前置需求
- 需求
- 已经有50亿个电话号码,现在给出10万个电话号码,如何快速准确地判断这些电话号码是否已经存在?
- 参考方案
- 通过数据库查询:比如MySQL,性能不行,速度太慢
- 将数据先放进内存:50亿*8字节=40GB,内存占用太大
- hyperloglog算法:准确度不行
- 现实类似问题
- 垃圾邮件判断
- 文字处理软件的错误单词检测
- 网络爬虫的url去重
- 解决方法
- 使用布隆过滤器
布隆过滤器介绍以及原理
-
布隆过滤器作用
- 占用很少的空间和使用较少的时间判断一个小数据集是否是一个大数据集的子集
-
布隆过滤器参数
- n:一个很长的二进制,n位
- m:需要放入的数据数量,m个
- k:k个哈希函数
-
布隆过滤器构建过程
-
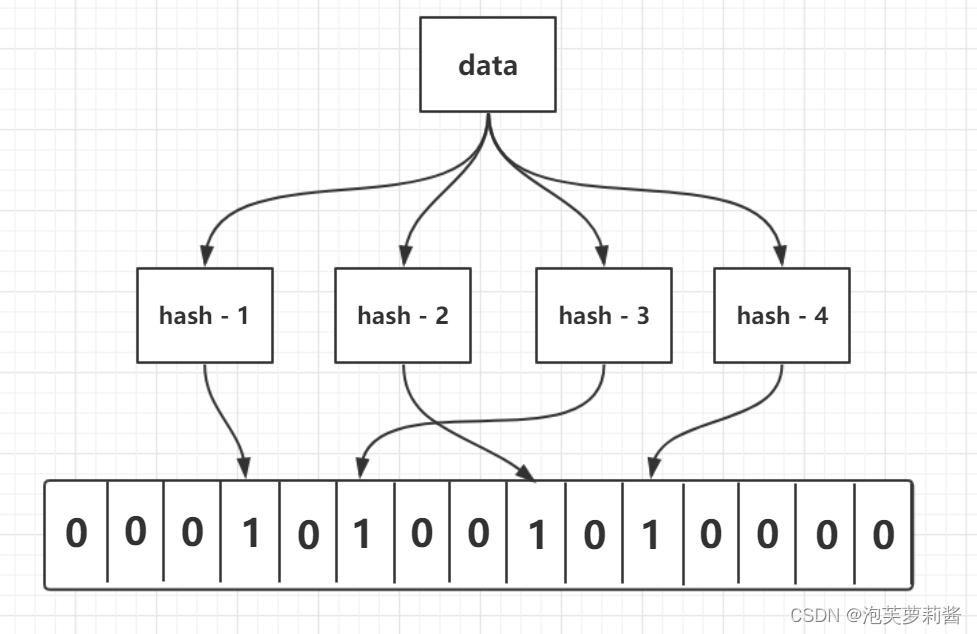
初始化:原始二进制数字中的每一位都置为0
-
一个数据经过1个哈希函数会得到一个位置,该位置置1
-
一个数据经过k个哈希函数处理会,在原理二进制中会有k个位置被置1
-
所有数据重复以上两步,即可构建出对于这个数据集的布隆过滤器
-
-
布隆过滤器判断有无
- 一个数据经过k个哈希函数处理,查看得到的位置是否都为1,如果有至少一个位置不为1,则证明这个数据不在数据集中,反之,这个数据很大可能在这个数据集中(因为存在误差)
-
布隆过滤器的误差
-
误差可能存在
- 一个数据并未参数构建布隆过滤器,但是它的计算结果可能会“已经存在”,比如当只用1个哈希函数或者二进制数很短时,可能别的数据的结果刚好与整个数据相同,于是这个数据也被当做存在了
- 已有的数据一定显示已有,未有数据可能”已有“
-
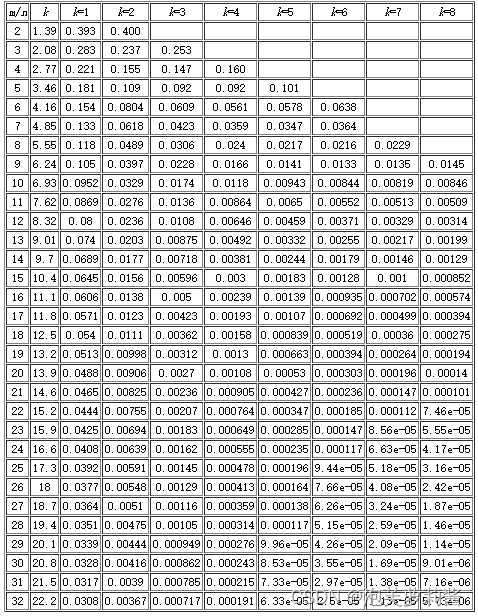
误差计算

-
误差率统计
-
布隆过滤器的实现
- 由Go和redis组合实现一个布隆过滤器
- 底层数据结构
- redis中衍生数据类型很适合作为实现布隆过滤器的底层数据类型
- 实现方法
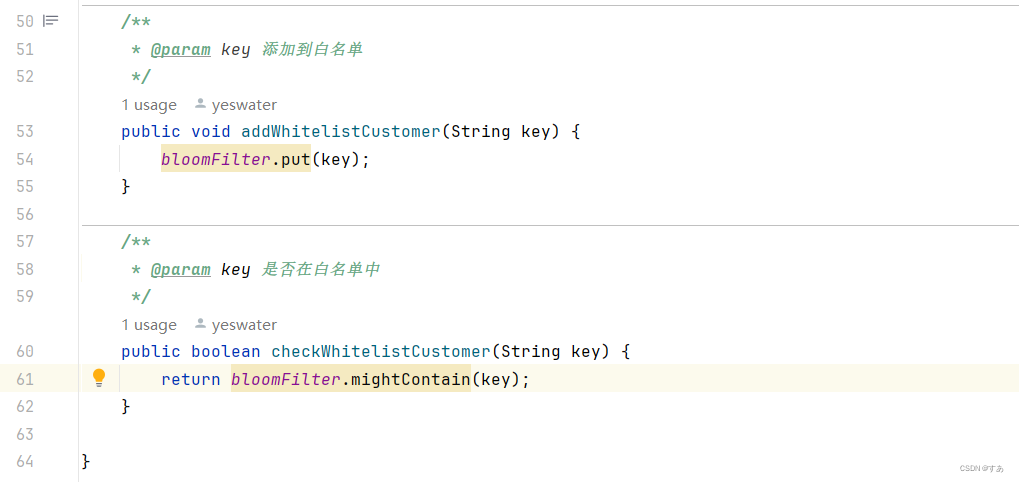
- 布隆过滤器的构造参数:插入数量m,哈希函数个数k
- 布隆过滤器的操作函数:Add,Contains,Probability
- 封装redis位图操作
- 总体代码
- 样例测试




![[数据集][目标检测]婴儿状态睡觉哭泣检测数据集VOC+YOLO格式7109张3类别](https://img-blog.csdnimg.cn/direct/d51f7da7b67c480a8879c3064d26d018.png)







![[推荐]有安全一点的网贷大数据信用查询网站吗?](https://img-blog.csdnimg.cn/img_convert/8454052fda4b0bc21fe93f9447af04e5.png)
