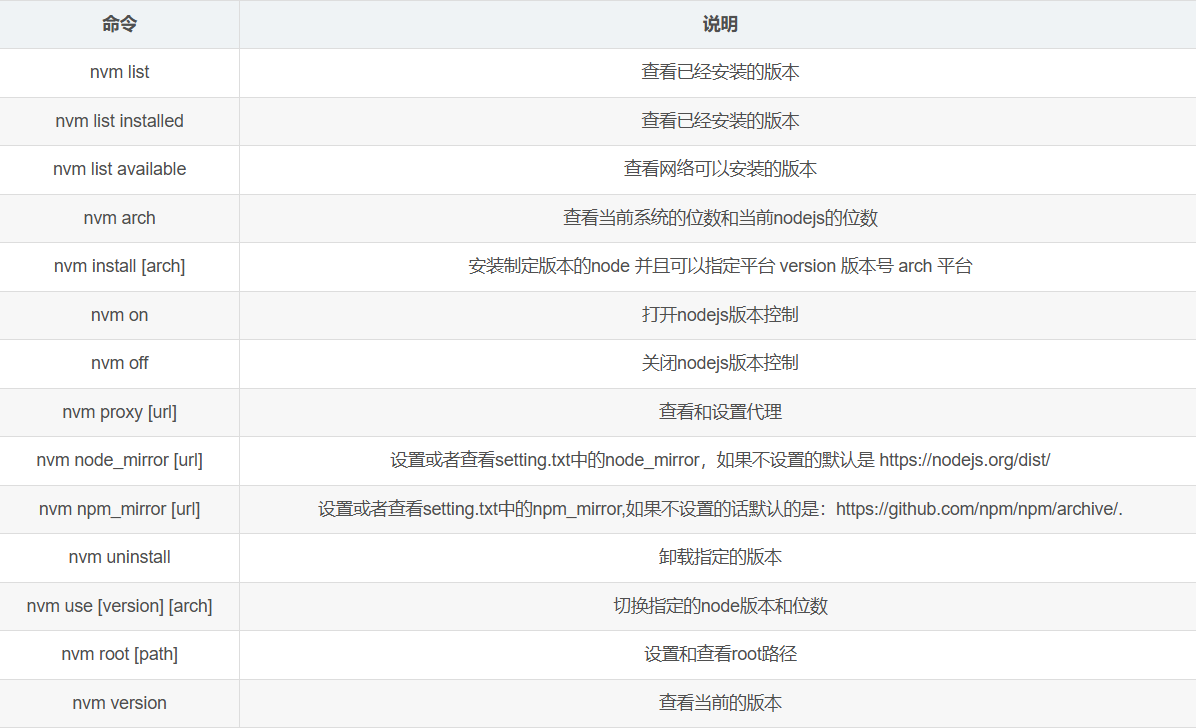
目录
- PriorityQueue详解
- 1、PriorityQueue简介
- 2、PriorityQueue继承体系
- 3、PriorityQueue数据结构
- PriorityQueue类属性注释
- 完全二叉树、大顶堆、小顶堆的概念
- ☆PriorityQueue是如何利用数组存储小顶堆的?
- ☆利用数组存储完全二叉树的好处?
- 4、PriorityQueue的`offer`方法
- 动画演示offer插入过程:
- 5、PriorityQueue的`grow`方法
- 6、PriorityQueue的`poll`方法
- 动画演示`poll`移除堆顶元素过程:
- 7、PriorityQueue的其`remove`方法
- 注意点:如果remove指定元素
- 8、PriorityQueue的其他方法`element peak`
- 补充
- 列表、哈希表、栈、队列、双向队列、阻塞队列基本方法参考
PriorityQueue详解
1、PriorityQueue简介
PriorityQueue 是 Java 集合框架中的一部分,位于java.util包下,它实现了一个基于优先级的无界队列。
在 PriorityQueue 中,队头的元素总是具有最高优先级的元素。这对于需要快速访问最小(或最大,取决于构造方式)元素的场景非常有用。
特点:
- ①、有序性:自动维护队列元素的排序,通常是按照自然顺序或提供的比较器进行排序。
- ②、无界:PriorityQueue 是无界的,意味着它可以动态地扩容。
- ③、性能:提供了对头部元素的快速访问,插入和删除操作(offer、poll)的平均时间复杂度为 O(log(n)),其中 n 是队列中的元素数量。
- ④、堆实现:内部通过一个完全二叉树(以数组形式存储,即堆[小顶堆或大顶堆])来实现。
- ⑤、非线程安全:PriorityQueue 不是线程安全的,如果需要在多线程环境中使用,应考虑使用 PriorityBlockingQueue。
使用场景:
实现优先级调度算法。
维护一个经常变动但需要快速访问最小值的数据集合,如事件驱动模拟中的事件队列。
2、PriorityQueue继承体系
public class PriorityQueue<E> extends AbstractQueue<E>implements java.io.Serializable

可以看到PriorityQueue就是实现了Queue接口,拥有普通队列的一些功能。由于其具有自动优先级排序的功能而比较特殊。
3、PriorityQueue数据结构
PriorityQueue类属性注释
public class PriorityQueue<E> extends AbstractQueue<E>implements java.io.Serializable {private static final int DEFAULT_INITIAL_CAPACITY = 11;/*** 用平衡二叉堆表示的优先队列:queue[n]的两个子节点是queue[2*n+1]和queue[2*(n+1)]。* 优先队列按照比较器(comparator)排序,如果比较器为空,则按元素的自然顺序排序:* 对于堆中的每个节点n及其每个后代d,都有n <= d。假设队列非空,值最小的元素在queue[0]中。*/transient Object[] queue;/*** 优先队列中的元素数量。*/private int size = 0;/*** 比较器,如果优先队列使用元素的自然顺序,则为空。*/private final Comparator<? super E> comparator;}注意点:
我们主要来看下面这段注释
/*** 用小顶堆表示的优先队列:queue[n]的两个子节点是queue[2*n+1]和queue[2*(n+1)]。* 优先队列按照比较器(comparator)排序,如果比较器为空,则按元素的自然顺序排序:* 对于堆中的每个节点n及其每个后代d,都有n <= d。假设队列非空,值最小的元素在queue[0]中。*/transient Object[] queue;
PriorityQueue本质上还是使用Object[]数组来存储元素,只不过其存储的位置符合小顶堆的结构。
完全二叉树、大顶堆、小顶堆的概念
完全二叉树(Complete Binary Tree):
是指所有层都被完全填满的二叉树,除了最后一层节点可以不完全填满,但节点必须从左到右排列。
完全二叉树示例:
1/ \2 3/ \4 5大顶堆(Max Heap):
大顶堆是一种特殊的完全二叉树,其中每个节点的值都大于或等于其子节点的值。
也就是说根节点是所有节点中最大的。
大顶堆示例:
10/ \9 8/ \ / \7 6 5 4小顶堆(Min Heap):
小顶堆也是一种特殊的完全二叉树,其中每个节点的值都小于或等于其子节点的值。
也就是说,根节点是所有节点中最小的。
小顶堆示例:
1/ \2 3/ \ / \4 5 6 7总结:
完全二叉树:强调树的形态,所有节点从左到右依次填满。
大顶堆和小顶堆:不仅是完全二叉树,还在此基础上增加了节点值的排序要求,确保堆顶元素是最大值(大顶堆)或最小值(小顶堆)。
☆PriorityQueue是如何利用数组存储小顶堆的?
以下面的小顶堆为例,转为数组存储:
1/ \2 3/ \ / \4 5 6 7我们知道像HashMap存储红黑树都是使用的TreeNode<K,V>对象,这个对象里面有 parent、left、right指针来指向当前树节点的父节点、左右子节点。
我们如果想用数组来存储树节点的元素,就必须能够根据其中一个节点得到其父节点和左右子节点。
那么直接按照层序遍历存储把上面的小顶堆转为数组:
[1,2,3,4,5,6,7]
如何根据其中一个节点就能够得到其父节点和左右子节点呢?
答案是:
对于完全二叉树而言(上面说了小顶堆是特殊的完全二叉树) ,按照层序遍历顺序存储在数组中的元素索引位置是有固定规律的。
我们看下 元素1的索引是0,左子结点元素是2、对应索引位置是1,右子结点元素是3、对应索引位置是2。
1,2,3这三个元素的索引位置 为 0, 1, 2
我们再看下 元素2的索引是1,左子结点元素是4、对应索引位置是3, 右子结点元素是5、对应索引位置是4。
2,4,5这三个元素的索引位置 为 1, 3, 4
我们列出上面的位置信息:
| 当前节点索引位置 | 左子节点索引位置 | 右子节点索引位置 |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
如果还看不出来规律没关系,我们再找一个元素3的索引是2,左子结点元素是6、对应索引位置是5, 右子结点元素是7、对应索引位置是6。
3,6,7这三个元素的索引位置 为 2, 5, 6
这个时候再列出位置信息:
| 当前节点索引位置 | 左子节点索引位置 | 右子节点索引位置 |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
是不是就很容易得出规律了: 假设某个元素的索引位置是i, 那么:
该元素左节点索引位置= 2*i+1
该元素右节点索引位置= 2*i+2
我们再反推,对于 该元素左节点来说,该元素就是其左子节点元素的父节点:
由左子节点元素索引位置反推父节点元素索引位置:
父节点元素索引位置=(i-1)/2
由右子节点元素索引位置反推父节点元素索引位置:
父节点元素索引位置= (i-2)/2
如何把父节点元素索引位置的反推结果统一呢?
