时序数据库基石:LSM Tree的增删查改
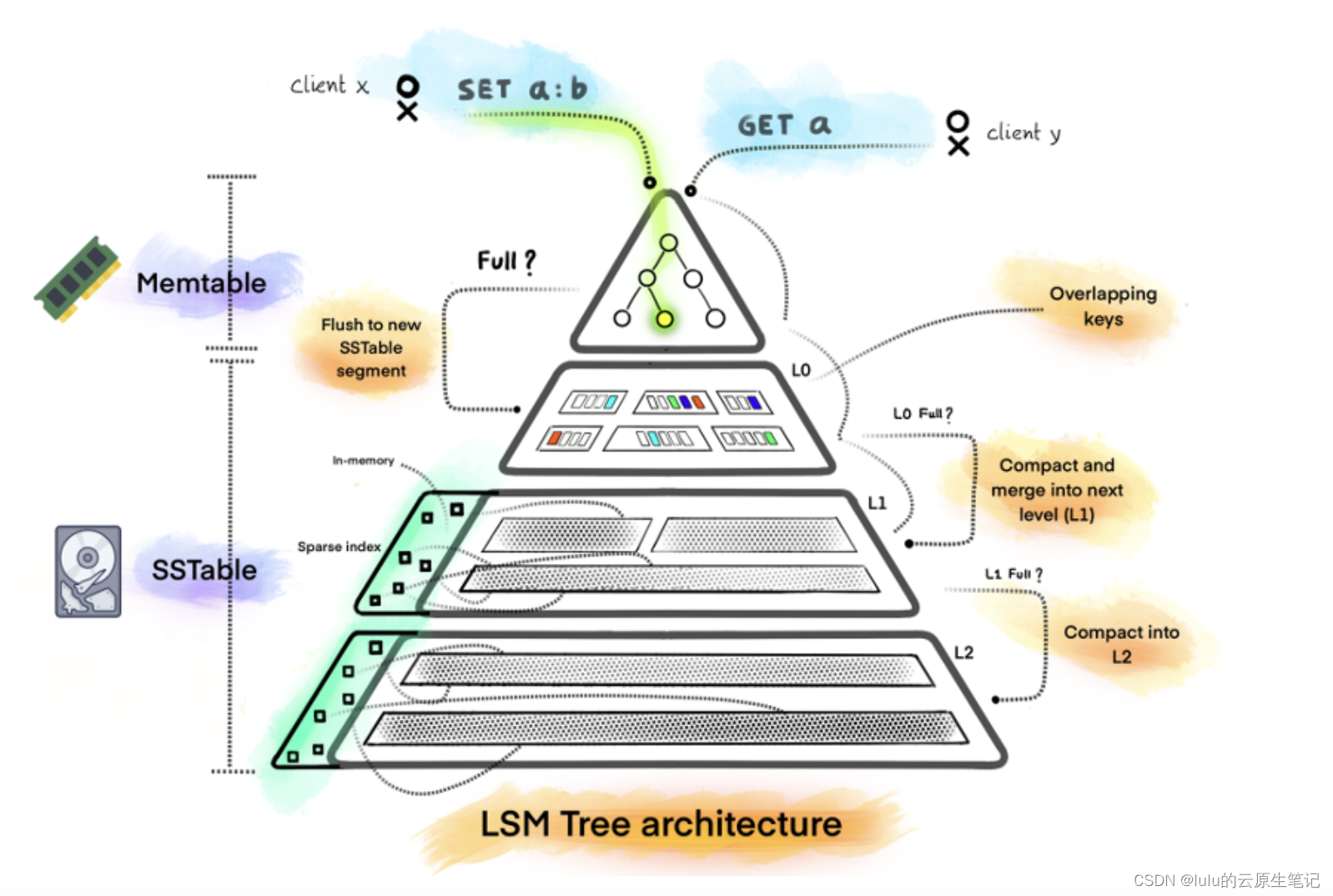
LSM结构
LSM树将任何的对数据操作都转化为对内存中的Memtable的一次插入。Memtable可以使用任意内存数据结构,如HashTable,B+Tree,SkipList等。对于有事务控制需要的存储系统,需要在将数据写入Memtable之前,先将数据写入持久化存储的WAL(Write Ahead Log)日志。由于WAL日志是顺序Append到持久化存储的,因此无论对磁盘还是SSD都是非常友好的。
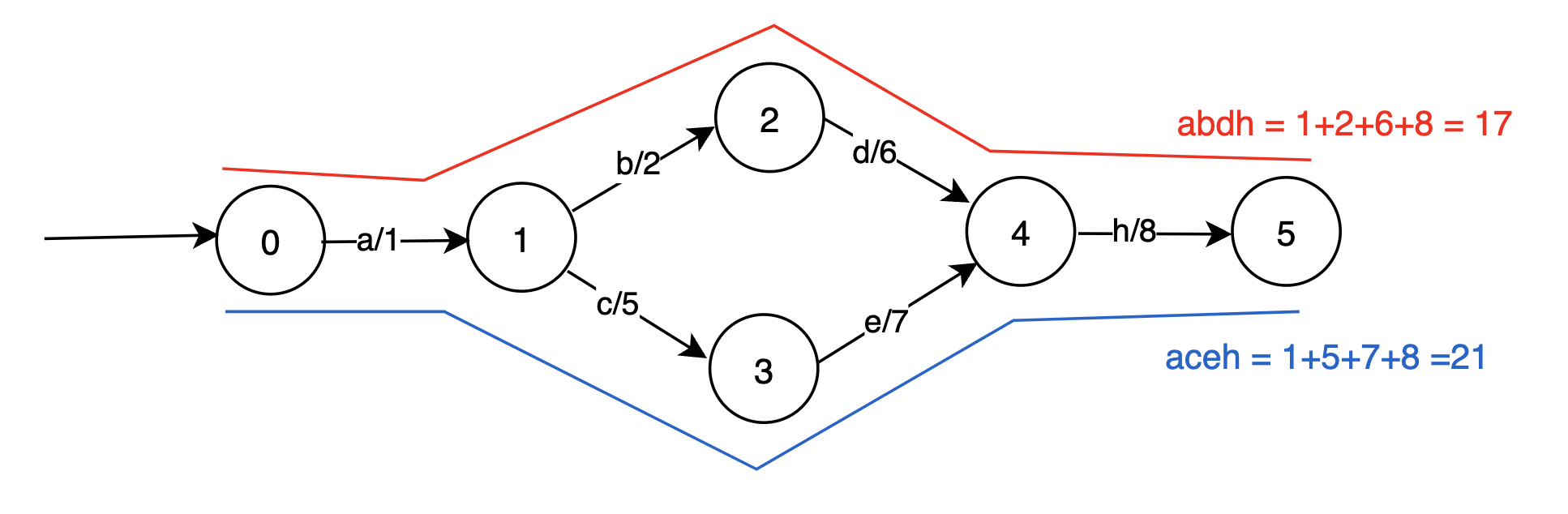
LSM树各类操作
前面我们提到了LSM的结构和合并,现在来看下LSM结构的增删查改:
再强调一次下面的概念:
- LSM树的增加、删除、修改(这三个都属于写操作)都是在内存中倒腾,完全没涉及到磁盘操作。当要修改现有数据时,LSM Tree并不直接修改旧数据,而是直接将新数据写入新的SSTable中。同样的,删除数据时,LSM Tree也不直接删除旧数据,而是写一个相应数据的删除标记的记录到一个新的SSTable中
