实时了解业内动态,论文是最好的桥梁,专栏精选论文重点解读热点论文,围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
材料科学侧重于研究和开发具有特定性能和应用的材料。该领域的研究人员旨在了解材料的结构、性能和性能,以创新和改进现有技术,并为各种应用创造新材料。该学科结合了化学、物理和工程原理,以应对挑战并改进航空航天、汽车、电子和医疗保健中使用的材料。
材料科学面临的一个重大挑战是整合来自科学文献的大量视觉和文本数据,传统方法通常无法有效地组合这些数据类型,从而限制了生成全面见解和解决方案的能力。难点在于从图像中提取相关信息并将其与文本数据相关联,这对于推进该领域的研究和应用至关重要。

Cephalo
麻省理工学院(MIT)的研究人员推出了Cephalo,这是一系列专为材料科学应用设计的多模态视觉语言模型(V-LLMs)。Cephalo旨在弥合视觉感知和语言理解之间的差距,以分析和设计仿生材料。
Cephalo 利用复杂的算法从科学文献中检测和分离图像及其相应的文本描述。它使用视觉编码器和自回归转换器集成这些数据,使模型能够解释复杂的视觉场景,生成准确的语言描述,并有效地回答查询。

该模型使用来自数千篇科学论文和以科学为重点的维基百科页面的集成图像和文本数据进行训练。它展示了其处理复杂数据和提供有见地的分析的能力。
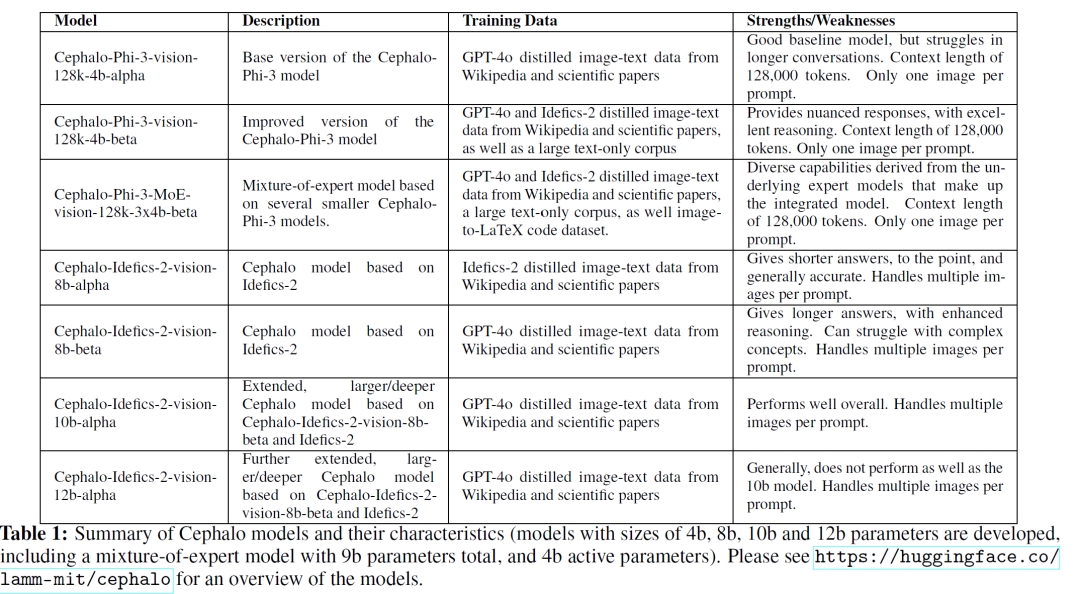
如上图所示,Cephalo推出的模型在4B和12B之间,基座模型有Phi-3和Idefics-2,分别采用GPT-40和Idefics-2针对原始数据进行提炼。当然本项目还利用层合并技术形成更大规模的大模型以及尝试采用MoE的方式进行实验。紧接着来看看本次项目的成果,在各个领域的影响力还是巨大的。

特色1:语料构成
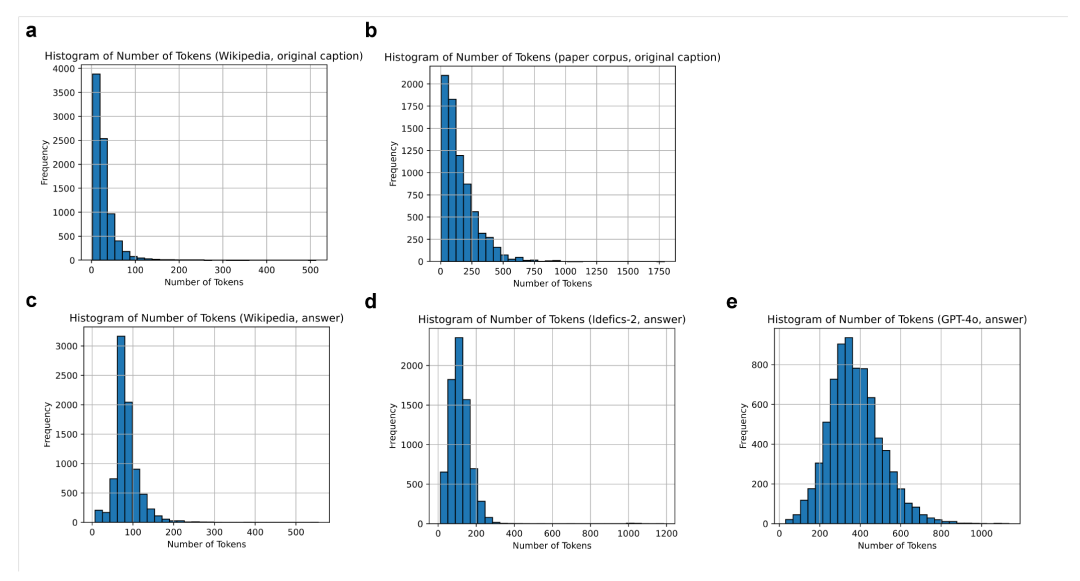