直接取 父节点元素索引位置=(i-1)/2即可,因为一个有效的索引位置应该是大于等于0的正整数,对于计算父节点元素索引位置来说, i 是大于0的,因为索引位置0是根节点,根节点没有父节点。 因此在i>0且取正整数的情况下 (i-1)/2 与 (i-2)/2 得到的结果是一致的。因为Java中整数类型的运算会丢弃小数部分。
比如(1-1)/2 和 (1-2)/2 都等于0,这正好说明索引位置1和索引位置2的元素的父节点索引位置是0,也就是根节点。
这个时候再看上面 对于属性 transient Object[] queue;的注释就能看懂了。
数组中第一个元素存放的是小顶堆的根节点也就是最小的元素,对于任意索引位置 i 的元素,其左子结点的索引为2*i+1,其右子结点的索引为2*i+2, 父节点的索引为(i-1)/2。
这个时候我们知道一个元素的位置就能推导出其父节点和左右子节点的位置,所以就能够用数组来存储二叉堆结构的树节点了。
这里再补充一个知识点,因为上面一会儿 二叉树,完全二叉树,二叉堆,大顶堆,小顶堆,别干懵了。
二叉树: 是一种通用的数据结构,用于表示具有层级关系的数据。
完全二叉树: 是二叉树的一种特殊形式,除了最后一层外,所有层都是满的,最后一层的节点尽可能靠左。
二叉堆: 是基于完全二叉树的堆数据结构,分为大顶堆和小顶堆,用于实现优先队列和堆排序等。
☆利用数组存储完全二叉树的好处?
上面其实就是计算按照层序遍历的顺序存储的完全二叉树的数组,其树节点的位置在数组中的关系。
好处还是比较多的:
-
①、空间利用高效
由于完全二叉树的节点是紧凑排列的,除了最后一层外每一层都是满的,因此可以高效地利用数组空间,没有空洞。相对于指针实现(如链表),数组存储方式节省了存储指针的额外空间。 -
②、索引计算简单
在完全二叉树中,通过数组存储,父节点和子节点的关系可以通过简单的算术运算来确定:
左子节点索引:2i + 1
右子节点索引:2i + 2
父节点索引:(i - 1) / 2 -
③、随机访问高效
数组允许通过索引进行O(1)时间复杂度的随机访问。这比链表结构要快得多,在需要频繁访问节点的场景下特别有用。 -
④、内存局部性好
数组在内存中是连续存储的,利用了缓存的局部性原理(cache locality),因此在遍历或访问树的过程中可以提高内存访问速度。 -
⑤、堆操作实现简洁
利用数组存储完全二叉树简化了很多操作的实现,比如堆操作(插入、删除、调整)的实现都变得相对简洁。像堆排序、优先队列(PriorityQueue)等数据结构,都能高效地利用数组存储完全二叉树。 -
⑥、避免复杂指针操作
数组存储方式避免了复杂的指针操作,减少了指针操作带来的潜在错误风险(如空指针等问题),代码更为简洁和安全。
4、PriorityQueue的offer方法
上面了解了PriorityQueue的数据存储结构之后,再详细看下具体的代码实现。
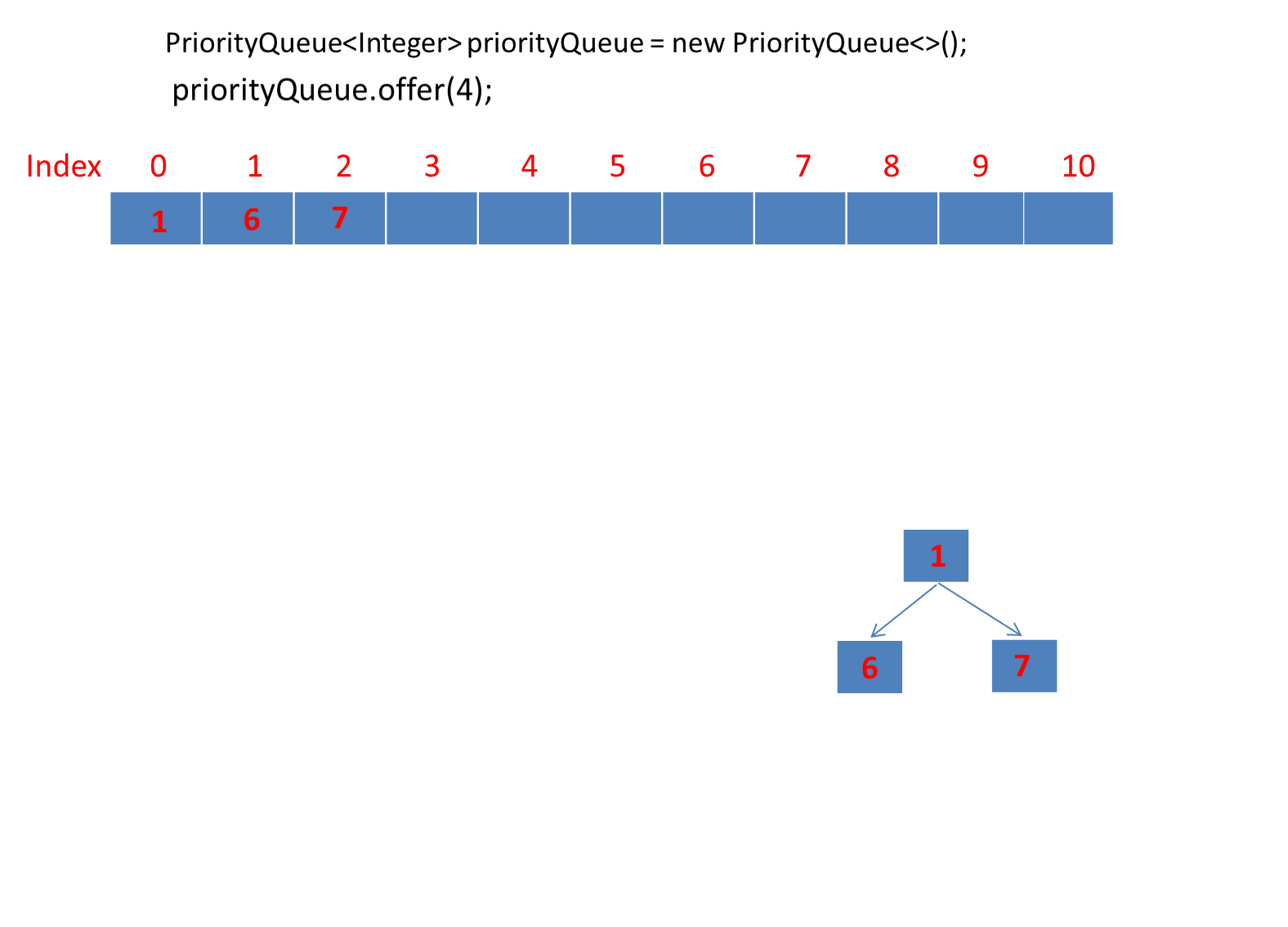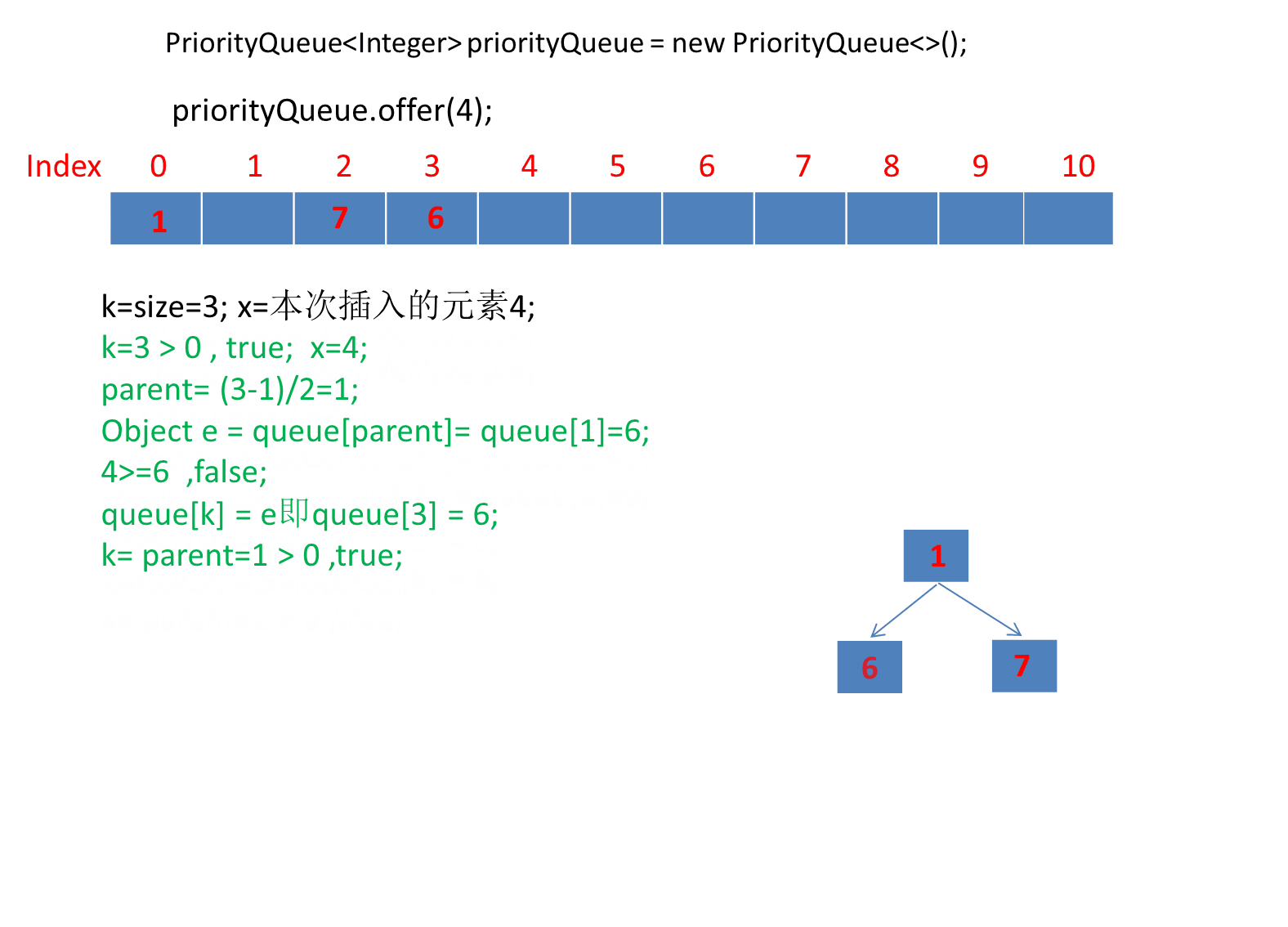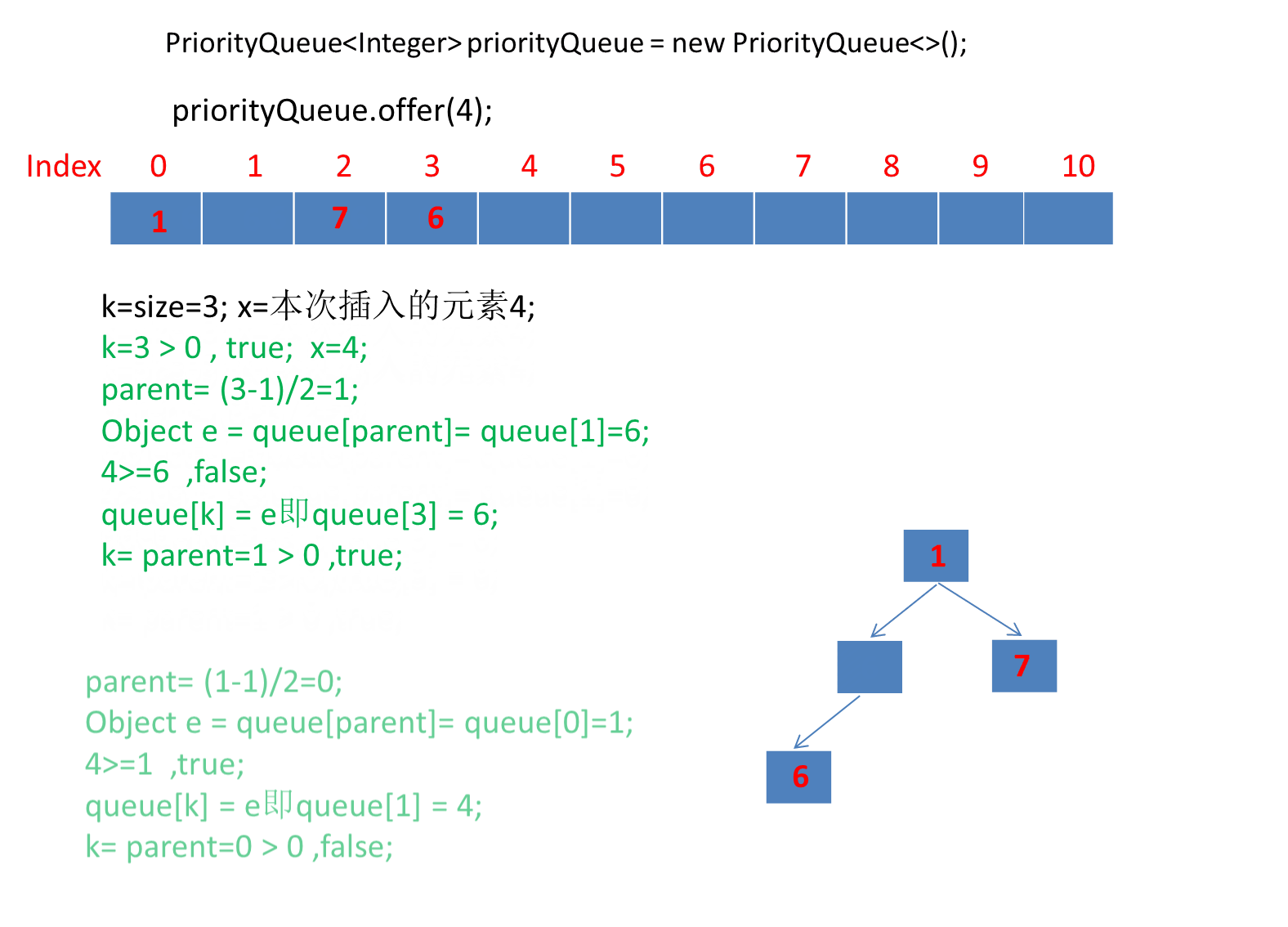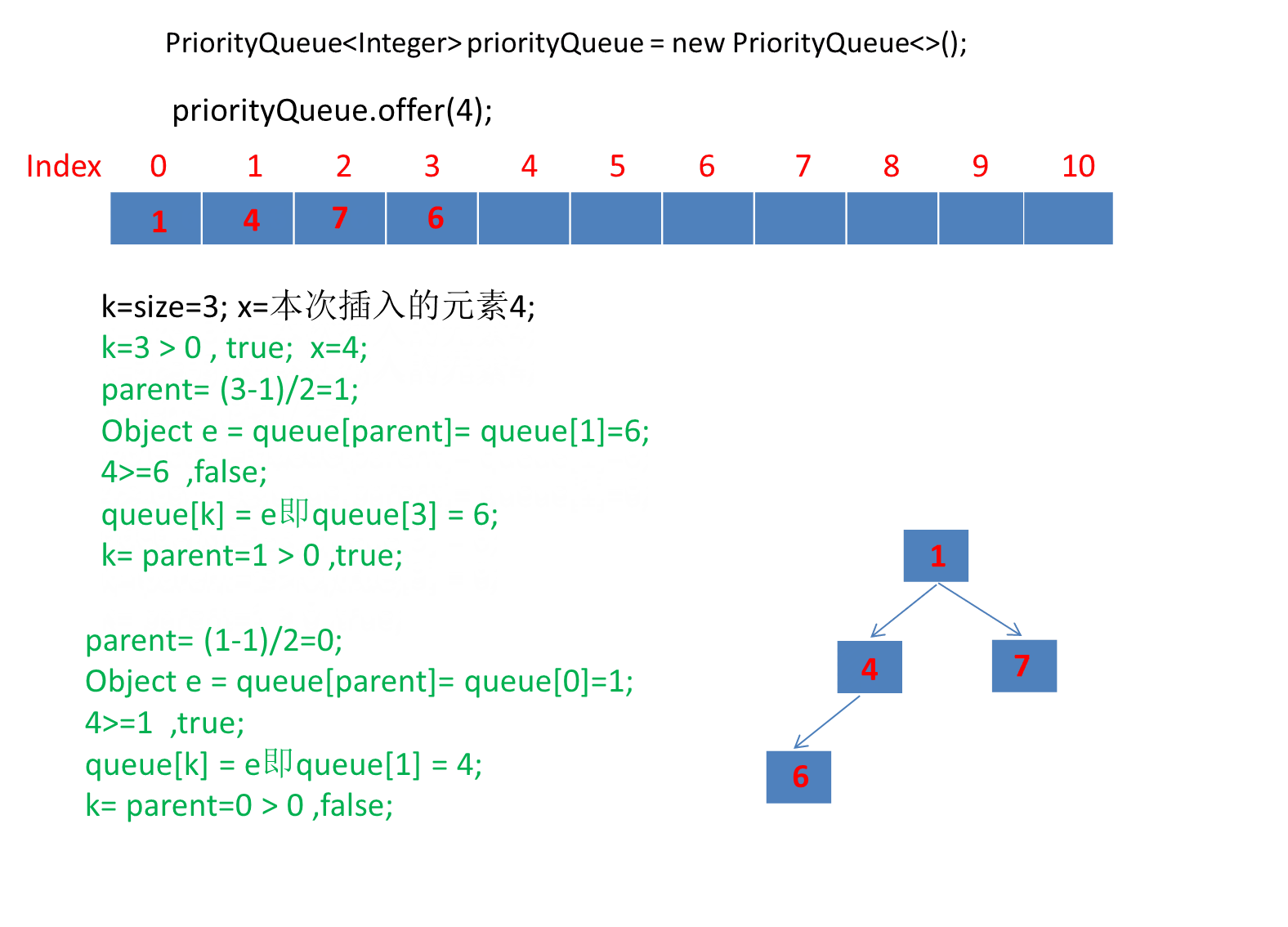
public boolean offer(E e) {// 如果插入的元素为空,抛出空指针异常if (e == null)throw new NullPointerException();// 更新修改计数,用于并发控制modCount++;// 当前队列的大小int i = size;// 如果当前大小已经达到数组的容量,需要扩容if (i >= queue.length)grow(i + 1);// 增加队列的大小size = i + 1;// 如果这是插入的第一个元素,直接放在队列的第一个位置if (i == 0)queue[0] = e;else// 否则,需要进行上浮操作以维持堆的性质siftUp(i, e);return true;}private void siftUp(int k, E x) {// 如果有比较器,使用比较器进行上浮if (comparator != null)siftUpUsingComparator(k, x);else// 否则使用元素自身的比较方法进行上浮siftUpComparable(k, x);}private