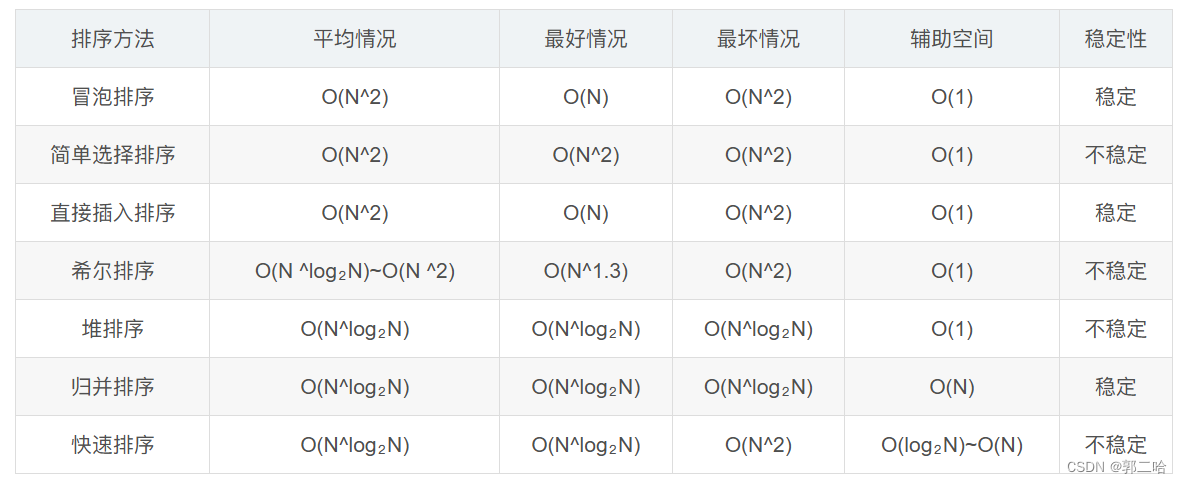
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
语法参考
在Python2.6之后,提供了字符串的format()方法对字符串进行格式化操作。format()功能非常强大,格式也比较复杂,具体语法分解如下:
{参数序号: 格式控制标记}.format(*args,**kwargs)
l 参数序号:参数序号其实是位置参数或关键字参数传递过来的参数变量,对参数序号进行格式控制标记设置其实就是对位置参数或关键字参数进行格式化处理。参数序号可以为空值,为空值时一定对应的是位置参数,并且在顺序上和位置参数一一对应。
l 格式控制标记:用来控制参数显示时的格式,和format()函数的format_spec参数是一样的,包括:<填充><对齐><宽度>,<.精度><类型>6 个字段,这些字段都是可选的,可以组合使用。参数序号和格式设置标记用大括号({})表示,可以有多个。{}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值
l *args:位置参数,是一个元组,可以为多个值。其和参数序号在位置上是一一对应的,数量上是一致的。
l **kwargs是关键字参数,是一个字典,其通过序号和参数序号进行对应,可以一对一,也可以一对多。使用关键字参数时,参数序号和关键字参数不一定数量一致。
如图1所示为通过位置参数或关键字参数进行格式化处理的流程。

图1 格式化处理的流程
下面具体介绍如何通过位置参数或关键字参数进行格式化操作。
其中,参数序号为传入的参数,格式设置模板是一个由字符串和格式控制说明字符组成的字符串,用来对传入的参数进行格式化设置。格式设置模板用大括号({})表示,可以有多个,其对应format()方法中逗号分隔的参数。
常量可以是符号、文字,甚至是一段话,根据程序开发需要进行设置。灵活使用常量,可以更大范围发挥format()方法的功效。
索引序号与参数映射
'{索引序号: 格式控制标记}'.format(*args,**kwargs)
l args是位置参数,是一个元组
l kwargs是关键字参数,是一个字典
l {}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值
(1)通过位置参数映射
就是按照位置顺序用位置参数替换前面的格式字符串的占位符。位置参数按照序号匹配,关键字参数按照名称匹配(注:按照位置填充,大括号只是占位符注,一一对应,按照位置输出结果)
l 索引序号为空
如果索引序号为空,索引序号与位置参数按照从左到右的顺序上可以建立映射,实现对传入参数的格式化处理。如索引序号和格式设置标记均为空值时,直接输出位置参数。代码如下:
'{}'.format('中国') # 输出为“中国”
位置参数与索引序号对应关系如图2所示。
![]()
图2 位置参数与索引序号对应关系
位置参数可以为两个或更多,其对应的索引序号也应该和位置索引一一对应。如果索引序号和格式设置标记均为空值时,其实就是直接连接位置参数的字符串。如通过format()方法连接字符串 “中国”、“1949”及“70”,代码如下:
'{}{}'.format('中国','1949') # 输出为“中国1949”
'{}{}{}'.format('中国','1949','70') # 输出为“中国194970”
位置参数对应关系如图3和图4所示。
![]()
图3 传递两个参数的情况
![]()
图4 传递三个参数的情况
通过常量可以直接连接或修饰各个序号索引之间的关系,如分别通过字符串常量“:”和“«««««”连接“中国“、”1949” 及“70”,代码如下:
'{}:{}:{}'.format('中国','1949','70') # 输出为“中国:1949:70”
'{}«««{}«««{}'.format('中国','1949','70') # 输出为“中国«««1949«««70”
通过常量连接或修饰各个序号索引之间的关系如图5所示。

图5 通过常量连接或修饰各个序号索引之间的关系
可以通过不同的汉字常量对位置参数进行修饰,如通过“建国于”、“到2019年已经” 、“年”连接“中国“、”1949” 及“70”,代码如下:
'{}建国于{}年,到2019年已经{}年!'.format('中国','1949','70')
输出为:
中国建国于1949年,到2019年已经70年!
