1 mysql性能测试的主要内容
- MySQL数据库介绍
- MySQL数据库监控指标
- MySQL慢查询工作原理及操作
- SQL的分析与调优方法
- MySQL索引的概念及作用
- MySQL索引的工作原理与设计规范
- MySQL存储引擎
- MySQL实时监控
- MySQL集群监控方案
- MySQL性能测试的用例准备
- 使用Jmeter开发MySQL性能测试脚本
- 执行测试
2 mysql数据库分支介绍
MariaDb
- MySQL之父Widenius创建,目标在于替换现有MySQL
- 兼容MySQL ,对于开发者来说感知不到变化
- ariaDB is free and open source software
3 mysql重点监控指标SQL语句
- QPS
queries per seconds每秒钟查询数量
mysql > show global status like 'Question%';
- TPS(每秒事务量)
TPS = (Com_commit + Com_rollback) / seconds
mysql > show global status like 'Com_commit';
mysql > show global status like 'Com_rollback';
- 线程连接数
mysql > show global status like 'Max_ used_ connections';
mysql > show global status like 'Threads%';
- 最大连接数
mysql > show variables like 'max_ connections';
- Query Cache
查询缓存用于缓存select查询结果
当下次接收到相同查询请求时,不再执行实际查询处理而直接返回结
适用于大量查询、很少改变表中数据
修改my.cnf将query_ cache_ size设置为具体的大小,具体大小是多少取决于查询
的实际情况,但最好设置为1024的倍数,参考值32M增加一行: query_ cache_ type=0/1 / 2
如果设置为1 ,将会缓存所有的结果,除非你的select语句使用
SQL_ _NO_ CACHE禁用了查询缓存。如果设置为2 ,则只缓存在select语句中通过SQL _CACHE指定需要缓
存的查询.
- Query Cache命中率
show status like 'Qcache%';
Query_cache_hits = (Qcahce_ hits /(Qcache_ hits + Qcache_inserts )) * 100%;
- 锁定状态
show global status like '%lock%';
Table_ locks_ waited/Table_locks_immediate值越大代表表锁造成的阻塞越严重
- 锁定状态
show global status like '%lock%';
Table_locks_waited/Table_locks_immediate值越大代表表锁造成的阻塞越严重
Innodb_ row_ lock_waitsinnodb行锁,太大可能是间隙锁造成的
- 主从延时
查询主,从延时时间: show slave status
4 mysql慢查询
4.1 慢查询定义
- 执行速度超过定义的时间的查询
- 不同的系统定,义不容的慢查询指标
4.2 慢查询开启
- 编辑/etc/my.cnf ,在[mysqld]域中添加: .
- 开启慢查询: slow_query_log= 1
- 慢查询日志路径: slow_query_log_file =/data/mysql/slow.log
- 慢查询的时长: long_query_time= 1
- 未使用索弓|的查询也被记录到慢查询日志中 log_queries_not_using_indexes=1
慢查询日志分析
mysqldumpslow命令
- -s是表示按照何种方式排序
- -t是top n的意思,即为返回前面多少条的数据
- -g后边可以写一个正则匹配模式,大小写不敏感的
4.3 mysqldumpslow -s 更多参数
al 平均锁定时间ar 平均返回记录时间at 平均查询时间(默认)c 访问计数l 锁定时间r 返回记录t 查询时间
-
得到返回记录集最多的10个SQL
mysqldumpslow -sr -t 10 slow.log -
得到访问次数最多的10个SQL
mysqldumpslow -sc -t 10 slow.log -
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow-st-t 10 -g "left join" slow.log

5 SQL语句性能分析
5.1 explain执行计划
- 用法: explain select语句
- 例如:
1explain select * from user; 执行完毕之后,它的输出有以下字段:

id、 select_type、 table、 partitions、 type、 possible_keys、 key、 key_len、 ref、 rows、 Extra
要想知道explain命名怎么使用,就必须把这些字段搞清楚
5.2 explain返回结果分析
- id
select识别符 ,代表语句的执行顺序,-般在select嵌套 查询时会不 同
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次 执行
id列为null的就表是这是一个结果集,不需要使用它来进行查询。
- select_ type
simple:表示不需要union操作或者不包含子查询的简单select查询。 有连接查询时,外层的查询为simple ,且只有一个
primary :一个需要union操作或者含有子查询的select ,位于最外 层的单位查询的select_type即为primary。且只有一个
union : union连接的两个select查询,第一个查询是dervied派生 表,除了第一个表外,第二个以后的表select_type都是union
dependent union :与union一样,出现在union或union all语句 中,但是这个查询要受到外部查询的影响
union result :包含union的结果集,在union和union all语句中,因 为它不需要参与查询,所以id字段为null
subquery :除了from字句中包含的子查询外,其他地方出现的子 查询都可能是subquery
dependent subquery :与dependent union类似,表示这个 subquery的查询要受到外部表查询的影响
