期末模拟题库
一、单项选择题
1、下列关于Python语言的特点的说法中,错误的是()
-
A Python 语言是非开源语言
-
B Python 语言是面向对象的
-
C Python 语言是跨平台的语言
-
D Python 语言是免费的
【答案】A
【解析】暂无解析
2、Python源代码文件的后缀名是()
-
A pdf
-
B png
-
C py
-
D doc
【答案】C
【解析】暂无解析
3、用于在IDLE交互环境中执行Python命令的是
-
A execute
-
B do
-
C run
-
D 按enter键
【答案】D
【解析】暂无解析
4、在Pyhton函数中,用于获取用户输入的是( )
-
A get( )
-
B print( )
-
C input( )
-
D eval( )
【答案】C
【解析】暂无解析
5、给标识符关联名字的过程是( )
-
A 赋值语句
-
B 命名
-
C 表达
-
D 生成语句
【答案】B
【解析】暂无解析
6、哪个选项不能正确引用turtle库进而使用setup()函数。
-
A import setup from turtle
-
B from turtle import *
-
C import turtle as t
-
D import turtle
【答案】A
【解析】暂无解析
7、关于turtle库,哪个选项的描述是错误的?
-
A turtle库最早成功应用于LOGO编程语言
-
B turtle绘图体系以水平右侧为绝对方位的0度
-
C turtle坐标系的原点默认在屏幕左上角
-
D turtle库是一个直观有趣的图形绘制函数库
【答案】C
【解析】暂无解析
8、下面代码的执行结果,哪个选项的描述是错误的? turtle.setup(650,350,200,200)
-
A 窗体左侧与屏幕左侧的距离是200像素
-
B 窗体中心在屏幕中的坐标值是(200,200)
-
C 建立一个长为650,高为350像素的窗体
-
D 窗体顶部与屏幕顶部的距离是200像素
【答案】B
【解析】暂无解析
9、哪个选项是turtle绘图中角度坐标系的绝对0度方向
-
A 画布正右方
-
B 画布正左方
-
C 画布正下方
-
D 画布正上方
【答案】A
【解析】暂无解析
10、哪个选项是下面代码的执行结果? turtle.circle(-90,90)
-
A 绘制一个半径为90像素的圆形
-
B 绘制一个半径为90像素的弧形,圆心在画布正中心
-
C 绘制一个半径为90像素的弧形,圆心在小乌龟当前行进的右侧
-
D 绘制一个半径为90像素的弧形,圆心在小乌龟当前行进的左侧
【答案】C
【解析】暂无解析
11、关于turtle的画笔控制函数,哪个选项的描述是错误的?
-
A turtle.width()和turtle.pensize()都可以设置画笔的尺寸
-
B turtle.colormode()作用是设置画笔RGB颜色的表示模式
-
C turtle.pendown()作用是落下笔画,并移动画笔绘制一个点
-
D turtle.penup()的别名有turtle.pu()、turtle.up()
【答案】C
【解析】暂无解析
12、哪个选项是修改turtle画笔颜色的函数?
-
A pensize()
-
B colormode()
-
C pencolor()
-
D seth()
【答案】C
【解析】暂无解析
13、那个选项不能改变turtle的画笔方向?
-
A left()
-
B bk()
-
C seth()
-
D right()
【答案】B
【解析】暂无解析
14、哪个项能够让画笔在移动中不绘制图形?
-
A pendown()
-
B penup()
-
C circle()
-
D fd()
【答案】B
【解析】暂无解析
15、哪个选项能够使用turtle库绘制一个半圆形?
-
A turtle.circle(100)
-
B turtle.circle(100,180)
-
C turtle.fd(100)
-
D turtle.bk(-100)
【答案】B
【解析】暂无解析
16、以下选项中,不是 Python 语言保留字的是:
-
A do
-
B except
-
C while
-
D pass
【答案】A
【解析】暂无解析
17、关于 Python 程序格式框架,以下选项中描述错误的是:
-
A 判断、循环、函数等语法形式能够通过缩进包含一批 Python 代码,进而表达对应的语义
-
B Python 语言不采用严格的“缩进”来表明程序的格式框架
-
C Python 单层缩进代码属于之前最邻近的一行非缩进代码,多层缩进代码根据缩进关系决定所属范围
-
D Python 语言的缩进可以采用 Tab 键实现
【答案】B
【解析】暂无解析
18、下列选项中不符合Python语言变量命名规则的是
-
A TempStr
-
B _AI
-
C I
-
D 3_1
【答案】D
【解析】暂无解析
19、以下选项中,关于Python字符串的描述错误的是
-
A 字符串是字符的序列,可以按照单个字符或者字符片段进行索引
-
B 字符串包括两种序号体系:正向递增和反向递减
-
C Python字符串提供区间访问方式,采用[N:M]格式,表示字符串中从N到M的索引子字符串(包含N和M)
-
D Python语言中,字符串是用一对双引号""或者一对单引号 ‘’ 括起来的零个或者多个字符
【答案】C
【解析】暂无解析
20、关于Python语言的特点,以下选项中描述错误的是
-
A Python语言是非开源语言
-
B Python语言是跨平台语言
-
C Python语言是脚本语言
-
D Python语言是多模型语言
【答案】A
【解析】暂无解析
21、关于Python的数字类型,以下选项中描述错误的是
-
A 1.0是浮点数,不是整数
-
B 浮点数也有十进制、二进制、八进制和十六进制等表示方式
-
C 整数类型的数值一定不会出现小数点
-
D 复数类型虚部为0时,表示为1+0j
【答案】B
【解析】暂无解析
22、下面代码的输出结果是
x = 50.01
print(type(x))
-
A <class ‘int’>
-
B <class ‘complex’>
-
C <class ‘float’>
-
D <class ‘bool’>
【答案】C
【解析】暂无解析
23、关于Python字符串,以下选项中描述错误的是
-
A 可以使用datatype()测试字符串的类型
-
B 输出带有引号的字符串,可以使用转义字符\
-
C 字符串可以保存在变量中,也可以单独存在
-
D 字符串是一个字符序列,字符串中的编号叫“索引”
【答案】A
【解析】暂无解析
24、下面代码的输出结果是
x=3.1415926
print(round(x, 2), round(x))
-
A 2 2
-
B 6.28 3
-
C 3 3.14
-
D 3.14 3
【答案】D
【解析】暂无解析
25、关于Python字符编码,以下选项中描述错误的是
-
A Python可以处理任何字符编码文本
-
B ord(x)和chr(x)是一对函数
-
C chr(x)将字符转换为Unicode编码
-
D Python默认采用Unicode字符编码
【答案】C
【解析】暂无解析
26、关于Python的分支结构,以下选项中描述错误的是
-
A 分支结构使用if保留字
-
B Python中if-else语句用来形成二分支结构
-
C Python中if-elif-else语句描述多分支结构
-
D 分支结构可以向已经执行过的语句部分跳转
【答案】D
【解析】暂无解析
27、关于Python循环结构,以下选项中描述错误的是
-
A 遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等
-
B break用来跳出最内层for或者while循环,脱离该循环后程序从循环代码后继续执行
-
C 每个continue语句只有能力跳出当前层次的循环
-
D Python通过for、while等保留字提供遍历循环和无限循环结构
【答案】C
【解析】暂无解析
28、下面代码的输出结果是
for s in "HelloWorld":if s = = "W":continueprint(s, end="")
-
A Hello
-
B World
-
C HelloWorld
-
D Helloorld
【答案】D
【解析】暂无解析
29、关于Python的无限循环,以下选项中描述错误的是
-
A 无限循环通过while保留字构建
-
B 无限循环一直保持循环操作,直到循环条件不满足才结束
-
C 无限循环也称为条件循环
-
D 无限循环需要提前确定循环次数
【答案】D
