🥰🥰🥰来都来了,不妨点个关注叭!
👉博客主页:欢迎各位大佬!👈

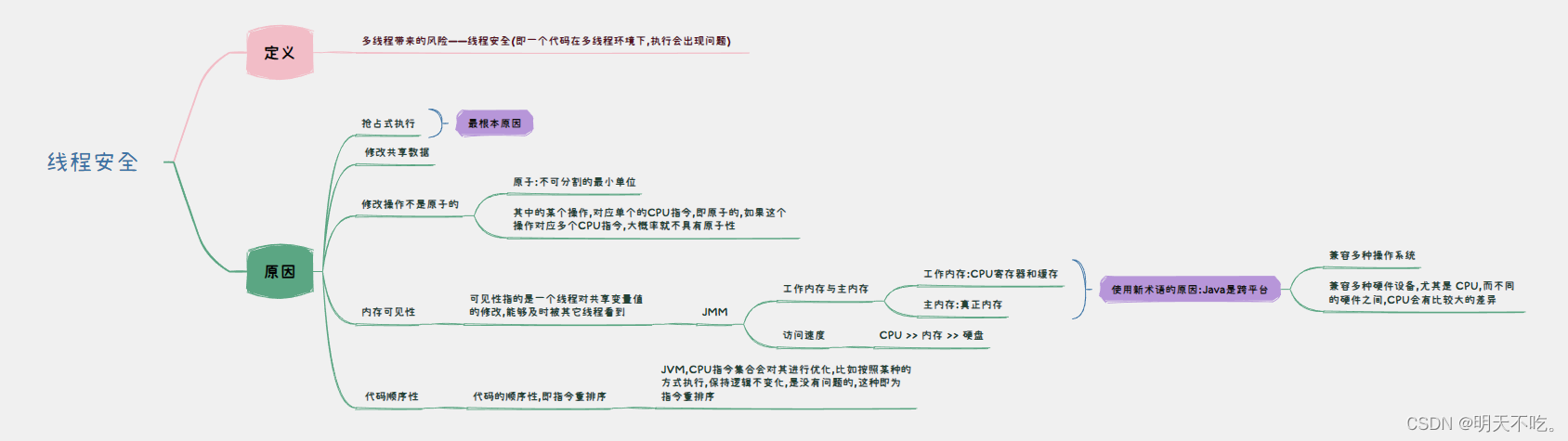
文章目录
- 1. 观察线程不安全
- 2. 线程不安全的原因
- 2.1 抢占式执行
- 2.2 修改共享数据
- 2.3 修改操作不是原子的
- 2.4 内存可见性
- 特别介绍 "工作内存"和"主内存"
- 2.5 代码顺序性
1. 观察线程不安全
多线程带来的风险——线程安全(即一个代码在多线程环境下,执行会出现问题)
那么为什么会出现线程安全问题呢???
【本质原因】线程在系统中的调度是无序的/随机的,即抢占式执行
我们创建2个线程,分别自增3w次,最后打印结果,想要得到6w的结果,通过下述代码,观察线程不安全,到底是怎么个事呢~我们一起来看看吧!
