🧨背景
stability在一个月之前默默的发布了Stable Audio Open 1.0的音频音效生成模型,不过好像影响力一般,也没有太多文章分享测试,而今天看comfyui作者的一篇介绍文档,他已经让comfyui默认支持了这个模型。
原开源地址:https://huggingface.co/stabilityai/stable-audio-open-1.0
Stable Audio Open 1.0根据文本提示生成 44.1kHz 的可变长度(最长 47 秒)立体声音频。它由三个组件组成:将波形压缩为可管理序列长度的自动编码器、用于文本调节的基于 T5 的文本嵌入,以及在自动编码器的潜在空间中运行的基于变换器的扩散 (DiT) 模型。
实际测试下来,在音效生成方面,其实还可以,结合sd3或许可以生成不错的解压视频,所以这里介绍给大家。
✨训练集与应用限制
训练素材
数据集包含 486492 条录音,其中 472618 条来自 Freesound,13874 条来自免费音乐档案馆 (FMA)。所有音频文件均根据 CC0、CC BY 或 CC Sampling+ 获得许可。这些数据用于训练我们的自动编码器和 DiT。我们使用公开的预训练 T5 模型 ( t5-base ) 进行文本调节。
限制
- 该模型无法生成逼真的声音。
- 该模型已使用英语描述进行训练,在其他语言中的表现不会那么好。
- 该模型并不适用于所有音乐风格和文化。
- 该模型在生成音效和现场录音方面比音乐更出色。
- 有时很难评估哪种类型的文本描述可以提供最佳的生成效果。可能需要及时进行工程设计才能获得令人满意的结果。
🎊使用方法
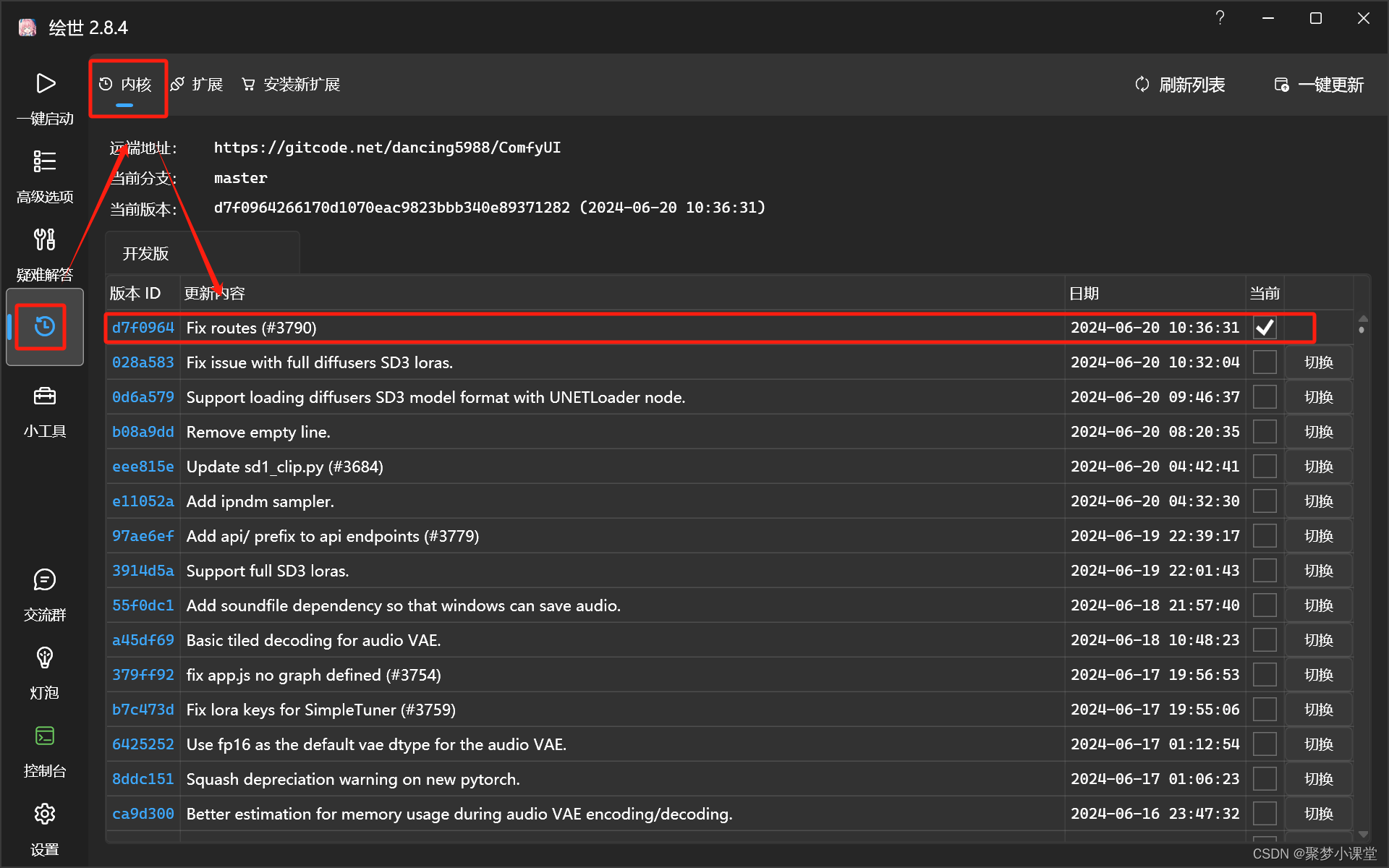
第一步,首先更新ComfyUI到最新的版本;
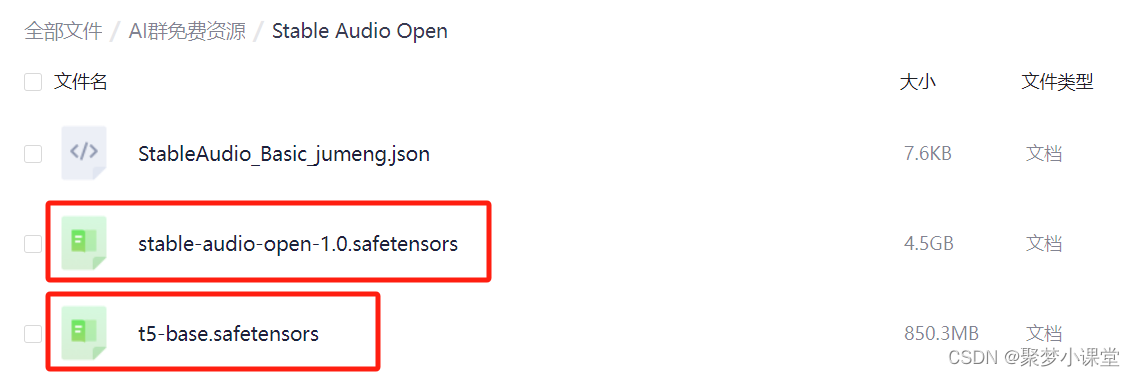
第二步,下载音频生成相关的两个模型:
【音频生成模型资源】
https://pan.quark.cn/s/83bc2652d05e
第三步,从第二步的网盘下载工作流;