通过不同的汉字常量对位置参数进行修饰的对应关系如图6所示。

图6 通过不同的汉字常量对位置参数进行修饰
l 索引序号不为空(同一个参数可以填充多次)
如果索引序号不为空,可以通过设置索引序号内的值和位置参数的索引值进行对应,即通过{n}对位置参数索引为n的值进行对应,从而实现对传入的位置参数进行格式化处理。如格式化2019年世界500强企业名单的第一名,代码如下:
'排名:{0} 企业:{1} 收入:{2} 利润:{3}'.format('1','沃尔玛','5144.05','66.7')
使用print()函数输出结果如下:
排名:1 企业:沃尔玛 收入:5144.05 利润:66.7
索引序号和位置参数不一定要按照这顺序一一对应,可以根据程序需要对索引序号内的位置索引进行设置,本例的索引序号和位置参数是一一对应的,对应关系如图7所示。

图7 索引序号和位置参数的对应关系
改变索引序号的,可以通过设置索引序号和位置参数的索引值对应,即通过{n}对位置参数索引为n的值进行对应,从而实现对传入的位置参数进行格式化处理。如格式化2019年世界500强企业名单的第一名,代码如下:
'企业:{1} 收入:{2} 排名:{0}'.format('1','沃尔玛','5144.05','66.7')
使用print()函数输出结果如下:
企业:沃尔玛 收入:5144.05 排名:1
本例索引序号和位置参数是非对应的,位置参数“沃尔玛”的索引为1,位置参数“5144.06”的索引为2,位置参数“1”的索引为0,根据程序需要将相应的索引值通过索引序号进行了对应,如图8所示。
![]()
图8 索引值和索引序号的对应关系
索引序号的值可以重复,即多个索引序号的值可以是同一个位置参数的索引。如输出2018年和2019年世界500强企业名单的第一名企业沃尔玛,代码如下:
'2018:{0} 收入:{2} 2019:{0} 收入:{1}'.format('沃尔玛','5144.05','5003.43')
位置参数“沃尔玛”的索引为0,位置参数“5144.06”为2019年的收入(亿美元),位置参数“5003.43”为2018年的收入。在代码中,位置参数“沃尔玛”的索引为0在索引序号引用了两次,如图9所示。
![]()
图9 位置参数与索引序号的对应关系
同一个位置参数可以填充多次,下面是索引序号和位置参数进行映射的示例:
print('{0}, {1}, {2}'.format('I', 'B', 'M')) # 输出结果为:I, B, M
print('{}, {}, {}'.format('I', 'B', 'M')) # 输出结果为:I, B, M
print('{2}{2}{0}{1}{1}'.format('I', 'B', 'M')) # 输出结果为:MMIBB
print('{0}{1},{0}{2}'.format('I','B','M')) # 输出结果为:IB,IM
print('{2}{1}{0}-{0}{1}{2}'.format('I', 'B', 'M')) # 输出结果为:MBI-IBM
如果位置参数不确定,也可以使用“*args”形式的位置参数来进行映射,*args可以将*号后面的字符串拆解成一个一个元素,如*'IBM',将“IBM”拆解成'I','B','M',下面代码实现的效果是一样的。
print('{2}, {1}, {0}'.format(*'IBM')) # 输出 M, B, I
print('{2}, {1}, {0}'.format('I', 'B', 'M')) # 输出 M, B, I
位置参数的值可以来自元祖或表,然后使用“*args”形式的位置参数来进行映射,如:
mingri=['www','mingrisoft','com']
print('{0}.{1}.{2}'.format(*mingri)) # 输出结果为:www.mingrisoft.com
如果索引序号设置字符串过长,可以使用变量代替索引序号设置字符串,如:
order='排名:{} 企业名称:{} 营业收入:{}万美元 利润:{}万美元'
print(order.format('1','沃尔玛','51440500','667000'))
输出结果为:
排名:1 企业名称:沃尔玛 营业收入:51440500万美元 利润:667000万美元
(2)通过关键字参数映射(关键字参数或命名参数)
索引序号按照关键字参数名称进行映射,kwargs是关键字参数,是一个字典{xxx}表示在关键字参数中搜素名称一致的。将元祖或字典打散成关键字参数给函数(通过和*或者**)format(),进行非常灵活的映射关系。
print('产品:{name}价格:{price}'.format(spec='6G+128G',name='Mate20',price=3669)) print('***{name}***, {price} '.format(spec='6G+128G',name='Mate20',price=3669))
user = {'net':'双4G','name':'Mate 20','price':3669,'spec':'6GB+128G'}
print('{name},{net},{spec},{price}'.format(**user))
输出结果为:
产品:Mate20价格:3669
***Mate20***, 3669
Mate 20,双4G,6GB+128G,3669
位置参数和关键字参数可以混合使用,如:
print('{server}.{1}.{0}'.format('com','mingrisoft',server= 'www'))
输出结果为:
www.mingrisoft.com
(3)通过元素进行映射
对于一些需要在字符串或元祖中截取部分元素进行格式化处理的情况,可以使用切片技术,但只能单个元素提取,如0[1],0[2],不能截取多个元素,如0[0:3],0[:2]等。(说明,0[1]查找位置参数索引为0 的元组中索引为1的元素)。代码举例如下:
print('{0[1]}--{0[0]}'.format(('猛龙','01')))
print('{0[0]}.{0[1]}.{0[2]}'.format(['www','mingrisoft','com']))
print('{0[2]}.{0[1]}.{0[0]}'.format('张三丰'))
print('{0[0]} {0[1]} {0[2]}'.format('www.mingrisoft.com'.split('.')))