derived : from字句中出现的子查询,也叫做派生表,其他数据库 中可能叫做内联视图或嵌套select
- table
显示的查询表名
如果查询使用了别名,那么这里显示的是别名
如果不涉及对数据表的操作,那么这显示为null
如果显示为尖括号括起来的< derived N>就表示这个是临时表
依次从好到差: system , const,eq_ref , ref , fulltext , ref_or_null, unique_subquery , index_subquery , range , index_merge , index , ALL
除了all之外,其他的type都可以使用到索引,除了index_ merge之 外,其他的type只可以用到一个索引
- type (从好到坏)重点代表了SQL的好与坏
system :表中只有一行数据或者是空表,职能用于myisam和 memory表。如果是Innodb引擎表, type列在这个情况通常都是 all或者index
const :使用唯一索引或者主键,返回记录-定是1行记录的等值 where条件时,通常type是const。其他数据库也叫做唯一索引扫描
eq_ref :出现在要连接过个表的查询计划中,驱动表只返回一-行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null ,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
ref :不像eq_ref那样要求连接顺序,也没有主键和唯一索引 的要求只要使用相等条件检索时就可能出现,常见与辅助索引|的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
fulltext :全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索弓|同时存在时,mysq|不管代价,优先选择使用全文索引。
ref_or_null :与ref方法类似,只是增加了null值的比较。实际用的不多。
unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值。
index_ subquery:用于in形式子查询使用到了辅助索引|或者in常数列表,子查询可能返回重复值,可以使用索弓|将子查询去重。
range :索弓|范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
index_ merge :表示查询使用了两个以上的索引,最后取交集或者并集,常见and,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
index :索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引|排序或者分组的查询。
all :这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
- possible_ keys
查询可能使用到的索引|都会在这里列出来
- key
查询真正使用到的索引,select__type为index__merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
- key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去
- ref
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
- rows
这里是执行计划中估算的扫描行数,不是精确值
- Extra常见返回
distinct :在select部分使用了distinc关键字
no tables used :不带from字句的查询或者From dual查询
using filesort :排序时无法使用到索引时,就会出现这个。常见于 order by和group by语句中
using index :查询时不需要回表查询,直接通过索弓|就可以获取查 询的数据。
using intersect :表示使用and的各个索引的条件时,该信息表示 是从处理结果获取交集
using union :表示使用or连接各个使用索引的条件时,该信息表 示从处理结果获取并集
using where :表示存储引擎返回的记录并不是所有的都满足查询 条件,需要在server层进行过滤

6 MYSQL索引介绍
6.1类型
-
主键索引
它是一种特殊的唯一索引 ,不允许有空值
一般是在建表的时候同时创建 主键索引
-
全文索引
fulltext是一种只适用于MyISAM表的一个索引类型
被索引列的数据类型只能是以下三种的组合char、varchar、text
MySQL是通过match)和against()这两个函数来实现它的全文索引查询的功能。
-
唯一索引 索引列的值必须唯一, 但允许有空值
-
组合索引
也叫多列索引,就是在多列上同时创建索引,使得多列的组合值唯一,创建组合索引|的好处是比分别创建多个单列索弓引|的查 询速度要快很多。
组合索弓|创建遵循“最左前缀”规则
如三列: id、name、age创建组合索引,则相当于分别创建了id、 name、 age , id、 name , id这三个索引
-
普通索引
最基本的索引,它没有任何限制
7 MYSQL索引创建规范
- 索引是一把双刃剑,它可以提高查询效率但也会降低插入和更新的速度并占用磁盘空间
- 在插入与更新数据时,要重写索引文件
- 单张表中索弓|数量不超过5个
- 单个索引|中的字段数不超过5个
- 不使用更新频繁地列作为主键
- 合理创建组合索引(避免冗余)
- 不在低基数列上建立索引,例如'性别'
- 不在索弓|列进行数学运算和函数运算,会使索引失效
- 不使用%前导的查询,如like"%xxx" 无法使用索引
- 不使用反向查询,如not in / not like ,无法使用索引,导致全表扫描
- 选择越小的数据类型越好,因为通常越小的数据类型通常在磁盘,内存,cpu,缓存中占用的空间很少,处理起来更快
- 在经常需要排序(order by),分组(group by)和的distinct列上加索引(单独order by用不了索引,索引考虑加where或加limit)
- 在表与表的而连接条件.上加,上索引,可以加快连接查询的速度
- 使用短索引l,如果你的一一个字段是Char(32)或者int(32),在创建索引的时候指定前缀长度,比如前10个字符(前提是多数值是唯一的)那么短索引可以提高查询速度,并且可以减少磁盘的空间,也可以减少I/0操作.