void siftUpUsingComparator(int k, E x) {while (k > 0) {// 找到父节点的位置 无符号右移一位 相当于 (k-1)/2 就是上面我们说的父节点位置int parent = (k - 1) >>> 1;// 获取父节点的元素Object e = queue[parent];// 如果插入的元素大于等于父节点的元素,停止上浮if (comparator.compare(x, (E) e) >= 0)break;// 否则,将父节点的元素下移到当前位置queue[k] = e;// 更新当前位置为父节点的位置,继续上浮k = parent;}// 将插入的元素放到最终位置queue[k] = x;}private void siftUpComparable(int k, E x) {// 将插入元素强制转换为Comparable类型Comparable<? super E> key = (Comparable<? super E>) x;while (k > 0) {// 找到父节点的位置int parent = (k - 1) >>> 1;// 获取父节点的元素Object e = queue[parent];// 如果插入的元素大于等于父节点的元素,停止上浮if (key.compareTo((E) e) >= 0)break;// 否则,将父节点的元素下移到当前位置queue[k] = e;// 更新当前位置为父节点的位置,继续上浮k = parent;}// 将插入的元素放到最终位置queue[k] = key;}总结下:
offer(E e) 方法:
检查空元素:如果插入的元素为 null,抛出 NullPointerException。
记录修改:增加修改计数 modCount,用于并发控制。
检查并扩容:如果当前数组容量不足,调用 grow 方法进行扩容。
增加大小:增加 size 变量。
插入第一个元素:如果这是队列中的第一个元素,直接插入到数组的第一个位置。
堆上浮:如果不是第一个元素,调用 siftUp 方法进行堆的上浮操作,以维持堆的性质。
siftUp(int k, E x) 方法:
选择上浮方法:如果有比较器 comparator,则使用 siftUpUsingComparator 方法,否则使用 siftUpComparable 方法。
siftUpUsingComparator(int k, E x) 方法:
使用提供的比较器 comparator 进行元素的比较和上浮操作。
上浮逻辑:与父节点比较,如果插入的元素小于父节点,则将父节点下移,继续上浮。
siftUpComparable(int k, E x) 方法:
强制类型转换:将插入的元素强制转换为 Comparable 类型。
上浮逻辑:与父节点比较,如果插入的元素小于父节点,则将父节点下移,继续上浮。
动画演示offer插入过程:
public static void main(String[] args) {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(6);priorityQueue.offer(1);priorityQueue.offer(7);priorityQueue.offer(4);priorityQueue.offer(5);priorityQueue.offer(2);priorityQueue.offer(3);}
由于第一个元素直接是插入数组第一个位置,所以第一个元素就直接插入了。

动画太长了这里分段演示了 。
继续演示剩下的3个元素。
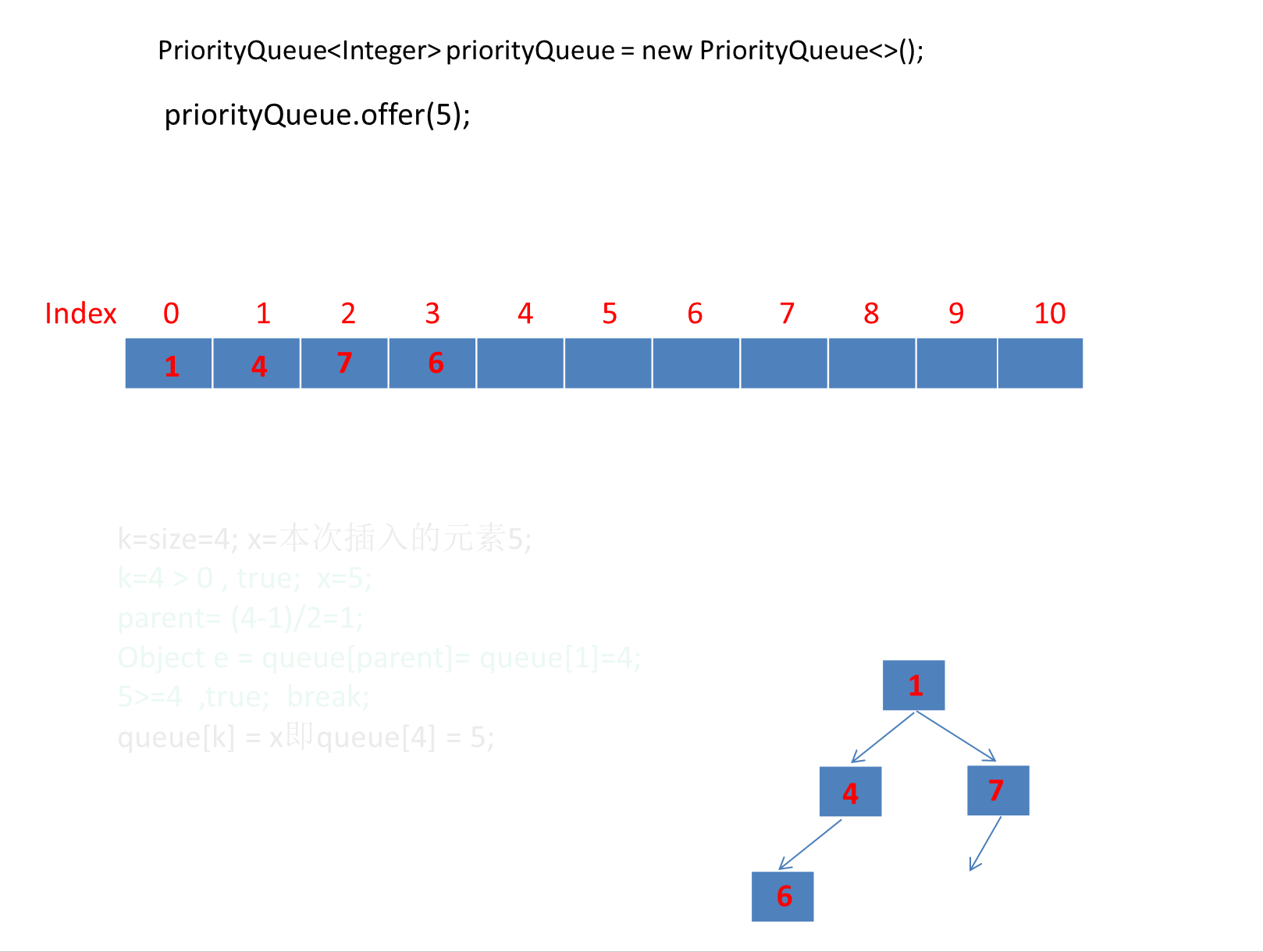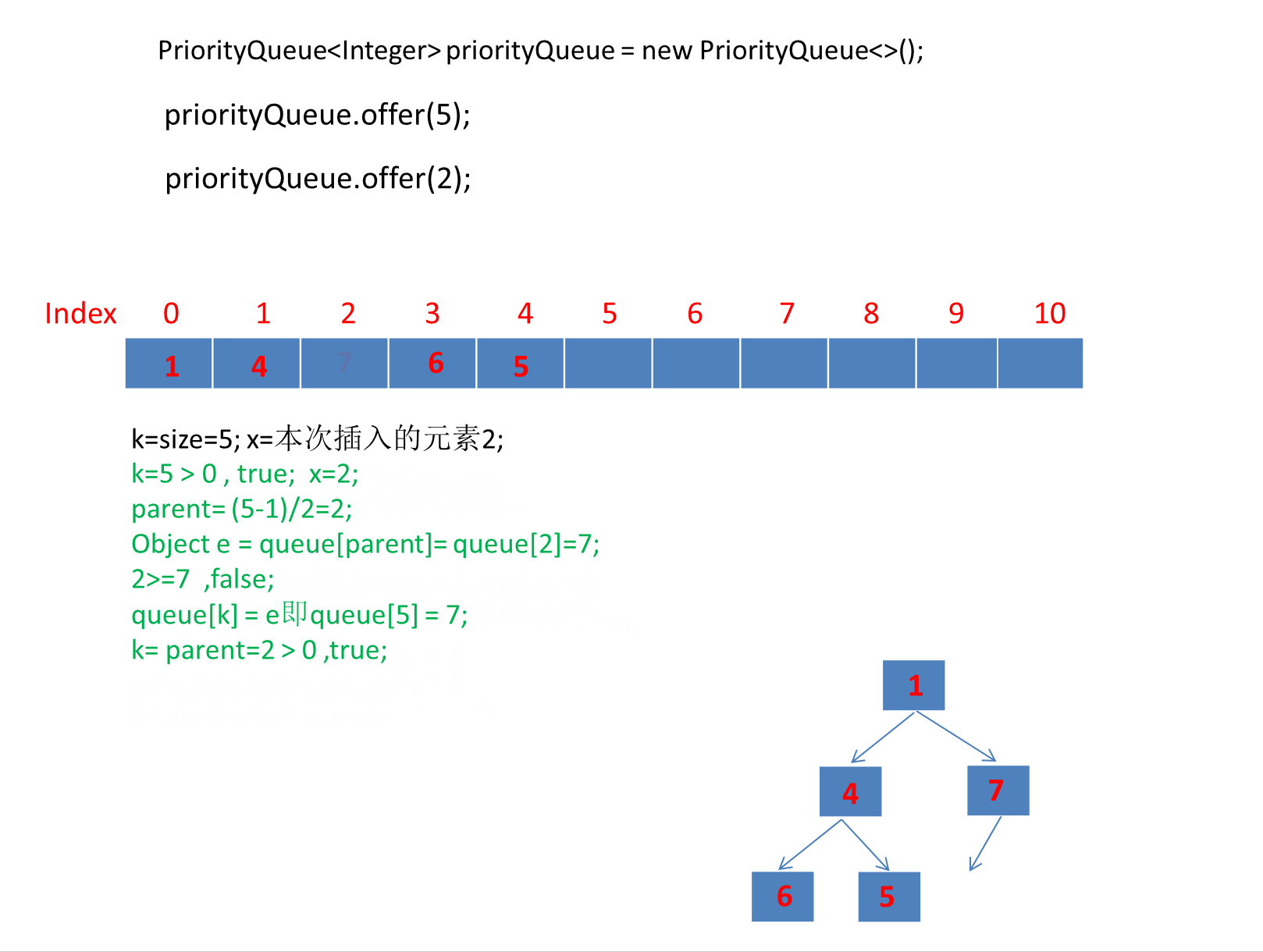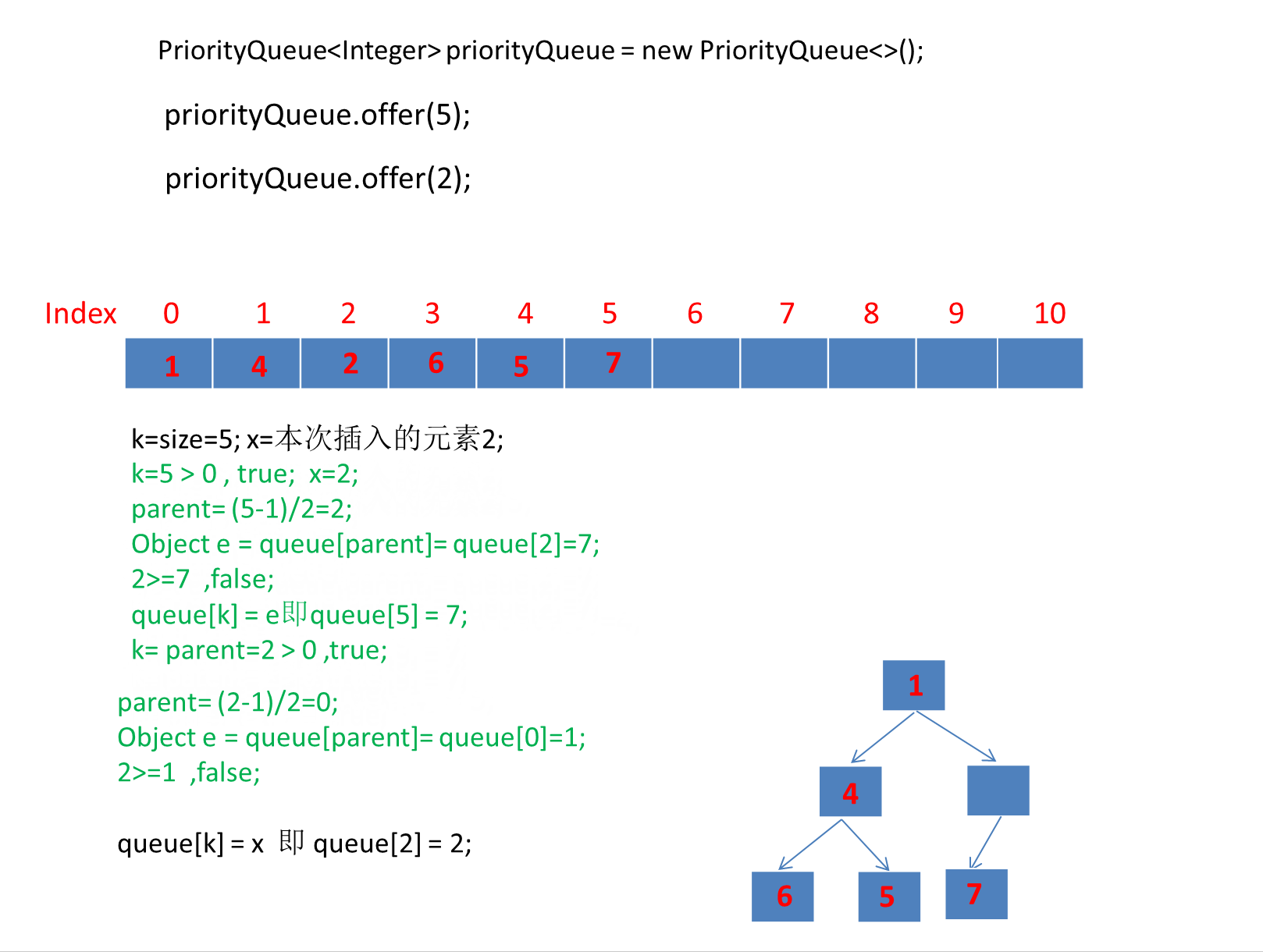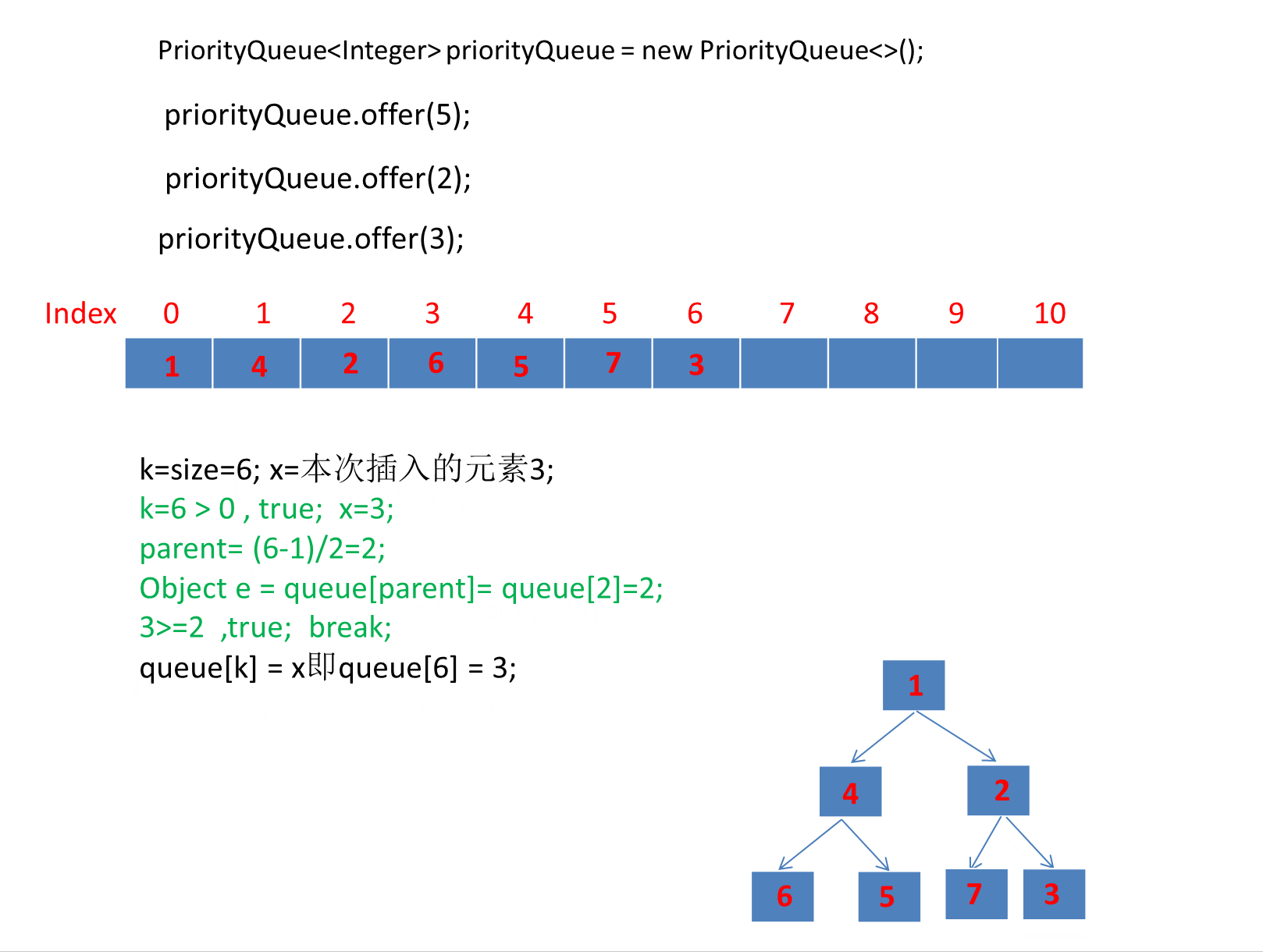
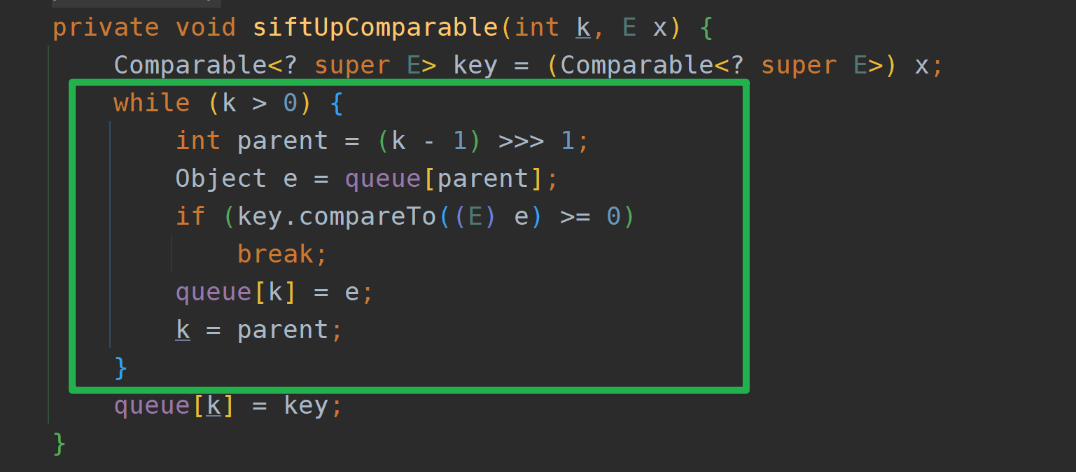
注意动画中绿色文字计算部分对应下图源码绿框内比较逻辑:
我们添加元素的顺序是 6,1,7,4,5,2,3 最终转为小顶堆存储的数组顺序是:

可以看到是符合小顶堆的定义的:
每个节点的值都小于或等于其子节点的值。
