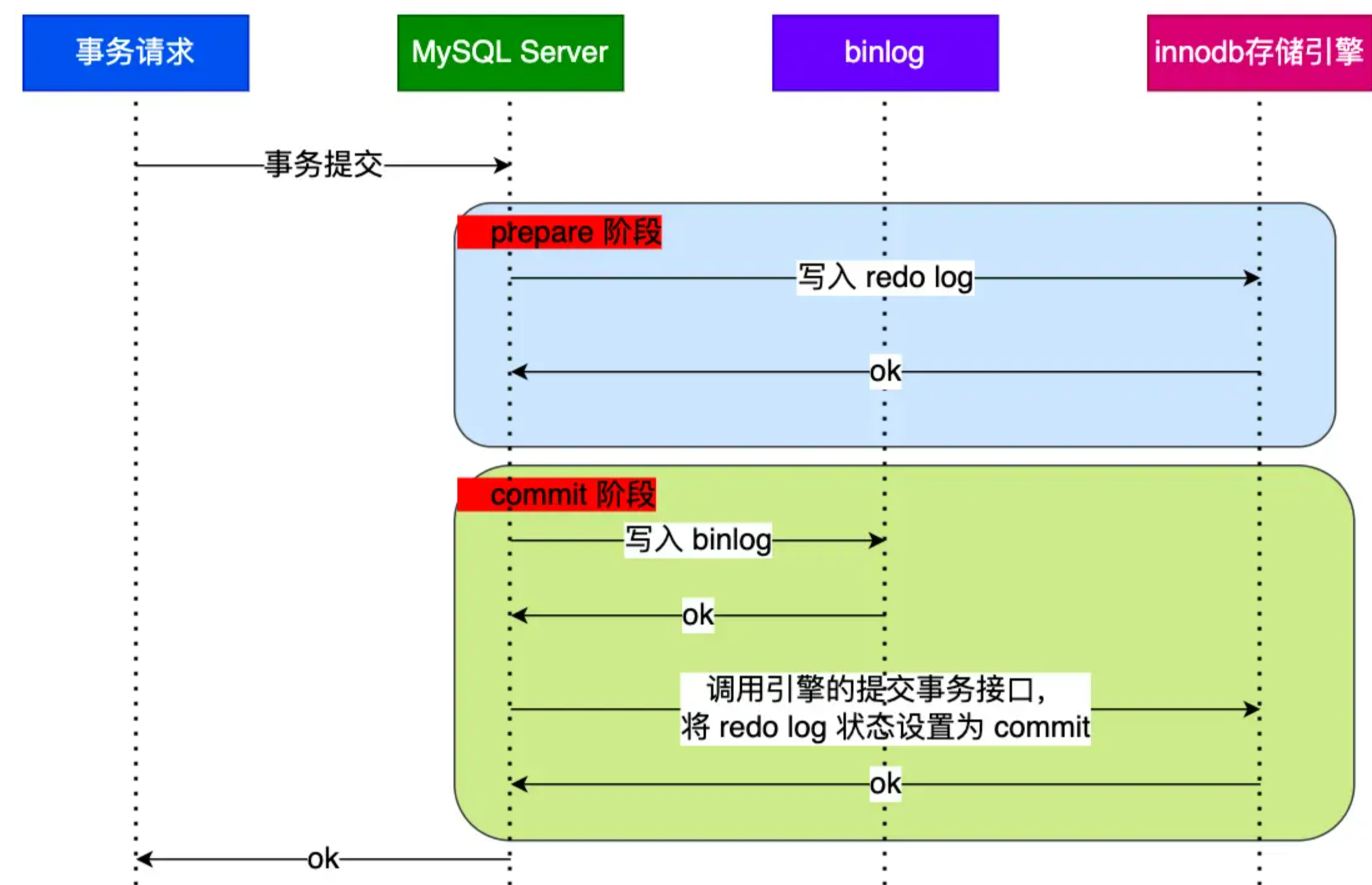
1. SQL解析 -> SQL优化 -> SQL路由 -> SQL改写 -> SQL执⾏-> 结果归并 ->返回结果简写为:解析->路由->改写->执⾏->结果归并
1. SQL解析过程分为词法解析,语法解析。
2. 词法解析:词法解析器用于将SQL拆解为不可再分的原子符号,称为Token,再使用语法解析器将SQL转换为抽象语法树。
3. 抽象语法树的遍历去提炼分片所需的上下文,并标记有可能需要的SQL改写。
1. 分片路由:带分片键,直接路由,标准路由,笛卡尔积路由
2. 广播路由:不带分片键,全库表路由,全库路由,全实例路由等。
1. Logic SQL逻辑表SQL,不能够直接在真实的数据库表中执行,SQL改写会将逻辑SQL改写为在真实数据库中可以正确执行的ActualSQL.
1. 采用自动化的执行引擎,将路由和改写完之后的Actual SQL安全且高效发送给底层数据源执行,自动平衡资源控制与执行效率
2. 两大模式:内存限制模式:数据库连接数量不做限制,多线程并发执行效率最大化,适用OLAP操作。连接限制模式:严格控制对一次操作所耗费的数据库连接数量,1库1线程,多库多线程使用OLTP操作,保证数据库资源被足够多应用使用。
从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,功能上可分为遍历,排序,分组,分页和聚合5种。
1. 结构划分两大类:流式-归并:每一次从结果集中获取到的数据,都通过逐条获取的方式返回正确的单条数据,它与数据库原生的返回结果集的方式最为契合。占用了额外的带宽,但不会导致内存暴涨,使用的最多。内存-归并:分片结果集的数据存储在内存中,再通过统一的分组,排序以及聚合等计算之后,再将其封装成为逐条访问的数据结果集返回,消耗内存。
1. 只⽀持【单分⽚键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分⽚算法.
2. PreciseShardingAlgorithm 精准分⽚ 是必选的,⽤于处理=和IN的分⽚.
3. RangeShardingAlgorithm 范围分⽚ 是可选的,⽤于处理BETWEEN AND分⽚.
4. 如果不配置RangeShardingAlgorithm,如果SQL中⽤了BETWEEN AND语法,则将按照全库路由处理,性能下降.
package com. dss. sharding. strategy ; import org. apache. shardingsphere. api. sharding. standard. PreciseShardingAlgorithm ;
import org. apache. shardingsphere. api. sharding. standard. PreciseShardingValue ; import java. util. Collection ;
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm < Long > { @Override public String doSharding ( Collection < String > , PreciseShardingValue < Long > ) { for ( String datasourceName : dataSourceNames) { String value = preciseShardingValue. getValue ( ) % dataSourceNames. size ( ) + "" ; if ( datasourceName. endsWith ( value) ) { return datasourceName; } } return null ; }
}
spring. application. name= sharding- jdbc
server. port= 8080 # 打印执行的数据库以及语句
spring. shardingsphere. props. sql. show= true # 数据源 db0
spring. shardingsphere. datasource. names= ds0, ds1# 第一个数据库
spring. shardingsphere. datasource. ds0. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds0. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds0. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_0? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds0. username= root
spring. shardingsphere. datasource. ds0. password= root# 第二个数据库
spring. shardingsphere. datasource. ds1. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds1. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds1. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_1? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds1. username= root
spring. shardingsphere. datasource. ds1. password= root#配置workId
spring. shardingsphere. sharding. tables. product_order. key- generator. props. worker. id= 1 #配置广播表
spring. shardingsphere. sharding. broadcast- tables= ad_config
spring. shardingsphere. sharding. tables. ad_config. key- generator. column= id
spring. shardingsphere. sharding. tables. ad_config. key- generator. type= SNOWFLAKE#配置【默认分库策略】
#spring. shardingsphere. sharding. default - database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. default - database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 }
#配置分库规则
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 } #id生成策略
spring. shardingsphere. sharding. tables. product_order. key- generator. column= id
spring. shardingsphere. sharding. tables. product_order. key- generator. type= SNOWFLAKE# 指定product_order表的数据分布情况,配置数据节点, 行表达式标识符使用 ${ . . . } 或 $-> { . . . } ,