输出结果如下:
01--猛龙
www.mingrisoft.com
丰.三.张
www mingrisoft com
在对元素进行格式化时,利用转义符可以对格式化的数据进行灵活的操作,如分别连接元祖中的数据,使用“\n”转义符实现分行对NBA球队进行输出。代码如下:
print('{0[1]}--{0[0]}\n{1[1]}--{1[0]}'.format(('猛龙','01'),('勇士','02')))
输出结果如下:
01--猛龙
02--勇士
print('{0[1][1]}\n{0[0][1]}'.format((('www','mingrisoft','com'),('www','huawei','com'))))
输出结果如下:
huawei
mingrisoft
可以对不同元祖中的对应元素进行提取,实现相应数据的对应输出。如提取元祖中网址中的网址信息,代码如下:
print('{0[1]}、{1[1]}'.format(('www','mingrisoft','com'),('www','huawei','com')))
mingrisoft、huawei
(4)通过组合映射
在格式化数据时,可以根据位置参数或关键字参数的制定元素,通过索引序号进行灵活的数据组合映射,以达到程序的需要。如将两个元祖中的元素组合,格式化输出三大互联网公司,代码如下:
print('{1[0]}{0[0]}\n{1[1]}{0[1]}\n{1[1]}{0[2]}\n{1[0]}{0[3]}'.format(('阿里巴巴','亚马逊','谷歌','腾讯','IBM'),('中国','美国')))
输出结果为:
中国阿里巴巴
美国亚马逊
美国谷歌
中国腾讯
也可以将多个未知参数中的元素进行组合,如将姓名等位置参数进行组合,生成新的姓名字符串,代码如下:
print('{0[0]}{1[0]}{2[0]}'.format('张王李赵','世常明延','国成微远'))
输出结果如下:
张世国
(5)通过元祖映射
通过元祖可以很好地实现索引序号与格式化数据的映射,如:
list = ['明日科技', 'www.mingrisoft.com']
print("公司名称:{0[0]}, 网址:{0[1]}".format(list)) # "0" 对应字典的索引值
info= ['joy', 22, '1.73']
print('My name is {0[0]}, age is {0[1]}, height is {0[2]}'.format(info))
film= (('复仇者联盟4:终局之战',8.6,2019,2793),('阿凡达',8.7,2009,2788),('泰塔尼克号',9.4,1997,2187))
print( '票房最高: {0[0][3]}, 评分最高: {0[2][1]},最新发行:{0[0][2]}'.format(film))
data = [4, 8, 15, 16, 23, 42]
print('{d[4]} {d[5]}'.format(d=data))
输出结果为:
公司名称:明日科技, 网址:www.mingrisoft.com
My name is joy, age is 22, height is 1.73
票房最高: 2793, 评分最高: 9.4,最新发行:2019
(6)通过字典映射
利用字典进行映射是比较常用的格式化操作的方法,可以通过字典的参数的items访问。
info= {'name': 'joy', 'age': 22, 'height':1.68}
print('name : {0[name]}, age :{0[age]}, height: {0[height]}'.format(info))
order= {'a001': 'joy', 'a002': 'jack', 'a003':'may', 'a004':'jobs'}
fatstr='{0['+random.choice((',').join(info).split(','))+']}'
print(fatstr.format(order))
person = {'name': 'joy', 'age': 22}
print('{p[name]} {p[age]}'.format(p=person))
输出结果为:
name : joy, age :22, height: 1.68
joy
joy 22
元祖和字典都支持命名占位符,如:
data = {'a001': '英国SAS', 'b001': '美国三角洲部队','c001': '俄罗斯阿尔法部队'}
print('{b001} {c001}'.format(**data))
输出结果为:
美国三角洲部队 俄罗斯阿尔法部队
(7)通过循环嵌套映射
通过循环语句可以批量循序建立映射关系,如下批量建立虚拟姓名:
new=('张王李赵','世常明延','国成微远')
for i in range(4):
print('{0}{1}{2}'.format(new[0][i],new[1][i],new[2][i]))
class Plant(object):
type = 'tree'
kinds = [{'name': 'oak'}, {'name': 'maple'}]
print('{p.type}: {p.kinds[0][name]}'.format(p=Plant()))
输出结果为:
张世国
王常成
李明微
赵延远
tree: oak
(8)通过传入对象映射
class Person:
def __init__(self,name,age):
self.name,self.age = name,age
def __str__(self):
return '我叫{self.name}, 今年{self.age}岁了'.format(self=self)
print(str(Person('joy', 22)))
输出结果为:
我叫joy, 今年22岁了
(9)灵活应用占位符
print('{0:{fill}{align}12}'.format("python", fill='#', align='^'))
for num in range(1,6):
for base in "dXob":
print("{0:{width}{base}}".format(num, base=base, width=6), end=' ')
print()
输出结果为:
###python###
1 1 1 1
2 2 2 10
3 3 3 11
4 4 4 100
5 5 5 101
格式化模板标签
'{索引序号: 格式控制标记}'.format(*args,**kwargs)
本节重点讲解格式控制标记,格式控制标记用来控制参数显示时的格式,包括:<填充><对齐><宽度>,<.精度><类型>6 个字段,这些字段都是可选的,可以组合使用。其对应关系如图10所示。

图10 格式控制标记与显示格式的对应关系
格式模板中的格式标记符即可以简单、快速对数据进行格式化处理,也可以进行复杂的自动化处理和计算。
1)fill,可选参数,指”width”内除了参数外的字符采用什么方式表示,默认采用空格,可以通过<填充>更换,填充字符只能有一个。
s = "PYTHON"
print("{0:30}".format(s))
print("{0:>30}".format(s))
print("{0:*^30}".format(s))
print("{0:-^30}".format(s))
print("{0:3}".format(s))
输出结果为:
PYTHON
PYTHON
************PYTHON************
------------PYTHON------------
PYTHON
print("{a:*^8}".format(a="mr")) # 输出***mr***
print("{:0>8}".format("866"))
print("{:$>8}".format("866"))
print("{:0>8}".format("866"))
print("{:-<8}".format("866"))
#中间对齐方式中如果出现字符两侧无法平均分配填充符,字符后填充符可以多填充
print("{:-^8}".format("866"))
print("{:*<30}>".format("www.mingrisoft.com"))
输出结果为:
***mr***
00000866
$$$$$866
00000866
866-----
--866---
www.mingrisoft.com************>
2)align,可选参数,可供选择的值有:<,>,^或=。指参数在<宽度>内输出时的对齐方式,分别使用<、>、^和=表示左对齐、右对齐、居中对齐和在符号后进行补齐。需要注意的是,如果align参数为空,对于字符串,默认左对齐。对于数字,默认右对齐。
l < (如果是字符串,默认左对齐)左对齐
l ^ 中间对齐
l > (如果是数字,默认右对齐)右对齐
l = (只用于数字)在符号后进行补齐
print("{:10}".format('18'))
print("{:10}".format(18))
print("{:<10}".format('18'))
print("{:<10}".format(18))
print("{:>10}".format('18'))
print("{:0>10}".format('18'))
