ES全文检索支持繁简和IK分词检索
- 1. 前言
- 2. 引入繁简转换插件analysis-stconvert
- 2.1 下载已有作者编译后的包文件
- 2.2 下载源码进行编译
- 2.3 复制解压插件到es安装目录的plugins文件夹下
- 3. 引入ik分词器插件
- 3.1 已有作者编译后的包文件
- 3.2 只有源代码的版本
- 3.3 安装ik分词插件
- 4. 建立IK和繁简集成的es索引
- 5. 新增数据测试检索
1. 前言
在现代信息检索中,处理不同语言的变体和实现高效的全文检索是一个重要的需求。对于中文,特别是需要处理简体和繁体的转换,以及高效的分词处理,这就显得尤为重要。ElasticSearch(ES)作为一个分布式全文搜索引擎,提供了强大的文本搜索和分析能力,但默认情况下并不支持简繁转换和高级的中文分词。因此,我们需要通过一些插件和自定义设置来实现这一功能。
本教程旨在展示如何在ES中引入繁简转换和IK分词插件,使得在检索时无论输入简体还是繁体都能够被检索到。无论用户输入“語法”还是“语法”,检索结果中都能命中包含简体和繁体的相关文档。这种处理方式不仅提升了用户体验,还增强了检索的准确性和全面性。
通过引入分析插件analysis-stconvert和分词插件analysis-ik,并结合自定义的ES配置,我们可以实现这一目标。以下将详细介绍如何下载、编译、安装这些插件,并通过示例展示如何建立支持繁简转换和IK分词的ES索引,最后通过实际数据插入和检索验证配置的效果。
2. 引入繁简转换插件analysis-stconvert
插件地址: https://github.com/infinilabs/analysis-stconvert/releases
2.1 下载已有作者编译后的包文件
如果存在可直接使用的zip文件,选择与自己版本一致的版本
2.2 下载源码进行编译
如果没有下载即可使用的安装包,需要自己下载源码进行编译。下载打开后使用mvn clean install进行打包

如果报错信息如下:
[ERROR] COMPILATION ERROR :
[INFO] -------------------------------------------------------------
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertAnalyzerProvider.java:[28,9] 无法将类 org.elasticsearch.index.analysis.AbstractIndexA
nalyzerProvider<T>中的构造器 AbstractIndexAnalyzerProvider应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings找到: java.lang.String,org.elasticsearch.common.settings.Settings原因: 实际参数列表和形式参数列表长度不同
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertTokenFilterFactory.java:[31,9] 无法将类 org.elasticsearch.index.analysis.AbstractToke
nFilterFactory中的构造器 AbstractTokenFilterFactory应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings找到: java.lang.String,org.elasticsearch.common.settings.Settings原因: 实际参数列表和形式参数列表长度不同
[ERROR] /E:/project/PersonalProjects/analysis-stconvert-7.17.11/analysis-stconvert-7.17.11/src/main/java/org/elasticsearch/index/analysis/STConvertCharFilterFactory.java:[34,9] 无法将类 org.elasticsearch.index.analysis.AbstractCharF
ilterFactory中的构造器 AbstractCharFilterFactory应用到给定类型;需要: org.elasticsearch.index.IndexSettings,java.lang.String找到: java.lang.String原因: 实际参数列表和形式参数列表长度不同
[INFO] 3 errors
[INFO] -------------------------------------------------------------
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
下面类中,增加如下参数,标红报错不需要处理仍可以打包成功