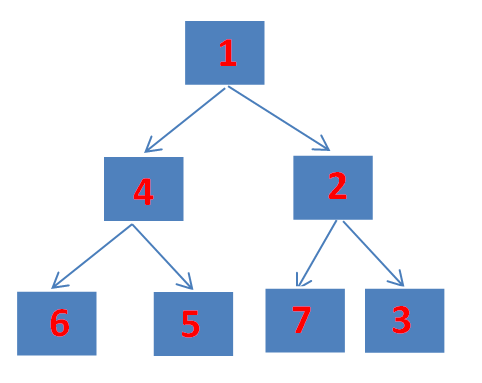
最后再利用反射获取 Object[] queue; 来验证下画的offer过程对不对
import java.lang.reflect.Field;
import java.util.Arrays;
import java.util.PriorityQueue;public class TestA {public static void main(String[] args) throws Exception {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(6);priorityQueue.offer(1);priorityQueue.offer(7);priorityQueue.offer(4);priorityQueue.offer(5);priorityQueue.offer(2);priorityQueue.offer(3);Class<? extends PriorityQueue> aClass = priorityQueue.getClass();Field queue = aClass.getDeclaredField("queue");queue.setAccessible(true);Object[] integers = (Object[]) queue.get(priorityQueue);System.out.println(Arrays.toString(integers));}
}运行结果:
可以看到和上面动画演示结果一致
[1, 4, 2, 6, 5, 7, 3, null, null, null, null]5、PriorityQueue的grow方法
又要见到老朋友了Arrays.copyOf
private void grow(int minCapacity) {// 获取当前队列的容量int oldCapacity = queue.length;// 如果当前容量小于64,则将容量增加一倍,再+2;否则,增加约50%的容量int newCapacity = oldCapacity + ((oldCapacity < 64) ?(oldCapacity + 2) :(oldCapacity >> 1));// 防止容量溢出,如果新容量超过最大数组大小,则调用hugeCapacity方法if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 使用Arrays.copyOf将数组扩容到新容量queue = Arrays.copyOf(queue, newCapacity);}总结下:
如果使用空参构造初始化的是一个容量为11的数组,当添加第十二个元素的时候开始扩容,由于当前容量是11 < 64 ,
那么扩容到 11 + 11 + 2 = 24。
可以使用代码验证下:
import java.lang.reflect.Field;
import java.util.Arrays;
import java.util.PriorityQueue;public class TestA {public static void main(String[] args) throws Exception {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(1);priorityQueue.offer(2);priorityQueue.offer(3);priorityQueue.offer(4);priorityQueue.offer(5);priorityQueue.offer(6);priorityQueue.offer(7);priorityQueue.offer(8);priorityQueue.offer(9);priorityQueue.offer(10);priorityQueue.offer(11);priorityQueue.offer(12);Class<? extends PriorityQueue> aClass = priorityQueue.getClass();Field queue = aClass.getDeclaredField("queue");queue.setAccessible(true);Object[] integers = (Object[]) queue.get(priorityQueue);System.out.println(Arrays.toString(integers));System.out.println(integers.length);}