- LSM Tree写数据时对磁盘的操作都是顺序块写入操作,而没有随机写操作。
- LSM Tree这种独特的写入方式,导致在查找数据时,LSM Tree就不能像B+树那样在一个统一的索引表中进行查找,而是从最新的SSTable到老的SSTable依次进行查找。如果在新SSTable中找到了需查找的数据或相应的删除标记,则直接返回查找结果;如果没有找到,再到老的SSTable中进行查找,直到最老的SSTable查找完
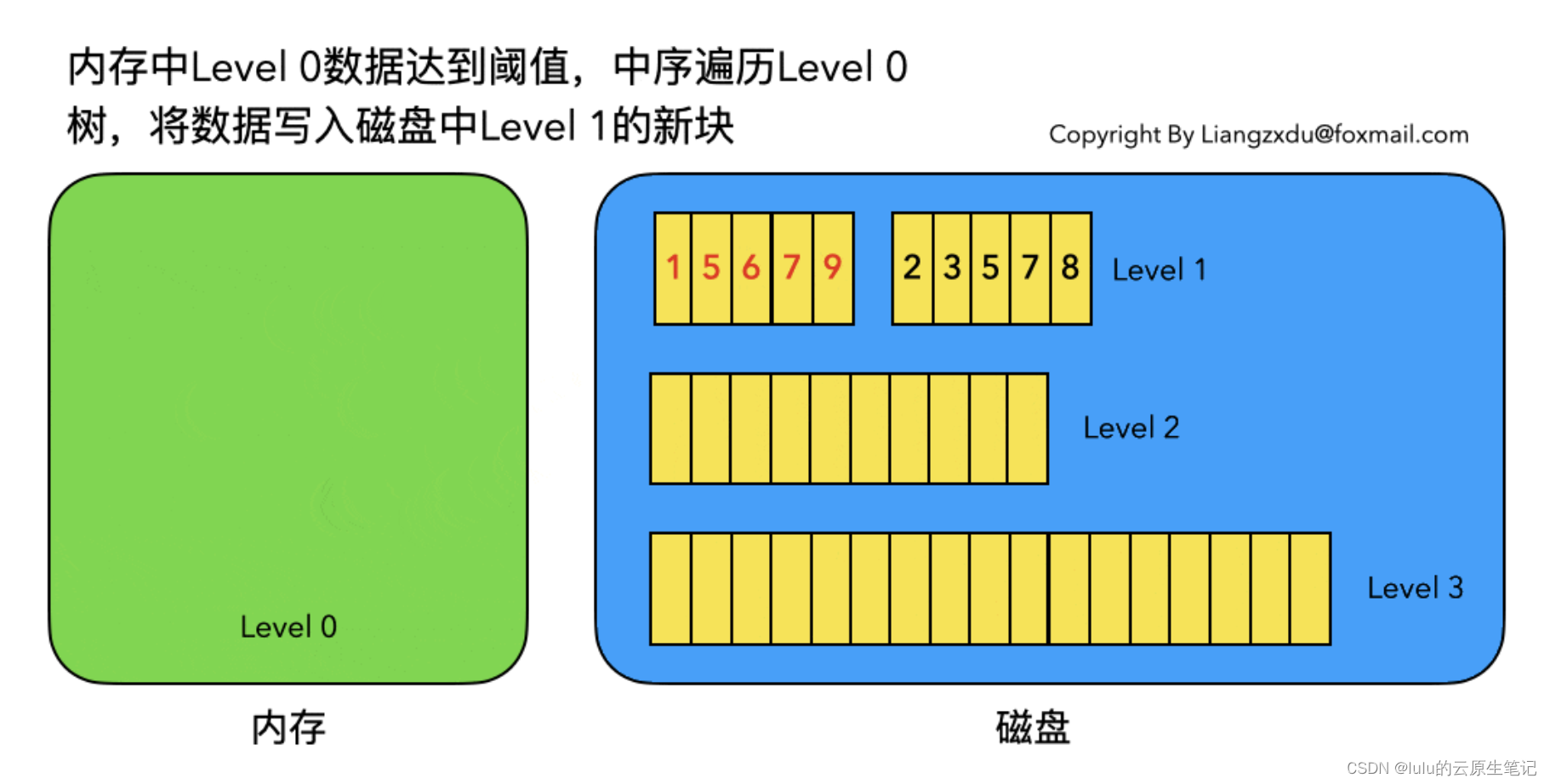
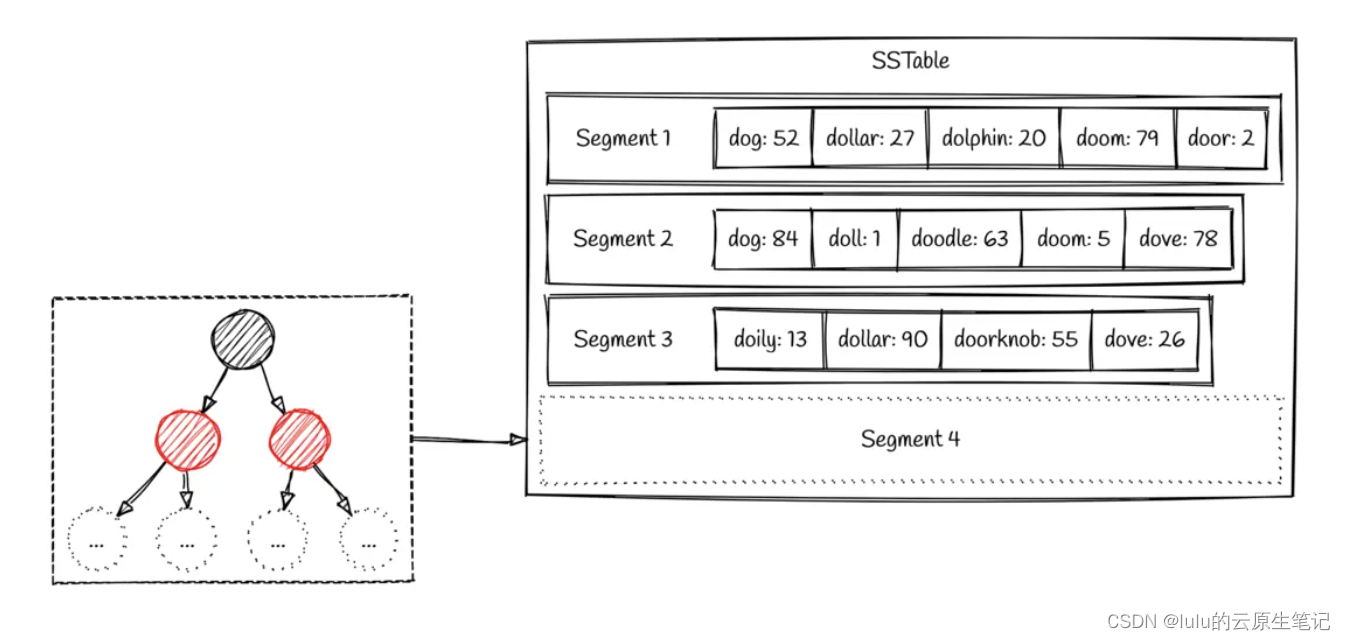
- 为了提高查找效率,LSM Tree对SSTable进行分层、有序组织,也就是说把SSTable组织成多层,同一层可以有多个SSTable,同一个数据在同一层的多个SSTable中可以不重复,而且数据可以做到在同一层中是有序的,即每一个SSTable内的数据是有序的,前一个SSTable的最大数据值小于后一个SSTable的最小数据值(实际情况比这个复杂,后面会介绍)。