【解析】暂无解析
30、下列快捷键中能够中断(Interrupt Execution)Python程序运行的是
-
A F6
-
B Ctrl + C
-
C Ctrl + F6
-
D Ctrl + Q
【答案】B
【解析】暂无解析
31、给出下面代码:
age=23
start=2
if age%2!=0:start=1
for x in range(start,age+2,2):print(x)
上述程序输出值的个数是
-
A 16
-
B 10
-
C 12
-
D 14
【答案】C
【解析】暂无解析
32、字典d={‘abc’:123, ‘def’:456, ‘ghi’:789},len(d)的结果是
-
A 3
-
B 6
-
C 12
-
D 9
【答案】A
【解析】暂无解析
33、关于Python的元组类型,以下选项中描述错误的是
-
A 元组中元素不可以是不同类型
-
B Python中元组采用逗号和圆括号(可选)来表示
-
C 一个元组可以作为另一个元组的元素,可以采用多级索引获取信息
-
D 元组一旦创建就不能被修改
【答案】A
【解析】暂无解析
34、S和T是两个集合,对S&T的描述正确的是
-
A S和T的补运算,包括集合S和T中的非相同元素
-
B S和T的差运算,包括在集合S但不在T中的元素
-
C S和T的交运算,包括同时在集合S和T中的元素
-
D S和T的并运算,包括在集合S和T中的所有元素
【答案】C
【解析】暂无解析
35、设序列s,以下选项中对max(s)的描述正确的是
-
A 一定能够返回序列s的最大元素
-
B 返回序列s的最大元素,但要求s中元素之间可比较
-
C 返回序列s的最大元素,如果有多个相同,则返回一个列表类型
-
D 返回序列s的最大元素,如果有多个相同,则返回一个元组类型
【答案】B
【解析】暂无解析
36、给定字典d,以下选项中对d.get(x, y)的描述正确的是
-
A 返回字典d中键为x的值,如果不存在,则返回y
-
B 返回字典d中键为y的值,如果不存在,则返回y
-
C 返回字典d中值为y的值,如果不存在,则返回x
-
D 返回字典d中键值对为x:y的值
【答案】A
【解析】暂无解析
37、下面代码的输出结果是
vlist=list(range(1,5))
for e in vlist:print(e,end=',')
-
A [1, 2, 3, 4]
-
B 1,2,3,4,
-
C 1 2 3 4 5
-
D 0;1;2;3;4;
【答案】B
【解析】暂无解析
38、对于递归函数的描述,以下选项中正确的是
-
A 函数比较复杂
-
B 函数内部包含对本函数的再次调用
-
C 函数名称作为返回值
-
D 包含一个循环结构
【答案】B
【解析】暂无解析
39、以下选项中,不属于函数的作用的是
-
A 提高代码执行速度
-
B 降低编程复杂度
-
C 增强代码可读性
-
D 复用代码
【答案】A
【解析】暂无解析
40、下面代码的输出结果是
>>>f=lambda x,y:y+x
>>>f(10,10)
-
A 10
-
B 10,10
-
C 100
-
D 20
【答案】D
【解析】暂无解析
41、关于形参和实参的描述,以下选项中正确的是
-
A 调用函数时,参数列表中给出要传入函数内部的参数,这类参数称为形参
-
B 函数定义中参数列表里面的参数是实际参数,简称实参
-
C 程序在调用时,将实参复制给函数的形参
-
D 程序在调用时,将形参复制给函数的实参
【答案】C
【解析】暂无解析
42、以下选项中,对于函数的定义错误的是
-
A def vfunc(a,*b):
-
B def vfunc(a,b=2):
-
C def vfunc(*a,b):
-
D def vfunc(a,b):
【答案】C
【解析】暂无解析
43、给出以下代码:
1s ["car","truck"]
def func(a):1s.append(a)return
func("bus")
print(ls)
以下选项中描述错误的是
-
A funC(a)中的a为非可选参数
-
B 执行代码输出结果为[‘car’, ‘truck’]
-
C ls.append(a) 代码中的ls是全局变量
-
D ls.append(a) 代码中的ls是列表类型
【答案】B
【解析】暂无解析
44、以下选项中,不是Python对文件的读操作方法的是
-
A readtext
-
B readline
-
C read
-
D readlines
【答案】A
【解析】暂无解析
45、以下选项中,不是Python对文件的打开模式的是
-
A ‘c’
-
B ‘r’
-
C ‘+’
-
D ‘w’
【答案】A
【解析】暂无解析
46、给出如下代码:
fname=input("请输入要打开的文件:")
fi open(fname,"r")
for line in fi.readlines():print(line)
fi.close()
以下选项中描述错误的是
-
A 用户输入文件路径,以文本文件方式读入文件内容并逐行打印
-
B 通过fi.readlines()方法将文件的全部内容读入一个列表fi
-
C 上述代码中fi.readlines()可以优化为fi
-
D 通过fi.readlines()方法将文件的全部内容读入一个字典fi
【答案】D
【解析】暂无解析
47、对于CSV文件的描述,以下选项中错误的是
-
A CSV文件格式是一种通用的、相对简单的文件格式,应用于程序之间转移表格数据
-
B 整个CSV文件是一个二维数据
-
C CSV文件的每一行是一维数据,可以使用Python中的列表类型表示
-
D CSV文件通过多种编码表示字符
【答案】D
【解析】暂无解析
48、表达式",".join(ls)中ls是列表类型,以下选项中对其功能的描述正确的是
-
A 将列表所有元素连接成一个字符串,元素之间增加一个逗号
-
B 将逗号字符串增加到列表ls中
-
C 将列表所有元素连接成一个字符串,每个元素后增加一个逗号
-
D 在列表ls每个元素后增加一个逗号
【答案】A
【解析】暂无解析
49、关于turtle库的画笔控制函数,以下选项中描述错误的是
-
A turtle.penup()的别名有turtle.pu(),turtle.up()
-
B turtle.pendown()的作用是落下画笔之后,移动画笔将绘制形状
-
C turtle.colormode()的作用是给画笔设置颜色模式
-
D turtle.width()和turtle.pensize()不是用来设置画笔尺寸
【答案】D
【解析】暂无解析
50、执行如下代码:
import turtle as t
for i in range(1, 5):t.fd(50)t.left(90)
在Python Turtle Graphics中,绘制的是
-
A 五角星
-
B 正方形
-
C 三角形
-
D 五边形
【答案】B
【解析】暂无解析
51、random库的random.randrange(start, stop[, step])函数的作用是
-
A 生成一个[start, stop)之间的随机小数
-
B 生成一个[start, stop)之间以step为步数的随机整数
-
C 将序列类型中元素随机排列,返回打乱后的序列
-
D 从序列类型(例如列表)中随机返回一个元素
【答案】B
【解析】暂无解析
52、下列函数中,不是基本的Python内置函数是
-
A perf_counter()
-
B all()
-
C any()
-
D abs()
【答案】A
【解析】暂无解析
53、基本的Python内置函数type(x)的作用是
-
A 对组合数据类型x进行排序,默认从小到大
-
B 对组合数据类型x计算求和结果
-
C 将x转换为等值的字符串类型
-
D 返回变量x的数据类型
【答案】D
【解析】暂无解析
54、列出当前系统已经安装的第三方库的命令格式是
-
A pip download <拟下载库名>
-
B pip list
-
C pip install <拟安装库名>
-
D pip -h
【答案】B
【解析】暂无解析
55、将Python脚本程序转变为可执行程序的第三方库是
-
A PyInstaller
-
B random
-
C pygame
-
D PyQt5
【答案】A
【解析】暂无解析
56、关于Python语言的注释,以下选项中描述错误的是
-
A Python语言的单行注释以单引号 ’ 开头
-
B Python语言的单行注释以#开头
-
C Python语言的多行注释以’‘’(三个单引号)开头和结尾
-
D Python语言有两种注释方式:单行注释和多行注释
【答案】A
【解析】暂无解析
57、关于Python注释,以下选项中描述错误的是
-