}
运行结果:
和我们上面根据代码分析得出的结果是一致的
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, null, null, null, null, null, null, null, null, null, null, null, null]
24
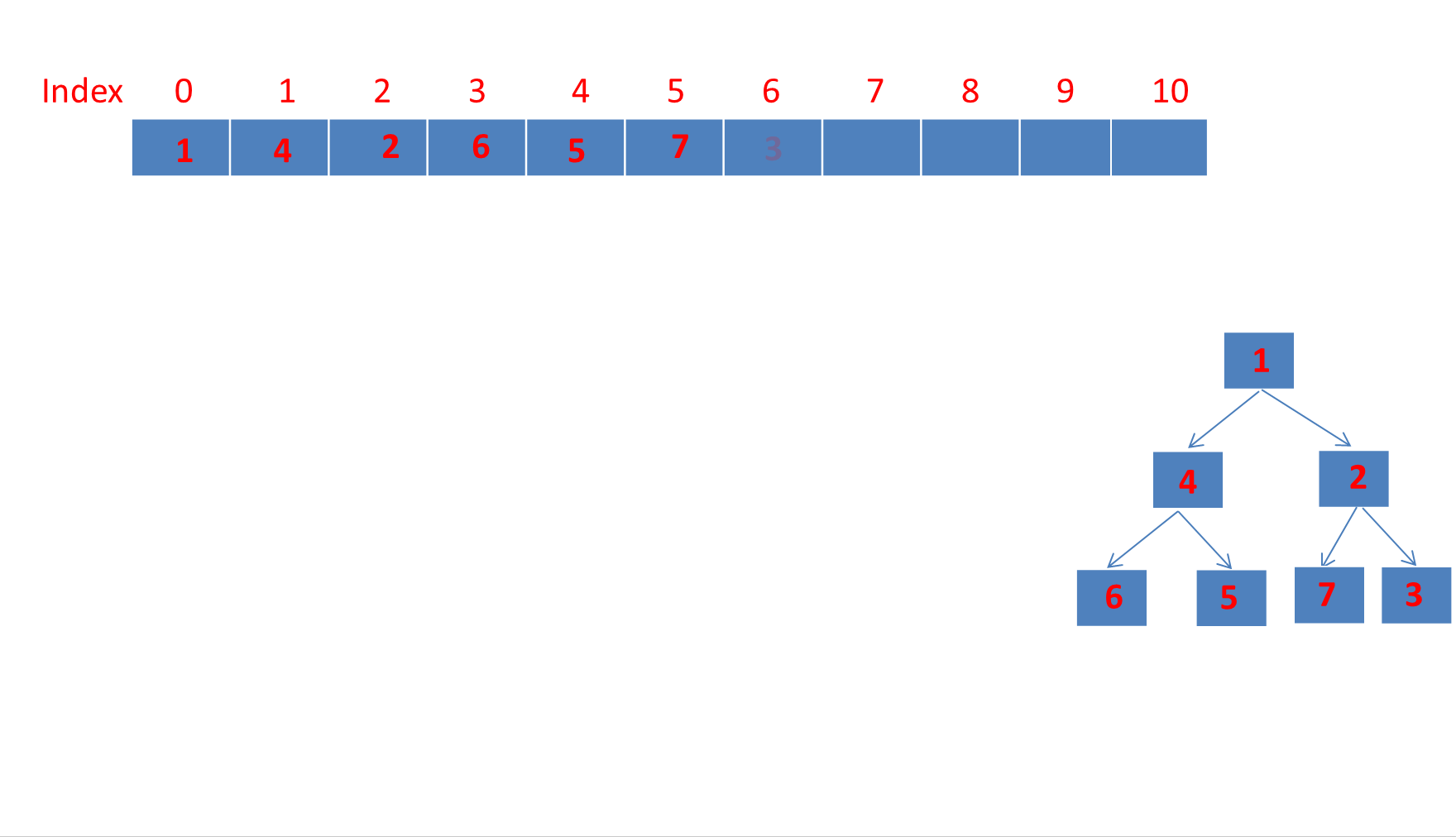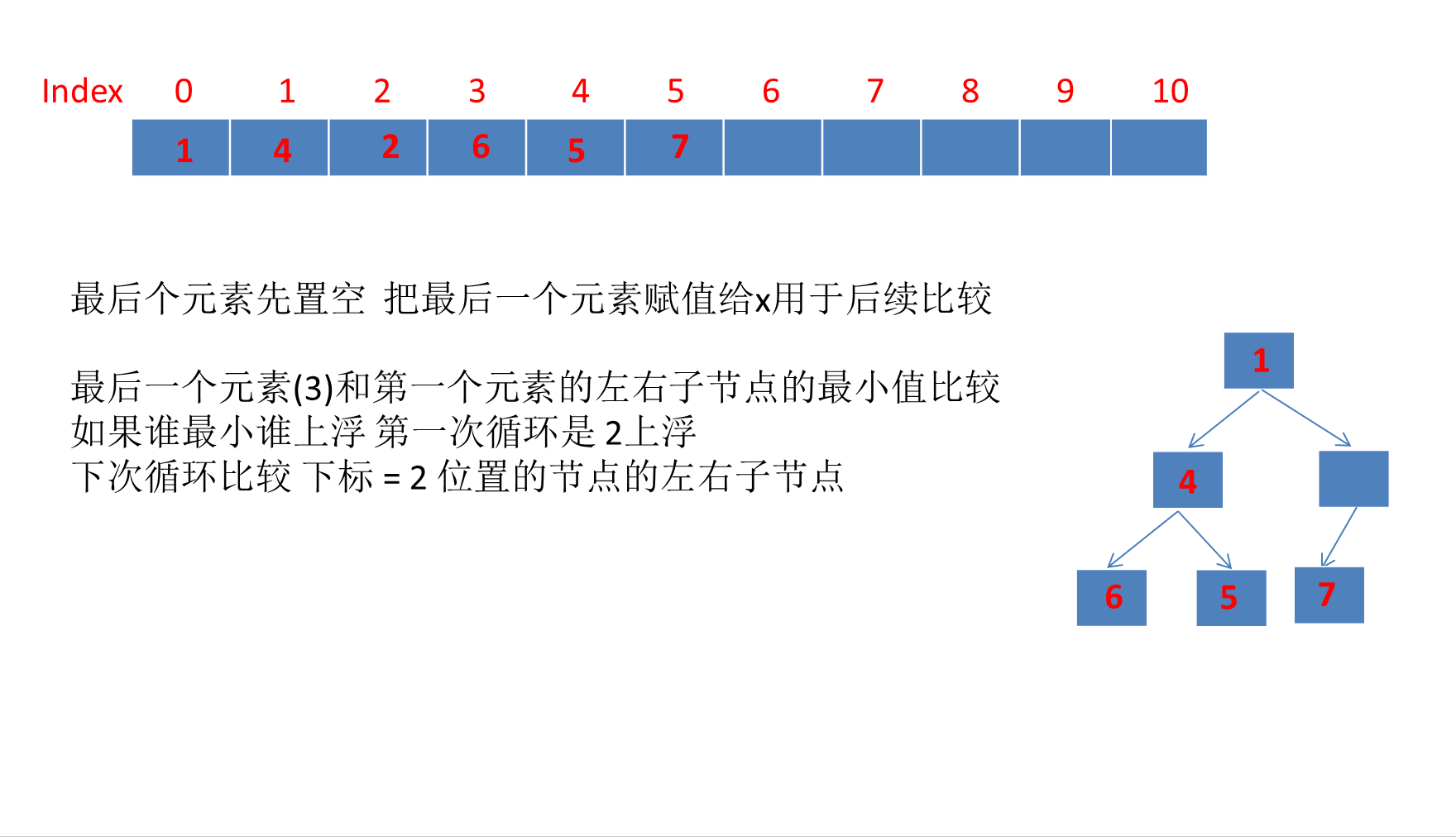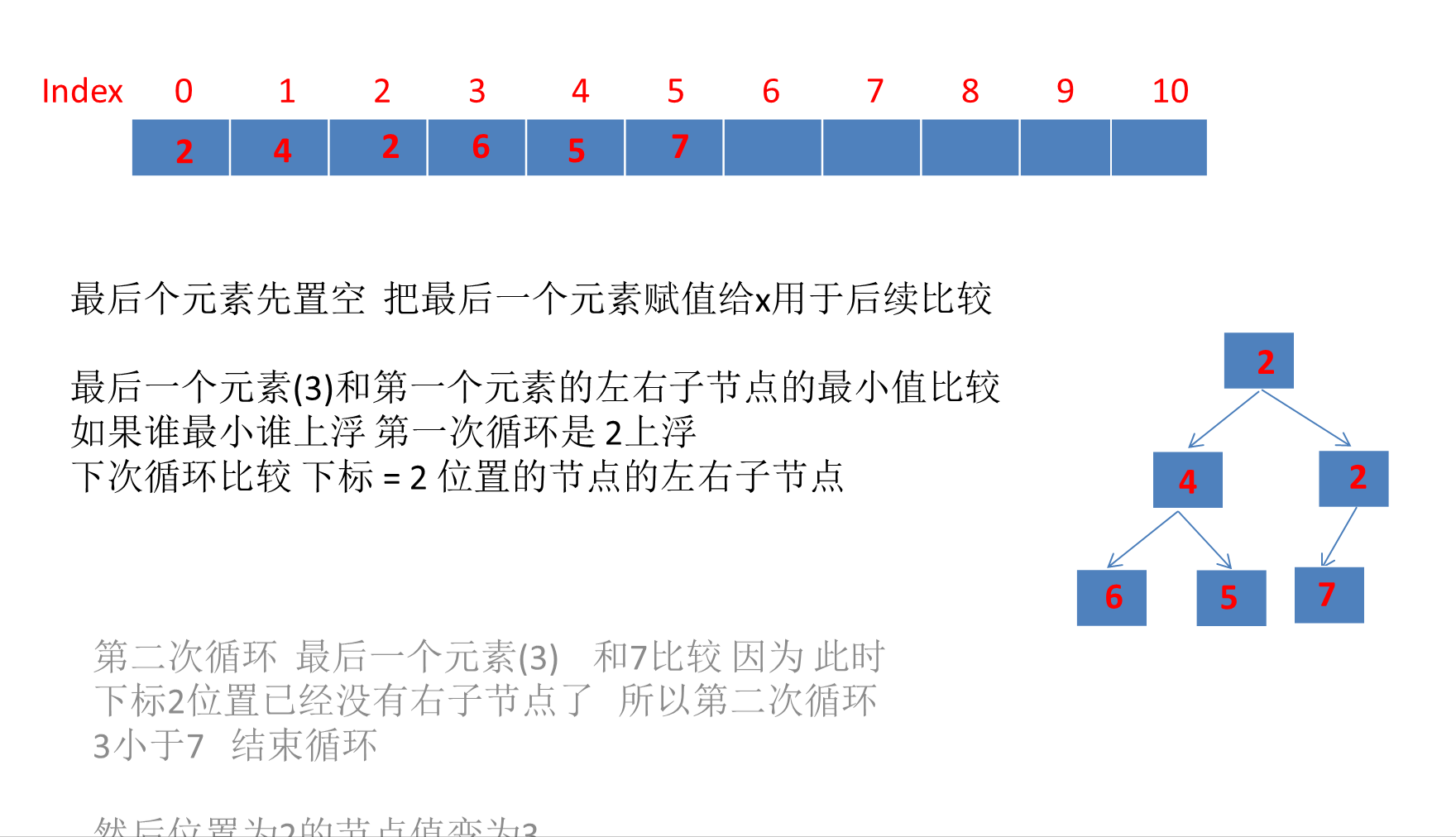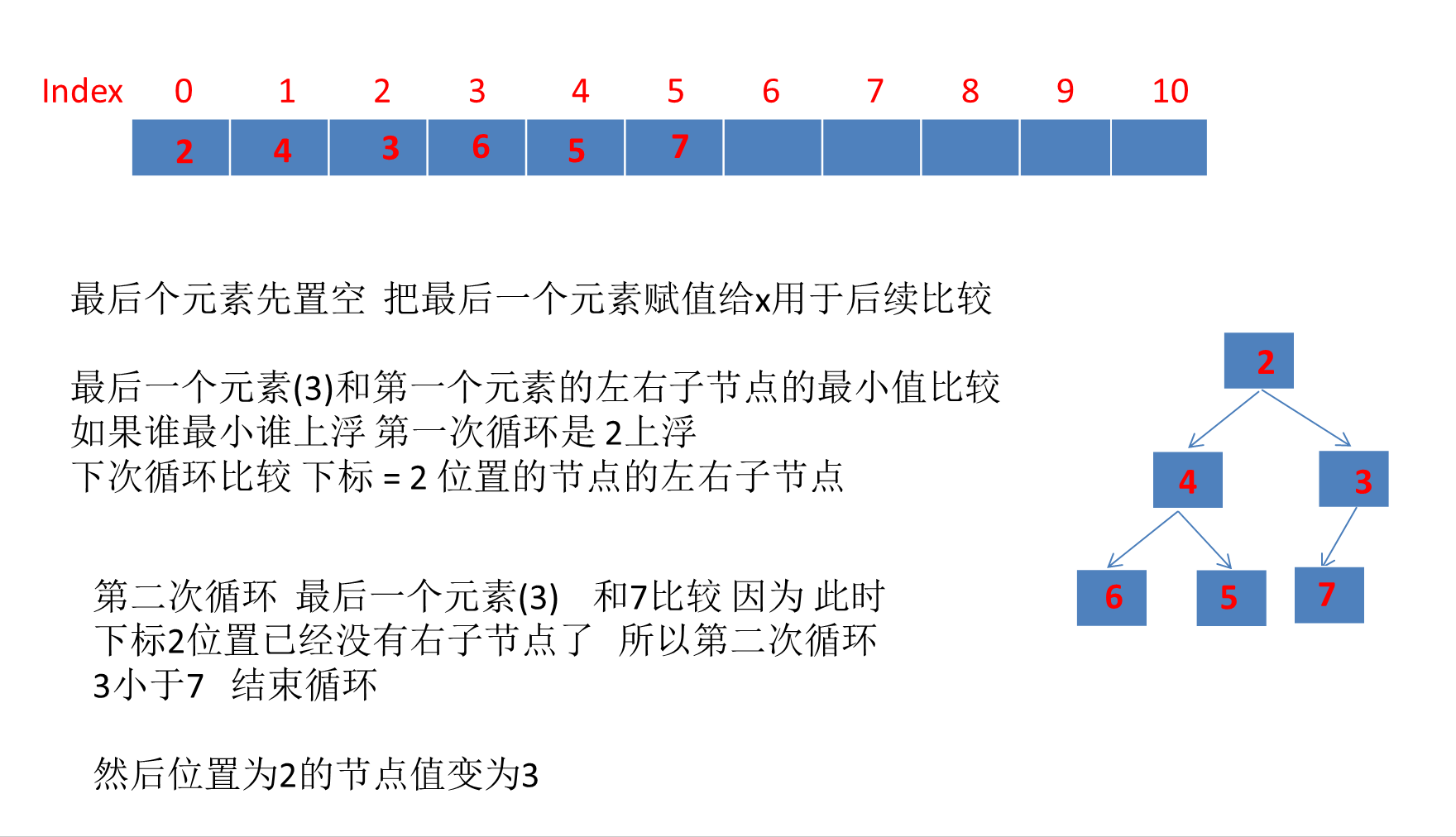
6、PriorityQueue的poll方法
poll方法用于移除并返回优先队列的头部元素(即优先级最高的元素)。如果队列为空,则返回 null。
public E poll() {if (size == 0)return null; // 如果队列为空,返回 nullint s = --size; // 减少队列的大小modCount++; // 更新操作计数(用于快速失败机制)E result = (E) queue[0]; // 获取队列头部元素(优先级最高的元素)E x = (E) queue[s]; // 获取队列最后一个元素queue[s] = null; // 将队列最后一个位置置为 null(便于垃圾回收)if (s != 0)siftDown(0, x); // 如果队列不为空,将最后一个元素下沉到合适的位置return result; // 返回优先级最高的元素
}private void siftDown(int k, E x) {if (comparator != null)siftDownUsingComparator(k, x); // 如果有比较器,使用自定义比较器进行下沉elsesiftDownComparable(k, x); // 否则,使用元素的自然顺序进行下沉
}private void siftDownComparable(int k, E x) {Comparable<? super E> key = (Comparable<? super E>) x; // 将元素转换为 Comparableint half = size >>> 1; // 计算非叶子节点的数量(所有有子节点的节点)while (k < half) { // 循环处理直到 k 位置是叶子节点int child = (k << 1) + 1; // 获取左子节点位置Object c = queue[child]; // 假设左子节点为较小的子节点int right = child + 1; // 获取右子节点位置if (right < size && ((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)c = queue[child = right]; // 如果右子节点存在且小于左子节点,则选择右子节点if (key.compareTo((E) c) <= 0)break; // 如果 x 已经小于等于子节点,则结束queue[k] = c; // 否则,将较小的子节点提升到 k 位置k = child; // 更新 k 为子节点的位置,继续下沉}queue[k] = key; // 将 x 放置在合适的位置