这样可以加快在同一层SSTable中的数据查询速度。同时,LSM Tree会将多个SSTable合并(Compact)为一个新的SSTable,这样可以减少SSTable的数量,同时把修改前的数据或删除的数据真正从SSTable中删除,减小了SSTable的大小(这就是Log-Structured Merge Tree名字中Merge一词的由来),对提高查找性能极其重要
- LSM树将任何的对数据操作都转化为对内存中的Memtable的一次插入
- Memtable可以使用任意内存数据结构,如HashTable,B+Tree,SkipList
- 对于有事务控制需要的存储系统,需要在将数据写入Memtable之前,先将数据写入持久化存储的WAL(Write Ahead Log)日志。由于WAL日志是顺序Append到持久化存储的,因此无论对磁盘还是SSD都是非常友好的。
小话题:加入了WAL的结构如下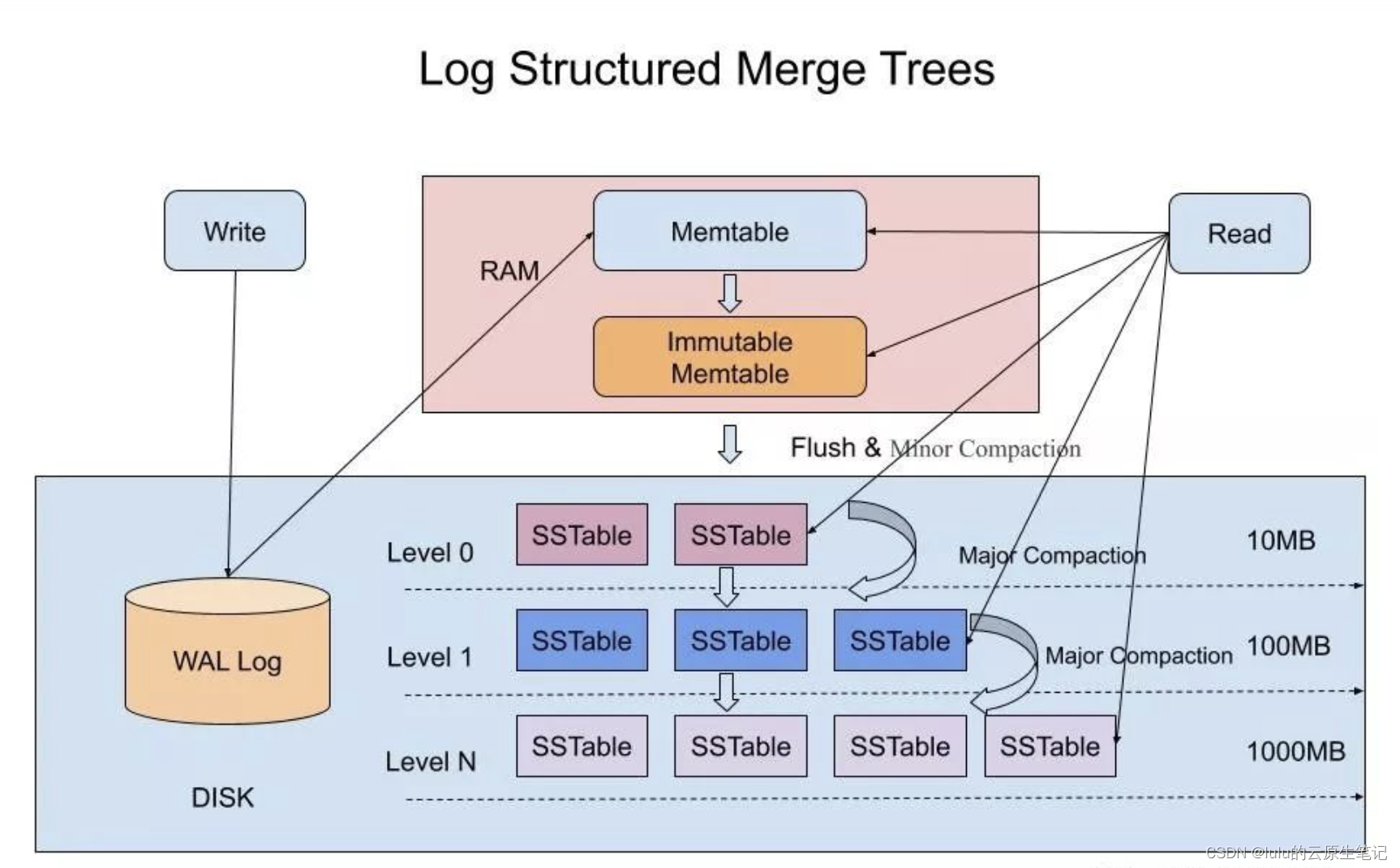