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $-> { . . . }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$-> { 0. .1 } . product_order_$-> { 0. .1 }
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. sharding- column= id
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. algorithm- expression= product_order_$-> { id % 2 } # 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order_item. actual- data- nodes= ds$-> { 0. .1 } . product_order_item_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. sharding- column= product_order_id
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. algorithm- expression= product_order_item_$-> { product_order_id % 2 } #配置绑定表
#spring. shardingsphere. sharding. binding‐tables[ 0 ] = product_order, product_order_item#精准分片- 水平分表
# 指定product_order表的数据分布情况,配置数据节点, 在 Spring 环境中建议使用 $-> { . . . }
spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 } #指定精准分片算法( 水平分表)
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. sharding- column= id
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomTablePreciseShardingAlgorithm@Test public void testSaveProductOrder ( ) { Random random = new Random ( ) ; for ( int i= 0 ; i< 20 ; i++ ) { ProductOrderDO productOrderDO = new ProductOrderDO ( ) ; productOrderDO. setCreateTime ( new Date ( ) ) ; productOrderDO. setNickname ( "PreciseShardingAlgorithm i=" + i) ; productOrderDO. setOutTradeNo ( UUID. randomUUID ( ) . toString ( ) . substring ( 0 , 32 ) ) ; productOrderDO. setPayAmount ( 100.00 ) ; productOrderDO. setState ( "PAY" ) ; productOrderDO. setUserId ( Long . valueOf ( random. nextInt ( 50 ) ) ) ; productOrderMapper. insert ( productOrderDO) ; } }
package com. dss. sharding. strategy ; import org. apache. shardingsphere. api. sharding. standard. PreciseShardingAlgorithm ;
import org. apache. shardingsphere. api. sharding. standard. PreciseShardingValue ; import java. util. Collection ; public class CustomDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm < Long > { @Override public String doSharding ( Collection < String > , PreciseShardingValue < Long > ) { for ( String datasourceName : dataSourceNames) { String value = preciseShardingValue. getValue ( ) % dataSourceNames. size ( ) + "" ; if ( datasourceName. endsWith ( value) ) { return datasourceName; } } return null ; }
}
spring. application. name= sharding- jdbc
server. port= 8080 # 打印执行的数据库以及语句
spring. shardingsphere. props. sql. show= true # 数据源 db0
spring. shardingsphere. datasource. names= ds0, ds1# 第一个数据库
spring. shardingsphere. datasource. ds0. type= com. zaxxer. hikari. HikariDataSource
spring. shardingsphere. datasource. ds0. driver- class - name= com. mysql. cj. jdbc. Driver
spring. shardingsphere. datasource. ds0. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_0? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia/ Shanghai& allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds0. username= root
spring. shardingsphere. datasource. ds0. password= root# 第二个数据库
spring. shardingsphere. datasource. ds1. type= com. zaxxer. hikari. HikariDataSource
spring. shardingsphere. datasource. ds1. driver- class - name= com. mysql. cj. jdbc. Driver
spring. shardingsphere. datasource. ds1. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_1? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia/ Shanghai& allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds1. username= root