// 线程安全问题
public class Counter {private int count = 0;public void add() {count++;}public int getCount() {return count;}
}
public class ThreadDemo {public static void main(String[] args) throws InterruptedException {Counter counter = new Counter();//创建两个线程 两个线程分别对这个counter 自增3w次Thread t1 = new Thread(()->{for(int i = 0; i < 300000; i++) {counter.add();}});Thread t2 = new Thread(()->{for(int i = 0; i < 300000; i++) {counter.add();}});t1.start();t2.start();//等待两个线程执行完成t1.join();t2.join();System.out.println(counter.getCount());}
}
多次运行结果如下:
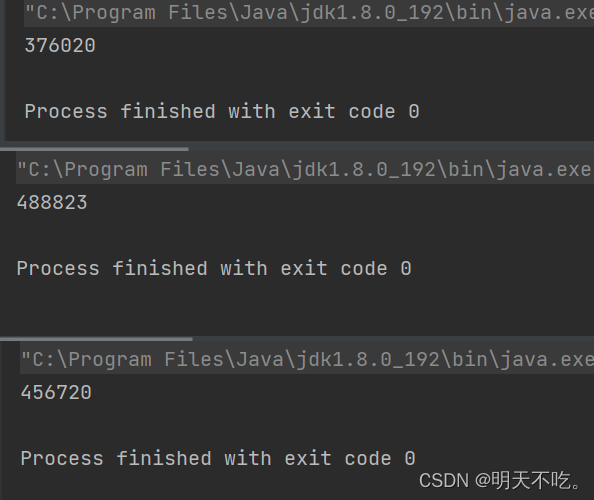
通过上面程序,两个线程针对同一个变量各自自增3w次,运行结果可以看到,预期结果为6w,实际结果却像是一个随机值,每次运行程序后的结果不一样
实际结果和预期结果不相符,这就是bug!由多线程引起的bug,即线程不安全/线程安全问题
为什么会出现这个情况呢?下面进行具体的分析:
与线程的随机调度密切相关~
【具体分析】
count++的操作 本质上是由三个CPU指令构成,如下:
1)load 把内存中的数据读取到CPU寄存器中
2)add 把寄存器中的值,进行+1运算
3)save 把寄存器中的值写回到内存中