A 注释可用于标明作者和版权信息
-
B 注释可以辅助程序调试
-
C Python注释语句不被解释器过滤掉,也不被执行
-
D 注释用于解释代码原理或者用途
【答案】C
【解析】暂无解析
58、下面代码的输出结果是
str1 ="mysql sqlserver PostgresQL"
str2 = "sql"
ncount = str1.count(str2)
print(ncount)
-
A 4
-
B 3
-
C 5
-
D 2
【答案】D
【解析】暂无解析
59、下面代码的执行结果是
a = 123456789
b ="*"
print("{0:{2}>{1},}\n{0:{2}^{1},}\n{0:{2}<{1},}".format(a, 20, b))
-
A
****123,456,789***** *********123,456,789 123,456,789********* -
B
****123,456,789*****123,456,789********* *********123,456,789 -
C
*********123,456,789****123,456,789*****123,456,789********* -
D
*********123,456,789 123,456,789********* ****123,456,789*****
【答案】C
【解析】暂无解析
60、用来判断当前Python语句在分支结构中的是
-
A 引号
-
B 缩进
-
C 大括号
-
D 冒号
【答案】B
【解析】暂无解析
61、以下选项中描述正确的是
-
A 条件35<=45<75是合法的,且输出为False
-
B 条件24<=28<25是合法的,且输出为False
-
C 条件24<=28<25是合法的,且输出为True
-
D 条件24<=28<25是不合法的
【答案】B
【解析】暂无解析
62、下面代码的输出结果是
sum = 1
for i in range(1, 101):sum += i
print(sum)
-
A 5049
-
B 5050
-
C 5052
-
D 5051
【答案】D
【解析】暂无解析
63、下面代码的输出结果是
x2 = 1
for day in range(4, 0, -1):x1 = (x2 + 1) * 2x2 = x1print(x1)
-
A 190
-
B 94
-
C 23
-
D 46
【答案】D
【解析】暂无解析
64、S和T是两个集合,对S|T的描述正确的是
-
A S和T的交运算,包括同时在集合S和T中的元素
-
B S和T的差运算,包括在集合S但不在T中的元素
-
C S和T的并运算,包括在集合S和T中的所有元素
-
D S和T的补运算,包括集合S和T中的非相同元素
【答案】C
【解析】暂无解析
65、以下选项中,不是具体的Python序列类型的是
-
A 列表类型
-
B 数组类型
-
C 元组类型
-
D 字符串类型
【答案】B
【解析】暂无解析
66、下面代码的输出结果是
s=["seashell","gold","pink","brown","purple","tomato"]
print([1:4:2])
-
A [‘gold’, ‘pink’, ‘brown’, ‘purple’, ‘tomato’]
-
B [‘gold’, ‘pink’, ‘brown’]
-
C [‘gold’, ‘brown’]
-
D [‘gold’, ‘pink’]
【答案】C
【解析】暂无解析
67、下面代码的输出结果是
s=["seashell","gold","pink","brown","purple","tomato"]
print(s[4:]
-
A [‘seashell’, ‘gold’, ‘pink’, ‘brown’]
-
B [‘gold’, ‘pink’, ‘brown’, ‘purple’, ‘tomato’]
-
C [‘purple’]
-
D [‘purple’, ‘tomato’]
【答案】D
【解析】暂无解析
68、关于递归函数基例的说明,以下选项中错误的是
-
A 递归函数必须有基例
-
B 递归函数的基例决定递归的深度
-
C 每个递归函数都只能有一个基例
-
D 递归函数的基例不再进行递归
【答案】C
【解析】暂无解析
69、在Python中,关于函数的描述,以下选项中正确的是.
-
A 一个函数中只允许有一条return语句
-
B Python中,def和return是函数必须使用的保留字
-
C 函数eval()可以用于数值表达式求值,例如eval(“2*3+1”)
-
D Python函数定义中没有对参数指定类型,这说明,参数在函数中可以当作任意类型使用
【答案】C
【解析】暂无解析
70、给出如下代码:
import turtle
def drawLine(draw):turtle.pendown() if draw elsel turtle.penup()turtle.fd(50)turtle.right(90)
drawLine(True)
drawLine(True)
drawLine(True)
drawLine(True)
以下选项中描述错误的是
-
A 代码drawLine(True)中True替换为–1,运行代码结果不变
-
B 运行代码,在Python Turtle Graphics 中,绘制一个正方形
-
C 代码def drawLine(draw)中的draw可取值True或者False
-
D 代码drawLine(True)中True替换为0,运行代码结果不变
【答案】D
【解析】暂无解析
71、给出如下代码:
import turtle
def drawLine(draw):turtle.pendown() if draw else turtle.penup()turtle.fd(50)turtle.right(90)
drawLine(True)
drawLine(0)
drawLine(True)
drawLine(True)
turtle.left(90)
drawLine(0)
drawLine(True
drawLine(True)
以下选项中描述错误的是:
-
A 代码drawLine(True)中True替换为–1,运行代码结果不变
-
B 运行代码,在Python Turtle Graphics 中,绘制一个数码管数字2
-
C 代码drawLine(True)中True替换为0,运行代码结果不变
-
D 代码def drawLine(draw)中的draw可取数值0、1、–1等
【答案】C
【解析】暂无解析
72、以下选项对应的方法可以用于从CSV文件中解析一二维数据的是
-
A join()
-
B exists()
-
C format()
-
D split()
【答案】D
【解析】暂无解析
73、以下选项对应的方法可以用于向CSV文件写入一二维数据的是
-
A split()
-
B strip()
-
C join()
-
D exists()
【答案】C
【解析】暂无解析
74、Wordcloud对象创建的常用参数mask的功能是
-
A 生成图片的宽度
-
B 指定字体文件的完整路径
-
C 词云形状
-
D 词云中最大词数
【答案】C
【解析】暂无解析
75、Wordcloud类的to_file方法的功能是
-
A to_file (filename)在filename路径下生成词云
-
B to_file (filename)生成词云的字体文件路径
-
C to_file (filename)将词云图保存为名为filename文件
-
D to_file (filename)生成词云的形状为filename
【答案】C
【解析】暂无解析
76、关于eval函数,以下选项中描述错误的是
-
A eval函数的作用是将输入的字符串转为Python语句,并执行该语句
-
B eval函数称为评估函数,可以去掉字符串最外侧的引号
-
C 执行“>>> eval(“Hello”)”和执行“>>> eval(“‘Hello’”)”得到相同的结果
-
D 如果用户希望输入一个数字,并用程序对这个数字进行计算,可以采用eval(input(<输入提示字符串>))组合
【答案】C
【解析】暂无解析
77、下列选项中可以获取Python整数类型帮助的是
-
A >>> help(float)
-
B >>> dir(int)
-
C >>> dir(str)
-
D >>> help(int)
【答案】D
【解析】暂无解析
78、给出如下代码: >>> x = 3.14 >>> eval(‘x + 10’) 上述代码的输出结果是
-
A TypeError: must be str, not int
-
