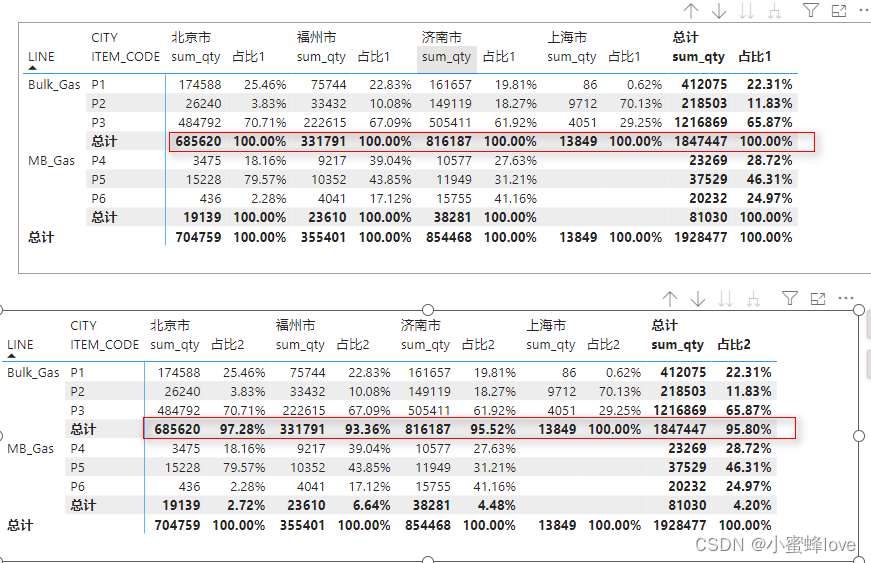
收到了个word版的电子书,需要拆分并转换为md存储到数据库中,便于搜索,记录下用正则提取文章的过程
word原文中有目录,可提取出目录后,在正文中根据目录来正则提取文章
正则的多行匹配
在匹配大量文章的时候,需要用到多行匹配
- 使
.匹配\n:要多行匹配,那么需要加上re.S和re.M标志. 加上re.S后, .将会匹配换行符,默认.不会匹配换行符
str = "a23b\na34b"
re.findall(r"a(\d+)b.+a(\d+)b", str)
#输出[]
#因为不能处理str中间有\n换行的情况
re.findall(r"a(\d+)b.+a(\d+)b", str, re.S)
#s输出[('23', '34')]
- 加上re.M后, ^ 标志将会匹配每一行,默 认 和 标志将会匹配每一行,默认^和 标志将会匹配每一行,默认和只会匹配第一行.
str = "a23b\na34b"
re.findall(r"^a(\d+)b", str)
#输出['23']
re.findall(r"^a(\d+)b", str, re.M)
#输出['23', '34']
word转md
开始用的是pandoc这个神器来完成docx转换为md https://pandoc.org/installing.html 下载zip文件,解压缩并加入到环境变量中
通过命令转换 pandoc -f docx -t markdown --extract-media ./ -o 原版1.md 原版.docx
对于py中,可以用mammoth,可以把word中的图片也保存下来。它是一个用于将Word文档转换为HTML的模块,它支持在Python、JavaScript、Java、 .Net等平 台使用。
而markdownify则是将HTML转换为Markdown文档的模块。
https://pypi.org/project/markdownify/
import time
import mammoth
from markdownify import markdownify# 转存 Word 文档内的图片
def convert_img(image):with image.open() as image_bytes:file_suffix = image.content_type.split("/")[1]path_file = "./img/{}.{}".format(str(time.time()),file_suffix)with open(path_file, 'wb') as f:f.write(image_bytes.read())return {"src":path_file}# 读取 Word 文件
with open(r"原版.docx" ,"rb") as docx_file:# 转化 Word 文档为 HTMLresult = mammoth.convert_to_html(docx_file,convert_image=mammoth.images.img_element(convert_img))# 获取 HTML 内容html = result.value# 转化 HTML 为 Markdownmd = markdownify(html,heading_style="ATX")with open("./docx_to_html.html",'w',encoding='utf-8') as html_file,open("./docx_to_md.md","w",encoding='utf-8') as md_file:html_file.write(html)md_file.write(md)messages = result.messages
手动复制md文件中的目录部分到ml.md
正则提取目录
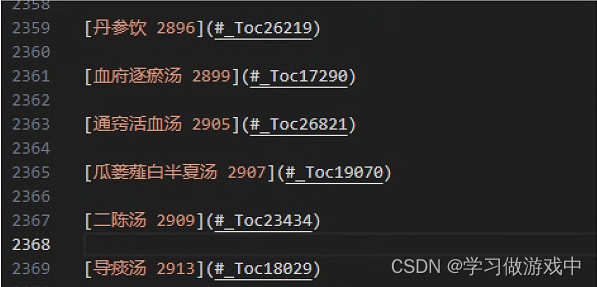
import re
import csvwith open('ml.md', 'r', encoding='utf-8') as source_file:content = source_file.read()pattern = r'^\[([\u4e00-\u9fa5].*?[\u4e00-\u9fa5].*?)[\:,\s].*?\].*?\)$'# 使用re.findall找到所有匹配项
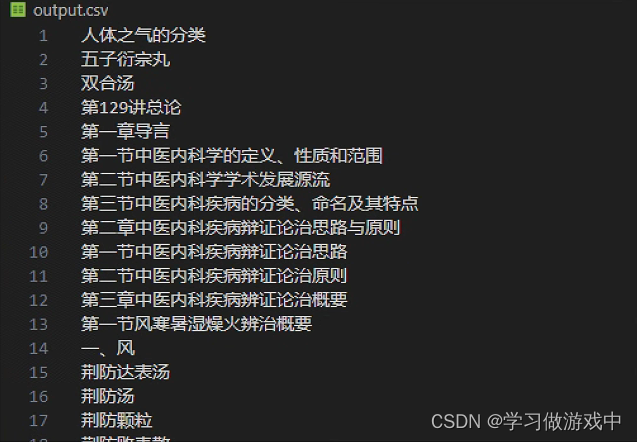
matches = re.findall(pattern, content, re.M)with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)# 将每个匹配的单词作为一行写入CSV文件for match in matches:writer.writerow([match])
保存为csv文件
正则提取文章正文
import re
import jsondir = "文章"
types = ['药方','风寒暑湿燥火辨治','风']
articles = ['荆防达表汤','荆防汤','荆防颗粒','荆防败毒散','桑菊饮','防风汤','牵正散','玉真散','天麻钩藤饮','镇肝熄风汤','羚角钩藤汤','大定风珠','补肝汤']
# 写入到md文件
def write_md(name, content):with open(f"{dir}/{name}.md", "w", encoding="utf-8") as f:f.write(content)# 正则找到匹配的文章,在嗨正则里不可以,但是在py里是能用的
def match_article(name):pattern = re.compile('^(#\s+'+name+'.*?)^#\s+[\u4e00-\u9fa5]+', re.MULTILINE | re.DOTALL)items = pattern.search(content).group(1)return itemswith open('docx_to_md.md', "r", encoding="utf-8") as f:content = f.read()for i in articles:print(f"{i}")z_content = match_article(i)filename = '-'.join(types)+'-'+iwrite_md(filename, z_content)