由于多线程调度顺序是不确定的,实际执行的过程中,t1 和 t2 这两个线程的 ++ 操作实际的指令排列顺序就会有很多个可能,通过下面指令排序示意图,我们来具体感受一下:
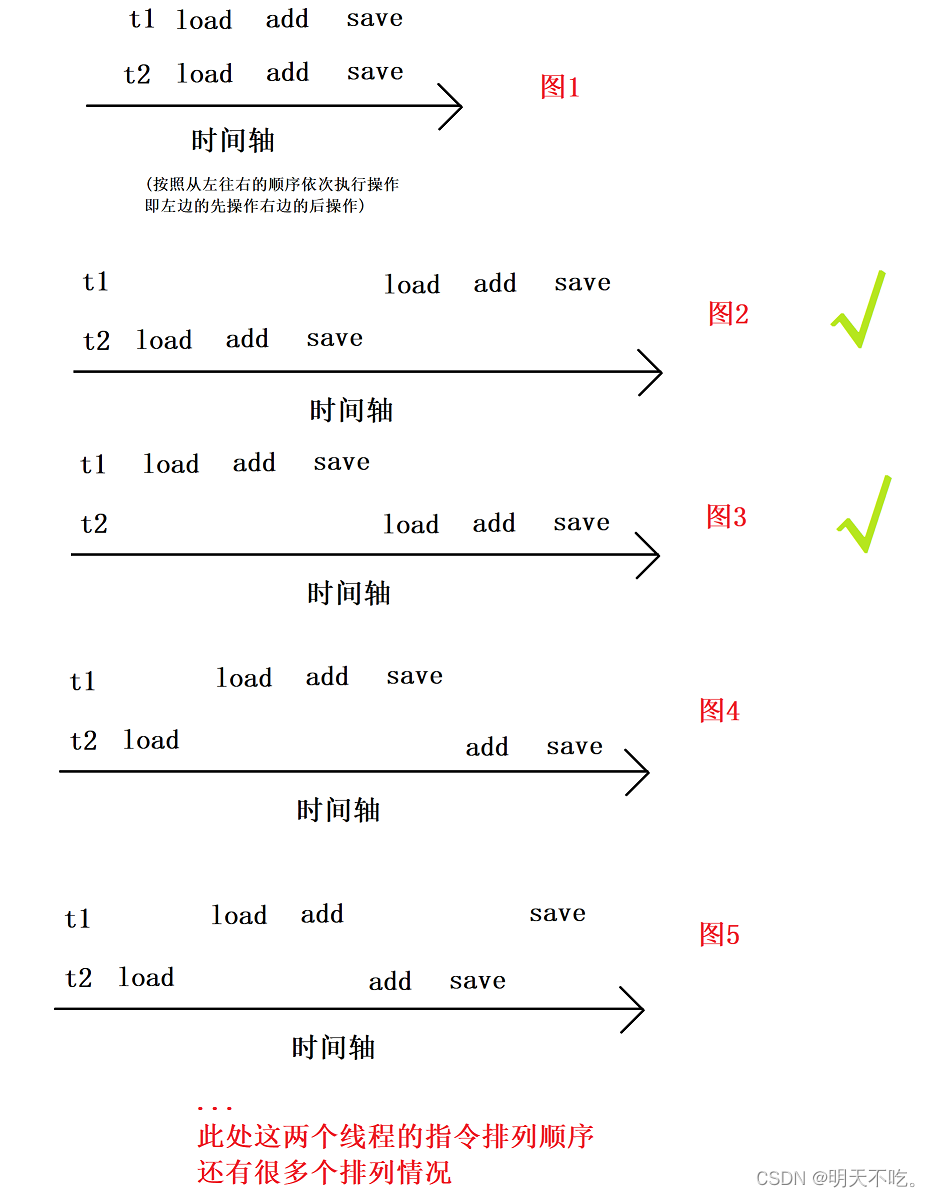
【补充说明】
t1 和 t2 是两个线程,肯定是运行在不同的CPU的核心上,也可能是运行在同一个CPU核心上(分时复用,并发)
这两种情况的最终效果一致,下面拿简单的在不同CPU核心上运行的情况为例进行演示,分析具体:
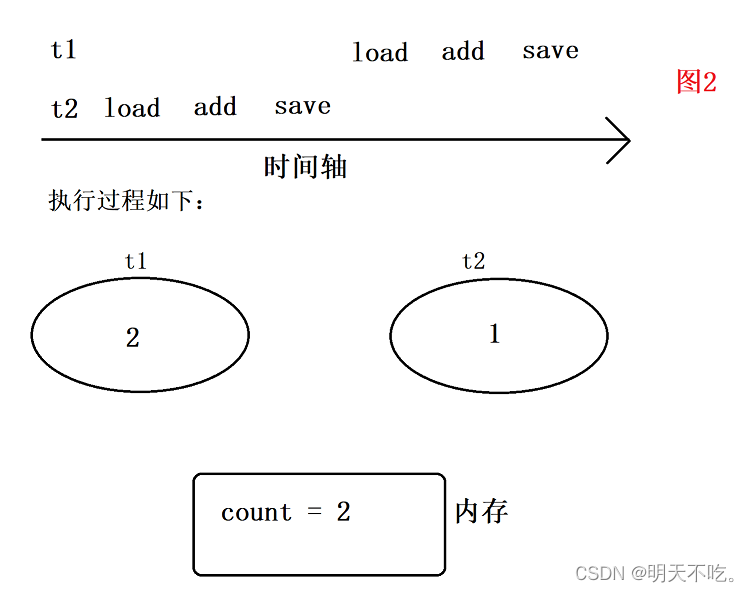
同理分析图3,可以得到:
其中图2、3指令的排列情况,此时看到两个线程各自自增1次,最终结果为2,循环3w次,可保证结果为6w,此时是没有bug的,结果正确!!!但是线程调度是无序的,上述代码我们并不知道是按照哪种情况来的,两个线程自增的过程中,到底经历了什么,我们并不清楚“顺序执行”与“交错执行”的次数,再来看看其它情况:
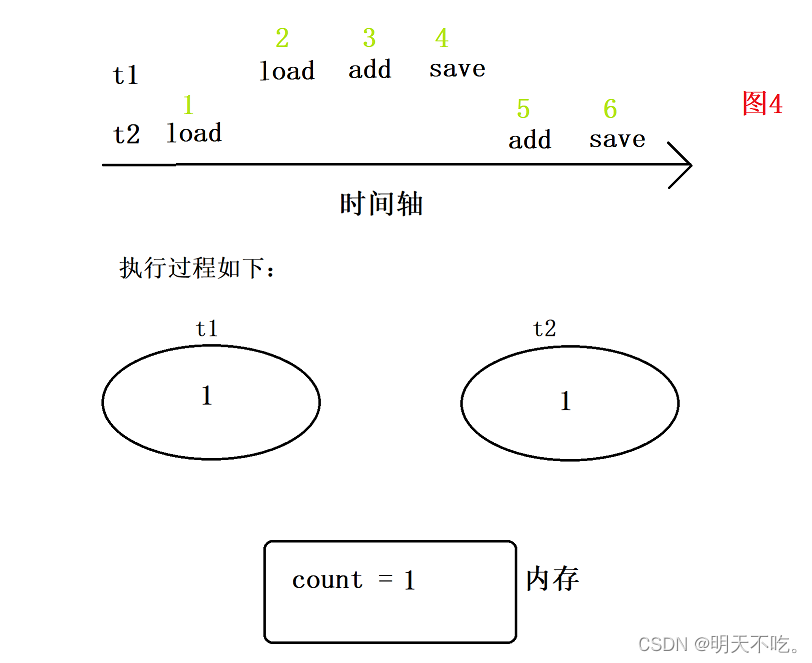
1.t2线程load,将内存的数据0读取到CPU寄存器中
2.t1线程load,将内存的数据0读取到CPU寄存器中
3.t1线程add,将寄存器中的值进行+1,为1
4.t1线程save,将寄存器中的值1写回到内存中,内存中为1
5.t2线程add,将寄存器中的值进行+1,为1
6.t2线程save,将寄存器中的值1写回到内存中,覆盖掉之前的内存值1,但内存值目前仍然为1,出现bug
此时发现,按照上述执行过程,两个线程自增两次,最后结果为1,说明bug出现了,其中一次自增的结果,被另一个给覆盖了所以出现这种情况,出现bug后,得到的结果一定是 <= 6w
【思考】但结果一定是 >= 3w吗???
答案:不是,实际上,结果可以是小于3w的,只是概率更低了
比如这种情况,如图所示:

t1自增1次,t2自增2次,最后结果还是1,两次无效自增,当然t2也可能让t1出现更多次的无效自增,此时完全可以实现结果小于3w,只不过是概率问题