B 13.14
-
C 系统报错
-
D 3.1410
【答案】B
【解析】暂无解析
79、Python语言的主网站网址是
-
A https://www.python123.io/
-
B https://www.python.org/
-
C https://pypi.python.org/pypi
-
D https://www.python123.org/
【答案】B
【解析】暂无解析
80、利用print()格式化输出,能够控制浮点数的小数点后两位输出的是
-
A {:.2}
-
B {.2f}
-
C {:.2f}
-
D {.2}
【答案】C
【解析】暂无解析
81、以下选项中,不是Python语言保留字的是
-
A del
-
B None
-
C switch
-
D try
【答案】C
【解析】暂无解析
82、关于Python程序中与“缩进”有关的说法中,以下选项中正确的是
-
A 缩进可以用在任何语句之后,表示语句间的包含关系
-
B 缩进是非强制性的,仅为了提高代码可读性
-
C 缩进统一为4个空格
-
D 缩进在程序中长度统一且强制使用
【答案】D
【解析】暂无解析
83、IDLE菜单中将选中区域取消缩进的快捷键是
-
A Ctrl+O
-
B Ctrl+[
-
C Alt+C
-
D Ctrl+V
【答案】B
【解析】暂无解析
84、IDLE菜单中将选中区域注释的快捷键是
-
A Alt+G
-
B Alt+Z
-
C Alt+4
-
D Alt+3
【答案】D
【解析】暂无解析
85、以下选项中,不是Python IDE的是
-
A PyCharm
-
B Spyder
-
C R studio
-
D Jupyter Notebook
【答案】C
【解析】暂无解析
86、以下代码的输出结果是:
print("{1}:{0:.6f}".format(3.1415926,'π'))
-
A π:3.14159
-
B π:3.141593
-
C 3.141593:π
-
D 3.14159:π
【答案】B
【解析】暂无解析
二、判断正误题
1、 do 不是Python语言的保留字。
【答案】正确
【解析】暂无解析
2、在Python语言中,‘=’表示赋值,也可以表示条件运算中的等于判断。
【答案】错误
【解析】暂无解析
3、可以使用from turtle import setup 引入turtl库。
【答案】错误
【解析】暂无解析
4、
print(round(0.1+0.2,1)==0.3)
代码输出结果是True.
【答案】正确
【解析】暂无解析
5、python的浮点数有两种表示方法:十进制表示和科学计数法。
【答案】正确
【解析】暂无解析
6、 下面代码的输出是1024。
x=0x1010
print(x)
【答案】错误
【解析】暂无解析
7、Pythoni通过解释器内置的open()函数打开一个文件
【答案】正确
【解析】暂无解析
8、‘bw’ 是pythoi文件打开的合法模式组合,表示文件以文本形式可写方式打开。
【答案】错误
【解析】暂无解析
9、一个元组可以作为另一个元组的元素,也可以采用多级索引获取信息。
【答案】正确
【解析】暂无解析
10、字典中对某个值的修改可以通过中括号加键的方式赋值实现。
【答案】正确
【解析】暂无解析
11、pythoni语句:f=open(,其中是文件句柄,用在程序中表达文件。
【答案】正确
【解析】暂无解析
12、如果s是一个序列,x不是s的元素,x not in s返回True.
【答案】正确
【解析】暂无解析
13、python使用del保留字定义一个函数,函数是一段具有特定功能、可重用的语句组
【答案】错误
【解析】暂无解析
14、组合数据类型分为3类:序列类型、集合类型和映射类型,其中字符串类型属于映射类型。
【答案】错误
【解析】暂无解析
15、中文和英文分词都可以用第三方库jieba分词库。
【答案】错误
【解析】暂无解析
16、Python中的分支结构可以向已经执行过的语句部分跳转
【答案】错误
【解析】暂无解析
17、Python的遍历循环中的遍历结构可以是字符串、文件、组合数据类型和range()函数等
【答案】正确
【解析】暂无解析
三、程序设计题
1、请利用模运算的方法,利用已知日期的星期数,求解别的日期的星期数
类型:数字类型的操做,取余运算的运用
描述
如果9月5日是星期二,请编写代码推导出输入日期的星期数
提示:请从已知的日和星期数的关系,推出该年星期映射规律的字符串,然后结合课本的微实例完成该实验。通过日数5,5%7=5,得到字符串的第五个位置是关于星期五的信息,星期映射为:
‘四五六七一二三’,由此可以推断出该年任意一天的星期数。
输入
请输入一个日期整数
输出
按格式输出,参照示例。
示例
输入
23输出
23日是星期六
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入一个日期整数dateNum = eval(input())# 星期表sunday_table = '四五六七一二三'# 通过日数5,5%7=5,判断dateNumif dateNum % 7 == 0:print('{}日是星期{}'.format(dateNum, sunday_table[0]))elif dateNum % 7 == 1:print('{}日是星期{}'.format(dateNum, sunday_table[1]))elif dateNum % 7 == 2:print('{}日是星期{}'.format(dateNum, sunday_table[2]))elif dateNum % 7 == 3:print('{}日是星期{}'.format(dateNum, sunday_table[3]))elif dateNum % 7 == 4:print('{}日是星期{}'.format(dateNum, sunday_table[4]))elif dateNum % 7 == 5:print('{}日是星期{}'.format(dateNum, sunday_table[5]))else:print('{}日是星期{}'.format(dateNum, sunday_table[6]))
2、关于字符串格式化输出
类型:分支结构、字符串格式化
描述
获得用户的输入当作对齐参数,用户输入:左、右、中,分别表示:左对齐、右对齐和居中对齐,以*作为填充符号,30字符宽度输出PYTHON字符串。
输入
输入汉字“左”、“右”或“中”
输出
根据汉字,对“PYTHON”字符串进行对应的对齐和填充输出。
示例
输入
中输出
************PYTHON************
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的对齐方式alignment = input()# 定义待格式化的字符串text = "PYTHON"# 设置总宽度为30个字符width = 30# 定义填充字符为*fill_char = '*'# 根据用户输入的对齐方式进行相应处理if alignment in '左':# 左对齐,右侧用*填充formatted_string = text.ljust(width, fill_char)elif alignment in '右':# 右对齐,左侧用*填充formatted_string = text.rjust(width, fill_char)elif alignment in '中':# 居中对齐,两侧用*填充formatted_string = text.center(width, fill_char)# 输出格式化后的字符串print(formatted_string)
3、凯撒密码解密
类型:字符串、简单循环
描述
利用凯撒秘密的加密算法,设计一个解密程序,得到明文信息
凯撒密码(加密):它采用了替换方法对信息中的每一个英文字符循环替换为字母表序列中该字符后面第三个字符,对应关系如下:
原文:ABCDEFGHIJKLMNOPQRSTUVWXYZ
密文:DEFGHIJKLMNOPQRSTUVWXYZABC
解密算法正好相反:它采用了替换方法对信息中的每一个英文字符循环替换为字母表序列中该字符前面的第三个字符,对应关系如下:
密文:DEFGHIJKLMNOPQRSTUVWXYZABC
明文:ABCDEFGHIJKLMNOPQRSTUVWXYZ
要求用户输入一串密文,利用程序打印出明文,注意判断密文中除了以上字符处理外,其它字符不做处理。
输入
请输入一个字符串
输出
该字符串对应的明文
示例
输入
SBWKRQ LV DQ HAFHOOHQW ODQJXDJH.输出
PYTHON IS AN EXCELLENT LANGUAGE.