}private void siftDownUsingComparator(int k, E x) {int half = size >>> 1; // 计算非叶子节点的数量(所有有子节点的节点)while (k < half) { // 循环处理直到 k 位置是叶子节点int child = (k << 1) + 1; // 获取左子节点位置 相当于 2*k + 1Object c = queue[child]; // 假设左子节点为较小的子节点int right = child + 1; // 获取右子节点位置 或者 2*k + 2 if (right < size && comparator.compare((E) c, (E) queue[right]) > 0)c = queue[child = right]; // 如果右子节点存在且小于左子节点,则选择右子节点if (comparator.compare(x, (E) c) <= 0)break; // 如果 x 已经小于等于子节点,则结束queue[k] = c; // 否则,将较小的子节点提升到 k 位置k = child; // 更新 k 为子节点的位置,继续下沉}queue[k] = x; // 将 x 放置在合适的位置
}总结下:
poll 方法通过以下步骤实现优先队列的出队操作:
检查队列是否为空,若为空返回 null。
获取并移除队列的最后一个元素。
将优先队列的头部元素与最后一个元素进行交换。
通过 siftDown 方法将交换后的元素下沉到合适的位置,直到维持了小顶堆的性质。
返回原来的头部元素,即优先级最高的元素。
动画演示poll移除堆顶元素过程:
源码中可以看出获取堆顶元素非常简单
E result = (E) queue[0]; // 获取队列头部元素(优先级最高的元素)
下面主要分析堆顶元素被移除后,如何重组堆,让其维持小顶堆的特性。
这里还需要再介绍一个完全二叉树的性质:
上面对于完全二叉树节点索引的性质已经介绍过了,这里不再赘述。
完全二叉树其他的性质:
在完全二叉树中,如果节点总数为 n,则最后一个非叶子节点的索引为 n/2 - 1。
叶子节点索引从 n/2 到 n-1。
非叶子节点的数量是 n/ 2。 (siftDown方法就利用到了这个性质)
这里需要明确的是 siftDown方法本质上就是把堆顶上的大元素下沉到堆底,循环这个过程,直到堆符合小顶堆的性质。
poll方法代码示例:
import java.lang.reflect.Field;
import java.util.Arrays;
import java.util.Hashtable;
import java.util.PriorityQueue;
import java.util.concurrent.ConcurrentHashMap;public class TestA {public static void main(String[] args) throws Exception {PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();priorityQueue.offer(6);priorityQueue.offer(1);priorityQueue.offer(7);priorityQueue.offer(4);priorityQueue.offer(5);priorityQueue.offer(2);priorityQueue.offer(3);Class<? extends PriorityQueue> aClass = priorityQueue.getClass();Field queue = aClass.getDeclaredField("queue");queue.setAccessible(true);Object[] integers = (Object[]) queue.get(priorityQueue);System.out.println(Arrays.toString(integers));System.out.println(priorityQueue.poll());System.out.println(Arrays.toString(integers));}
}
运行结果:
[1, 4, 2, 6, 5, 7, 3, null, null, null, null]
1
[2, 4, 3, 6, 5, 7, null, null, null, null, null]
我觉得这个poll移除元素 重组堆的过程理解起来没那么难,就是动画不好画
还是建议断点看看源码,更好,下面动画只是很简略的画了一下 。
可以看到和上面运行结果一致 最终移除堆顶元素后的数组:
[2, 4, 3, 6, 5, 7, null, null, null, null, null]
7、PriorityQueue的其remove方法