print('{:A>10}'.format('18'))
print("{:^10}".format('18'))
print('{:0=10}'.format(-18))
print('{:0<10}'.format(-18))
print('{:0>10}'.format(-18))
print('{:0=10}'.format(18))
输出结果为:
18
18
18
18
18
0000000018
AAAAAAAA18
18
-000000018
-180000000
0000000-18
0000000018
注意:zfill()方法也可以返回指定长度的字符串,原字符串右对齐,前面填充0。
zfill()方法语法:str.zfill(width)
参数width指定字符串的长度。原字符串右对齐,前面填充0。
返回指定长度的字符串。
print("11".zfill(5))
结果输出为:
00011
3)sign,可选参数,sign可以使用 "+" | "-" | " "。+表示正号, -表示负号宽度指当前槽的设定输出字符宽度,如果该槽参数实际值比宽度设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则按照对齐指定方式在宽度内对齐,默认以空格字符补充。
s = 3.1415926
t=-3.1415926
print("{:+25}".format(s)) #左对齐,默认
print("{:^25}".format(s)) #居中对齐
print("{:>-25}".format(s)) #右对齐
print("{:*^ 25}".format(t)) #居中对齐且填充*号
print("{:+^25}".format(t)) #居中对齐且填充+号
print("{:十^25}".format(t)) #居中对齐且填充汉字“十”
print("{:^+1}".format(t)) #z指定宽度为1,不足变量s的宽度
输出结果为:
+3.1415926
3.1415926
3.1415926
*******-3.1415926********
+++++++-3.1415926++++++++
十十十十十十十-3.1415926十十十十十十十十
-3.1415926
4)#和0,可选参数,#为进制标志,对于进制数,在进制符前加#,输出时会带上进制前缀,即显示0b,0o,0x。0为填充0,设置width时,没设填充值,加上0,填充0指定位置用0填充。如:
print("{:0>5}".format('18'))
print("{:#x}".format(50)) # 在进制符前加#,输出时会带上进制前缀
print("{:#o}".format(12)) # 在进制符前加#,输出时会带上进制前缀
print("{:#b}".format(22)) # 在进制符前加#,输出时会带上进制前缀
print("{:>#8x}".format(50)) # 在进制符前加#,输出时会带上进制前缀
print("{:=#10o}".format(12)) # 在进制符前加#,输出时会带上进制前缀
输出结果为:
00018
0x32
0o14
0b10110
0x32
0o 14
5)Width,可选参数, integer 是数字宽度,表示总共输出多少位数字。通常和align参数配合使用,示例如下:指当前槽的设定输出字符宽度,如果该槽对应的format()参数长度比<宽度>设定值大,则使用参数实际长度。如果该值的实际位数小于指定宽度,则位数将被默认以空格字符补充。如:
print('%+6s' % '明日') # 字符串左对齐
print('%+6d' % -3.14) # 格式化为整数,左对齐
print('%-6s' % '明日') # 字符串左对齐
print('%-6d' % -3.14) # 格式化为整数,左对齐
print('% 6s' % '明日') # 字符串左对齐
print('%06d' % 3.14) # 格式化为整数,左对齐
输出结果为:
明日
-3
明日
-3
明日
000003
6)千位符,千位符用逗号(,),用于显示数字的千位分隔符,例如:
print("{0:^12,}".format(31415926))
print("{0:-^12,}".format(3.1415926))
print("{0:*^12,}".format(31415.926))
输出结果为:
31,415,926
-3.1415926--
*31,415.926*
7) .precision,可选参数,设置浮点数或字符串的精度。对于浮点数来说,用于设置浮点数的精度,即小数点后保留的位数。对于字符串来说,就是截取字符串的位数。表示两个含义,由小数点(.)开头。对于浮点数,精度表示小数部分输出的有效位数。对于字符串,精度表示输出的最大长度。
print("{0:.2f}".format(12345.67890))
print("{0:H^20.3f}".format(12345.67890))
print("{0:.4}".format("PYTHON"))
结果输出为:
12345.68
HHHHH12345.679HHHHHH
PYTH
8)type,可选参数,表示获取对应类型的值并格式化到指定位置。格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,主要的格式符有:
l s,字符串 (采用str()的显示)。
l r,字符串 (采用repr()的显示)。
l c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置。
l o,将整数转换成八进制表示,并将其格式化到指定位置。
l x,将整数转换成十六进制表示,并将其格式化到指定位置。
l b 将整数转换成二进制整数,并将其格式化到指定位置。
l d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置。
l e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)。
l E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)。
l f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)。
l g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)。
l G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)。
l %,当字符串中存在格式化标志时,需要用 %%表示一个百分号。
如果类型参数未提供,则和调用str(value)效果相同,转换成字符串格式化。如:
print("{}".format(12345.67890))
print("{0:>12}".format(12345.67890))
结果输出为:
12345.6789
12345.6789
对于字符符串类型,可以提供的参数有 's'
print("{:s}".format('3.1415926'))
print("{0:>12s}".format('mingri'))
print("{0:>12s}\n{1:>6s}".format('mingri','mr'))
结果输出为:
3.1415926
mingri
mingri
mr
整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None,如:
print("{:c}".format(1221))
print("{:4d}".format(3145926))
print("{:b}".format(31))
print("{:o}".format(31))
print("{:x}".format(31))
print('{0:o} :{0:x}:{0:o}'.format(31))
结果输出为:
Ӆ
3145926
11111
37
1f
37 :1f:37
#浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None
print('{:e}'.format(314159267)) #科学计数法,默认保留6位小数
print('{:0.2e}'.format(314159267)) #科学计数法,指定保留2位小数
print('{:f}'.format(314159267)) # 小数点计数法,默认保留6位小数
print('{:0.2f}'.format(314159267)) #小数点计数法,指定保留2位小数
print('{0:0.2f}\n{0:0.8f}'.format(314159267)) #小数点计数法,指定保留小数位数
print('{:0.2F}'.format(314159267)) #小数点计数法,指定保留2位小数
print('{0:0.2F}\n{0:0.8f}'.format(314159267)) #小数点计数法,指定小数位数
结果输出为:
3.141593e+08
3.14e+08
314159267.000000
314159267.00
314159267.00
314159267.00000000
314159267.00
314159267.00
314159267.00000000