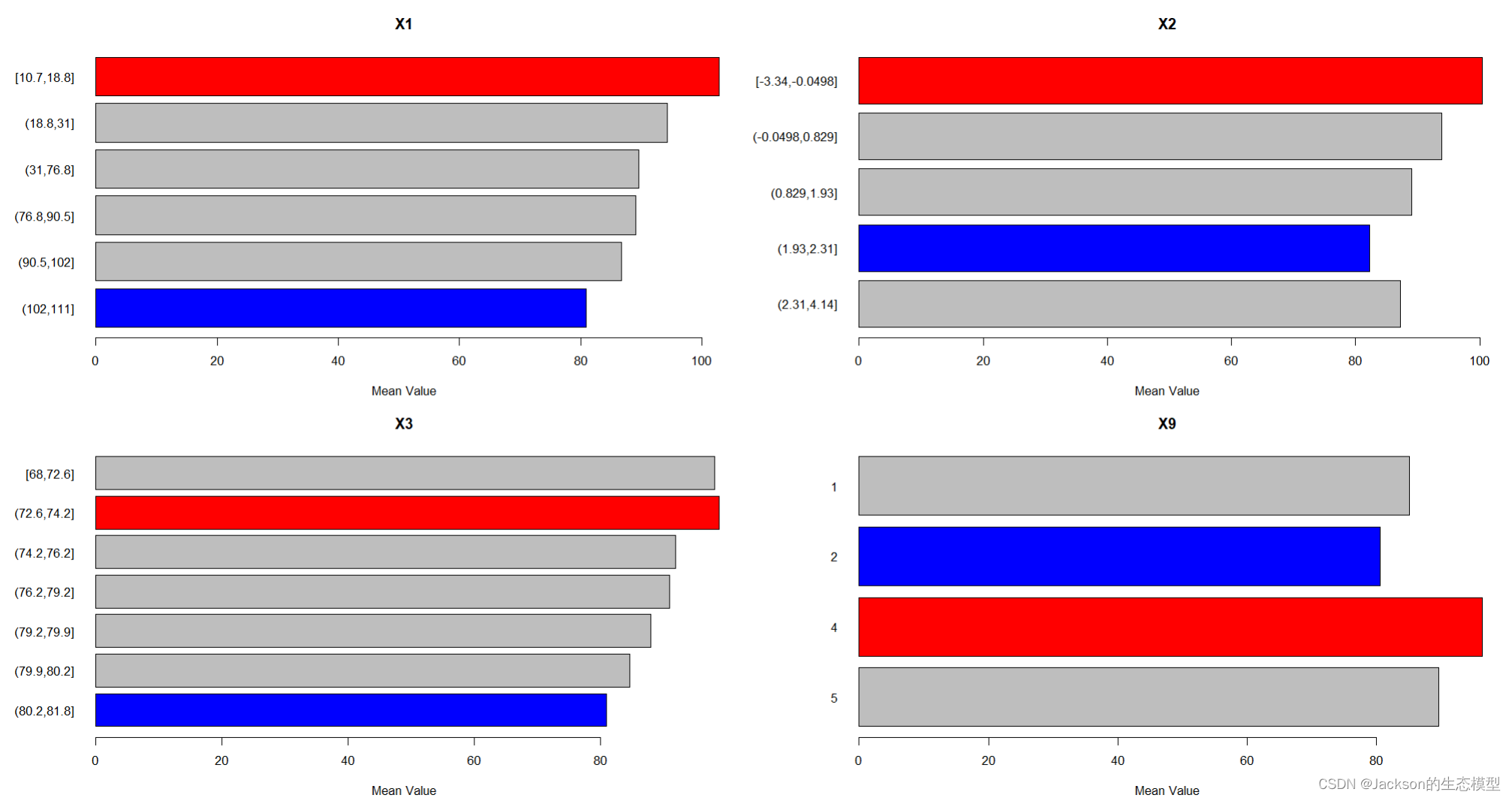
图像文本数据集的Token记长度记数直方图,a代表来至示来自维基百科,b代表来之论文语料库,原始说明。c-e显示了使用不同视觉文本模型处理的结果。c显示了Idefics-2处理维基百科后的图像描述的Token长度。面板d和e显示了使用Idefics-2和GPT-4o处理的论文语料库数据集的结果。
GPT-4o数据集通常会产生更长的描述,对内容的详细分析让它提供了增强的推理能力和对图像内容的细致解释的能力。所有Token均使用 Phi-3-Vision标记器(tokenizer)完成。
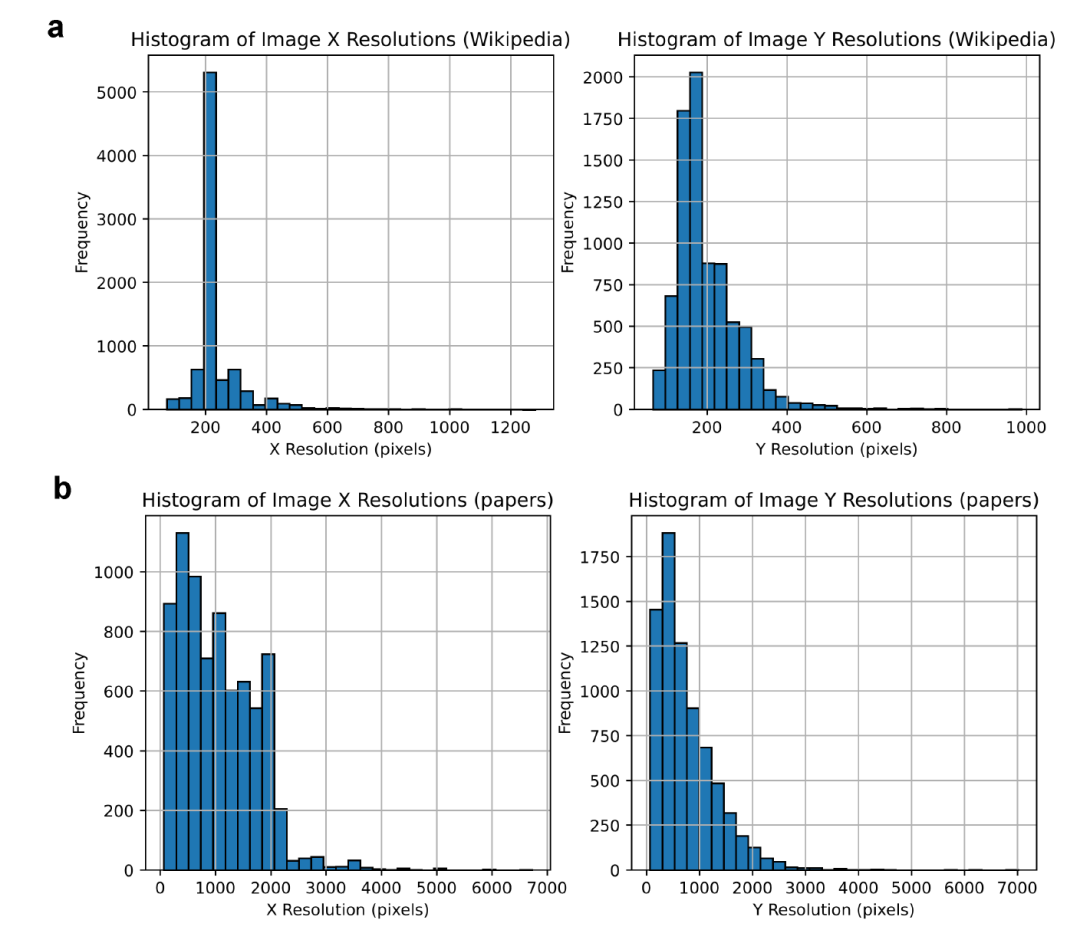
上图为从wiki和论文中获取图像分辨率的直方统计图。相对而言,论文的图片质量普遍高一点。