打包成功后可以在项目目录\target\releases看到编译后的压缩包elasticsearch-analysis-stconvert-7.17.11.zip
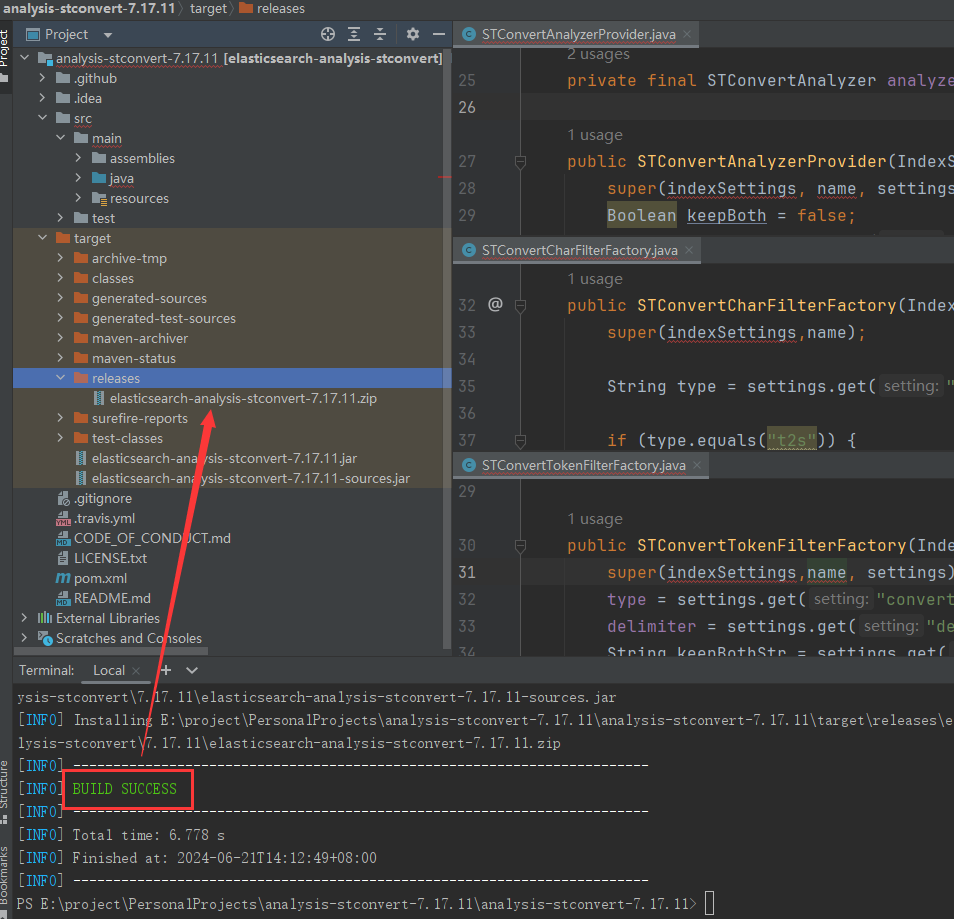
2.3 复制解压插件到es安装目录的plugins文件夹下

es数据库启动时会自动加载插件,如下输出即表示引入成功
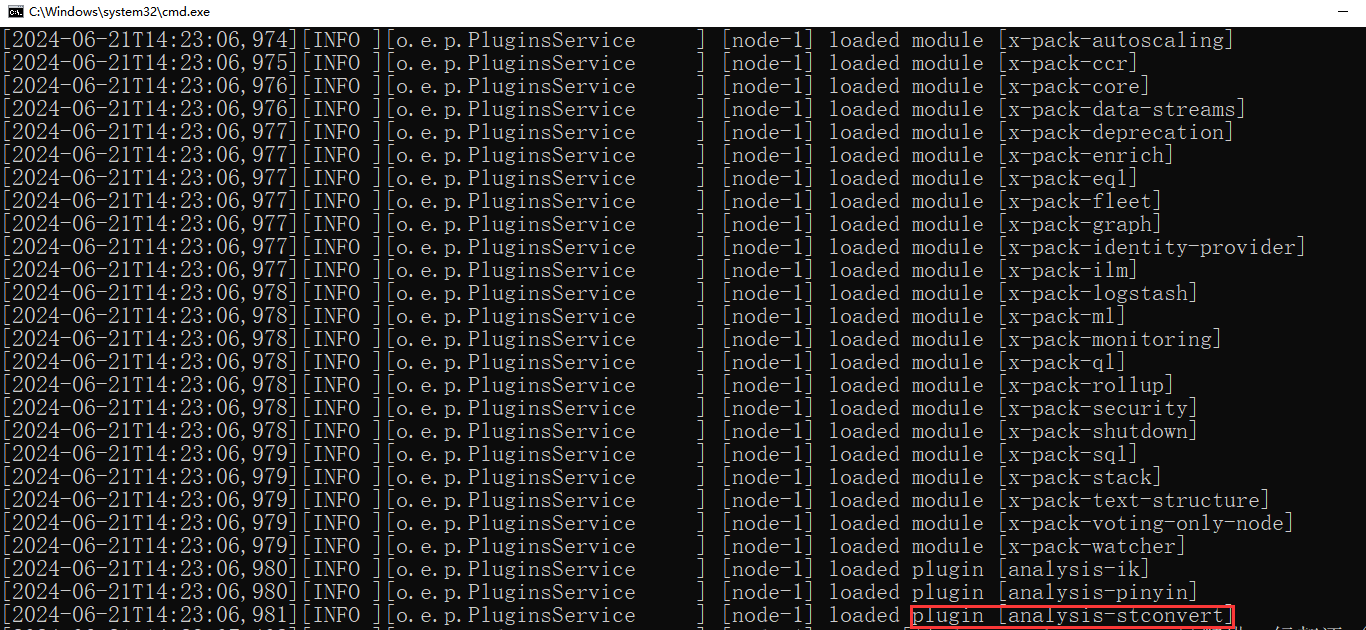
3. 引入ik分词器插件
GitHub下载地址:Releases · infinilabs/analysis-ik · GitHub
3.1 已有作者编译后的包文件
选择与所需es版本相同的ik分词器,下载已经打包后的.zip文件

