AI目录:sheng的学习笔记-AI目录-CSDN博客
需要学习的前置知识:聚类,可参考:sheng的学习笔记-AI-聚类(Clustering)-CSDN博客
什么是密度聚类
密度聚类亦称“基于密度的聚类”(density-based clustering),此类算法假设聚类结构能通过样本分布的紧密程度确定。通常情形下,密度聚类算法从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的聚类结果
后续表达的距离函数dist(·,·)在默认情况下设为欧氏距离
DBSCAN 算法
DBSCAN是一种著名的密度聚类算法,它基于一组“邻域”(neighborhood)参数(ε,MinPts)来刻画样本分布的紧密程度,给定数据集D={x1,x2,…,xm},定义下面这几个概念
基础概念

图9.8给出了上述概念的直观显示
 D中不属于任何簇的样本被认为是噪声(noise)或异常(anomaly)样本
D中不属于任何簇的样本被认为是噪声(noise)或异常(anomaly)样本
算法定义

若x为核心对象,由x密度可达的所有样本组成的集合记为X={x'∈D|x‘由x密度可达},则不难证明X即为满足连接性与最大性的簇。
算法
于是,DBSCAN算法先任选数据集中的一个核心对象为“种子”(seed),再由此出发确定相应的聚类簇,算法描述如图9.9所示。在第1~7行中,算法先根据给定的邻域参数(ε,MinPts)找出所有核心对象;然后在第10~24行中,以任一核心对象为出发点,找出由其密度可达的样本生成聚类簇,直到所有核心对象均被访问过为止
数据集如下

代码

过程解释
以表9.1的西瓜数据集4.0为例,
- 假定邻域参数(ε,MinPts)设置为ε=0.11,MinPts=5。
- DBSCAN算法先找出各样本的ε-邻域并确定核心对象集合:Ω={x3,x5,x6,x8,x9,x13,x14,x18,x19,x24,x25,x28,x29}。
- 从Ω中随机选取一个核心对象作为种子,找出由它密度可达的所有样本,这就构成了第一个聚类簇。
- 假定核心对象x8被选中作为种子,则DBSCAN生成的第一个聚类簇为C1={x6,x7,x8,x10,x12,x18,x19,x20,x23}。
- DBSCAN将C1中包含的核心对象从Ω中去除:Ω=Ω\C1={x3,x5,x9,x13,x14,x24,x25,x28,x29}。
- 从更新后的集合Ω中随机选取一个核心对象作为种子来生成下一个聚类簇。
- 上述过程不断重复,直至Ω为空
示意图
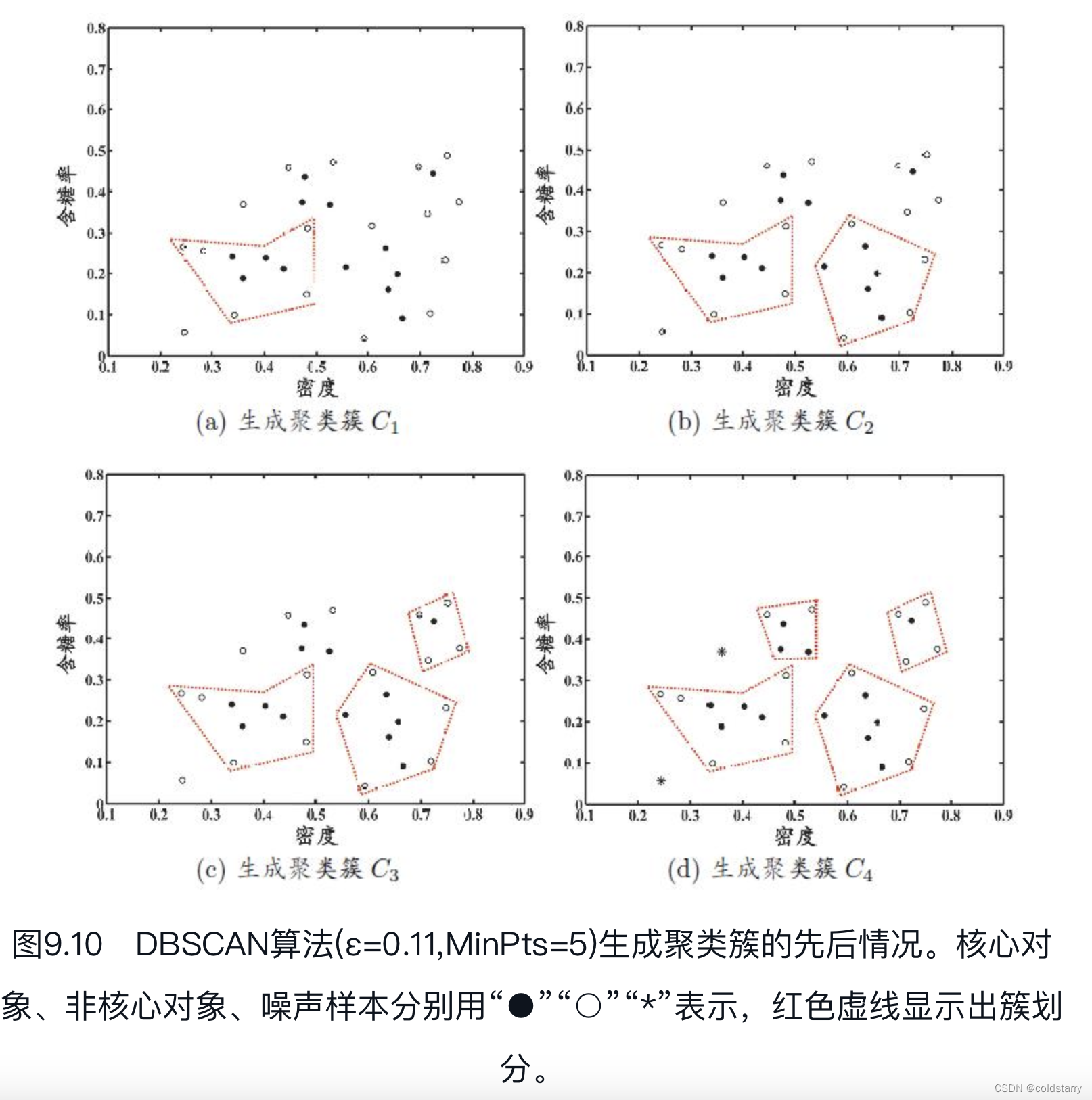
C2={x3,x4,x5,x9,x13,x14,x16,x17,x21};
C3={x1,x2,x22,x26,x29);
C4={x24,x25,x27,x28,x30)。
参考文章:
11.聚类 - 三、密度聚类 - 《AI算法工程师手册》 - 书栈网 · BookStack
书:机器学习 周志华