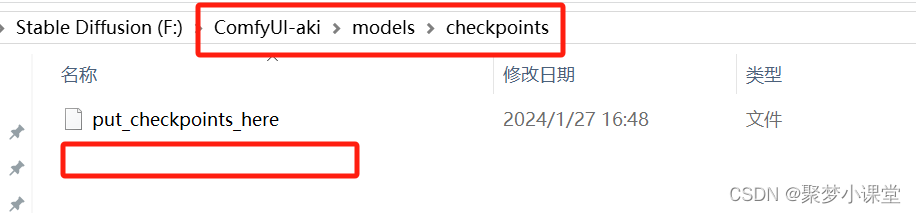
第四步,把stable-audio-open-1.0.safetensors模型放在models文件夹下的checkpoints文件夹下,可以有二级目录;
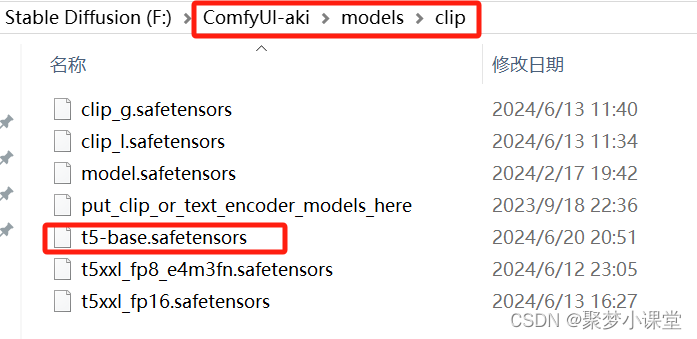
把t5-base模型放在models下clip文件夹下(注意,这里不能直接用sd3的t5xxl模型,这两个不通用)
第五步,打开工作流,选择大模型的地址,输入提示词就可以正常生成音频了。
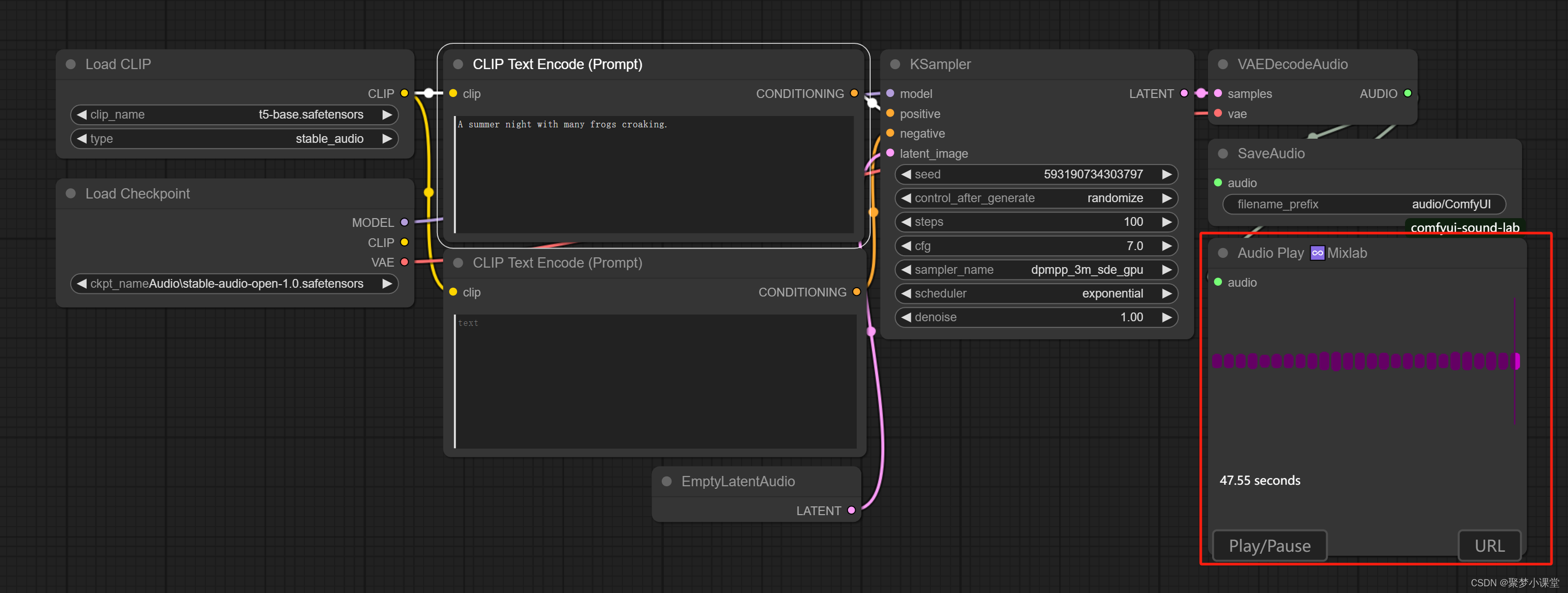
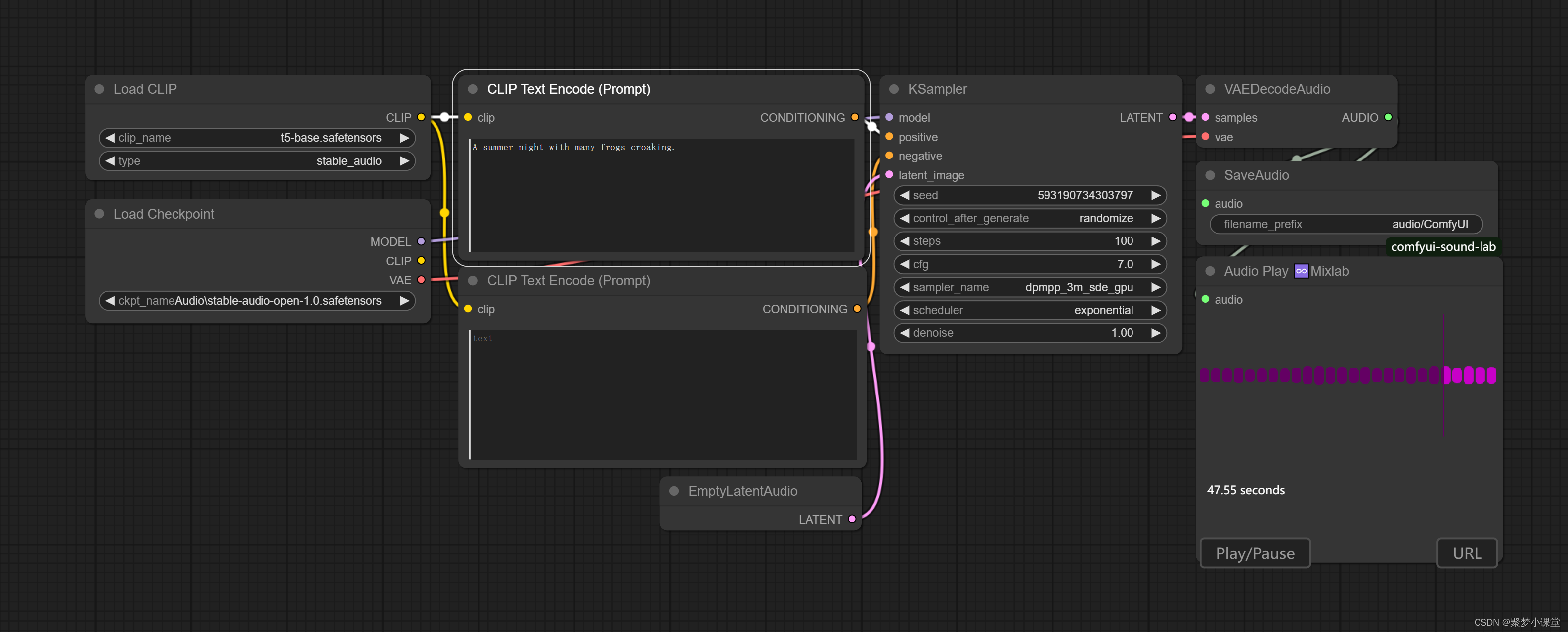 注意:如果最右下角的mixlab的节点你没有安装,直接删掉这个节点也可以,这个节点的作用是在comfyui中直接播放音乐,比较方便而已,并不影响生成。
注意:如果最右下角的mixlab的节点你没有安装,直接删掉这个节点也可以,这个节点的作用是在comfyui中直接播放音乐,比较方便而已,并不影响生成。