LSM树支持常见的变更操作,插入,删除,更新。常见的实现里,为了统一变更的数据结构标识,往MemTable里写入的除了<Key, TimeStamp, Value>三元组外,还会带上操作的类型。所有的变更操作并不直接修改磁盘上的数据,而只是将变更写入MemTable。因此数据变更除了WAL日志一次顺序IO之外,没有额外的任何随机IO,插入效率非常高。
1、数据写入
无WAL的写入:
由于 LSM tree 只会进行顺序写入,所以自然而然地就会引出这样一个问题,写入的数据可能是任意顺序的,我们又如何保证数据能够保持 SSTable 要求的有序组织呢?
这就需要引入新的常驻内存 (in-memory) 数据结构: memtable_了, _memtable 的底层数据结构可以是类似红黑树这种,当有新的写入操作则将数据插入到红黑树中。
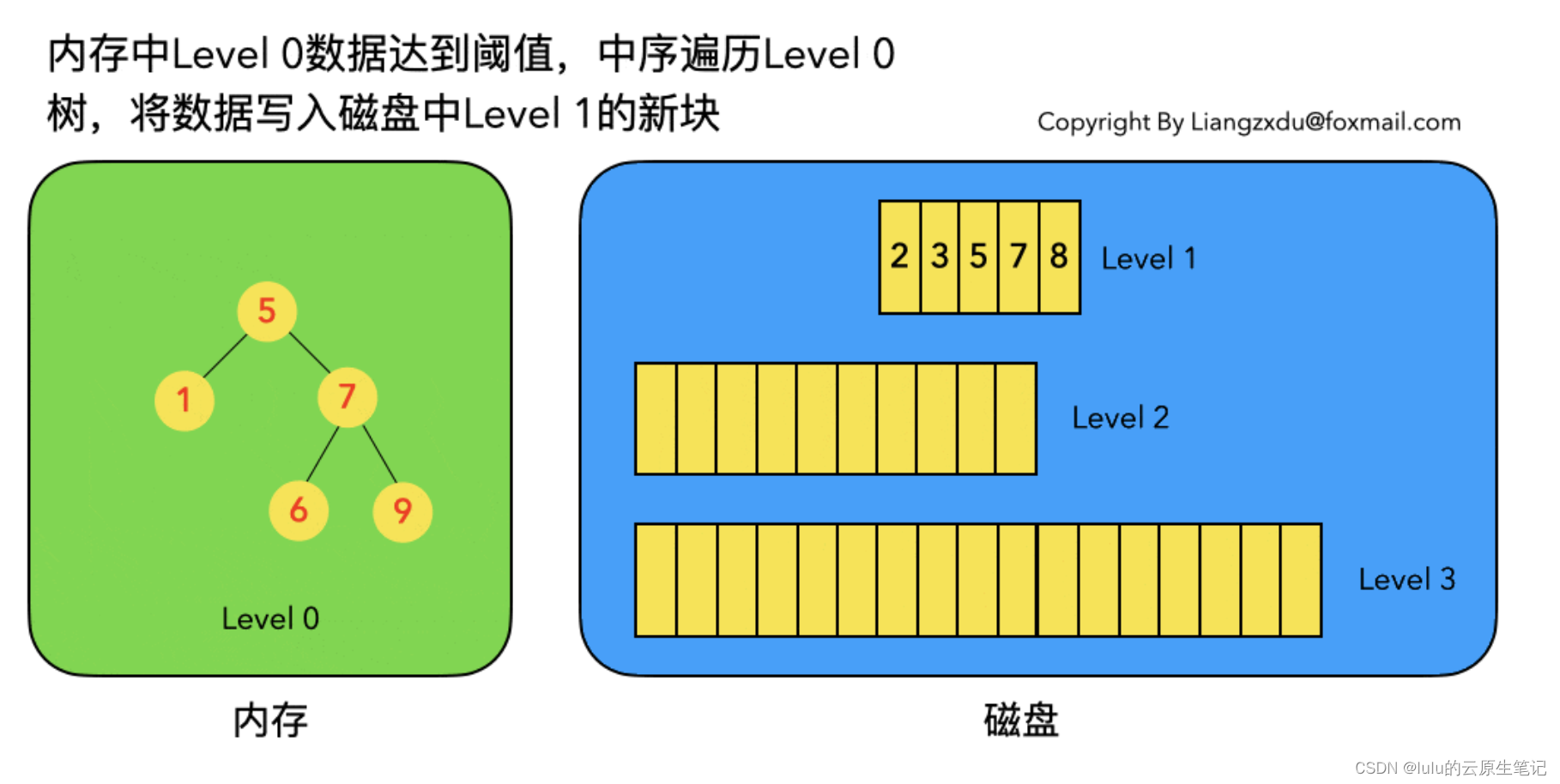
写入操作会先把数据存储到红黑树中,直至红黑树的大小达到了预先定义的大小。一旦红黑树的大小达到阈值,就会把数据整个刷到磁盘中,这个过程就可以把数据保证有序写入了。经过一层数据结构的承接,就可以保证单向顺序写入的同时,也能保证数据的有序。