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的密文ciphertext = input()# 定义解密后的明文字符串plaintext = ""# 遍历密文中的每个字符for char in ciphertext:if 'A' <= char <= 'Z':# 对于大写字母,进行解密# 计算字符前移3位后的字符new_char = chr((ord(char) - ord('A') - 3) % 26 + ord('A'))plaintext += new_charelif 'a' <= char <= 'z':# 对于小写字母,进行解密# 计算字符前移3位后的字符new_char = chr((ord(char) - ord('a') - 3) % 26 + ord('a'))else:# 非字母字符不做处理,直接添加到明文中plaintext += char# 输出明文print(plaintext)
4、判断是否为闰年
类型:分支
描述
输入一个4位整数,判断其是否为闰年(能被4整除,但不能被100整除,或者能被400整除的年份为闰年)
输入
输入一个4位整数
输出
判断年份是否为闰年的结论
示例
(点击编辑器左上角{;}按钮编辑代码框)
输入
2004输出
2004年是闰年
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入导入年份year = int(input())# 判断year是否为闰年,根据题目(能被4整除,但不能被100整除,或者能被400整除的年份为闰年)if (year % 4 == 0 and year % 100 != 0) or year % 400 == 0:print('{}年是闰年'.format(year))else:print('{}年不是闰年'.format(year))
5、鸡兔同笼
类型:双重循环
描述
假设笼中鸡和兔的脚总数为80,编写一个程序计算鸡和兔分别有多少只的所有组合
输入
无
输出
完整并精确地描述题目输出格式要求
示例
(点击编辑器左上角{;}按钮编辑代码框)
输入输出
'兔': 19, '鸡': 2
'兔': 18, '鸡': 4
....................
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 假设笼中鸡和兔的脚总数为80,编写一个程序计算鸡和兔分别有多少只的所有组合total_feet = 80# 1、兔子数量从0到可能的最大值(总脚数除以4)for rabbits in range(total_feet // 4, 0, -1):# 2、鸡的数量从0到可能的最大值(总脚数除以2)for chickens in range(1, total_feet // 2):# 判断,如果当前组合的脚数等于总数if (rabbits * 4 + chickens * 2) == total_feet:print('兔{}只,鸡{}只'.format(rabbits, chickens))
6、找出100以内的素数,并输出
类型:循环
描述
输出100以内的素数,素数即除了1和它自身之外不能被其他数整除的数
输入
无
输出
以逗号间隔输出所有素数
示例
(点击编辑器左上角{;}按钮编辑代码框)
输入输出
1,2,3,5,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,over
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 输出100以内的素数,素数即除了1和它自身之外不能被其他数整除的数for num in range(1, 101):for i in range(2, num):# 如果能整除的数,就不是素数跳出这次循环if num % i == 0:breakelse:print(num, end=',')print('over')
7、回文数判断
类型:分支,函数
描述
回文数即一个3位整数,其中个位与百位数字相同的数即为回文数。请利用函数来判断一个数是否为回文数,完成如下输出:
示例
输入
101输出
101是回文数输入
134输出
134不是回文数
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的整数numbers = input()# 判断个位与百位数字相同的数即为回文数if numbers[0] in numbers[len(numbers) -1]:print('{}是回文数'.format(numbers))else:print('{}不是回文数'.format(numbers))
8、求三角形的周长和面积
描述
用户输入三角形三边长a,b,c,判断三边长是否能构成三角形,并求其周长和面积,如果周长是z,
面积公式为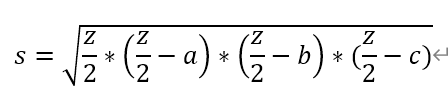 。
。
输入
3,4,5
输出
周长12面积6.0
示例
(输出中的标点为中文,输入为三个数据同一行输入,以逗号间隔)
输入
3,4,5输出
周长12面积6.0输入
10,12,32
不构成三角形
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的三边长a,b,ca, b, c = map(int, input().split(','))# 计算三角形周长z=a+b+cz = a + b + c# 判断三个边是否能构成一个三角形if a + b > c and a + c > b and b + c > a:# 计算三角形面积s = (z / 2 * (z / 2 - a) * (z / 2 - b) * (z / 2 - c)) ** 0.5print('周长{}面积{}'.format(z, s))else:print('不构成三角形')
9、计算收入
类型:分支判断,计算
描述
孙悟空是某公司的一名员工,其月薪是5000元。公司决定本年度没有请假的员工还将拿到2000元的全勤奖和1%的股权。请编写程序计算孙悟空本年度的总收入并输出相应信息。
输入
输入是否请假的情况,Y表示请假,N表示没有请假
输出
输出总收入
示例
(其中%和:都是中文符号)
输入
N输出
孙悟空获得公司1%股权
孙悟空本年度的总收入是:62000输入
Y输出
孙悟空本年度的总收入是:60000
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入是否请假的情况,Y表示请假,N表示没有请假ch = input()# 判断是否请假if ch in 'Y':print('孙悟空本年度的总收入是:{}'.format(5000 * 12))else:print('孙悟空获得公司1%股权')print('孙悟空本年度的总收入是:{}'.format(5000 * 12 + 2000))
10、判断水仙花数
类型:函数、简单循环
描述
请使用函数完成水仙花的数的判断,水仙花数是指一个三位数,其中各位数字的立方和等于该数字本身。例如,153是一个水仙花数,因为153=111+555+333。
输入
153
输出
153是水仙花数
示例
输入
153输出
153是水仙花数输入
222输出
222不是水仙花数
