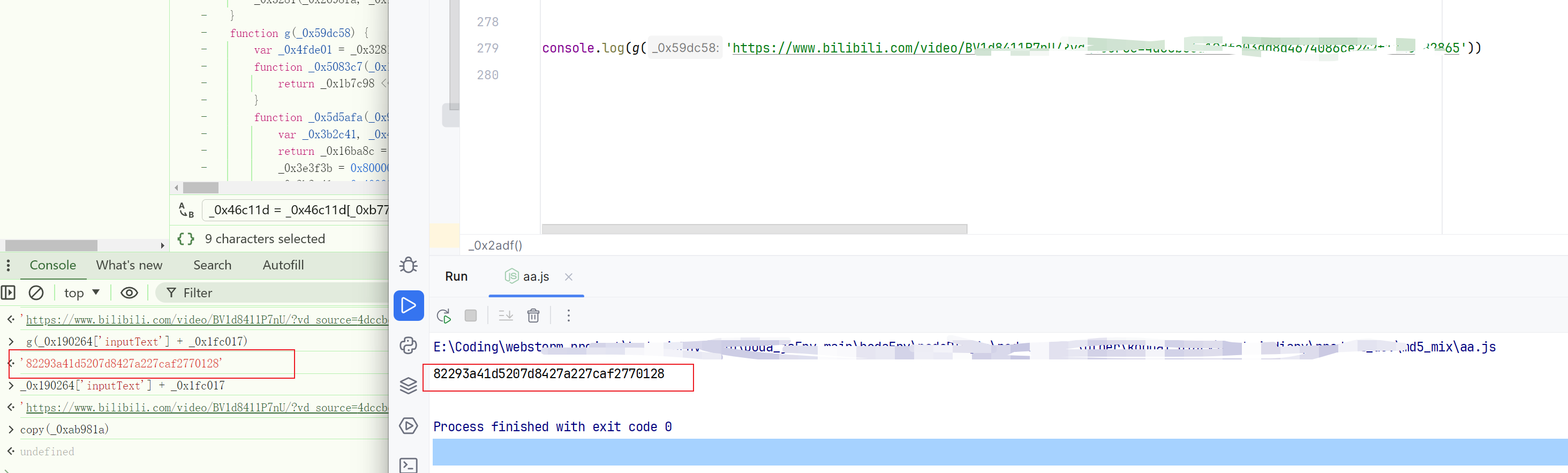
前言
SIGMOD 2024会议最近刚在智利圣地亚哥结束,有关高维向量检索/向量数据库/ANNS的论文主要有5篇,涉及混合查询(带属性或范围过滤的向量检索)优化、severless向量数据库优化、量化编码优化、磁盘图索引优化。此外,也有一些其它相关论文,比如FedKNN: Secure Federated k-Nearest Neighbor Search。
下面对这些论文进行一个简单汇总介绍。
SeRF : Segment Graph for Range-Filtering Approximate Nearest Neighbor Search

这篇论文主要研究带范围过滤的向量检索问题,作者基于HNSW提出了两种范围过滤图索引:SegmentGraph和2DSegmentGraph,它们分别用于处理范围约束是半界范围和任意范围的情况。由于构建一个考虑范围情况的索引会显著增加索引处理时间和索引尺寸,这篇论文主要对离线构建过程做了大量优化,从而大幅减少离线处理开销和显著压缩了索引。比如,SegmentGraph通过无损压缩实现了索引尺寸与原始HNSW相当。
RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search

这篇论文主要研究了一种新的量化(quantization)方法RaBitQ,讲高维向量编码为等维度的二值向量。与当前流行的PQ及其变体相比,RaBitQ具有如下优势:(1)距离评估是无偏的,具有理论概率误差界;(2)RaBitQ能实现更高的精度且只需更短的编码;(3)距离评估更高效。
Vexless : A Serverless Vector Data Management System Using Cloud Functions

这篇论文主要研究了在无服务器云函数(Cloud Funtions)下向量数据库的设计和优化,本文主要聚焦在三个方面:(1)Sharding策略;(2)通讯机制;(3)冷启动。本文基于Azure Functions对上述三个方面做了具体的优化,优化系统Vexless具有高弹性、低运营成本、细粒度计费模型等优点。
ACORN: Performant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data

这篇论文主要研究混合查询问题,即带属性过滤约束的向量检索。当前混合查询技术路线主要有3类:前过滤、后过滤、混合过滤。本文的技术路线是沿着第3种,即为属性和向量构建混合索引,即设计专用于混合查询的索引。对于范围过滤,本文的方案可能仅适用于一些简单范围过滤情况,比如一定数量的年份,可能并不适用于具有非常精细的范围过滤约束的混合查询。
本文方案基于HNSW算法,优化HNSW的索引构建过程从而使构建的HNSW索引融合属性信息,主要思想与之前的NHQ、Filter-DiskANN等类似,都是把属性信息融入到近邻图索引中,从而使索引不仅包含向量近邻关系也考虑顶点之间的属性关系。ACORN构建了一个更“稠密”的HNSW,即邻居数更多了。显然,ACORN需要更多索引构建时间和索引内存占用开销。
执行混合查询时,若谓词的可选择性比较低,可能用前过滤比较适合,本文通过代价模型来根据查询谓词的可选择性来选择具体执行前过滤还是ACORN。
ACORN支持的过滤类型(y是谓词):(1)equals(y); (2)contains(y1,y2,…); (3)between(y1,y2); (4)regex-match(y).
在实验中,(3)过滤类型是年份。
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment

本文提出了一种 I/O 高效的磁盘图索引框架Starling,以优化数据段内的数据布局和搜索策略。它有两个主要组成部分:(1)数据布局包含内存中导航图和重新排序的磁盘图索引,这增强了存储局部性并减少搜索路径长度,从而最大限度地减少磁盘带宽浪费; (2) 块搜索策略,旨在最大限度地减少向量查询执行期间昂贵的磁盘 I/O 操作。 在2GB内存和10GB磁盘容量的数据段上,Starling可容纳多达3300万个128维向量,提供超过0.9的平均精度以及低于1毫秒延迟的HVSS。与最先进的方法相比,Starling的吞吐量提高了43.9 倍,查询延迟降低了98%,同时保持了相同的精度水平。