如果没有这个节点,可以到output文件夹下找到生成的音频:
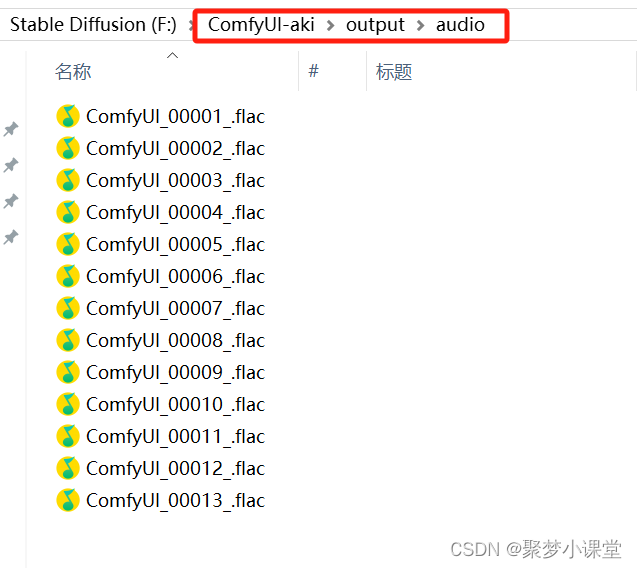
测试下来,音频效果还不错,以下是几个可以尝试的音频提示词:
非常轻松的爵士小调:Very relaxing and pleasant jazz music, suitable for vlogs.
蛙鸣:A summer night with many frogs croaking.
雷电交加:Thunder and lightning, accompanied by the sounds of the wind and waves.
😄玩的开心,如果对你有帮助的话,记得点赞哦~
✨写在最后
之前一直讲的都是webUI的课程,这次针对ComfyUI的新手开了一门图文课程,目前还在持续更新中,欢迎订阅哦~
https://blog.csdn.net/jumengxiaoketang/category_12683612.html
感谢大家的支持~