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的数据numbers = eval(input())# 获取个位geWei = numbers % 10# 获取十位shiWei = numbers // 10 % 10# 获取百位baiWei = numbers // 100# 计算其中各位数字的立方和等于该数字本身if (pow(geWei, 3) + pow(shiWei, 3) + pow(baiWei, 3)) == numbers:print('{}是水仙花数'.format(numbers))else:print('{}不是水仙花数'.format(numbers))
11、判断是否登录成功
类型:组合数据类型,循环
描述
用户登录所用11位手机号码和6位密码以键值对方式保存在字典中,要求用户输入其手机号码和密码,判断是否可以登录成功。
输入
用户名
密码
输出
登录成功
示例
输入
123
123输出
用户名或密码错误。
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 定义字典data = {'13966668888': '123456','13822225555': '654321','15533336666': '555555'}# 输入其手机号码phone = input()# 输入其密码pwd = input()# 判断是否可以登录成功if data.get(phone) == pwd:print('登录成功')else:print('用户名或密码错误')
12、字符串拼接
类型:程序基本语法
描述
接受用户输入的两个字符串,将它们组合后输出
输入
输入两个字符串
输出
组合输出
示例
输入
Tom
北京
输出
世界这么大Tom想去北京看看。
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 请输入一个人的名字str1 = input()# 请输入一个国家的名字str2 = input()# 输出print('世界这么大{}想去{}看看。'.format(str1, str2))
13、整数序列求平方和
类型:计算、简单循环
描述
用户输入一个正整数N,计算从1到N(包括1和N)的平方和的结果。
输入
2
输出
1到2平方和结果是5
示例
输入
2输出
1到2平方和结果是5
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 请输入整数nn = input()# 存放平方和sum = 0# 循环遍历for i in range(1, int(n)+1):sum += pow(i, 2)print('1到{}平方和结果是{}'.format(int(n), sum))
14、健康食谱输出
类型:组合类型,分支判断、双重循环
描述
列出5种不同的食材,输出它们可能组成的所有菜式名称。例如有3中不同的食材:[‘西红柿’,‘鸡蛋’,‘牛肉’],输出它们可能组成的所有菜式名称
输入
无
输出
西红柿鸡蛋
西红柿牛肉
鸡蛋西红柿
鸡蛋牛肉
牛肉西红柿
牛肉鸡蛋
示例
(示例结果为部分结果)
输入
无输出
西红柿鸡蛋
西红柿牛肉
鸡蛋牛肉
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 定义食谱字典diet = ['西红柿', '花椰菜', '黄瓜', '牛排', '虾仁']# 用双重循环生成所有两两组合for i in range(len(diet)):for j in range(len(diet)):# 确保不生成重复组合,并且不与自身组合if i != j:print(diet[i] + diet[j])
15、定义函数循环打印菜单,直到用户选择退出
类型:函数、循环,分支
描述
要求利用函数循环打印菜单,程序会循环提示用户输入,除非用户输入正确的选项。
菜单如下:
===========
1.增加学生信息
2.查询学生信息
3.修改学生信息
4.删除学生信息
0.退出
===========
输入
输入提示信息中菜单的正确选项
输出
输入正确给出用户输入选项;输入错误提示错误信息,重新输出菜单信息。
示例
(点击编辑器左上角{;}按钮编辑代码框)
输入
1输出
用户输入的选项是1
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹# 进入编程框,可以按照正常情况缩进
def print_menu():while True:print('=' * 11)print('1.增加学生信息')print('2.查询学生信息')print('3.修改学生信息')print('4.删除学生信息')print('0.退出')print('=' * 11)# 获取输入提示信息中菜单的正确选项choice = int(input())# 判断终止条件if 0 <= choice <= 4:return choiceelse:print('输入错误:只能输入0-4')if __name__ == '__main__':choice = print_menu()print('用户输入的选项是{}'.format(choice))
16、幸运日生成器
类型:自带库、函数、分支
描述
定义一个函数,该函数能够返回随机的年、月、日作为本年度的幸运日期。该函数有获取当前年份的功能,随机生成月份和日期,组合起来作为本年度幸运日期。
输入
无
输出
幸运日期是202年10月10日(不作为样例,只是参考格式)
示例
输入
无输出
幸运日期是2023年10月10日(举例,不代表结果一定是2023年10月10日)
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹
import random
import time# 进入编程框,按实际情况缩进
def get_luck_date():# 获取当前年份year = time.localtime().tm_year# 随机生成月份month = random.randint(1, 12)# 根据月份判断天数if month in [1, 3, 5, 7, 8, 10, 12]:day = 31elif month in [4, 6, 9, 11]:day = 30else:# 二月份,判断闰年if (year % 4 == 0 and year % 100 != 0) or year % 400 == 0:day = 29else:day = 28# 随机生成日数new_day = random.randint(1, day)# 返回结果return f'幸运日期是{year}年{month}月{new_day}日'if __name__ == '__main__':print(get_luck_date())
17、从文件中分析我国39所985高校所对应的学校类型,请统计各类型高校的数量
类型:文件操作、循环,数据计算
描述
edu.txt文件以‘utf-8’进行编码,将文件中的内容通过程序读取后,利用合理的数据类型存储,对我国39所985高校的学校类型开展统计工作,最后给出各类型高校的数量结果。(用try ----except结构获取文件打开异常。)
输入
无
输出(不代表实际统计值,只是部分示例)
综合:1
理工:1
师范:2
(略)
示例
给出部分输出如下(其中的符号为英文符号)
输入
无输出
综合:1
理工:1
师范:2
.............