8 mysql存储引擎
8.1 MyISAM
-
优点
读的性能比InnoDB高很多
索引与数据分开,使用了压缩,从而提高了内存使用率.
-
缺点
不支持事务
写入数据时,直接锁表
8.2 InnoDB
-
优点
支持事务
支持外键
支持行级锁
-
缺点
不支持fulltext索引 (全文索引)
行级所并不绝对,当不确定扫描范围时,锁全表
索引与数据是紧密捆绑的,没有使用压缩导致体积庞大
9 mysql数据库的实时监控
9.1orzdba shell脚本
orzdba是淘宝DBA团队开发出来的一个perl监控脚本,主要功能是监控mysql数据库,也有一些磁盘和cpu的监控选项,好不好用就见仁见智,毕竟各公司需求不尽相同.
下载:网上找一下,脚本内容即可
- 启动
./orzdba
- 使用
Info :Created By zhuxu@taobao.com
Usage :
Command line options :-h,--help 打印帮助信息.-i,--interval 时间(秒)间隔.-C,--count 次数时间.-t,--time 打印当前时间.-nocolor 打印无颜色.-l,--load 打印加载信息.-c,--cpu 打印Cpu信息.-s,--swap 打印交换信息.-d,--disk 打印磁盘信息.-n,--net 打印网络信息.-P,--port 用于mysql连接的端口号(默认3306).-p,--passwd 用于mysql连接的用户密码(默认为null)-S,--socket 套接字用于mysql连接的套接字文件。-com 打印MySQL状态 Status(Com_select,Com_insert,Com_update,Com_delete).-hit Print Innodb Hit%.命中率-innodb_rows Print Innodb Rows 行 Status(Innodb_rows_inserted/updated/deleted/read).-innodb_pages Print Innodb Buffer Pool Pages Status(Innodb_buffer_pool_pages_data/free/dirty/flushed)缓冲池页面状态-innodb_data Print Innodb Data Status(Innodb_data_reads/writes/read/written)-innodb_log Print Innodb Log Status(Innodb_os_log_fsyncs/written)-innodb_status Print Innodb Status from Command: 'Show Engine Innodb Status'(history list/ log unflushed/uncheckpointed bytes/ read views/ queries inside/queued)-T,--threads Print Threads Status(Threads_running,Threads_connected,Threads_created,Threads_cached).-rt Print MySQL DB RT(us).-B,--bytes Print Bytes received from/send to MySQL(Bytes_received,Bytes_sent).-mysql Print MySQLInfo (include -t,-com,-hit,-T,-B).-innodb Print InnodbInfo(include -t,-innodb_pages,-innodb_data,-innodb_log,-innodb_status)-sys Print SysInfo (include -t,-l,-c,-s).-lazy Print Info (include -t,-l,-c,-s,-com,-hit).-L,--logfile Print to Logfile.-logfile_by_day One day a logfile,the suffix of logfile is 'yyyy-mm-dd';and is valid with -L.