注意:如果是有WAL的写入,则是以下操作
-
当收到一个写请求时,会先把该条数据记录在WAL Log里面,用作故障恢复。
-
当写完WAL Log后,会把该条数据写入内存的SSTable里面(删除是墓碑标记,更新是新记录一条的数据),也称Memtable。注意为了维持有序性在内存里面可以采用红黑树或者跳跃表相关的数据结构。
-
当Memtable超过一定的大小后,会在内存里面冻结,变成不可变的Memtable,同时为了不阻塞写操作需要新生成一个Memtable继续提供服务。
-
把内存里面不可变的Memtable给dump到到硬盘上的SSTable层中,此步骤也称为Minor Compaction,这里需要注意在L0层的SSTable是没有进行合并的,所以这里的key range在多个SSTable中可能会出现重叠,在层数大于0层之后的SSTable,不存在重叠key。
-
当每层的磁盘上的SSTable的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为Major Compaction,这个阶段会真正 的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于SSTable都是有序的,我们可以直接采用merge sort进行高效合并。
2、数据变更
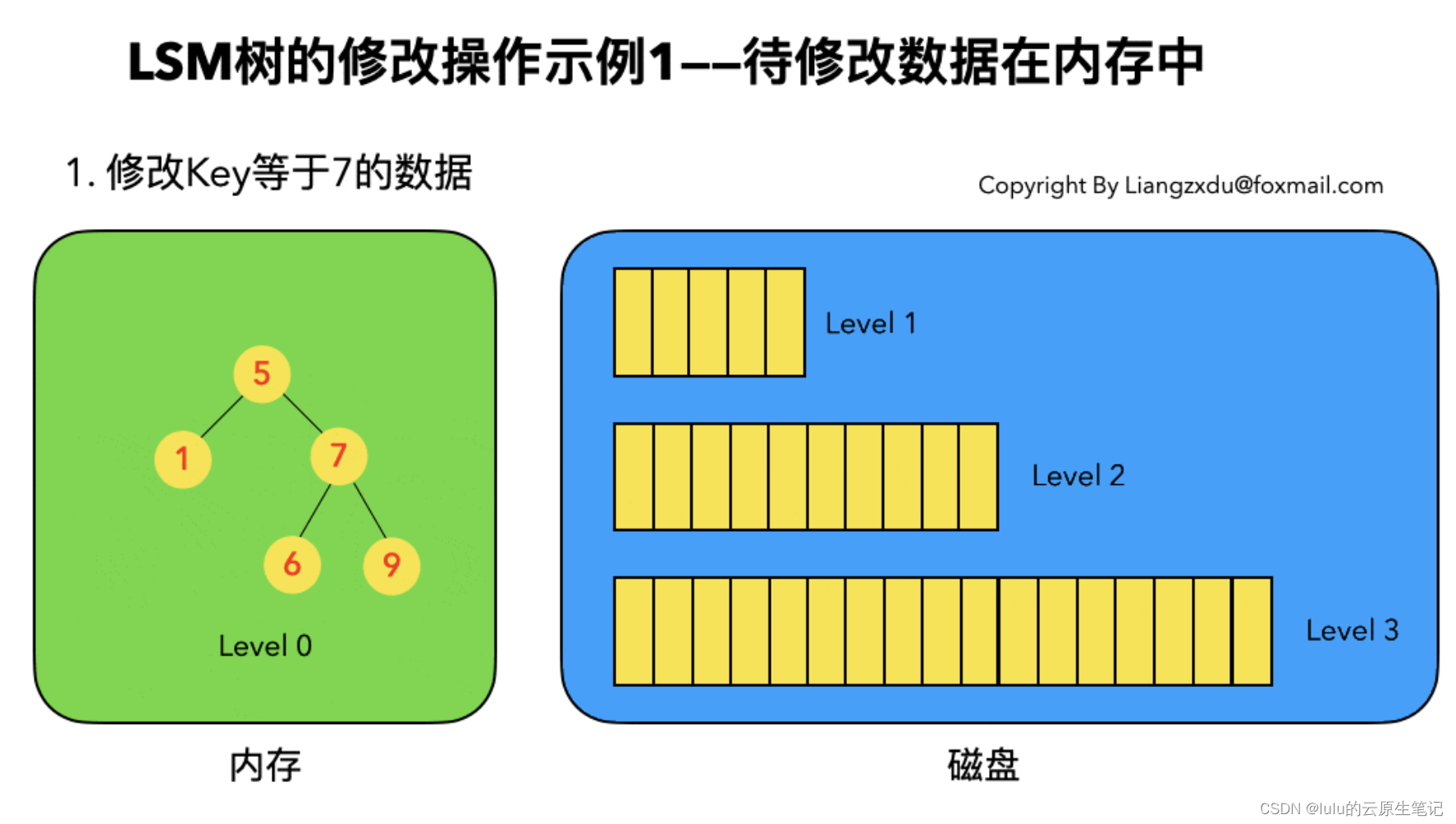
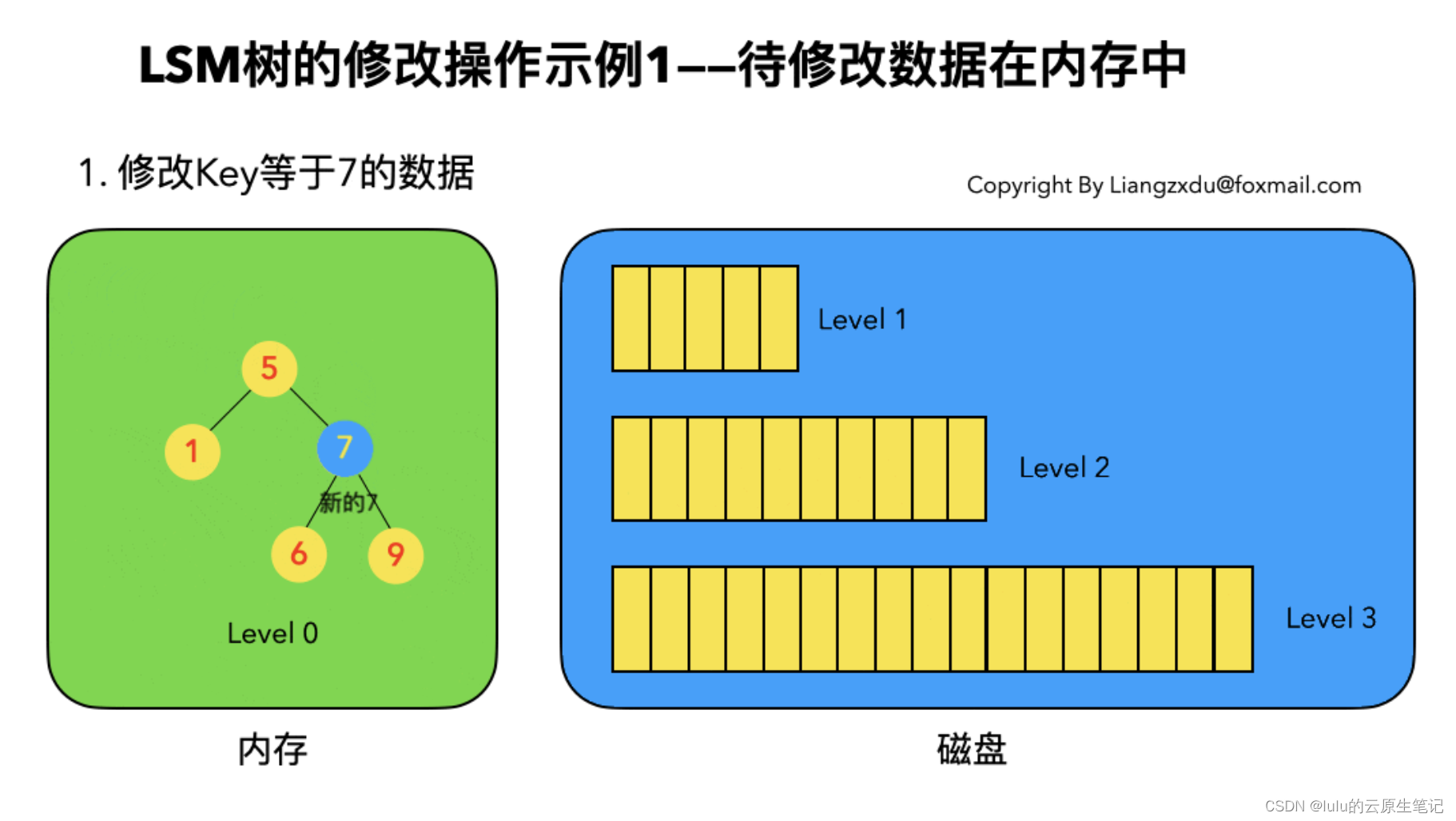
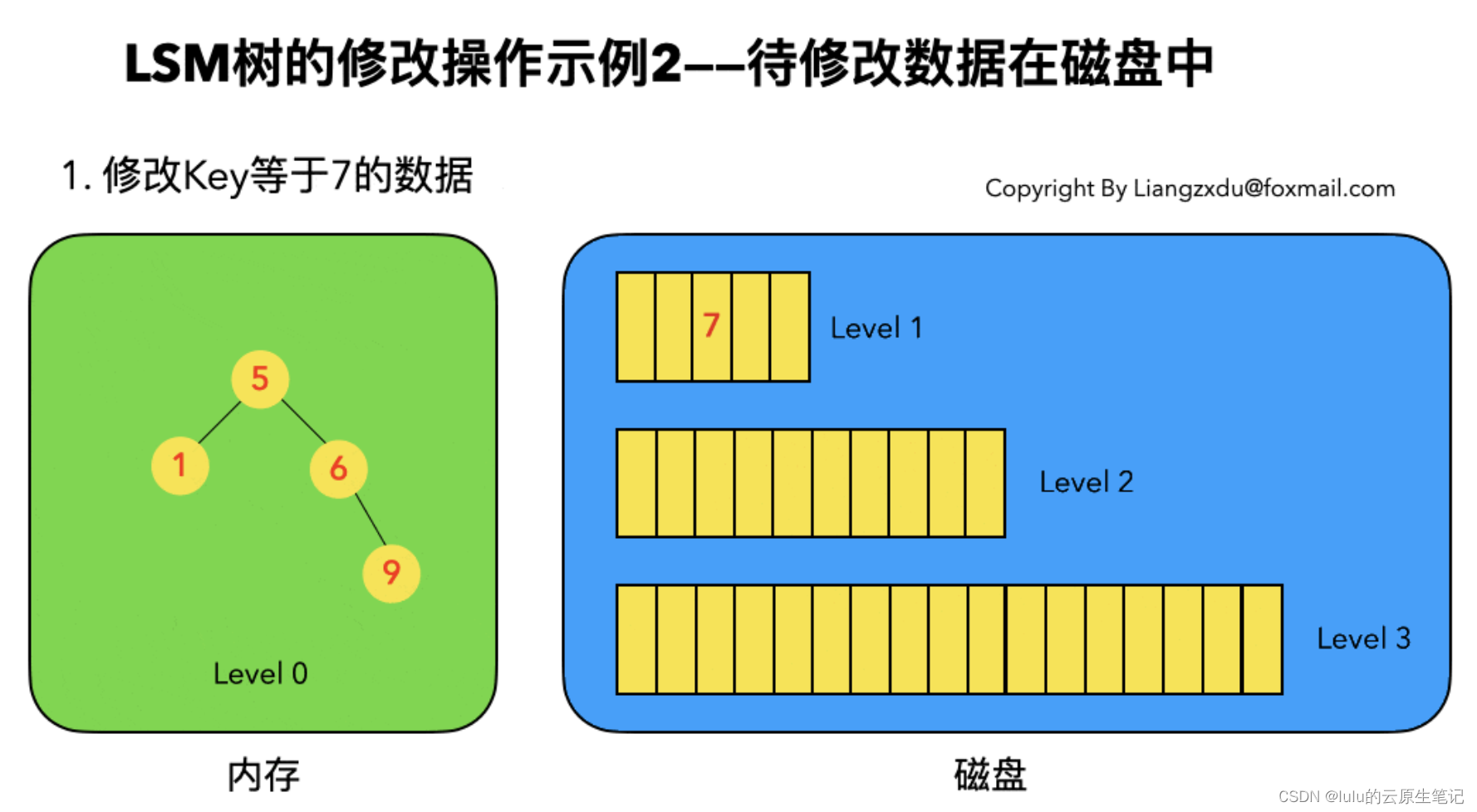
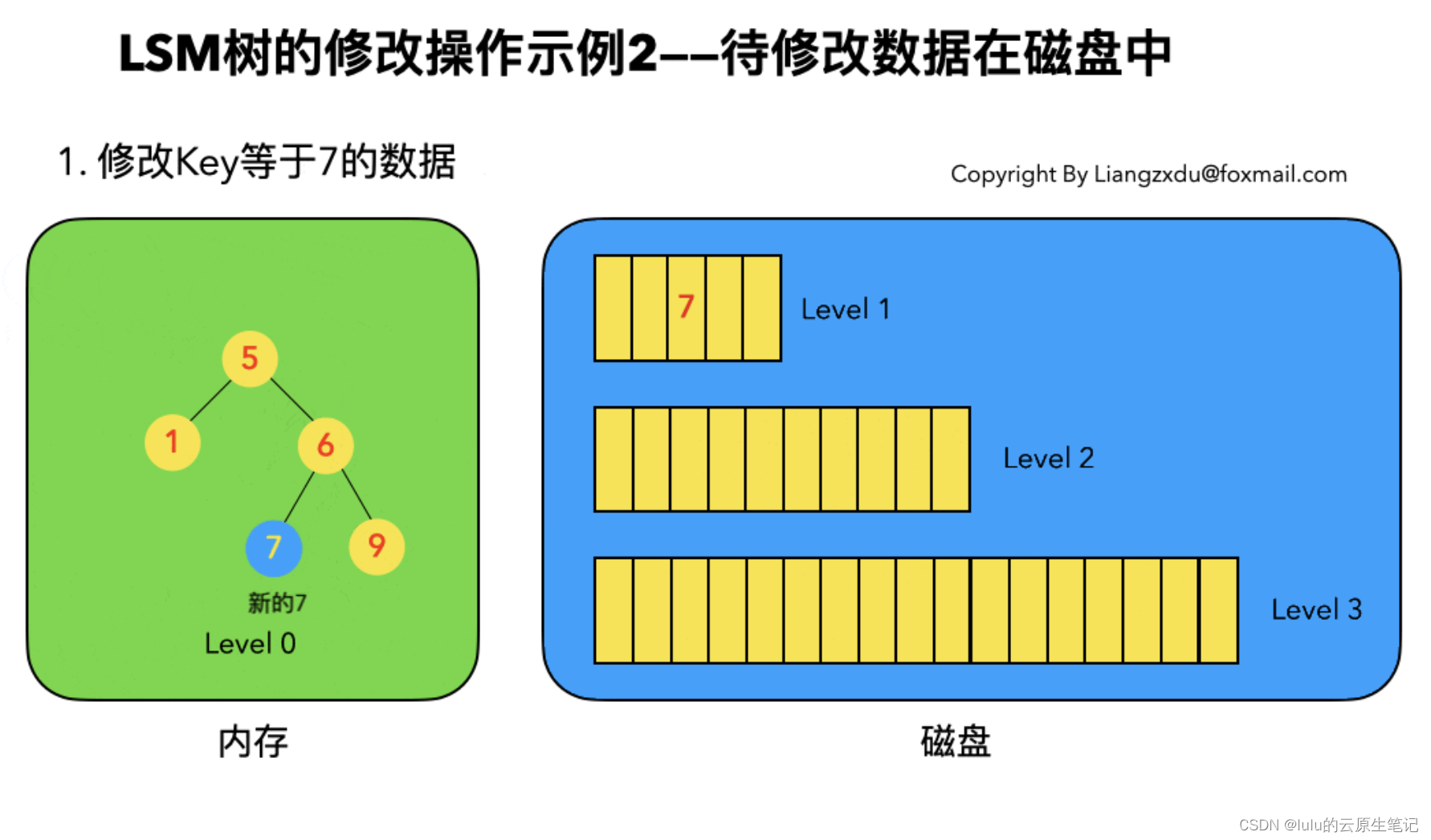
3、数据删除
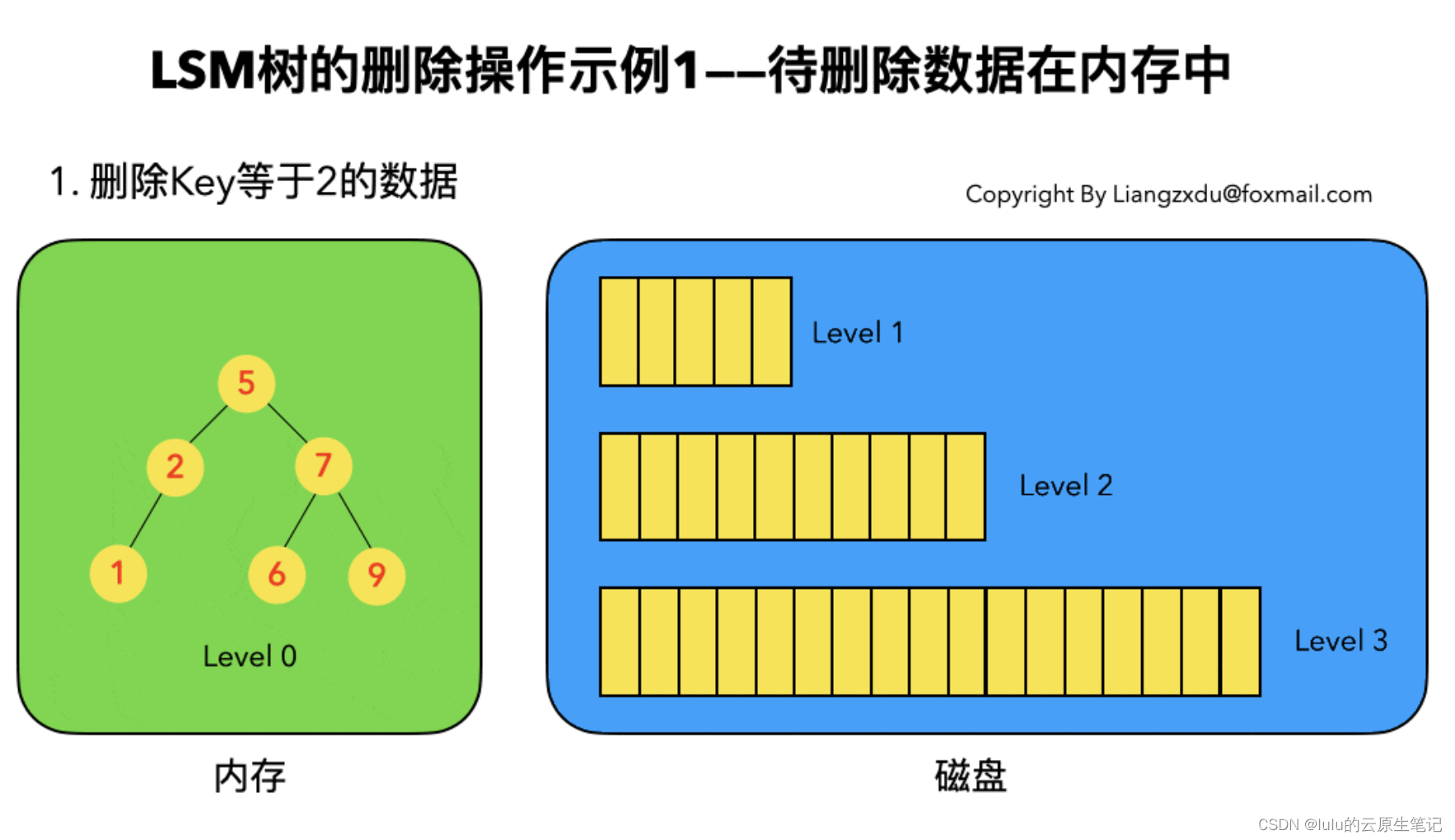
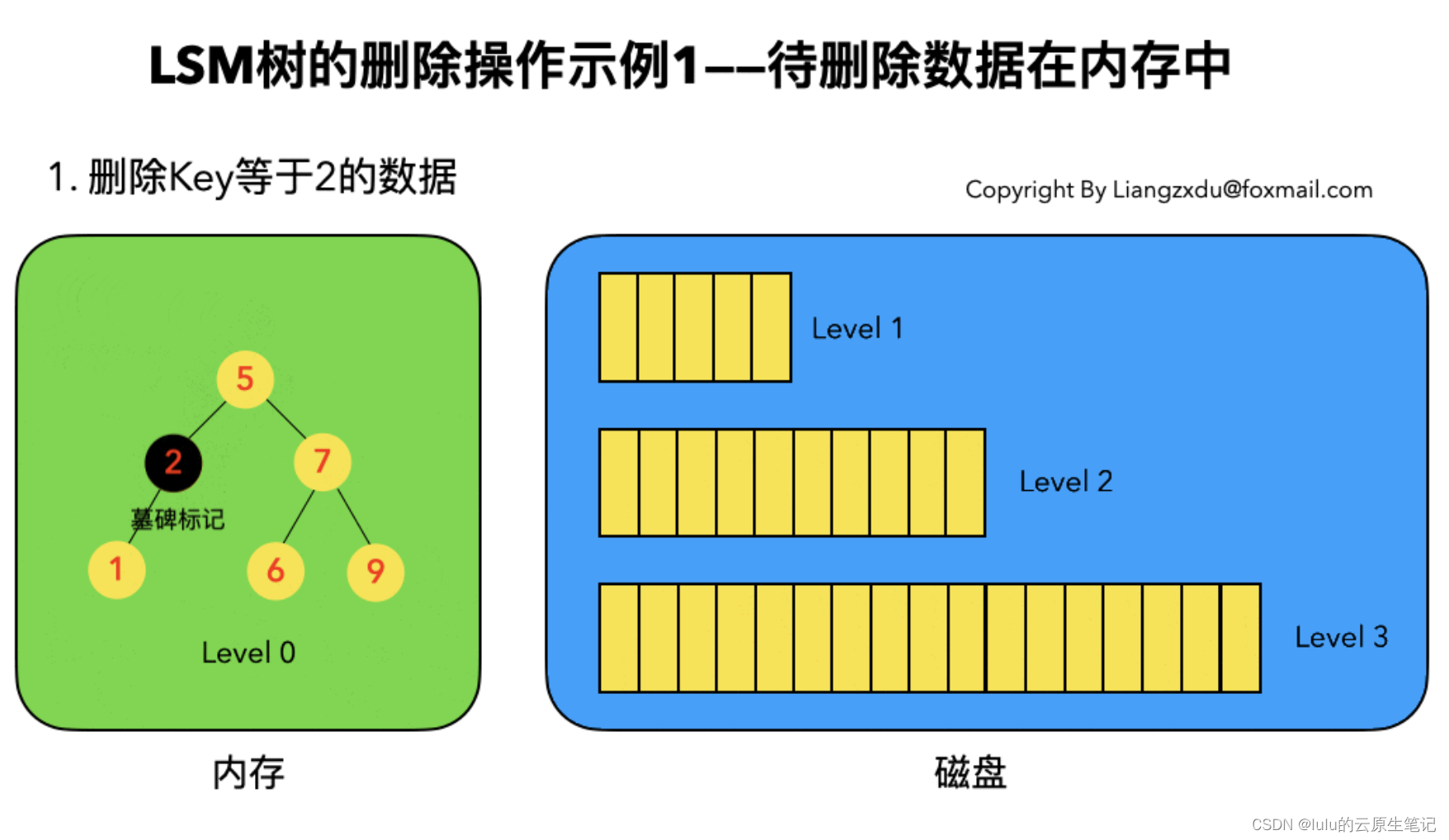
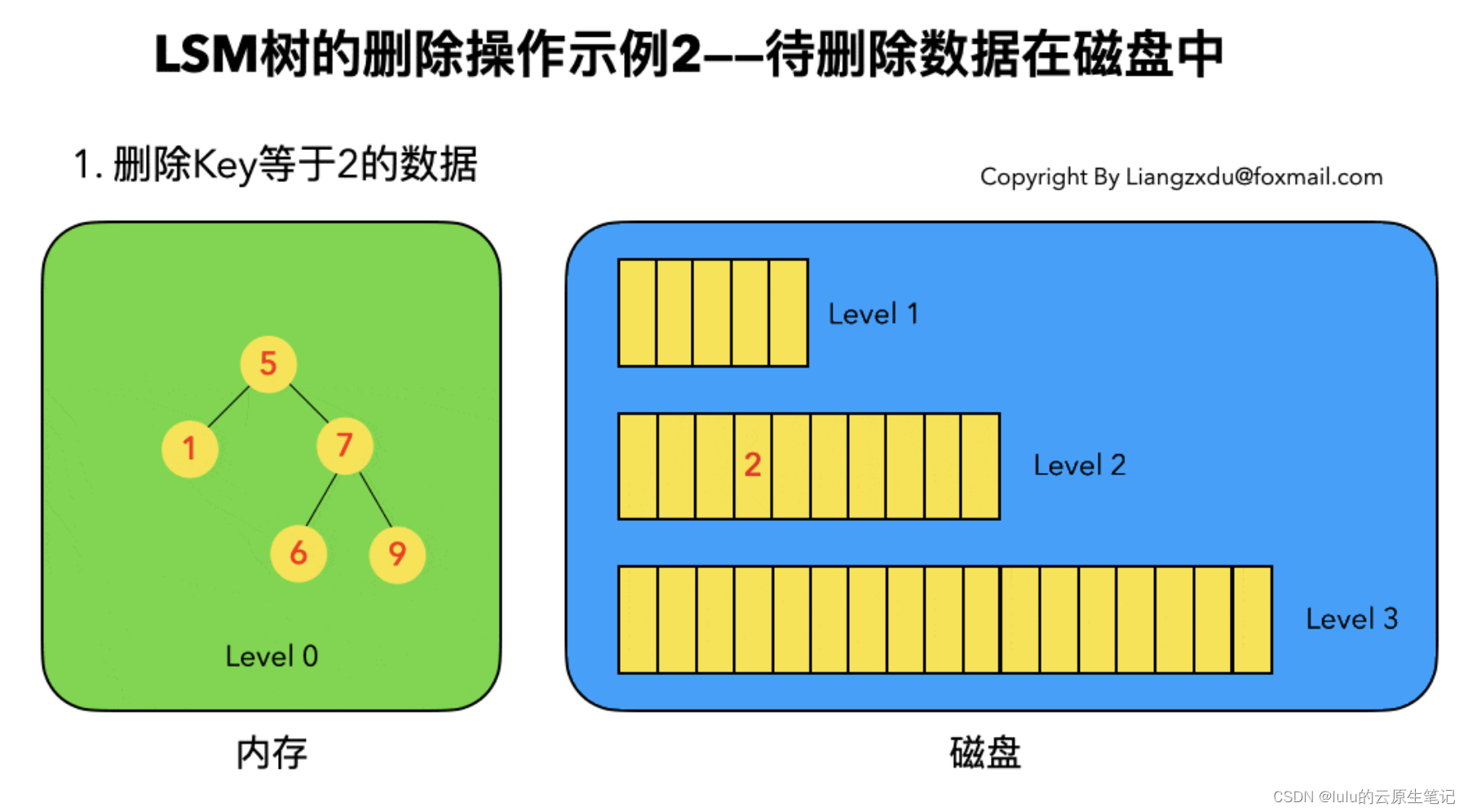