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':try:# 获取用户输入的文件fname = input()# 读取edu.txt文件数据fr = open(fname, 'r', encoding='utf8')li_data = fr.read()fr.close()# 处理数据li_data = li_data.replace('\n', ',')# 初始化一个空字典,用于存储每种类型school_types_count = {}# 处理数据,将其按逗号分隔school_types = li_data.split(',')# 统计学校类型数量for school_type in school_types:# 判断是否相同类型,进行计数if school_type in school_types_count:school_types_count[school_type] += 1else:school_types_count[school_type] = 1# 遍历输出for ket, value in school_types_count.items():print('{}:{}'.format(ket, value))except:print('文件打开异常')
18、求温度平均值
下面是一个传感器采集数据文件sensor-data.txt的一部分: 2018-02-28 01:03:16.33393 19.3024 38.4629 45.08 2.68742 2018-02-28 01:06:16.013453 19.1652 38.8039 45.08 2.68742 2018-02-28 01:06:46.778088 19.175 38.8379 45.08 2.69964 …… 其中,每行是一个读数,空格分隔多个含义,分别包括日期、时间、温度、湿度、光照和电压。其中,光照处于第5列。
请编写程序,统计并输出传感器采集数据中温度部分的平均值,所有值保留小数点后2位。报错输出用异常处理机制(try-except)。输出中冒号为中文符号。
输入
sensor-data.txt输出
平均的温度值是:20.09输入
s-data.txt输出
文件打开错误
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':try:# 获取用户输入的文件fileName = input()# 存储温度temperature = 0count = 0# 读取文件数据with open(fileName, 'r', encoding='utf-8') as file:for line in file.readlines():# 处理数据li_data = line.strip().split(' ')# 计算处理temperature += float(li_data[2])count += 1# 计数平均的温度值mean_value = temperature / countprint(f'平均的温度值是:{mean_value:.2f}')except:print('文件打开错误')
19、平均数蕴含了“重心”的意思
平均数蕴含了“重心”的意思,中位数用于概括一组数据的位置,是高度耐抗的,有个别的极大值或者极小值,不会引起中位数的变化。在numbers.txt中给出了100个人的某月收入(单位:元),求100人月收入的算术平均数和中位数并参照如下格式输出:其中不规定小数点位数。
算术平均数为3428.96。
中位数为3966.5。
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 存储数据li_data = []# 读取文件数据with open('numbers.txt', 'r', encoding='utf-8') as file:for line in file.readlines():# 存储li_data.append(int(line.strip()))# 计算算术平均数average = sum(li_data) / len(li_data)# 将数据进行排序方便计算中位数li_data = sorted(li_data)# 根据排序获取中位元素的下标index = len(li_data) // 2# 判断长度是否是偶数,如果是中位数就是中间俩个数的平均值if len(li_data) % 2 == 0:median = (li_data[index - 1] + li_data[index]) / 2else:median = li_data[index]print('算术平均数为{}。'.format(average))print('中位数为{}。'.format(median))
20、反转输出
获得输入正整数 N,反转输出该正整数,不考虑异常情况。
**示例1:**
输入:"986"
输出:"689"
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的一个整数N = input()# 输出print(N[::-1])
21、UNICODE字符串输出
获得用户输入的一个整数,一行输出以该整数作为 Unicode 开始并逐一递增的 10 个字符。
**示例1:(示例仅仅代表格式)**
输入:23
输出:<=>?@ABCDE
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的一个整数numbers = input()# 循环逐一递增10个字符for i in range(10):print(chr(eval(numbers) + i), end='')
22、模拟发车
类型:循环
描述
发车模拟:南宁到桂林的汽车,从早上6点到晚上20点,用户输入发车间隔,利用间隔输出所有车次
如每隔两小时发一趟,则输出如下示例:
输入
2输出
发6点钟的车
发8点钟的车
发10点钟的车
发12点钟的车
发14点钟的车
发16点钟的车
发18点钟的车
发20点钟的车
共发8趟车
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 获取用户输入的发车间隔interval = int(input())# 起始发车时间departure_time = 6# 总运行时间total_hours = 20count = 0# 计算并输出总共发车的趟数,如果每隔interval小时发一趟,则输出如下示例while departure_time <= total_hours:print('发{}点钟车'.format(departure_time))count += 1departure_time += intervalprint('共发{}趟车'.format(count))
23、下面是一个传感器采集数据文件sensor-data.csv的一部分
下面是一个传感器采集数据文件sensor-data.csv的一部分:
2018-02-28 01:03:16.33393 19.3024 38.4629 45.08 2.687422018-02-28 01:06:16.013453 19.1652 38.8039 45.08 2.687422018-02-28 01:06:46.778088 19.175 38.8379 45.08 2.69964……
其中,每行是一个读数,空格分隔多个含义,分别包括日期、时间、温度、湿度、光照和电压。其中,温度处于第3列。
请编写程序,用户输入文件名,统计并输出传感器采集数据中光照部分的最大值,最小值,平均值,所有值保留小数点后2位。读取文件不用指定编码方式。
输入为:sensor-data.csv输出为:(符号为中文)最大值、最小值、平均值分别是:49.08, 40.08, 44.37输入为:x.csv输出为:文件打开错误
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':try:# 获取用户输入的文件fileName = input()# 存储光照数据li_data = []# 读取文件数据with open(fileName, 'r', encoding='utf-8') as file:for line in file.readlines():# 处理数据,并存储line = line.strip().split(',')# 转成浮点类型并且存储li_data.append(float(line[4]))# 统计并输出传感器采集数据中光照部分的最大值,最小值,平均值,所有值保留小数点后2位Max = max(li_data)Min = min(li_data)Mean = sum(li_data) / len(li_data)print(f'最大值、最小值、平均值分别是:{Max:.2f}, {Min:.2f}, {Mean:.2f}')except:print('文件打开错误')
24、从文件中分析某个班级中学生的民族类型,请统计各民族的数量
类型:文件操作、循环,数据计算
描述
nation.txt文件以‘utf-8’进行编码,文件中的分隔符为英文符号,请将文件中的内容通过程序读取后,利用合理的数据类型存储,对某个班级学生的民族类型开展统计工作,最后给出各民族的数量结果,文件名要求由用户输入。(用try ----except结构获取文件打开异常。)
示例
给出部分输出如下(其中的符号为英文符号)
输入
nation.txt输出
汉族:10
瑶族:8
壮族:9
.............输入
x.txt输出
文件打开错误
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':try:# 获取用户输入的文件fileName = input()# 定义一个空字典,统计各民族的数量nation_count = {}# 读取文件数据with open(fileName, 'r', encoding='utf-8') as file:for line in file.readlines():# 处理数据,并存储line = line.strip().split(';')# 循环统计各民族的数量for row in line:# 判断重复类型,并计算if row in nation_count:nation_count[row] += 1else:nation_count[row] = 1# 遍历输出for key, value in nation_count.items():print('{}:{}'.format(key, value))except:print('文件打开错误')
25、从文件中分析我国39所985高校所对应的学校类型,请统计各类型高校的数量
类型:文件操作、循环,数据计算
描述
edu.txt文件以‘utf-8’进行编码,将文件中的内容通过程序读取后,利用合理的数据类型存储,对我国39所985高校的学校类型开展统计工作,最后给出各类型高校的数量结果。(用try ----except结构获取文件打开异常。)
输入
文件名
输出(不代表实际统计值,只是部分示例)
综合:1
理工:1
师范:2
(略)
示例
给出部分输出如下(其中的符号为英文符号)
输入
edu.txt输出
综合:1
理工:1
师范:2
.............