Sample 案例:shell> nohup ./orzdba -lazy -d sda -C 5 -i 2 -L /tmp/orzdba.log > /dev/null 2>&1 &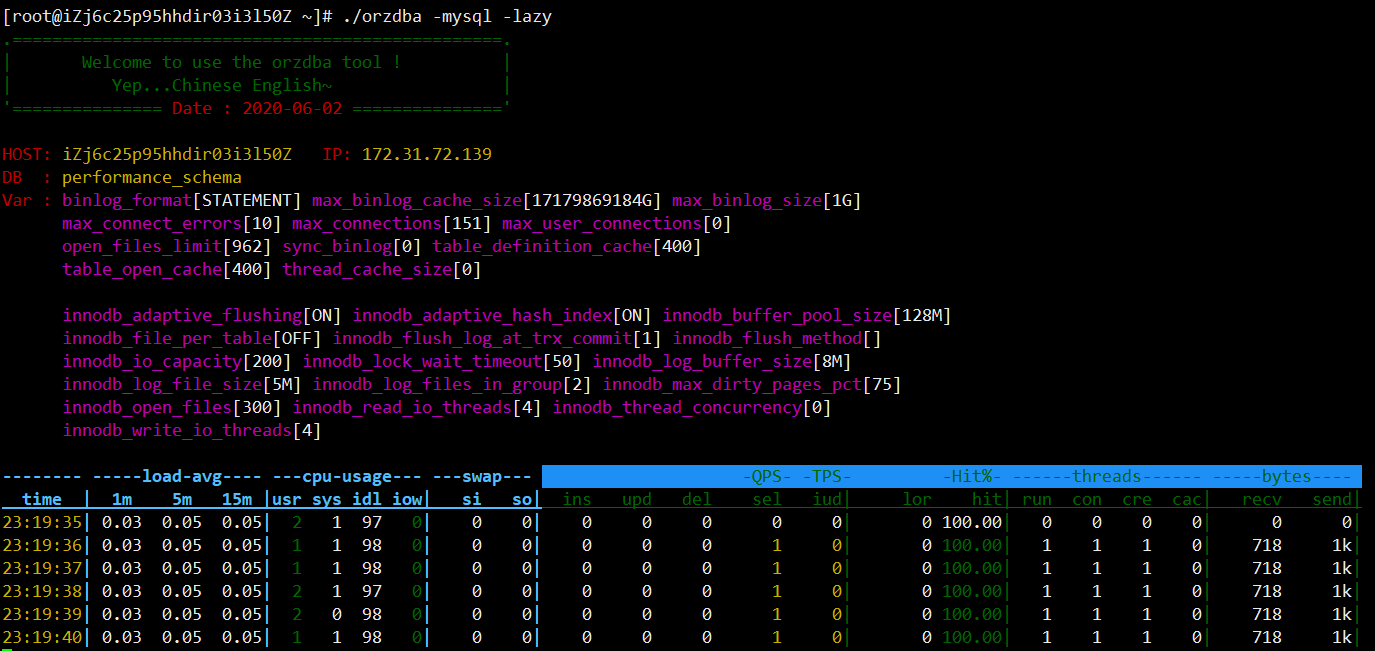
10 mysql集群监控工具介绍
-
天兔LEPUS工具
- 为所有数据库管理者、互联网企业数据库 监控而设计