这个方法用于移除并返回堆顶元素。如果堆是空的,则抛出 NoSuchElementException。
public E remove() {E x = poll(); // 调用 poll 方法获取并移除堆顶元素if (x != null) // 如果堆顶元素不为 nullreturn x; // 返回堆顶元素elsethrow new NoSuchElementException(); // 如果堆为空,抛出 NoSuchElementException
}
带参数的 remove 方法,移除指定的元素 o。如果找到该元素,则移除并返回 true,否则返回 false。
public boolean remove(Object o) {int i = indexOf(o); // 查找元素 o 在堆中的索引if (i == -1) // 如果索引为 -1,表示堆中不存在该元素return false; // 返回 falseelse {removeAt(i); // 在位置 i 处移除该元素return true; // 返回 true,表示成功移除元素}
}
在指定索引 i 处移除元素的方法
private E removeAt(int i) {modCount++; // 增加修改计数器,表示堆结构发生了变化int s = --size; // 减少堆的大小if (s == i) // 如果移除的是最后一个元素queue[i] = null; // 直接将该位置置为 nullelse {E moved = (E) queue[s]; // 获取堆中的最后一个元素queue[s] = null; // 将最后一个位置置为 nullsiftDown(i, moved); // 尝试将 moved 元素下沉到合适的位置if (queue[i] == moved) { // 如果 moved 元素没有下沉siftUp(i, moved); // 尝试将 moved 元素上浮到合适的位置if (queue[i] != moved) // 如果 moved 元素被替换了return moved; // 返回 moved 元素,表示它被替换}}return null; // 返回 null,表示没有元素被替换
}
注意点:如果remove指定元素
移除的是非最后一个元素这种情况下:
实际上可以类比上面的poll方法,poll是移除堆顶元素。然后从堆顶元素开始往下循环处理堆重组。
移除指定的元素 obj,那就从obj元素开始往下循环处理堆重组。 处理堆重组使用的都是siftDown方法。
8、PriorityQueue的其他方法element peak
element()方法用于获取但不移除堆顶元素。如果堆为空,则抛出 NoSuchElementException。
public E element() {E x = peek();if (x != null)return x;elsethrow new NoSuchElementException();}
peek()方法用于获取但不移除堆顶元素。如果堆为空,则返回 null。
public E peek() {return (size == 0) ? null : (E) queue[0];}
补充
列表、哈希表、栈、队列、双向队列、阻塞队列基本方法参考
为了防止混乱这里对表、哈希表、栈、队列、双向队列、阻塞队列的一些常用基本方法列出以供参考
| Collection | Method | Description | Throws Exception |
|---|---|---|---|
| List | add(E e) | 添加元素到列表末尾,返回 true | 无 |
add(int index, E element) | 在指定位置插入元素 | IndexOutOfBoundsException | |
get(int index) | 获取指定位置的元素 | IndexOutOfBoundsException | |
remove(int index) | 移除指定位置的元素 | IndexOutOfBoundsException | |
set(int index, E element) | 替换指定位置的元素 | IndexOutOfBoundsException | |
contains(Object o) | 判断列表是否包含指定元素 | 无 | |
