf/ \--output_dir ./tllm_checkpoint_16gpu_tp8_pp2 \--dtype float16 \--tp_size 8 \--pp_size 2trtllm-build --checkpoint_dir ./tllm_checkpoint_16gpu_tp8_pp2 \--output_dir ./tmp/llama/70B/trt_engines/fp16/16-gpu/ \--workers 8 \ #启动8个后台线程同时build--gemm_plugin auto
跑多个LoRA ckpt: (有编号,-1表示原始model,0表示luotuo那个,1表示Japanese那个)
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
BASE_LLAMA_MODEL=llama-7b-hf/python convert_checkpoint.py --model_dir ${BASE_LLAMA_MODEL} \--output_dir ./tllm_checkpoint_1gpu \--dtype float16
trtllm-build --checkpoint_dir ./tllm_checkpoint_1gpu \--output_dir /tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/ \--gemm_plugin auto \--lora_plugin auto \--max_batch_size 8 \--max_input_len 512 \--max_output_len 50 \--lora_dir "luotuo-lora-7b-0.1/" "Japanese-Alpaca-LoRA-7b-v0/" \--max_lora_rank 8 \--lora_target_modules attn_q attn_k attn_vpython ../run.py --engine_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \--max_output_len 10 \--tokenizer_dir ${BASE_LLAMA_MODEL} \--input_text "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" \--lora_task_uids -1 0 1 -1 0 1 \--use_py_session --top_p 0.5 --top_k 0Streaming LLM: (可以允许无限长度)
--streamingllm enable
--max_attention_window_size=2048
做多向前看多少个token的attention