- 无需部署Agent,轻松监控1000+数据库实例,完善灵活的告警配置,详细的性能分析指标
-
搭建及教程
官方文档:www.dbarun.com/docs/lepus/
11 开发性能测试脚本及执行
11.1用例准备
- 使用sq|模拟用户使用场景
11.2JMeter开发mysq|性能测试
- 步骤
1.DBC Connection Configuration配置mysq|配置
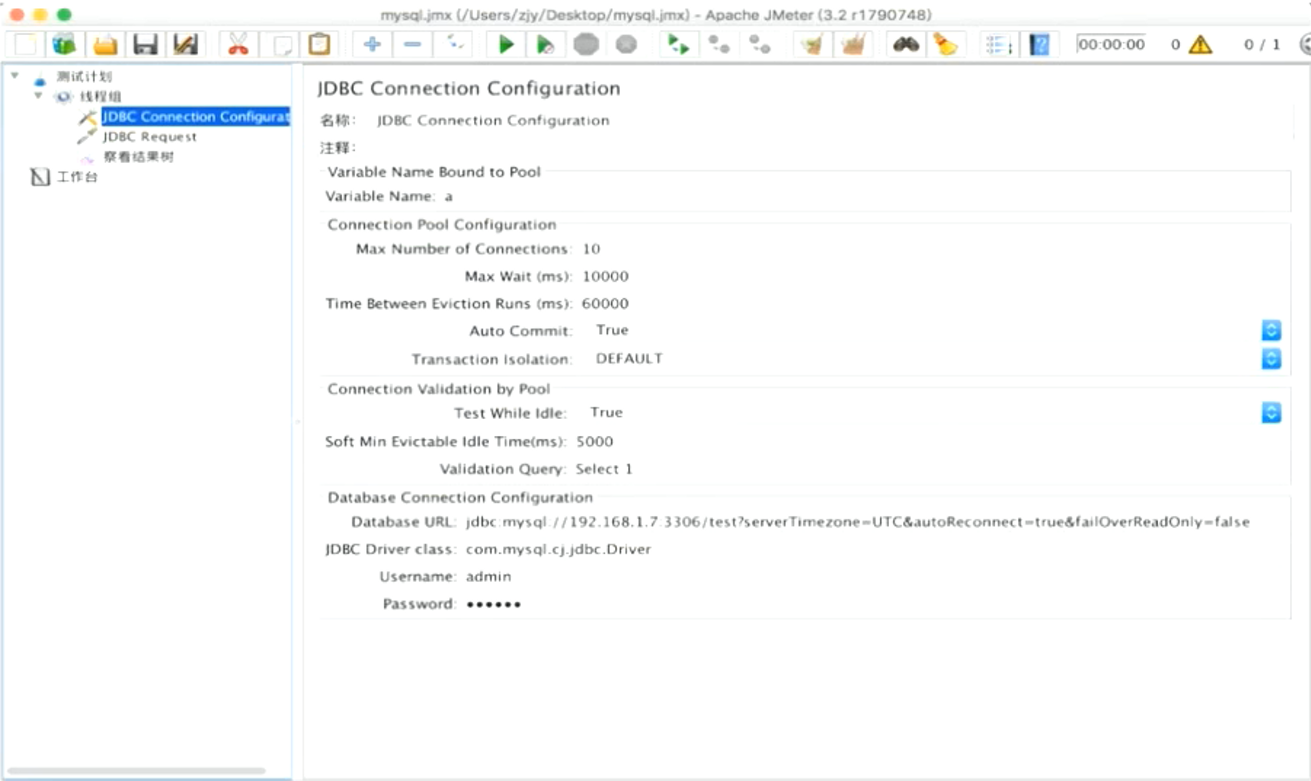
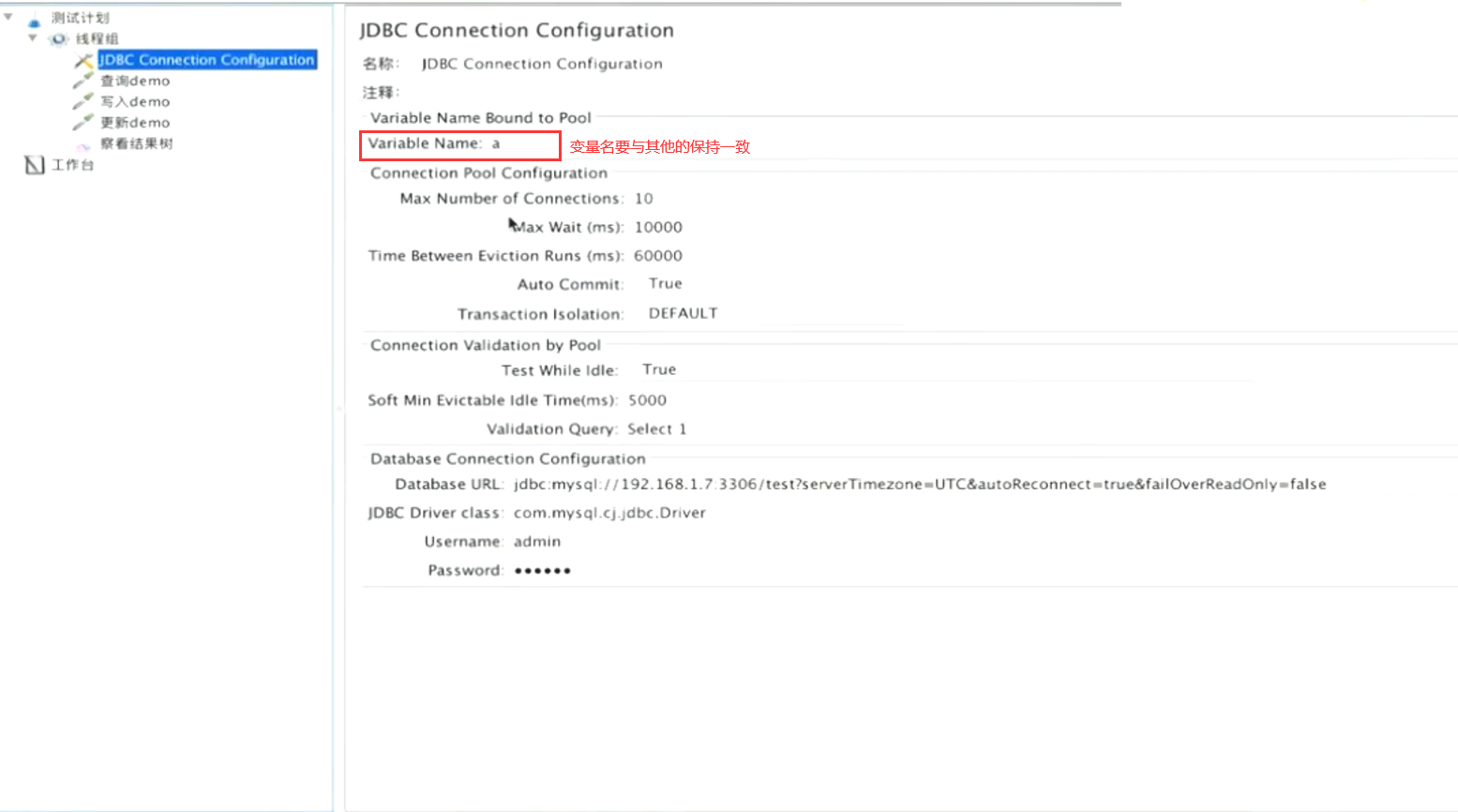
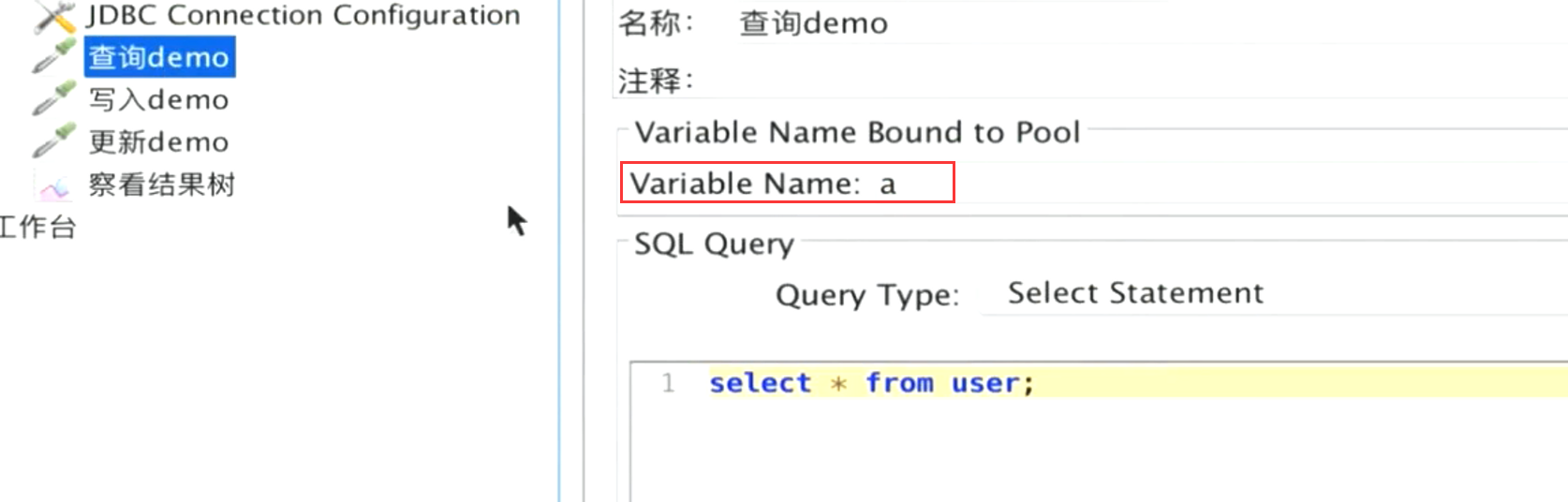
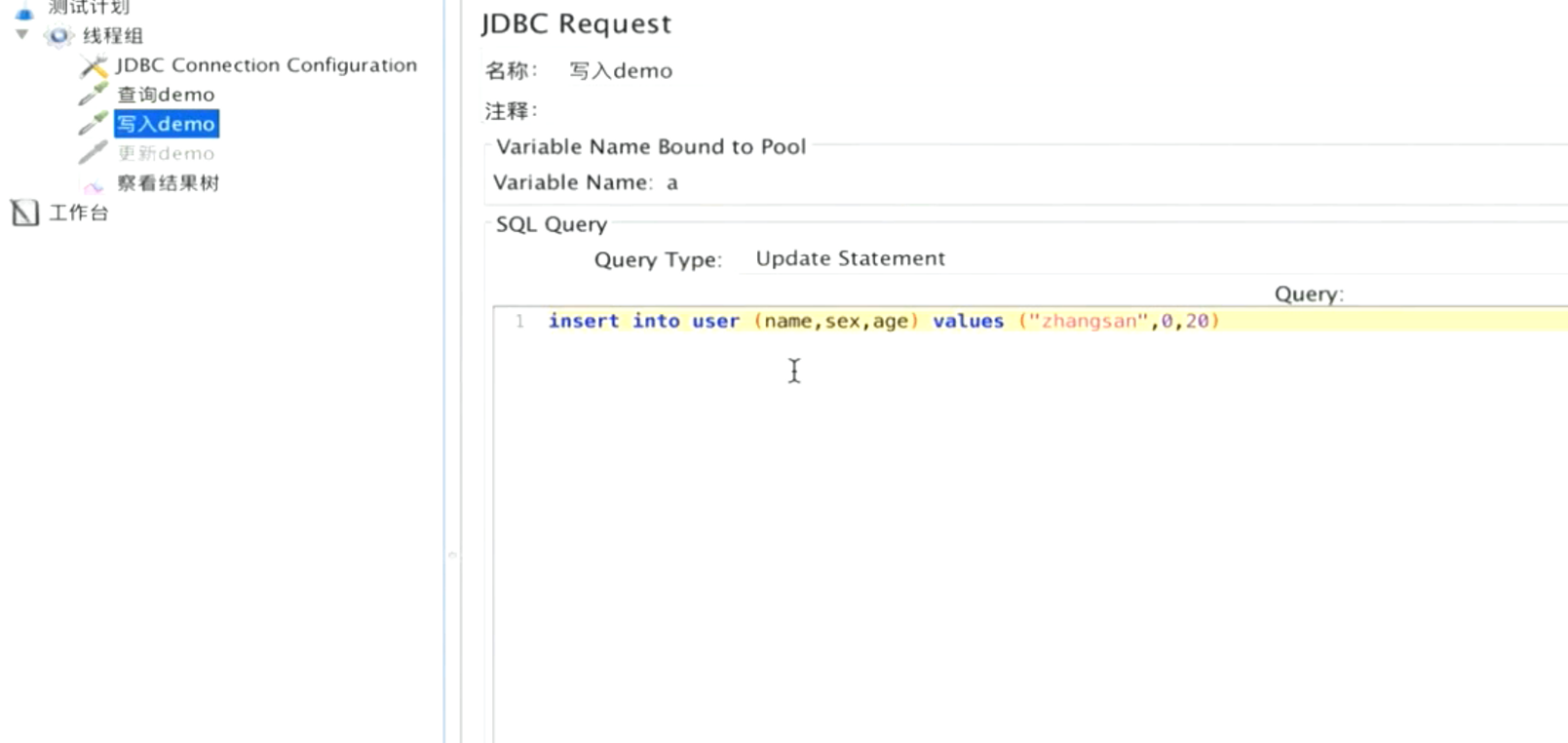