#g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数。
print('{:1g}'.format(0.000031415926))
print('{:.2g}'.format(0.000031415926))
print('{:.5G}'.format(0.000031415926))
print('{:.3n}'.format(0.000031415926))
print('{:1g}'.format(3.1415926))
print('{:.2g}'.format(3.1415926))
print('{:.5G}'.format(3.1415926))
print('{:.3n}'.format(3.1415926))
输出结果为:
3.14159e-05
3.1e-05
3.1416E-05
3.14e-05
3.14159
3.1
3.1416
3.14

快用锦囊
锦囊1 格式转换
如果格式控制标记未提供,则默认为将其他格式数据格式化为字符型,如:
print('{}'.format(3.14)) # 使用format ()函数将浮点数转换成字符
import datetime
# 将日期格式化为字符
print('{}'.format(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S")))
输出结果为:
3.14
2019-08-01 03:34:52
设置格式化为字符型值时,可以进行相应数据类型的格式化,字符串可以提供的参数为's' 。十进制整形提供的参数为'd' 和'n',二进制的参数为'b',八进制的参数为'o',十六进制小写的参数为 'x' ,十六进制大写的参数为 'X' ,ASC码的参数为'c',浮点数的参数为'f'。主要进制转换符号说明如下:
l 'b' - 二进制。将数字以2为基数进行输出。
l 'd' - 十进制整数。将数字以10为基数进行输出。
l 'o' - 八进制。将数字以8为基数进行输出。
l 'x' - 十六进制。将数字以16为基数进行输出,9以上的位数用小写字母。
十进制、十六进制、八进制、二进制的转换示例如下:
print('{:d}'.format(100)) # 转换成字符型、整形和浮点数
print('{:s}'.format('100')) # 转换成字符型、整形和浮点数
print('{:c}'.format(97)) # 转换unicode成字符
print('{:d},{:f}'.format(100,12.2)) # 转换成整形和浮点数
print('{:8d},{:2d},{:2f}'.format(314,314,314)) # 转换成指定格式的十进制
print('{:c},{:c},{:c}'.format(65,33,8712)) # 转换成unicode字符
print('{:c}{:c}{:c}{:c}'.format(39321,26684,37324,25289)) # 转换unicode成字符
print('{:o},{:x},{:X}'.format(12,12,12)) # 将十进制转换成八进制和十六进制
输出结果为:
100
100
a
100,12.200000
314,314,314.000000
A,!,∈
香格里拉
14,c,C
如果要将十六进制、八进制、二进制的数字转换为十进制数,一定要标注进制前缀,如"0x"“0o”“0b”,示例代码如下:
print('{:d}'.format(0X5A)) # 十六进制数5A转换成10进制数,0X代表十六进制数
print('{:8d}'.format(0B011101)) # 二进制数转换成10进制数,0B代表二进制数
print('{:d}'.format(0O34)) # 八进制数转换成10进制数,0O代表八进制数
print('{:08d}'.format(0O123456)) # 16制数123456转换成10进制数,不足用0填充
print('{:*>8d}'.format(+0X1234)) # 16进制数1234转换成10进制数,右对齐,不足用*
输出结果为:
90
29
28
00042798
****4660
保留进制前缀,#为进制标志,对于进制数,在进制符前加#,输出时会带上进制前缀,即显示0b,0o,0x,示例代码如下:
print("{:#x}".format(123)) # 在进制符前加#,输出时会带上进制前缀
print("{:#o}".format(28)) # 在进制符前加#,输出时会带上进制前缀
print("{:#b}".format(15)) # 在进制符前加#,输出时会带上进制前缀
输出结果为:
0x7b
0o34
0b1111
锦囊2 格式化十进制整数
格式化整形数值可以提供的参数有’d’、 ’n’,两者相同相同。和format()函数不同,使用str.format()方法格式化数值时,被格式化的数值必须是整数,不能是浮点数。常用应用如下:
print('{:}'.format(122)) # 格式参数为空,默认为10进制
print('{:d}'.format(122)) # 原来是十进制数,转换后为原值
print('{:6d}'.format(122)) # 转换为6位十进制数,空余部分用空格填充
print('{:-6d}'.format(122)) # 转换为6位带符号十进制数,在符号前填充空余部分空格
print('{:08d}'.format(122)) # 转换为8位十进制数,空余部分填充0
print('{:+8d}'.format(122)) # 转换为8位带符号十进制数,在符号前填充空余部分空格
print('{:-8d}'.format(122)) # 转换为8位十进制数,空余部分填充空格
print('{:=8d}'.format(-122)) # 转换为8位十进制数,负号后空余部分填充空格
print('{:=8d}'.format(122)) # 转换为8位十进制数,空余部分填充空格
print('{:*<8d}'.format(122)) # 转换为8位十进制数,左对齐,空余部分填充*
print('{:#>8d}'.format(122)) # 转换为8位十进制数,右对齐,空余部分填充#
print('{:n}'.format(122)) # 原来是十进制数,转换后为原值
print('{:6n}'.format(122)) # 转换为6位十进制数,空余部分用空格填充
print('{:-6n}'.format(122)) # 转换为6位带符号十进制数,在符号前填充空余部分空格
输出结果为:
122
122
122
122
00000122
+122
122
- 122
122
122*****
#####122
122
122
122
对于整数来说,加、减、乘、除是最基本的操作,对整数进行格式化后可以直接连接成算数式。下面是一些简单的计算操作,代码如下:
print('{:d}={:2d}={:3d}'.format(122,122,122))# 8位整数显示,不足部分整数前用空格填充
print('{:4d}+{:4d}={:4d}'.format(25,10,35)) # 格式化为带符号整数显示数据
add1=[12,23,35,10,8] # 加数
add2=[7,19,6,211,790] # 被加数
for i in range(5): # 循环输出计算式
print('{:<5d}+{:5d}={:5d}'.format(add1[i],add2[i],add1[i]+add2[i])) # 加数设成左对齐
输出结果为:
122=122=122
25+ 10= 35
12 + 7= 19
23 + 19= 42
35 + 6= 41
10 + 211= 221
8 + 790= 798
锦囊3 格式化浮点数
对于浮点数类型,可以提供的格式化参数有 'e' 、'E'、 'f' 、'F'、 'g'、 'G' 、'%' 等。本锦囊主要讲解用 f 格式化浮点类型的方法。使用 f 格式化浮点类型时,可以在其前边加上精度,控制输出浮点数的值;可以设置宽度控制数字的占位宽度。如果输出位数大于宽度,就按实际位数输出,如果输出位数小于宽度,则用占位符填充不足部分;也可以为浮点数指定符号,+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格,在幅负数前加 -;- 与什么都不加({:f})时一致:{:f}默认保留6位小数。 {:。3f}表示浮点数的精度为3(小数位保留3位),{:.f}是错误,必须在小数点后书写数字。常用示例代码如下:
print('{:f}'.format(628)) # 格式化为保留1位小数的浮点数
print('{:.1f}'.format(628)) # 格式化为保留1位小数的浮点数
print('{:.2f}'.format(628)) # # 格式化为保留2位小数的浮点数
print('{:.1f}'.format(3.14159)) # 格式化为保留1位小数的浮点数
print('{:.5f}'.format(3.14159)) # 格式化为保留5位小数的浮点数
print('{:>8.3f}'.format(-3.14159)) # 格式化为保留1位小数的浮点数
print('{:<8f}'.format(3.1415926535898,'f')) # 默认精度保留6位小数
