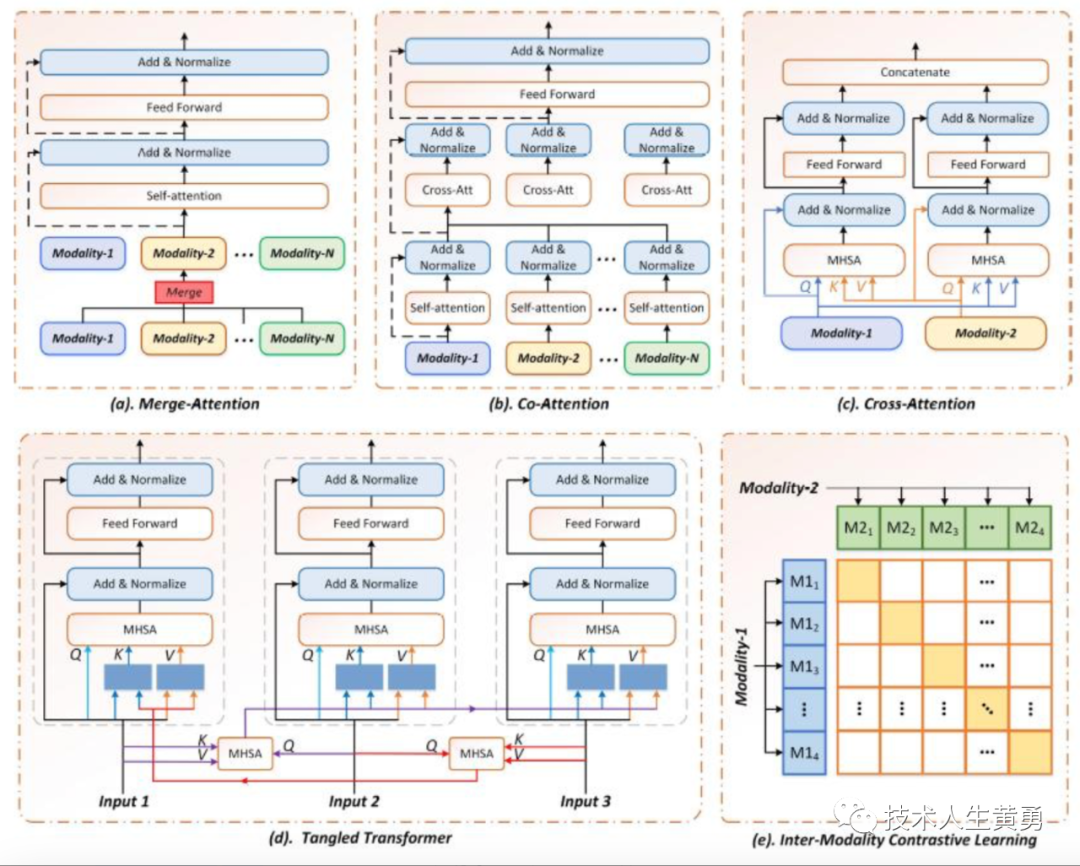
各大互联网企业开发的类ChatGPT大模型
- 国际互联网公司
- 国内互联网公司
ChatGPT是由开放人工智能公司OpenAI开发的一款基于人工智能技术的聊天机器人,采用了大规模Transformer网络,可以实现对话的生成和理解。其可以进行多轮对话,并具备一定的语言理解和推理能力,可以回答关于各种主题的问题,并为用户提供个性化的服务。ChatGPT的目标是打造一种真正智能、有趣、富有同理心的对话体验,使人与机器之间的交流更加自然和流畅。

国际互联网公司
除了ChatGPT,目前世界上各大计算机企业公司研究发布的与ChatGPT类似大模型列举如下:
-
GShard:谷歌开发的分布式训练技术,在超过600台TPU上训练了一个有1000亿个参数的神经网络模型,其规模比当前最大的GPT-3模型还要大。
-
M6:由阿里巴巴发布的多模态机器学习平台,其中包括一个基于大规模Transformer模型的自然语言处理模块,可以完成文本分类、信息抽取等任务。
-
DALL-E:由OpenAI推出的图像生成模型,可以从自然语言描述中生成对应的图像,也是基于GPT模型构建。
-
Codex:由GitHub发布的代码生成模型,使用基于GPT-3模型的深度学习算法,可以根据人类语言描述生成代码。
-
T5:由Google Brain团队开发的模型,使用类似GPT的架构,能够在各种NLP任务中表现出色,如QA、文本分类、翻译等。
-
Megatron:由Nvidia发布的语言模型训练工具包,可以快速训练超大规模的语言模型。使用这个工具包,团队已经成功训练了超过10亿个参数的语言模型。
-
Turing NLG:由微软发布的自然语言生成模型,能够生成高质量的文章、摘要、对话等。
-
CLIP:由OpenAI发布的跨语言图像-文本预训练模型,可以将对图像和自然语言的理解相结合,实现更为精准的图像识别任务。
国内互联网公司
此外,国内的各大互联网企业也展开了相关开发研究,具有代表性的有:
-
百度 - 文心一言:拥有超过100亿个参数的文本生成模型,可以用于文本摘要、机器翻译等任务,并且在多项自然语言处理领域比赛中获得最好成绩。
-
腾讯 - HunYuan 大模型:由腾讯 AI 实验室发布,是一个拥有5,800亿个参数的大规模预训练语言模型,在7个自然语言处理基准测试中均取得了最好结果。
-
阿里 - 通义大模型:由阿里巴巴 DAMO 实验室打造的语言模型,拥有百亿级别的参数规模,在问答、机器翻译等自然语言处理任务上具有很好的性能。
-
华为 - 盘古大模型:华为推出的百亿级别的语言模型,可以完成文本摘要、问答等任务,具有较好的泛化能力和效果稳定性。
-
复旦大学 - MOSS:由复旦大学 NLP 实验室发布的大规模预训练语言模型,具有强大的语义表示学习能力,可以完成多个自然语言处理任务。
-
阿里巴巴达摩院 - 通义千问: 在GPT-3.5基础上进行创新优化,具有更好的性能表现和更强的适应性,并可广泛应用于智能客服、智能问答、智能翻译等领域。