| Map | put(K key, V value) | 插入键值对,返回之前关联的值 | 无 |
get(Object key) | 获取指定键的值 | 无 | |
remove(Object key) | 移除指定键的键值对 | 无 | |
containsKey(Object key) | 判断是否包含指定键 | 无 | |
containsValue(Object value) | 判断是否包含指定值 | 无 | |
| Stack | push(E item) | 压入元素到栈顶 | 无 |
pop() | 移除并返回栈顶元素 | EmptyStackException | |
peek() | 返回栈顶元素但不移除 | EmptyStackException | |
| Queue | add(E e) | 添加元素到队列末尾,若队列已满抛异常 | IllegalStateException |
offer(E e) | 添加元素到队列末尾,返回 true 或 false | 无 | |
remove() | 移除并返回队列头部元素 | NoSuchElementException | |
poll() | 移除并返回队列头部元素,若队列为空返回 null | 无 | |
element() | 返回队列头部元素但不移除 | NoSuchElementException | |
peek() | 返回队列头部元素但不移除,若队列为空返回 null | 无 | |
| Deque | addFirst(E e) | 添加元素到双端队列的开头 | 无 |
addLast(E e) | 添加元素到双端队列的末尾 | 无 | |
offerFirst(E e) | 添加元素到双端队列的开头,返回 true 或 false | 无 | |
offerLast(E e) | 添加元素到双端队列的末尾,返回 true 或 false | 无 | |
removeFirst() | 移除并返回双端队列的开头元素 | NoSuchElementException | |
removeLast() | 移除并返回双端队列的末尾元素 | NoSuchElementException | |
pollFirst() | 移除并返回双端队列的开头元素,若为空返回 null | 无 | |
pollLast() | 移除并返回双端队列的末尾元素,若为空返回 null | 无 | |
getFirst() | 返回双端队列的开头元素但不移除 | NoSuchElementException | |
getLast() | 返回双端队列的末尾元素但不移除 | NoSuchElementException | |
peekFirst() | 返回双端队列的开头元素但不移除,若为空返回 null | 无 | |
peekLast() | 返回双端队列的末尾元素但不移除,若为空返回 null | 无 | |
| BlockingQueue | add(E e) | 添加元素到队列末尾,若队列已满抛异常 | IllegalStateException |
offer(E e) | 尝试添加元素到队列末尾,返回 true 或 false | 无 | |
offer(E e, long timeout, TimeUnit unit) | 尝试添加元素到队列末尾,在超时时间内等待 | InterruptedException | |
put(E e) | 添加元素到队列末尾,若队列已满则等待 | InterruptedException | |
take() | 移除并返回队列头部元素,若队列为空则等待 | InterruptedException | |
poll(long timeout, TimeUnit unit) | 移除并返回队列头部元素,在超时时间内等待 | InterruptedException | |
remainingCapacity() | 返回队列剩余的容量 | 无 | |
drainTo(Collection<? super E> c) | 移除所有可用元素到指定集合 | 无 | |
drainTo(Collection<? super E> c, int maxElements) | 移除最多指定数量的可用元素到指定集合 | 无 | |
clear() | 移除所有元素 | 无 |