print('{:f}>{:.4f}>{:.2f}'.format(3.1415926,3.1415926,3.1415926))
print('{:2f}-{:2f}={:2f}'.format(12.2345,10,2.2345)) # 格式化为带符号整数显示数据
输出结果为:
628.000000
628.0
628.00
3.1
3.14159
-3.142
3.141593
3.141593>3.1416>3.14
12.234500-10.000000=2.234500
在计算式中,可以通过格式化统一浮点数的精度(小数位数)。通常是将浮点数格式化为包含两位小数的浮点数。下面是一些经典的应用,代码如下:
one=[3.2345,6,5.123,12.5678,21] # 计算数
two=[18.54,43.67564,3.1315,21.21,7.543] # 计算数
thr=[9.1287,1.876,6.345,21.654,7] # 计算数
str='{:.2f}{:}{:.2f}{:}{:.2f}={:.2f}'
for i in range(5): # 循环输出计算式
str=('{0:.2f}+{1:.2f}*{2:.2f}={3:.2f}')
x='{:.2f}' # 计算精度
all=float(x.format(one[i]))+float(x.format(two[i]))*float(x.format(thr[i]))
print(str.format(one[i],two[i],thr[i],all))
输出结果为:
3.23+18.54*9.13=172.50
6.00+43.68*1.88=88.12
5.12+3.13*6.34=24.96
12.57+21.21*21.65=471.77
21.00+7.54*7.00=73.78
锦囊4 格式化百分数
在格式化解释中单独或者在精度之后添加“%”号,可以实现用百分数显示浮点数,如:
print('{:%}'.format(0.161896)) # 将小数格式化成百分数
print('{:.2%}'.format(0.161896)) # 格式化为保留两位小数的百分数
print('{:.6%}'.format(0.0238912)) # 格式化为保留六位小数的百分数
print('{:.2%}'.format(2/16)) # 格式化为保留两位小数的百分数
print('{:.1%}'.format(3.1415926)) # 格式化为保留一位小数的百分数
print('{:.0%}'.format(0.161896)) # 格式化为保留整数的百分数
print('{:8.6%}'.format(0.0238912)) # 格式化为保留六位小数的八位百分数
print('{:8.3%}'.format(0.0238912)) # 格式化为保留三位小数的八位百分数
输出结果为:
16.189600%
16.19%
2.389120%
12.50%
314.2%
16%
2.389120%
2.389%
锦囊5 格式化科学记数法
如果要将浮点数采用科学技术法表示,可以在格式化解释中使用“e”和“E”或者“g”和“G”。'e' 为通用的幂符号,用科学计数法打印数字,用'e'表示幂。使用'g'时,将数值以fixed-point格式输出。当数值特别大的时候,用幂形式打印。
#####e和E
print('{:e}'.format(3141592653589)) # 科学计数法,默认保留6位小数
print('{:e}'.format(3.14)) # 科学计数法,默认保留6位小数
print('{:e}'.format(3.14,'0.4e')) # 科学计数法,默认保留6位小数
print('{:0.2e}'.format(3141592653589)) #科学计数法,保留2位小数
print('{:0.2E}'.format(3141592653589)) #科学计数法,保留2位小数,大写E表示
#####g和G
print('{:F}'.format(3.14e+1000000)) #小数点计数法,无穷大转换成大小字母
print('{:g}'.format(3141592653589)) #科学计数法,保留2位小数
print('{:g}'.format(314)) #科学计数法,保留2位小数
print('{:0.2g}'.format(3141592653589)) #科学计数法,保留2位小数,大写E表示
print('{:G}'.format(3141592653589)) #小数点计数法,无穷大转换成大小字母
print('{:g}'.format(3.14e+1000000)) #小数点计数法,无穷大转换成大小字母
输出结果为:
3.141593e+12
3.140000e+00
3.140000e+00
3.14e+12
3.14E+12
INF
3.14159e+12
314
3.1e+12
3.14159E+12
inf
锦囊6 格式化金额
format()函数提供千位分隔符用逗号还能用来做金额的千位分隔符。如果要实现通常格式化后金额前面带上相关货币的符号,需要在该函数前面手动加上相应货币符号。如:
print('${:.2f}'.format(1201398.2315)) # 添加美元符号,小数保留两位
print(chr(36) + '{:.2f}'.format(1201398.2315)) # ASCII码添加美元,小数保留两位
print( '¥{:,.2f}'.format(1201398.2315)) # 添加人民币符号,用千位分隔符进行区分
print( '£{:,.2f}'.format(888800)) # 添加英镑符号,用千位分隔符进行区分
print( '{:.2f}'.format(123.6612)) # 添加欧元符号,保留两位小数,千位分隔
print( chr(0x20ac) +'{:,.2f}'.format(1201398.2315)) # 使用16进制编码添加欧元
print(chr(36) + '{:.2f}'.format(1201398.2315))# ASCII码加美元符号,小数保留两位
输出效果为:
$1201398.23
$1201398.23
¥1,201,398.23
£888,800.00
123.66
1,201,398.23
$1201398.23
锦囊7 格式化字符
格式化字符主要包括截取字符串,字符串对齐方式显示,填充字符串等几个方面,下面举例如下:
print('{:M^20.3}'.format('PYTHON')) #截取3个字符,宽度20居中,不足用‘M’填充
print('{:10}'.format("PYTHON",'10')) # 默认居左,不足部分用‘ ’填充
print('{:.3}'.format('mingrisoft.com')) # 截取3个字符,默认居左显示
print('{:>10}'.format("PYTHON")) # 居右显示,不足部分用‘ ’填充
s='mingrisoft.com'
print('{:>20}'.format(s)) # 右对齐,不足指定宽度部分用0号填充
print('{:>4}'.format(s)) # 右对齐,因字符实际宽度大于指定宽度4,不用填充
print('{:*>20}'.format(s)) # 右对齐,不足指定宽度部分用*号填充
print('{:0>20}'.format(s)) # 右对齐,指定0标志位填充
print('{:>20}'.format(s)) # 右对齐,没指定填充值,用默认值空格填充
print('{:0^30}'.format(s)) # 居中对齐,用+号填充不足部分
结果输出为:
MMMMMMMMPYTMMMMMMMMM
PYTHON
min
PYTHON
mingrisoft.com
mingrisoft.com
******mingrisoft.com
000000mingrisoft.com
锦囊8 指定转化
转换字段 conversion field 的取值有三种,前面要加 !:
l s:传递参数之前先对参数调用 str()
l r:传递参数之前先对参数调用 repr()
l a:传递参数之前先对参数调用 ascii()
可以指定字符串的转化类型:其中 "!r" 对应 repr(); "!s" 对应 str(); "!a" 对应 ascii()。
print("repr() shows quotes: {!r}; str() doesn't: {!s}".format('mingri', 'soft'))
print("joy is a cute {!s}".format("baby")) # !s 相当于对于参数调用str()
print("joy is a cute {!r}".format("baby")) # !s 相当于对于参数调用str()
print('I am {!s}!'.format('Bruce Lee 李小龙'))
print('I am {!r}!'.format('Bruce Lee 李小龙'))
print('I am {!a}!'.format('Bruce Lee 李小龙'))
结果输出为:
repr() shows quotes: 'mingri'; str() doesn't: soft
joy is a cute baby
joy is a cute 'baby'
I am Bruce Lee 李小龙!