【总结】
线程安全问题归根结底是因为线程的无序调度,导致了执行顺序的不确定,结果就发生了变化
下面具体细分线程不安全的原因,一起来看看~
2. 线程不安全的原因
2.1 抢占式执行
抢占式执行是根本原因!!!线程在系统中的调度是随机的!!!
2.2 修改共享数据
多个线程修改同一个变量,是线程不安全的!!!以下几种情况线程安全:
一个线程修改同一个变量——> 安全
多个线程读取同一个变量——> 安全
多个线程修改不同的变量——> 安全
在上述线程不安全的代码中,涉及到多个线程对同一个变量 counter.count 变量进行修改,即 counter.count 变量是一个线程都能够访问的共享数据
这个原因很好理解,如果多个线程修改同一个变量,由于抢占式执行,这个线程修改完,又被另一个线程修改完的数据给覆盖,就会导致线程不安全问题
2.3 修改操作不是原子的
【原子性】不可分割的最小单位
注意:一条 java 语句不一定是原子的,也不一定只是一条指令
比如上述代码中 counter.count变量的 ++ 的操作里,其实是有三个操作组成,即对应三条指令:
1)从内存中把数据读到CPU
2)把寄存器中的值,进行+1运算
3)把寄存器中的值写回到内存中
其中的某个操作,对应单个的CPU指令,即原子的,如果这个操作对应多个CPU指令,大概率就不具有原子性啦
【补充】如果直接使用 = 赋值,就是一个原子的操作
【不保证原子性会给多线程带来什么问题呢?】
如果一个线程正在对一个变量操作,在操作过程中其他线程插入进来了,如果这个操作被打断了,结果可能就是错误的!!!即正是因为不是原子的,导致这两个线程的指令排列存在很多种可能(与线程的抢占式调度密切相关,如果线程不是"抢占"的,就算这个操作不是原子的,那也是没有什么问题的)
上述三个场景均是当前代码 counter.count++ 线程不安全原因,另外还有几种场景会引起线程不安全问题,和当前的栗子count++ 无关,场景如下:
2.4 内存可见性
【含义】可见性指的是一个线程对共享变量值的修改,能够及时被其它线程看到
通俗的说,所谓内存可见性,就是在多线程环境下,编译器对于代码的优化,产生了误判,从而引起bug,进一步导致代码的bug
【Java内存模型(JMM)】Java虚拟机规范了Java内存模型
【目的】屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的并发效果
下面的这一套的说法,称为JMM,其概念来自于 jvm 规范文档,相当于是官方给出的这套说法在描述内存可见性,会涉及到主内存、工作内存这两个词,下面具体来介绍介绍这两个概念~
特别介绍 “工作内存"和"主内存”
内存可见性问题,举个栗子,如下:
t1 线程频繁读取主内存,效率是十分低的,就被优化成直接读自己的工作内存
t2 线程修改主内存的结果,由于 t1 没有读主内存,仍然读的是自己工作内存,修改不能被识别到,导致出现bug
(通俗一点讲就是,t1 需要经常读取内存,一直是一个值,很聪明,直接优化读自己的工作内存,但是 t2 修改了主内存,t1 仍然在读工作内存,则会出错)
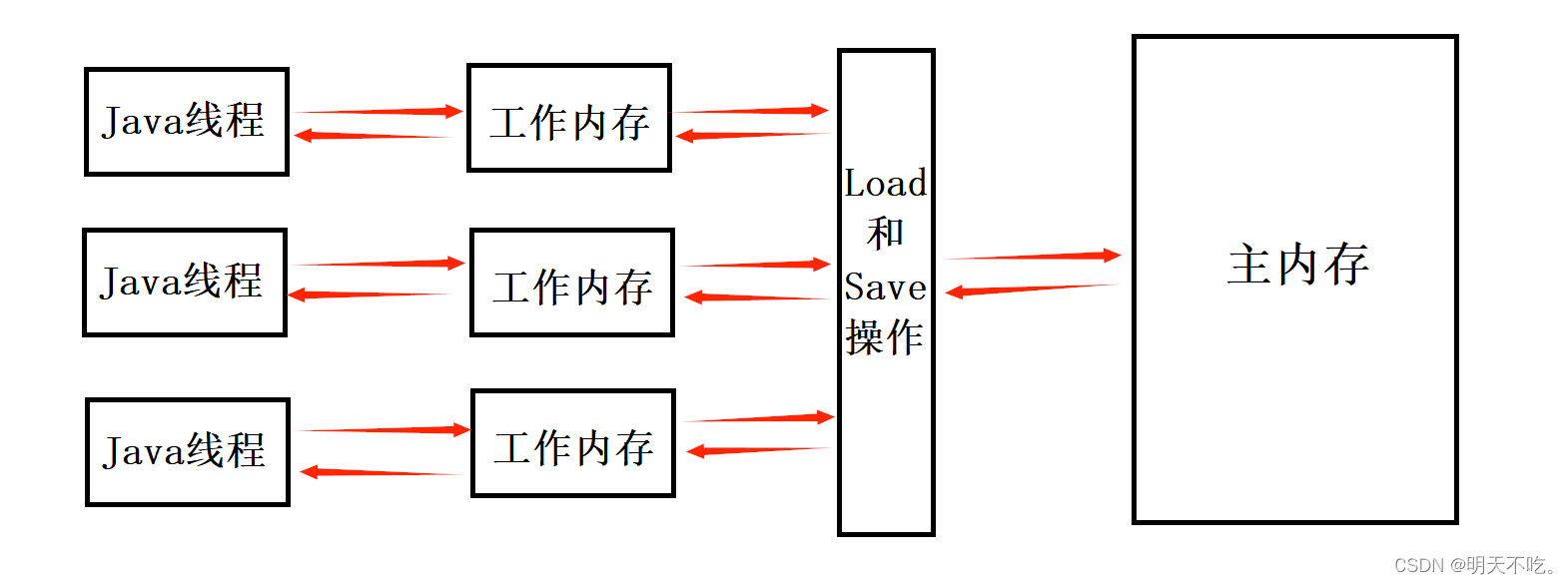
这里和我们平时所了解的不太一样,所以在这里特别说明
【工作内存】CPU寄存器和缓存
【主内存】才是我们平时所说的内存条,真正的内存
【为什么会不一致呢】
其实是因为,这两个词语翻译自英文
工作内存 —— work memory
主内存—— main memory
事实上,memory 这个英文单词并不一定就特指内存条,它其实也可以翻译成"存储区",单纯地表示"一个用来存储的空间"而已,在翻译过来的时候,仍将 memory 翻译成"内存",work memory 就被翻译为"工作内存"
这样就会让我们误会:内存条还分为不同的种类吗?根据功能分为"工作内存"和"主内存"吗?