为了开发一种强大的数据集生成方法,研究人员使用PyMuPDF中的 fitz 库从0到1实现全新的算法。该过程首先识别PDF中每页的所有图像。随后找到以“Fig”或类似标识符开头的文本块。然后该算法将这些文本块与位于其下方的最近图像进行匹配。
匹配过程通过几个清理步骤进行改进,包括处理不同的图像颜色图和格式,以及删除特定符号,例如期刊添加到文档中的符号。一些 PDF 产生了分割的图形,需要额外的处理才能确保数据集的完整性。
通过与通用V-LLM(视觉大模型)共享图像和原始标题,并让模型开发图像的全面描述,可以开发用于训练的图像文本对。研究人员同时使用开源 V-LLM、Idefics2和GPT-4o来完成针对图的信息提炼。作为替代方案,我们还探索了使用纯文本的 LLM(例如,Phi-3-Bioinspired,它提供了另一种选择。具有视觉功能的 LLM 来处理和提炼数据集通常更好,并提供更详细和合理的描述。
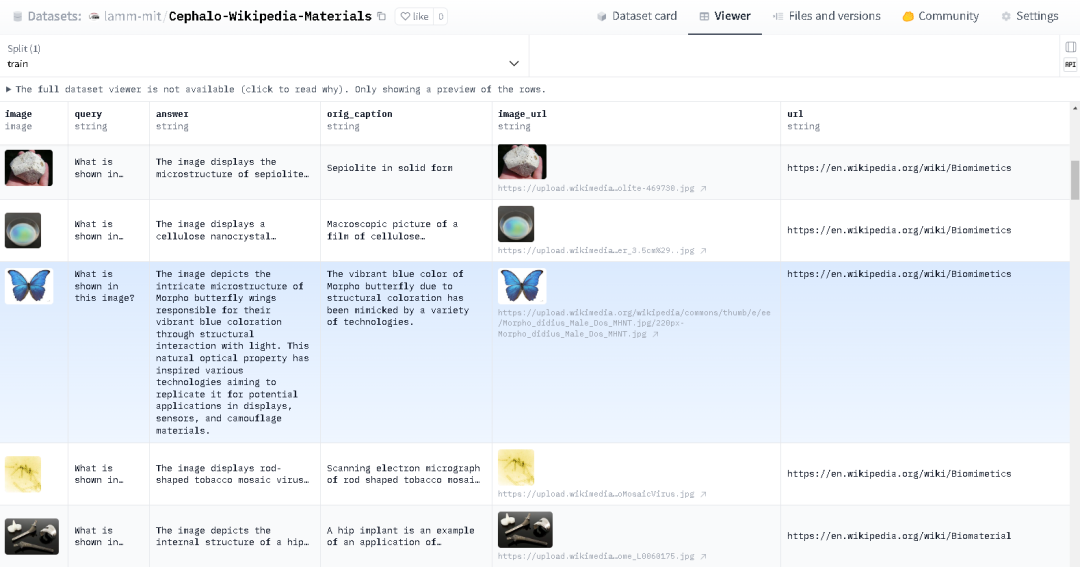
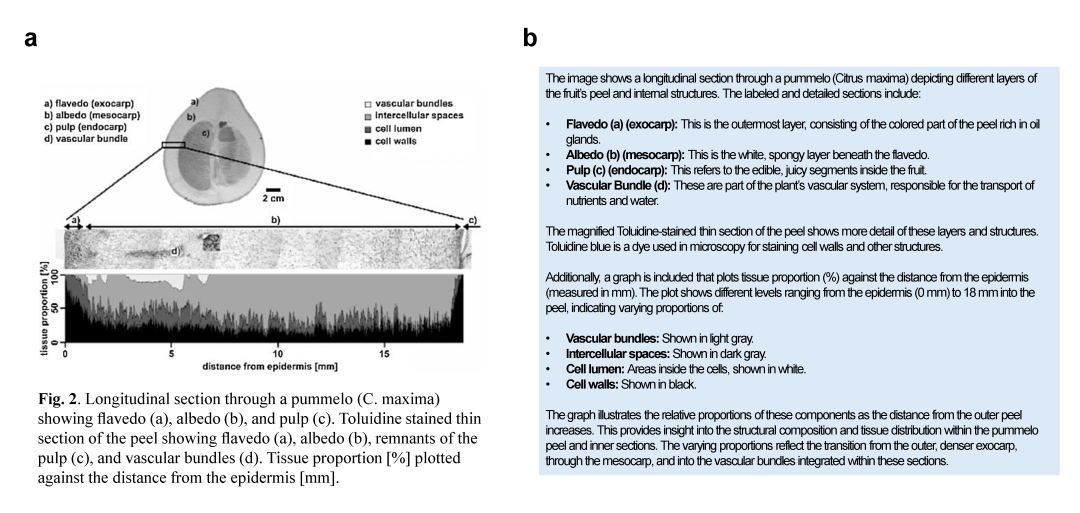