I am 'Bruce Lee 李小龙'!
I am 'Bruce Lee \u674e\u5c0f\u9f99'!
锦囊9 格式化日期月份
format()函数也可以对日期和时间进行格式化,格式化时可以通过日期和时间格式符号进行设置,常用python中时间日期格式化符号如表1所示。常用操作代码如下:
import datetime
now=datetime.datetime.now()
print('{:%Y-%m-%d %H:%M:%S %A}'.format(now)) # 当前时间格式化为年月日+完整英文星期
print('{:%Y-%m-%d %H:%M:%S %a}'.format(now)) # 当前时间格式化为年月日+简写英文星期
# 中文年月日显示
print('{:%Y}'.format(now),'年','{:%m}'.format(now),'月','{:%d}'.format(now), '日')
# 中文时间显示
print('{:%H}'.format(now),'时','{:%M}'.format(now),'分','{:%S}'.format(now), '秒')
print('{:%Y-%m-%d %H:%M:%S %a}'.format(now)) # 当前时间格式化为年月日+简写英文星期
print('{:%Y-%m-%d}'.format(now)) # 当前时间格式化为标准年月日
print('{:%y-%m-%d}'.format(now)) # 当前时间格式化为短日期年月日
print('{:%Y<%m>%d}'.format(now)) # 当前时间格式化为长日期年月日, 间隔符为“<”和“>”
print('{:%c}'.format(now)) # 本地对应的年月日星期表示
输出结果为:
2019-09-15 20:37:42 Sunday
2019-09-15 20:37:42 Sun
2019 年 09 月 15 日
20 时 37 分 42 秒
2019-09-15 20:37:42 Sun
2019-09-15
19-09-15
2019<09>15
Sun Sep 15 20:37:42 2019
import datetime
now=datetime.datetime.now()
print('{:%B}'.format(now)) # 本地完整的英文月份表示
print('现在是今年第{:%j}天'.format(now)) # 今天是一年中第几天
print('本周是今年第{:%U}周'.format(now)) # 本周是一年中第几周
print('{:%y%m%d}'.format(now)) # 无间隔符短年月日
print('{:%Y-%m}'.format(now)) # 长日期格式年月
print('{:%m-%d}'.format(now)) # 月日显示、
print('{:%m}'.format(now)) # 月份单独显示
print('{:%d}'.format(now)) # 日期单独显示
输出结果为:
September
现在是今年第258天
本周是今年第37周
190915
2019-09
09-15
09
15
import datetime
now=datetime.datetime.now()
print('{:%H%M%S}'.format(now)) # 时分秒。无间隔符
print('{:%H:%M:%S}'.format(now)) # 标准时分秒
print('{:%H:%M:%S %I}'.format(now)) # 12小时制 时分秒
print('{:%H:%M}'.format(now)) # 时+分
print('{:%M%S}'.format(now)) # 时钟+分
print('{:%h}'.format(now)) # 只显示时钟点
print('{:%H:%M:%S %p}'.format(now)) # 日期显示按AM,PM显示
输出结果为:
205140
20:51:40
20:51:40 08
20:51
5140
Sep
20:51:40 PM
import datetime
now=datetime.datetime.now()
print('{:%a}'.format(now)) # 英文星期简写
print('{:%A}'.format(now)) # 英文星期完整显示
week=['星期日','星期一','星期二','星期三','星期四','星期五','星期六']
print(week[int('{:%w}'.format(now))]) # 中文星期
输出结果为:
Sun
Sunday
星期日
import datetime
dt = datetime.datetime(2019, 9, 9)
dm=datetime.datetime(2019, 9, 9, 12, 50,20)
# 将输入的日期按年月日和时间格式化,因时间没有输入,按0时处理
print('{:%Y-%m-%d %H:%M:%S}'.format(dt))
print('{:%Y-%m-%d}'.format(dt)) # 将输入的日期按年月日格式化
print('{:%Y-%m-%d %H:%M:%S}'.format(dm)) # 将输入的日期按年月日和时间格式化
输出结果为:
2019-09-09 00:00:00
2019-09-09
2019-09-09 12:50:20
import datetime
now=datetime.datetime.now()
print('{0:%Y%m%d}{1:03d}'.format(now,1)) # 年月日 +3位编号
print('{0:%Y%m%d}NO{1:03d}'.format(now,5)) # 年月日+NO+3位编号
print('{0:%d}NO{1:05d}'.format(now,8)) # 日期+NO+5位编号
print('{0:%H%M}NO{1:05d}'.format(now,8)) # 时钟+分 +NO+5位编号
for i in range(5): # 循环输出计算式
print('{0:%Y%m%d}NO{1:05d}'.format(now,i+1))
输出结果为:
20190915001
20190915NO005
15NO00008
2135NO00008
20190915NO00001
20190915NO00002
20190915NO00003
20190915NO00004
20190915NO00005
锦囊10 数据对齐
在输出数据时,数据对齐的工整程度和数据之间的间距非常影响用户的阅读感受,如下面的2019年世界500强企业排行,如图11所示,数据间距过小,后面的数据也没有对齐,阅读感受不是很好。

图11 原数据阅读感较差
通过制表符“\t”,利用format()方法设置对齐字符串的宽度和对齐方式,可以很容易排列对齐数据,下面对世界500强企业进行对齐输出(数据保存在源文件目录下500.txt文件中),代码如下:
with open("500.txt", 'r') as fp:
lines=fp.readlines()
for line in lines:
list=line.strip().split(' ')