spring. shardingsphere. datasource. ds1. password= root#配置workId
spring. shardingsphere. sharding. tables. product_order. key- generator. props. worker. id= 1 #配置广播表
spring. shardingsphere. sharding. broadcast- tables= ad_config
spring. shardingsphere. sharding. tables. ad_config. key- generator. column= id
spring. shardingsphere. sharding. tables. ad_config. key- generator. type= SNOWFLAKE #配置【默认分库策略】
#spring. shardingsphere. sharding. default- database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. default- database- strategy. inline. algorithm- expression= ds$- > { user_id % 2 }
#配置分库规则
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. algorithm- expression= ds$- > { user_id % 2 } #id生成策略
spring. shardingsphere. sharding. tables. product_order. key- generator. column= id
spring. shardingsphere. sharding. tables. product_order. key- generator. type= SNOWFLAKE # 指定product_order表的数据分布情况,配置数据节点, 行表达式标识符使用 ${ ... } 或 $- > { ... } ,
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $- > { ... }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$- > { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$- > { 0. .1 } . product_order_$- > { 0. .1 }
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. sharding- column= id
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. algorithm- expression= product_order_$- > { id % 2 } # 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order_item. actual- data- nodes= ds$- > { 0. .1 } . product_order_item_$- > { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. sharding- column= product_order_id
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. algorithm- expression= product_order_item_$- > { product_order_id % 2 } #配置绑定表
#spring. shardingsphere. sharding. binding‐tables[ 0 ] = product_order, product_order_item#精准分片- 水平分表
# 指定product_order表的数据分布情况,配置数据节点, 在 Spring 环境中建议使用 $- > { ... }
spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$- > { 0. .1 } . product_order_$- > { 0. .1 } #指定精准分片算法 ( 水平分库) 根据user_id分库
spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. sharding- column= user_id
spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomDBPreciseShardingAlgorithm#指定精准分片算法 ( 水平分表) 根据订单id分表
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. sharding- column= id
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomDBPreciseShardingAlgorithm1. ⽤于处理BETWEEN AND语法,没配置的话会报错 Cannot find range sharding strategy in sharding rule.
2. 主要是会根据 SQL中给出的分⽚健值范围值处理分库、分表逻辑.
package com. dss. sharding. strategy ; import org. apache. shardingsphere. api. sharding. standard. RangeShardingAlgorithm ;
import org. apache. shardingsphere. api. sharding. standard. RangeShardingValue ; import java. util. Collection ;
import java. util. LinkedHashSet ;
import java. util. Set ; public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm < Long > { @Override public Collection < String > doSharding ( Collection < String > , RangeShardingValue < Long > ) { Set < String > = new LinkedHashSet < > ( ) ; Long lower = shardingValue. getValueRange ( ) . lowerEndpoint ( ) ; Long upper = shardingValue. getValueRange ( ) . upperEndpoint ( ) ; for ( long i= lower; i<= upper; i++ ) { for ( String datasource : dataSourceNames) { String value = i % dataSourceNames. size ( ) + "" ; if ( datasource. endsWith ( value) ) { result. add ( datasource) ; } } } return result; }