上图中的数据集的字段既包含原始的Caption,也有经过vLLM综合内容生成的QA字段,更加丰满了(例如下图的a重新生成b的描述。)

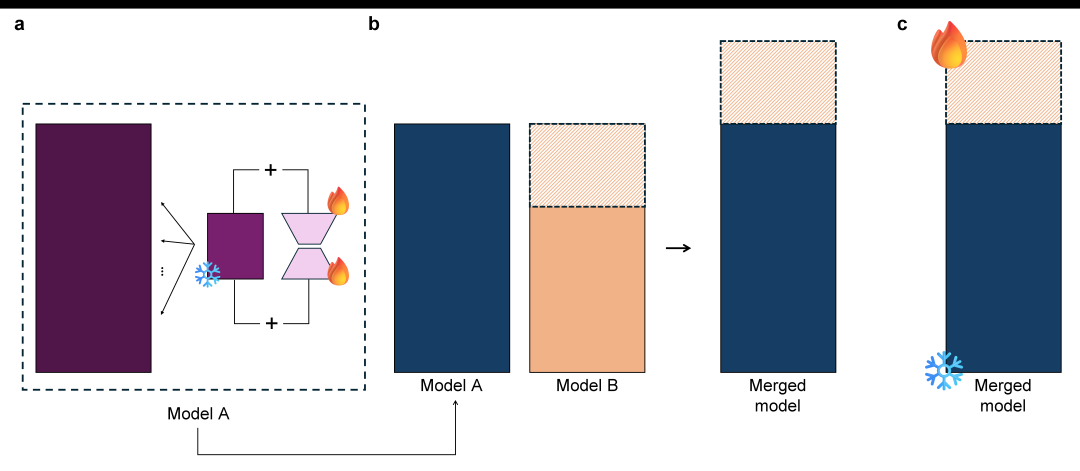
特色2:层合并
混合模型Cephalo-Idefics-2-vision-10b-alpha通过有效地将特定领域的专业知识与一般的对话能力相结合,表现出卓越的性能。这是通过将lamm-mit/Cephalo-Idefics-2-vision-8b-beta模型的解码器的前32层与聊天/指令调整的HuggingFaceM4/idefics2-8b-chatty模型的最后N层合并。在针对合并模型的最后N层进行微调。若N=8,则产生10b的模型。
-
a显示了使用低秩自适应对第一个模型进行微调。
-