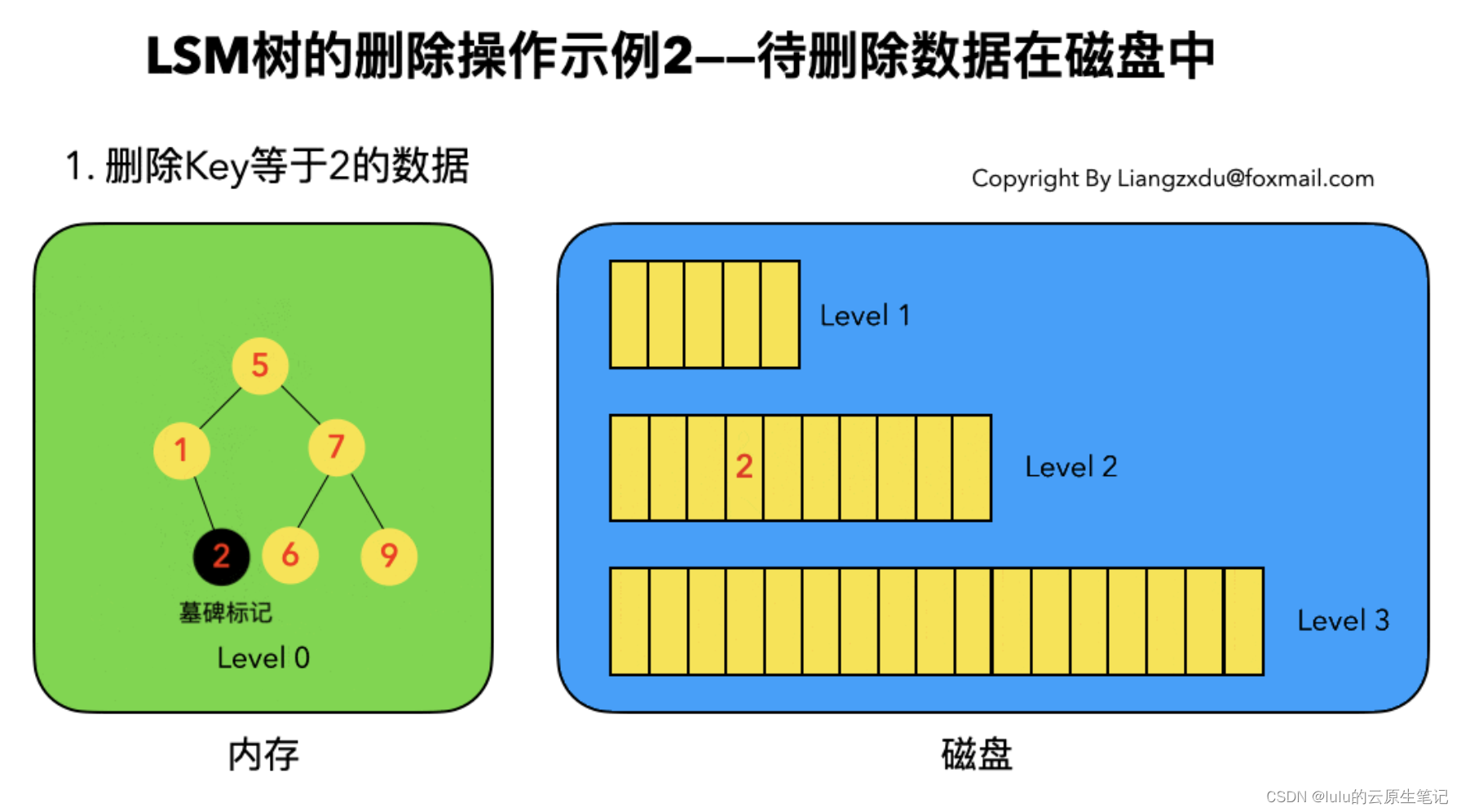
4、数据查找
-
根据LSM Tree的写入特点我们知道,如果一项数据更新多次,这项数据可能会存储在多个不同的SSTable中,甚至一项数据的不同部分的最新数据内容存储在不同的SSTable中(数据部分更新的场景)。LSM Tree把这种现象叫做空间放大(space amplification),因为一项数据在磁盘中存储了多份副本,而老的副本是已经过时了的,不需要的,数据实际占用的存储空间比有效数据需要的大。
-
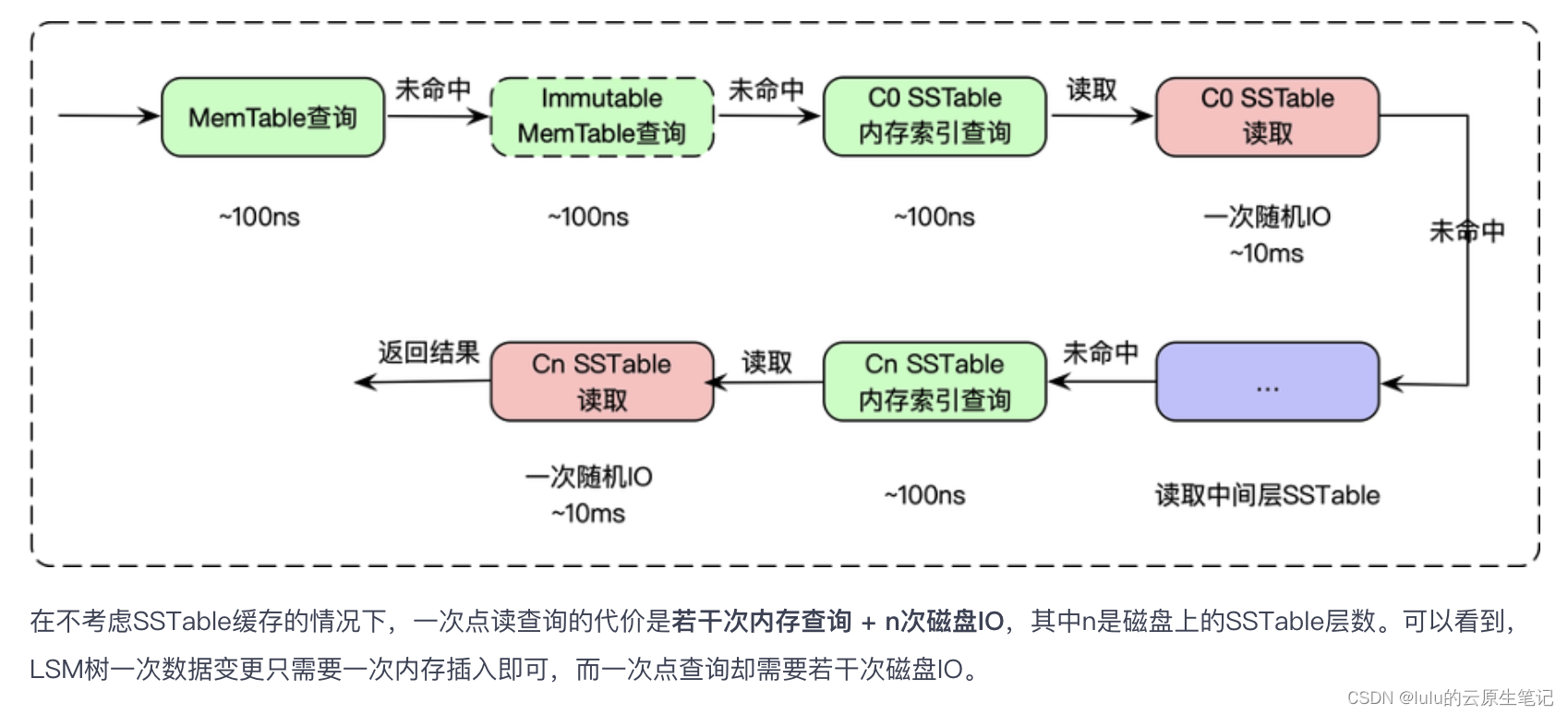
空间放大这种现象导致LSM Tree的查找过程是这样的:按新到老的顺序查找SSTable,直到在某个(或某些个)SSTable中查找到了所需的数据,或者最老的SSTable查找完也没有找到需要的数据。具体查找顺序为:先在内存MemTable中查找,然后在内存中的Immutable MemTable中查找,然后在level 0 SSTable中查找,最后在level N SSTable中查找。
-
查找某个具体的SSTable时,一般先把SSTable的元数据block读到内存中,根据BloomFilter可以快速确定数据在当前SSTable中是否存在,如果存在,则采用二分法确定数据在哪个数据block,然后将相应数据block读到内存中进行精确查找。
-
从LSM Tree数据查找过程我们可以看到,为了查找到目标数据,我们需要读取并查找不包含目标数据的SSTable,如果目标数据在最底层level N的SSTable中,我们需要读取和查找所有的SSTable!LSM Tree把这种读取和查找了无关SSTable的现象叫做读放大(read amplification)。
点查:
范围查询
范围查询根据表的查询Key的范围区间[StartKey, EndKey],通常会先对StartKey在LSM树上逐层做LowerBound查询,即每一层上找到大于或等于StartKey的数据的起始位置。由于LSM树每一层都是有序的(内存中的MemTable如果是无序的Hash表则需要全部遍历),只需要从这个起始位置开始读取数据,直到读取到EndKey为止。
5、数据合并