}
spring. application. name= sharding- jdbc
server. port= 8080 # 打印执行的数据库以及语句
spring. shardingsphere. props. sql. show= true # 数据源 db0
spring. shardingsphere. datasource. names= ds0, ds1# 第一个数据库
spring. shardingsphere. datasource. ds0. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds0. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds0. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_0? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds0. username= root
spring. shardingsphere. datasource. ds0. password= root# 第二个数据库
spring. shardingsphere. datasource. ds1. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds1. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds1. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_1? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds1. username= root
spring. shardingsphere. datasource. ds1. password= root#配置workId
spring. shardingsphere. sharding. tables. product_order. key- generator. props. worker. id= 1 #配置广播表
spring. shardingsphere. sharding. broadcast- tables= ad_config
spring. shardingsphere. sharding. tables. ad_config. key- generator. column= id
spring. shardingsphere. sharding. tables. ad_config. key- generator. type= SNOWFLAKE#配置【默认分库策略】
#spring. shardingsphere. sharding. default - database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. default - database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 }
#配置分库规则
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 } #id生成策略
spring. shardingsphere. sharding. tables. product_order. key- generator. column= id
spring. shardingsphere. sharding. tables. product_order. key- generator. type= SNOWFLAKE# 指定product_order表的数据分布情况,配置数据节点, 行表达式标识符使用 ${ . . . } 或 $-> { . . . } ,
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $-> { . . . }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$-> { 0. .1 } . product_order_$-> { 0. .1 }
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. sharding- column= id
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. algorithm- expression= product_order_$-> { id % 2 } # 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order_item. actual- data- nodes= ds$-> { 0. .1 } . product_order_item_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. sharding- column= product_order_id
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. algorithm- expression= product_order_item_$-> { product_order_id % 2 } #配置绑定表
#spring. shardingsphere. sharding. binding‐tables[ 0 ] = product_order, product_order_item#精准分片- 水平分表
# 指定product_order表的数据分布情况,配置数据节点, 在 Spring 环境中建议使用 $-> { . . . }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$-> { 0. .1 } . product_order_$-> { 0. .1 }
spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 } #指定精准分片算法( 水平分库) 根据user_id分库
spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. sharding- column= user_id
spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomDBPreciseShardingAlgorithm( 水平分表) 根据订单id分表
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. sharding- column= id
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomTablePreciseShardingAlgorithm( 水平分表)
spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. range- algorithm- class - name= com. dss. sharding. strategy. CustomRangeShardingAlgorithm1. 提供对SQL语句中的=, IN和BETWEEN AND的分⽚操作,⽀持【多分⽚键】