3.2 只有源代码的版本
首先下载源码解压后使用idea打开,修改es版本与分词器版本相同
使用 mvn clean install 打包时报错:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.5.1:compile (default-compile) on project elasticsearch-analysis-ik: Compilation failure
[ERROR] /D:/PersonalProjects/analysis-ik-7.17.11/analysis-ik-7.17.11/src/main/java/org/elasticsearch/index/analysis/IkAnalyzerProvider.java:[13,9] 无法将类 org.elasticsearch.index.analysis.AbstractIndexAnalyzerProvider<T>中的构造器
AbstractIndexAnalyzerProvider应用到给定类型;
[ERROR] 需要: org.elasticsearch.index.IndexSettings,java.lang.String,org.elasticsearch.common.settings.Settings
[ERROR] 找到: java.lang.String,org.elasticsearch.common.settings.Settings
修改代码报错部分:增加indexSetting参数到super入参的第一个位置

使用mvn clean install进行打包,注意我们所需的是/target/release目录下的.zip压缩包

3.3 安装ik分词插件
将下载或者编译后的.zip文件解压到es的安装目录下的plugins目录下,并重命名为ik
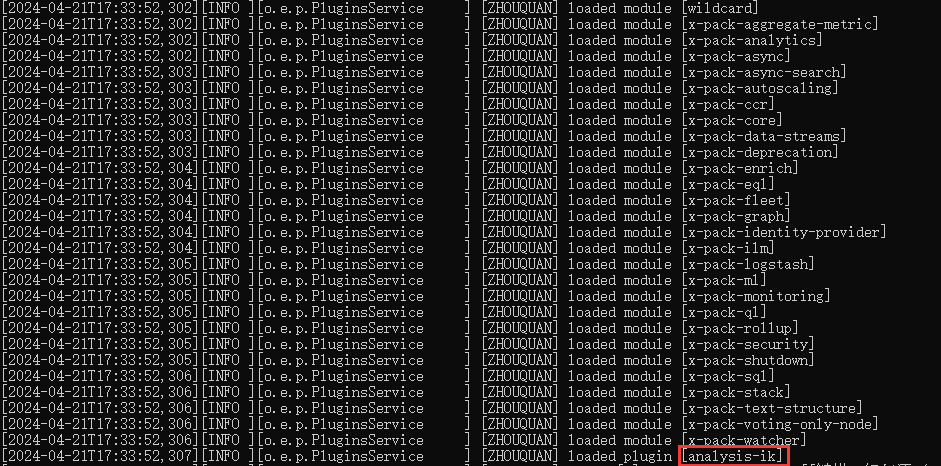
然后启动es,查看日志可发现已经加载的ik分词器
常规的最常用的使用方式就是,数据插入存储时用 ik_max_word模式分词,而检索时,用ik_smart模式分词,即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
4. 建立IK和繁简集成的es索引
PUT http://localhost:9200/test/