str=''
for item in list:
str=str +'\t{:10}'.format(item)
print(str)
运行程序,输出结果如图12所示,从图中可以看到数据对齐比较工整,能较好地浏览数据。

图12 设置玩对齐的效果
对于常规的数据,使用通过制表符“\t”和通过format()方法设置宽度和对齐方式就可以很好地实现对齐,但对于中文字段较多,字段较长的数据,如果设置文字宽度不合适,就很容出现文字不对齐的情况,如输出2018年全球大学排名前20名,代码如下:
with open("dx.txt", 'r') as fp:
lines=fp.readlines()
for line in lines:
list=line.strip().split(',')
str='\t{:0>2}'.format(list[0])+'\t{:<6}'.format(list[1])+'\t{0:<16}'.format(list[2])+'\t{:<40}'.format(list[3])
print(str)
运行程序,输出效果如图13所示。

图13 汉字字段较多时不对齐
从图13可以看到,输出的一些数据没有对齐,主要问题是utf-8中中文占用3个字节,GBK中占用了2个字节,英文字符占用一个字节,所以设置文字宽度时统一按英文文字占用一个1字节设置就会造成文字宽度不一致的情况。如果设置中文字段宽度时宽度不够时采用中文空格编码chr(12288)填充,就可以很好地解决这个问题,代码如下:
with open("dx.txt", 'r') as fp:
lines=fp.readlines()
for line in lines:
list=line.strip().split(',')
str='\t{0:0>2}'.format(list[0])+'\t{0:{1}<5}'.format(list[3],chr(12288))+'\t{0:{1}<10}'.format(list[1],chr(12288))+'\t{0:<45}'.format(list[2])
print(str)
运行程序,输出效果如图14所示

图14 设置对齐的效果
锦囊11 生成数据编号
对数据进行编号,也是对字符串格式化操作的一种方式,设置填充字符(编号通常设置0),设置对齐方式时可以使用<、>和^符号表示左对齐、右对齐和居中对齐,对齐填充的符号在“宽度”范围内输出时填充,如:
print('{:0>3}'.format(1))
print('{:0>5}'.format('03'))
print('a{:0>6}'.format(111))
输出结果为:
001
00003
a000111
要生成的编号通常比较复杂,如根据当天的日期建立编号,或者批量生成编号,或者将给定的批量数据中的数字转换成位数固定的编号,下面给出实现如上编号的实现方法:
import datetime
wx=datetime.datetime.now().date()
now=datetime.datetime.now()
print(str(wx)+'{:0>3}'.format(1)) # 年月日 +3位编号
print('{:%Y%m%d}{:0>3}'.format(now,1)) # 年月日 +3位编号
print('{:%Y%m%d}NO{:0>5}'.format(now,5)) # 年月日+NO+3位编号
print('{:%Y}NO{:0>5}'.format(now,5)) # 日期+NO+3位编号
print('{:%H%M}NO{:0>3}'.format(now,5)) # # 时钟+分 +NO+3位编号
输出结果为:
2019-08-01001
20190801001
20190801NO00005
2019NO00005
1155NO005
20190801 NO001
01 NO001
1155 NO001
for i in range(1,6):
print('mr{:0>3}'.format(i))
mr001
mr002
mr003
mr004
mr005
要实现嵌套编号,如A001-A005,B001-B005,C001-005的嵌套编号。代码如下:
for i in range(65,69):
for j in range(1,6):
data=chr(i)+'{:0>3}'.format(j)+' '
print(data,end='')
print()
结果输出如下:

锦囊12 format的索引序号作为函数变量
Format()的索引序号可以在Format()的位置参数或关键字参数中给定,也可以把索引序号作为函数变量,动态添加,如对输入的数字格式化为5位编号,编写函数mark,变量num作为索引序号,调用时直接赋值给num变量即可,实现代码如下:
mark = "编号:{num:0>5d}".format
print(mark(num=3))
输出结果为:
编号:00003
调用mark函数可以实现批量输出格式化的编号,如输出10个5位编号,编号从0001到00009,代码如下:
mark = "编号:{num:0>5d}".format
for i in range(10):
print(mark(num=i))
输出结果为:
编号:00000
编号:00001
编号:00002
编号:00003
编号:00004
编号:00005
编号:00006
编号:00007
编号:00008
编号:00009
锦囊13 {}内嵌{}
格式化标签模板中的格式设置参数也可以通过str.Format()方法的位置参数或关键字参数给定,但必须放在{}里面,如通过{}内嵌{}将位置参数2的值设置位置参数1(3.1415926)的小数位数为2,则格式化模板为{0:>.{1}f},其中{1}指定的是第2个位置参数2。代码如下:
print('{0:>.{1}f} '.format(3.1415926,2)) # {1}对应位置参数2
输出结果为:
3.14
通过{}内嵌{}在批量处理数据时非常有用,可以方便的设置变量,不用按个修改模板参数中的值,如输出9*9的乘法口诀,可以设置输出口诀元素的宽度,如设置long为‘1d’或‘2d’,把long设置为位置参数即可。代码如下:
long='1d'
for i in range(1,10):
for j in range(1,10):
print("{0:<{3}}*{1:>{3}}={2:{3}}".format (i,j,i*j,long),end=" ")
print("")
运行程序,如图15所示,因为设置元素宽度为1个宽度,所以输出效果不是很整齐。修改第一行代码中的long='2d',运行程序,如图16所示,运行效果就比较整齐了。

图15 long为‘1d’的运行效果

图16 long为‘2d’的运行效果
锦囊14 format变形
可以简化为f'xxxx'形式,在字符串前加f以达到格式化的目的,在{}里加入对象,如下面的代码:
print('{0} {1}'.format('hello','world'))
可以简化为:
a = 'hello'
b = 'world'
print(f'{a} {b}')
运行结果如下:
hello world
hello world