2. 由于多分⽚键之间的关系复杂,Sharding-JDBC并未做过多的封装
3. ⽽是直接将分⽚键值组合以及分⽚操作符交于算法接⼝,全部由应⽤开发者实现,提供最⼤的灵活度。
package com. dss. sharding. strategy ; import org. apache. shardingsphere. api. sharding. complex. ComplexKeysShardingAlgorithm ;
import org. apache. shardingsphere. api. sharding. complex. ComplexKeysShardingValue ; import java. util. ArrayList ;
import java. util. Collection ;
import java. util. List ;
import java. util. Map ; public class CustomComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm < Long > { @Override public Collection < String > doSharding ( Collection < String > , ComplexKeysShardingValue < Long > ) { Collection < Long > = this . getShardingValue ( complexKeysShardingValue, "id" ) ; Collection < Long > = this . getShardingValue ( complexKeysShardingValue, "user_id" ) ; List < String > = new ArrayList < > ( ) ; for ( Long userId : userIdValues) { for ( Long orderId : orderIdValues) { String suffix = userId % 2 + "_" + orderId % 2 ; for ( String databaseName : dataSourceNames) { if ( databaseName. endsWith ( suffix) ) { shardingSuffix. add ( databaseName) ; } } } } return shardingSuffix; } private Collection < Long > getShardingValue ( ComplexKeysShardingValue < Long > , final String key) { Collection < Long > = new ArrayList < > ( ) ; Map < String , Collection < Long > > = shardingValues. getColumnNameAndShardingValuesMap ( ) ; if ( columnNameAndShardingValuesMap. containsKey ( key) ) { valueSet. addAll ( columnNameAndShardingValuesMap. get ( key) ) ; } return valueSet; } }
spring. application. name= sharding- jdbc
server. port= 8080 # 打印执行的数据库以及语句
spring. shardingsphere. props. sql. show= true # 数据源 db0
spring. shardingsphere. datasource. names= ds0, ds1# 第一个数据库
spring. shardingsphere. datasource. ds0. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds0. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds0. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_0? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds0. username= root
spring. shardingsphere. datasource. ds0. password= root# 第二个数据库
spring. shardingsphere. datasource. ds1. type= com. zaxxer. hikari. HikariDataSource. shardingsphere. datasource. ds1. driver- class - name= com. mysql. cj. jdbc. Driver. shardingsphere. datasource. ds1. jdbc- url= jdbc: mysql: / / 127.0 .0 .1 : 3306 / xdclass_shop_order_1? useUnicode= true & characterEncoding= utf- 8 & useSSL= false & serverTimezone= Asia / Shanghai & allowPublicKeyRetrieval= true
spring. shardingsphere. datasource. ds1. username= root
spring. shardingsphere. datasource. ds1. password= root#配置workId
spring. shardingsphere. sharding. tables. product_order. key- generator. props. worker. id= 1 #配置广播表
spring. shardingsphere. sharding. broadcast- tables= ad_config
spring. shardingsphere. sharding. tables. ad_config. key- generator. column= id
spring. shardingsphere. sharding. tables. ad_config. key- generator. type= SNOWFLAKE#配置【默认分库策略】
#spring. shardingsphere. sharding. default - database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. default - database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 }
#配置分库规则
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. sharding- column= user_id
#spring. shardingsphere. sharding. tables. product_order. database- strategy. inline. algorithm- expression= ds$-> { user_id % 2 } #id生成策略
spring. shardingsphere. sharding. tables. product_order. key- generator. column= id