b讲述了合并的过程,这个过程使用两个模型,模型A和模型B,来构建更大的模型。模型A是一个领域特定的微调模型,模型B是一个通用的聊天/指令调整模型。研究人员选择一组层(来自模型 A 的所有层,模型 B 的深层)。这遵循使用领域特定模型的早期层和通用模型的后期层的策略。然后将选定的层合并为一个新的组合模型,该模型经过微调。
-
c新模型的微调是通过冻结源模型A的所有层并对源自模型B的层进行全面微调来完成的。生成的模型可以实现图像字幕、视觉问答和多模态内容生成等任务。
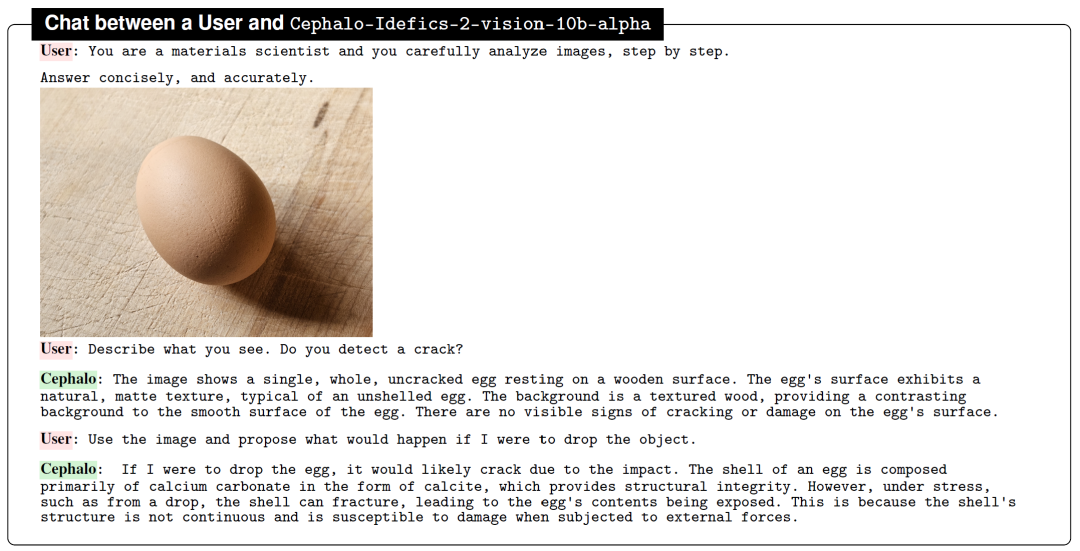
给它一张鸡蛋的图,让它描述,同时问它要是摔了会如何。从物理的角度还是回答得有模有样的!
当然本次的研究还顺手训练了基于原来模型的MoE,3*4B的LLM。
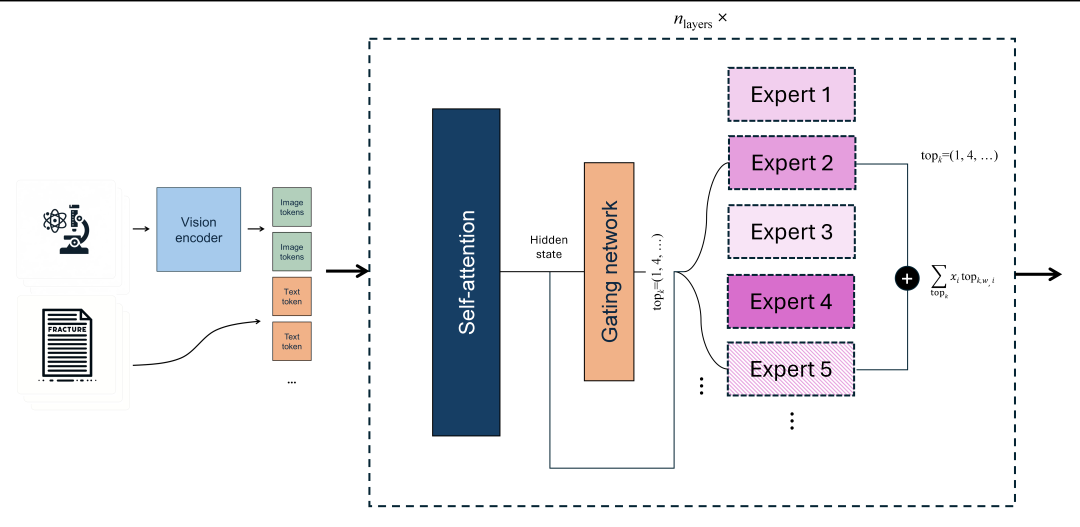
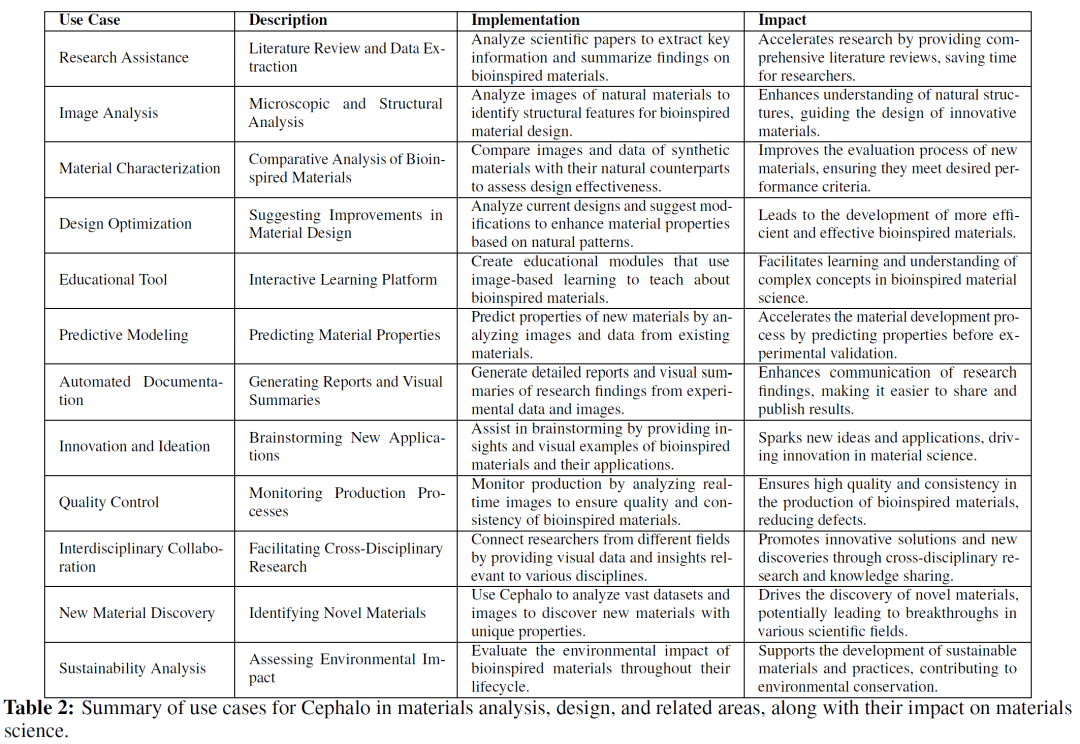
Cephalo可以生成精确的图像到文本和文本到图像的翻译,提供高质量、上下文相关的训练数据。此功能显著增强了人类 AI和多智能体AI框架内的理解和交互。研究人员已经在各种用例中测试了Cephalo,包括分析断裂力学、蛋白质结构和仿生设计,展示了其多功能性和有效性。
在性能和结果方面,Cephalo的模型范围从 4B到 12B不等,可适应不同的计算需求和应用。这些模型在各种用例中进行了测试,例如生物材料、断裂和工程分析以及仿生设计。例如,Cephalo展示了其解释复杂视觉场景和生成精确语言描述的能力,增强了对失效和断裂等物质现象的理解。这种视觉和语言的整合可以进行更准确和详细的分析,支持材料科学创新解决方案的开发。
此外,这些模型在特定应用中显示出显着改进。例如,Cephalo可以在分析生物材料时生成微观结构的详细描述,这对于理解材料特性和性能至关重要。在断裂分析中,该模型准确描述裂纹扩展并提出提高材料韧性的方法的能力尤为重要。这些结果凸显了Cephalo在推进材料研究和为现实世界挑战提供实用解决方案方面的潜力。