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':try:# 获取用户输入的文件fileName = input()# 定义一个空字典,统计各类型高校的数量university_count = {}# 读取文件数据with open(fileName, 'r', encoding='utf-8') as file:for line in file.readlines():# 处理数据,并存储line = line.strip().split(',')# 循环统计各类型高校的数量for row in line:# 判断重复类型,并计算if row in university_count:university_count[row] += 1else:university_count[row] = 1# 遍历输出for key, value in university_count.items():print('{}:{}'.format(key, value))except:print('文件打开异常')
26、生成随机密码
请编写程序,生成随机密码。具体要求如下:
(1)使用 random 库,采用 0x1010 作为随机数种子。
(2)密码 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*中的字符组成。
(3)每个密码长度固定为 10 个字符。
(4)程序运行每次产生 10 个密码,每个密码一行。
(5)每次产生的 10 个密码首字符不能一样。
输入输出示例
| 输入 | 输出 | |
|---|---|---|
| 示例 1 | 无 | So2WpkoC7i armJ86eUG9 B*GcqsYC^B wQ3bcfcAJy Xdyg8pQTIS YO!1YH1AP3 cuhZUk@s5& D@4d9$TBfp TBm#WfYNHr Ue75y$E9Cv |
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹
import randomif __name__ == '__main__':# 设置随机种子以保证可重复性random.seed(0x1010)# 定义包含所有可能字符的字符串s = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890!@#$%^&*'# 初始化一个空列表,用于存放生成的密码ls = []# 初始化一个空字符串,用于存放每个密码的首字符excludes = ''# 当列表中的密码数量小于10时,持续生成密码while len(ls) < 10:pwd = '' # 初始化一个空字符串,用于生成一个10字符长度的密码# 生成10字符长度的密码for i in range(10):# 从字符集合中随机选择一个字符,并将其添加到密码中pwd += s[random.randint(0, len(s) - 1)]# 检查密码的首字符是否已经存在于 excludes 字符串中if pwd[0] in excludes:continue # 如果首字符重复,跳过当前密码,继续生成新密码else:# 如果首字符不重复,将生成的密码添加到列表中ls.append(pwd)# 将密码的首字符添加到 excludes 字符串中excludes += pwd[0]# 直接打印print("\n".join(ls))
27、县区查询
类型:文件
描述
附件中的文本文件里包含河北省的地区信息,
文件第一行为省名和地级市名,其他每行的第一个地名为地级市名,后面地名为该地区的下辖区、县和县级市的名称,如下所示:
河北,石家庄,唐山,秦皇岛,邯郸,邢台,保定,张家口,承德,沧州,廊坊,衡水 石家庄,长安区,桥东区,…,藁城市,鹿泉市 唐山,路南区,路北区,…,遵化县,迁安县 秦皇岛,海港区,三海关区…,抚宁县,卢龙县 邯郸,邯山区,丛台区,…,曲周县,武安县 邢台,桥东区,桥西区,…,南宫市,沙河西 保定,新市区,北市区,…,安国市,高碑店市 张家口,桥东区,桥西区,…,赤城县,崇礼县 承德,双桥区,双滦区,…,围场蒙古做自治县 沧州,新华区,运河区,…,河间市,黄骅市 廊坊,安次区,广阳区,…,三河市,霸州市 衡水,桃城区,枣强县,…,深州市,冀州县
下面代码可以将该文件的内容读到列表中,运行这段代码,查看输出的列表内容,完成要求的操作:
with open(‘hebei.txt’, ‘r’, encoding=‘utf-8’) as file: district_ls = [x.split(‘,’) for x in file] print(district_ls)
(1)如果用户输入的是地级市名,以列表形式输出其下辖所有下辖区、县和县级市名称。
(2)如果用户输入的是市辖区、县或县级市名,则输出其上一级的地级市名,若有的市辖区名在不同地级市中同时存在时,输出全部地级市名。
输入格式
输入一个地区或县区名
输出格式
输出其下辖所有区县名称或其上一级的地级区名(有的县区名或能在不同地级区中同时存在,则分多行打印几个上级地区名。)
示例1
输入:唐山
输出:['路南区', '路北区', '古治区', '开平区', '丰南区', '丰润区', '曹妃甸区', '滦县', '滦南县', '乐亭县', '迁西县', '玉田县', '遵化县', '迁安县']
示例2
输入:鸡泽县
输出:邯郸
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 定义一个空元组,用于存储数据district_ls = []# 读取hebei.txt文件数据with open('hebei.txt', 'r', encoding='utf-8') as file:for line in file.readlines():# 进行分割每行数据并存储到列表中district_ls.append(line.strip().split(','))# 定义一个空字典用于存放数据district_ls_new = {}# 根据题目要求处理数据存储格式,遍历每一行数据for row in district_ls:# print(row)# 创建一个新的列表来存储该地区的数据data_li = []# 循环遍历,从第二元素开始,第一元素做为keyfor index in range(1, len(row)):# print(row[index])# 添加数据到data_li列表中data_li.append(row[index])# 存储到字典中,键为地区名,值为data_li列表:data = {'地区名': ['xxx', 'xxx'], '地区名': ['xxx', 'xxx']}district_ls_new[row[0]] = data_li# 获取用户输入的一个地区或县区名district = input()# 判断用户输入的是否是地区名if district in district_ls_new:# 如果输入的是地区名,输出该地区包含的县区名列表print(district_ls_new.get(district))else:# 如果输入的不是地区名,则遍历字典的值列表,判断输入的县区名是否在任何一个地区名的值列表中for city, districts in district_ls_new.items():if district in districts:print(city)
28、查询高校名
类型:文件处理
描述
#以下代码的作用是:
#打开文件,创建一个名为Uname的对象,Uname.readlines()的作用是将文件内容逐行读取到列表中
#文件的每行为一个以‘\n’结尾的字符串,做为列表ls的一个元素
#列表ls的第一个元素ls[0]的内容是:'序号,学校名称,学校标识码,主管部门,所在地,办学层次,备注\n'with open('university.csv','r',encoding='utf-8') as Uname:ls = Uname.readlines()#print(ls)
#输出:['序号,学校名称,学校标识码,主管部门,所在地,办学层次,备注\n',
# '1,北京大学,4111010001,教育部,北京市,本科,\n',
# '2,中国人民大学,4111010002,教育部,北京市,本科,\n',
# '3,清华大学,4111010003,教育部,北京市,本科,\n',
# ……
# ]
附件’university.csv’中包含北京主要高校的序号、学校名称、学校标识码、主管部门、所在地、办学层次、备注等信息,以逗号分隔符。 参考提示代码,将文件内容逐行读取到列表中,根据用户输入一个关键字,查询学校名称包含用户输入关键字的学校名并输出。
输入格式
输入一个关键字
输出格式
包含关键字的全部学校名
示例
输入:
中央
输出:
中央财经大学
中央音乐学院
中央美术学院
中央戏剧学院
中央民族大学
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 读取university.csv文件数据with open('university.csv', 'r', encoding='utf-8') as Uname:ls = Uname.readlines()# 获取用户输入的关键字keyword = input()# 存在包含关键字的学校名称matching_schools = []# 遍历每一行数据(从第二行开始,因为第一行是表头)for line in ls[1:]:# 将每行数据按逗号分割columns = line.strip().split(',')# 学校名称在第二列(索引为1)school_name = columns[1]# 判断学校名称是否包含用户输入的关键字if keyword in school_name:# 如果包含,添加到结果列表matching_schools.append(school_name)# 输出所有匹配的学校名称for school in matching_schools:print(school)
29、字典查询
类型:字典
描述
有字典 dict1 = {‘赵广辉’:‘13299887777’,‘特朗普’:‘814666888’,‘普京’:‘522888666’,‘吴京’:‘13999887777’},编程实现查找功能,用户输入姓名,如在字典中存在,输出“姓名:电话”,如不存在,则输出“数据不存在”。
输入格式
一个姓名
输出格式
姓名:电话
示例 1
输入:赵广辉
输出:赵广辉:13299887777
代码:
# -*- coding = utf-8 -*-
# @Author:为一道彩虹if __name__ == '__main__':# 字典dict1 = {'赵广辉': '13299887777', '特朗普': '814666888', '普京': '522888666', '吴京': '13999887777'}# 获取用户输入的姓名name = input()# 判断name是否存在字典中if name in dict1:print(f'{name}:{dict1[name]}')else:print("数据不存在")
先赞后看,养成习惯!!!^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我的坚持下去的动力。点赞后不要忘了关注我哦!






![【前端】[vue3] [uni-app] 组件样式击穿:deep](https://img-blog.csdnimg.cn/direct/a9540a8da28949ae86d7b536b5b40ef9.png#pic_center)