2.DBC Request写sq|脚本
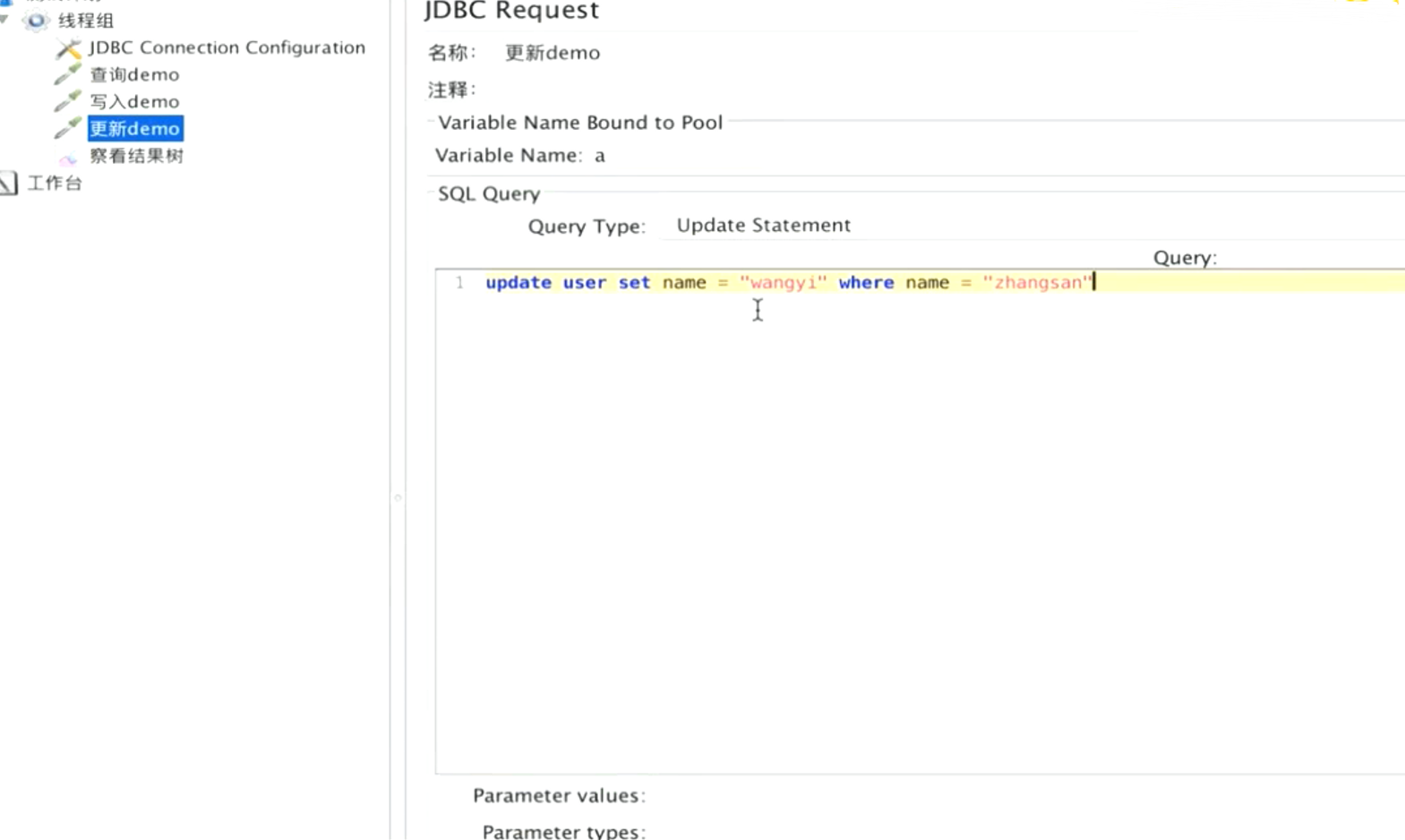
3.打开性能监控工具进行查询
- 其他 监控部署好、SQL架构是否合理、异常类测试(主从延迟、主从宕机)
下面是配套资料,对于做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!

编辑资料获取方式 :xiaobei_upup,添加时备注“csdn alex”
我是小北,专注软件测试和测试开发高薪就业和跳槽,有很多就业方案可以分享给你。








![[word] Word如何删除所有的空行? #职场发展#学习方法](https://img-blog.csdnimg.cn/img_convert/794d729053d074244e428cdca4ddbbe2.png)