{"aliases": {},"settings": {"index": {"refresh_interval": "3s","number_of_shards": "3","number_of_replicas": "1","max_inner_result_window": "10000","max_result_window": "20000","analysis": {"analyzer": {"ik_max_word_convert": {"type": "custom","char_filter": ["tsconvert","stconvert"],"tokenizer": "ik_max_word","filter": ["lowercase"]},"ik_smart_convert": {"type": "custom","char_filter": ["tsconvert","stconvert"],"tokenizer": "ik_smart","filter": ["lowercase"]}}}}},"mappings": {"properties": {"otherTitle": {"type": "text","analyzer": "ik_max_word_convert","search_analyzer": "ik_smart_convert"}}}
}
analysis部分定义了自定义分析器:
- ik_max_word_convert:
- type:
"custom":定义一个自定义分析器。 - char_filter:
tsconvert: 自定义字符过滤器(用于繁体到简体转换)。stconvert: 自定义字符过滤器(用于简体到繁体转换)。
- tokenizer:
"ik_max_word"- 使用IK分析器的最大词语分割。 - filter:
["lowercase"]- 将所有字符转换为小写。
- type:
- ik_smart_convert:
- type:
"custom" - char_filter:
tsconvertstconvert
- tokenizer:
"ik_smart" - filter:
["lowercase"]
- type:
5. 新增数据测试检索
新增测试数据
PUT /test/_doc/2
{"nickName":"語法講義"
} PUT /test/_doc/3
{"nickName":"语法讲义"
}
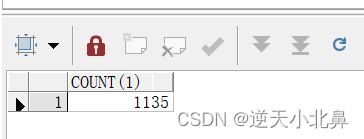
中文简写查询
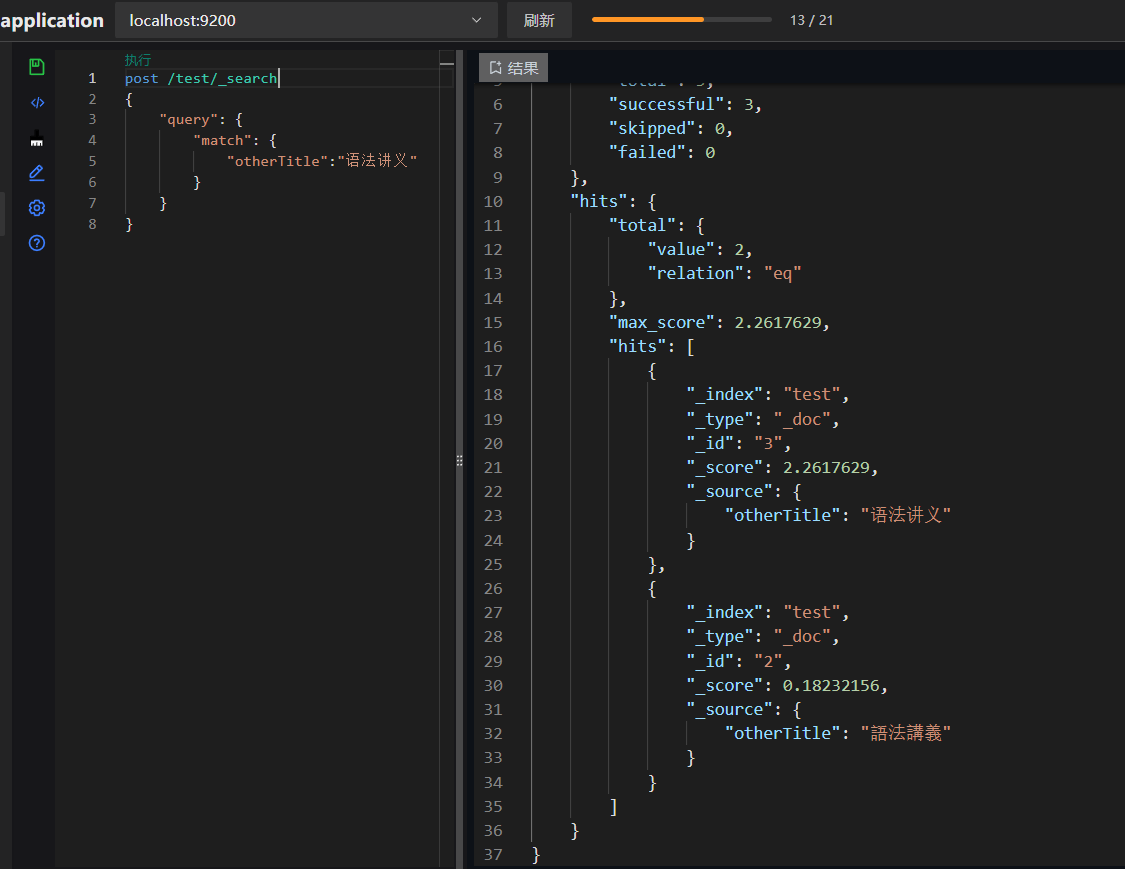
中文繁体查询

通过上述配置和测试,我们可以看到无论是简体输入还是繁体输入,ES都能正确检索到相关文档。这证明了我们引入的繁简转换和IK分词插件的有效性,以及自定义分析器配置的正确性