spring. shardingsphere. sharding. tables. product_order. key- generator. type= SNOWFLAKE# 指定product_order表的数据分布情况,配置数据节点, 行表达式标识符使用 ${ . . . } 或 $-> { . . . } ,
# 但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $-> { . . . }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$-> { 0. .1 } . product_order_$-> { 0. .1 }
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. sharding- column= id
#spring. shardingsphere. sharding. tables. product_order. table- strategy. inline. algorithm- expression= product_order_$-> { id % 2 } # 指定product_order_item表的分片策略,分片策略包括【分片键和分片算法】
#spring. shardingsphere. sharding. tables. product_order_item. actual- data- nodes= ds$-> { 0. .1 } . product_order_item_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. sharding- column= product_order_id
#spring. shardingsphere. sharding. tables. product_order_item. table- strategy. inline. algorithm- expression= product_order_item_$-> { product_order_id % 2 } #配置绑定表
#spring. shardingsphere. sharding. binding‐tables[ 0 ] = product_order, product_order_item#精准分片- 水平分表
# 指定product_order表的数据分布情况,配置数据节点, 在 Spring 环境中建议使用 $-> { . . . }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds$-> { 0. .1 } . product_order_$-> { 0. .1 }
#spring. shardingsphere. sharding. tables. product_order. actual- data- nodes= ds0. product_order_$-> { 0. .1 } #指定精准分片算法( 水平分库) 根据user_id分库
#spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. sharding- column= user_id
#spring. shardingsphere. sharding. tables. product_order. database- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomDBPreciseShardingAlgorithm( 水平分表) 根据订单id分表
#spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. sharding- column= id
#spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. precise- algorithm- class - name= com. dss. sharding. strategy. CustomTablePreciseShardingAlgorithm( 水平分表)
#spring. shardingsphere. sharding. tables. product_order. table- strategy. standard. range- algorithm- class - name= com. dss. sharding. strategy. CustomRangeShardingAlgorithm, order_id, user_id 同时作为分片健
spring. shardingsphere. sharding. tables. product_order. table- strategy. complex. sharding- columns= user_id, id
spring. shardingsphere. sharding. tables. product_order. table- strategy. complex. algorithm- class - name= com. dss. sharding. strategy. CustomComplexKeysShardingAlgorithm1. 这种分⽚策略⽆需配置⽂件进⾏配置分⽚健,分⽚健值也不再从 SQL中解析,外部⼿动指定分⽚健或分⽚库,让 SQL在指定的分库、分表中执⾏.
2. 通过Hint代码指定的⽅式⽽⾮SQL解析的⽅式分⽚的策略.
3. Hint策略会绕过SQL解析的,对于这些⽐较复杂的需要分⽚的查询,Hint分⽚策略性能可能会更好.
4. 可以指定sql去某个库某个表进⾏执⾏
(⾃定义完算法只实现了⼀部分,需要在调⽤ SQL 前通过HintManager 指定分库、分表信息)
package com. dss. sharding. strategy ; import org. apache. shardingsphere. api. sharding. hint. HintShardingAlgorithm ;
import org. apache. shardingsphere. api. sharding. hint. HintShardingValue ; import java. util. ArrayList ;
import java. util. Collection ; public class CustomTableHintShardingAlgorithm implements HintShardingAlgorithm < Long > { @Override public Collection < String > doSharding ( Collection < String > , HintShardingValue < Long > ) { Collection < String > = new ArrayList < > ( ) ; for ( String datasourceName: dataSourceNames) { for ( Long shardingValue : hitShardingValue. getValues ( ) ) { String value = shardingValue % dataSourceNames. size ( ) + "" ; if ( datasourceName. endsWith ( value) ) { result. add ( datasourceName) ; } } } return result; }
}