其实并不是的!!!实际上所说的"工作内存",应理解为"工作存储区"更为合适,它是CPU寄存器和缓存,与内存条无关的!!!
【为什么 Java 官方用work memory 描述呢】
主要是因为,Java是跨平台的意味着它必须满足如下条件:
1)兼容多种操作系统
2)兼容多种硬件设备,尤其是 CPU!!! 而不同的硬件之间,CPU会有比较大的差异
比如,以前的CPU上只有寄存器,但是现在的CPU上除了寄存器,还有缓存,随着时代的发展,有的CPU还有好几个缓存,目前常见的是三级缓存:L1、L2、L3,如下:

这样一来,Java官方文档要指CPU内部的存储空间,如果只提到"CPU寄存器",那就十分不严谨,因为还有各种缓存,如果使用"CPU寄存器和缓存"描述,名字又过长过于麻烦,因此,官方直接发明了一个新的术语:work memory 来代表CPU寄存器和缓存,即CPU内部的存储空间
【为什么要这么麻烦拷来拷去】
因为 CPU 访问自身寄存器的速度以及高速缓存的速度,远远超过访问内存的速度(快3 - 4个数量级, 即快几千倍, 上万倍)
比如在某个代码中要连续 1000 次读取某个变量的值,如果 1000 次都从内存读,速度很慢,但是如果
只是第一次从内存读,读到的结果缓存到 CPU 的某个寄存器中,那么后 999 次读数据就不必直接访问
内存了,效率就会大大提高!!!
【补充说明】
缓存的读取速度介于寄存器和内存之间,其中三级缓存中,L1 最快,仍比寄存器慢,但空间最小,L3 最慢,但也比内存快很多,空间最大
在这里特别说明一下
快和慢都是相对的,CPU 访问寄存器速度远远快于内存, 但是内存的访问速度又远远快于硬盘,对应的,CPU 的价格最贵,内存次之,硬盘最便宜
访问速度:CPU >> 内存 >> 硬盘
价格:CPU >> 内存 >> 硬盘
2.5 代码顺序性
【含义】代码的顺序性,即指令重排序~具体是什么呢?下面通过一个例子来进行解释:
1)去菜鸟驿站取杯子快递
2)回宿舍玩耍
3)去菜鸟驿站取本子快递
如果是在单线程的情况下,JVM、CPU指令集合会对其进行优化,比如按照 1->3->2的方式执行,是没有任何问题的,这样执行的方式还少跑一趟,直接一起取了,这种即为指令重排序
编译器对于指令重排序的前提是"保持逻辑不发生变化",这点在单线程的环境下比较容易判断,但是在多线程环境中,较为复杂,就不那么容易判断了,多线程的代码执行的复杂程度更高,编译器很难再编译阶段对代码的执行效果进行预测,因此重排序很容易导致优化前后的不等价,这就会出现问题
【特别说明】重排序是一个很复杂的话题,涉及到CPU以及编译器的一些底层工作管理,此处不作太多补充
💛💛💛本期内容回顾💛💛💛
 ✨✨✨本期内容到此结束啦~下期内容将介绍如何解决线程安全问题(期待ing)
✨✨✨本期内容到此结束啦~下期内容将介绍如何解决线程安全问题(期待ing)