Yang, Xiaocheng, Mingyu Yan, Shirui Pan, Xiaochun Ye and Dongrui Fan. “Simple and Efficient Heterogeneous Graph Neural Network.” AAAI Conference on Artificial Intelligence (2022).
论文地址:[PDF] Simple and Efficient Heterogeneous Graph Neural Network | Semantic Scholar
论文代码:https://github.com/ICT-GIMLab/SeHGNN
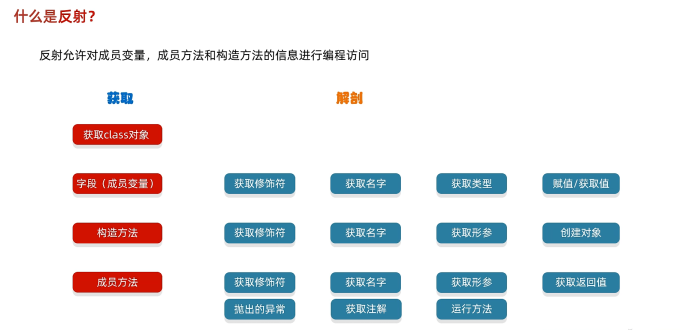
提前需要了解的知识
什么是异构图?

什么是元路径?

摘要
异构图神经网络(Heterogeneous graph neural networks, HGNNs)具有将异构图丰富的结构和语义信息嵌入到节点表示中的强大能力。现有的hgnn继承了许多专为同构图设计的图神经网络(gnn)的机制,特别是注意力机制和多层结构。这些机制带来了过高的复杂性,但很少有人研究它们对异构图是否真的有效。文中对这些机制进行了深入细致的研究,提出了简单高效的异构图神经网络(SeHGNN)。为了轻松捕获结构信息,SeHGNN使用轻量级的均值聚合器对邻居聚合进行预计算,通过消除过度使用的邻居注意力和避免在每个训练周期中重复的邻居聚合来降低复杂度。为了更好地利用语义信息,SeHGNN采用具有长元路径的单层结构来扩展感受野,并采用基于transformer的语义融合模块来融合不同元路径的特征。因此,SeHGNN具有网络结构简单、预测精度高、训练速度快的特点。在真实异构图上的大量实验结果表明,SeHGNN在精度和训练速度上均优于现有同类算法
动机

图1描述了hgnn的两种主要类别。基于元路径的方法(Schlichtkrull等人,2018;Zhang et al. 2019;Wang et al. 2019;Fu et al. 2020)首先捕获同一语义的结构信息,然后融合不同语义信息。这些模型首先聚合每个元路径范围内的近邻特征以生成语义向量,然后将这些语义向量进行融合以生成fnal嵌入向量。无元路径方法(Zhu et al. 2019;Hong等,2020;Hu et al. 2020b;Lv等人2021)同时捕获结构和语义信息。这些模型像传统gnn一样聚合来自节点局部邻域的消息,但使用额外的模块(如attention)将节点类型和边类型等语义信息嵌入传播的消息中。
现有的hgnn继承了gnn的许多机制在同质图上,特别是注意力机制主义和多层结构,如图1所示,但很少有工作研究这些机制在异构图上是否真的有效。此外,多层网络中的层次注意力计算
以及在每个训练周期中重复的邻域聚合带来过多的复杂性和计算量。例如,基于注意力模块的邻居聚合过程在基于元路径的方法中,耗时超过85%HAN模型(Wang et al. 2019)和无元路径模型HGB (Lv et al. 2021),已经成为hgnn在更大规模的异构图上应用的速度瓶颈。
该文对该问题进行了深入细致的研究这些机制并产生了两个发现:(1)语义注意力是必要的,而邻居注意力是不必要的,(2)单层结构和长元路径模型的性能优于多层结构和短元路径模型。这些发现表明近邻注意力和多层结构不仅引入了不必要的复杂性,但也会阻碍模型取得更好的性能。
为此,提出一种新的基于元路径的方法SeHGNN。SeHGNN采用均值聚合器(Hamilton、Ying和Leskovec 2017)来简化近邻聚合,采用具有长元路径的单层结构来扩展感受野,并利用基于transformer的语义融合模块来学习语义对之间的相互注意力。此外,由于SeHGNN中的简化邻居聚合是无参数的,且只涉及线性操作,因此在预处理步骤中只需要执行一次邻居聚合。因此,SeHGNN不仅表现出更好的性能,而且避免了在每个训练周期中重复聚合近邻的需要,从而显著提高了训练速度。
模型
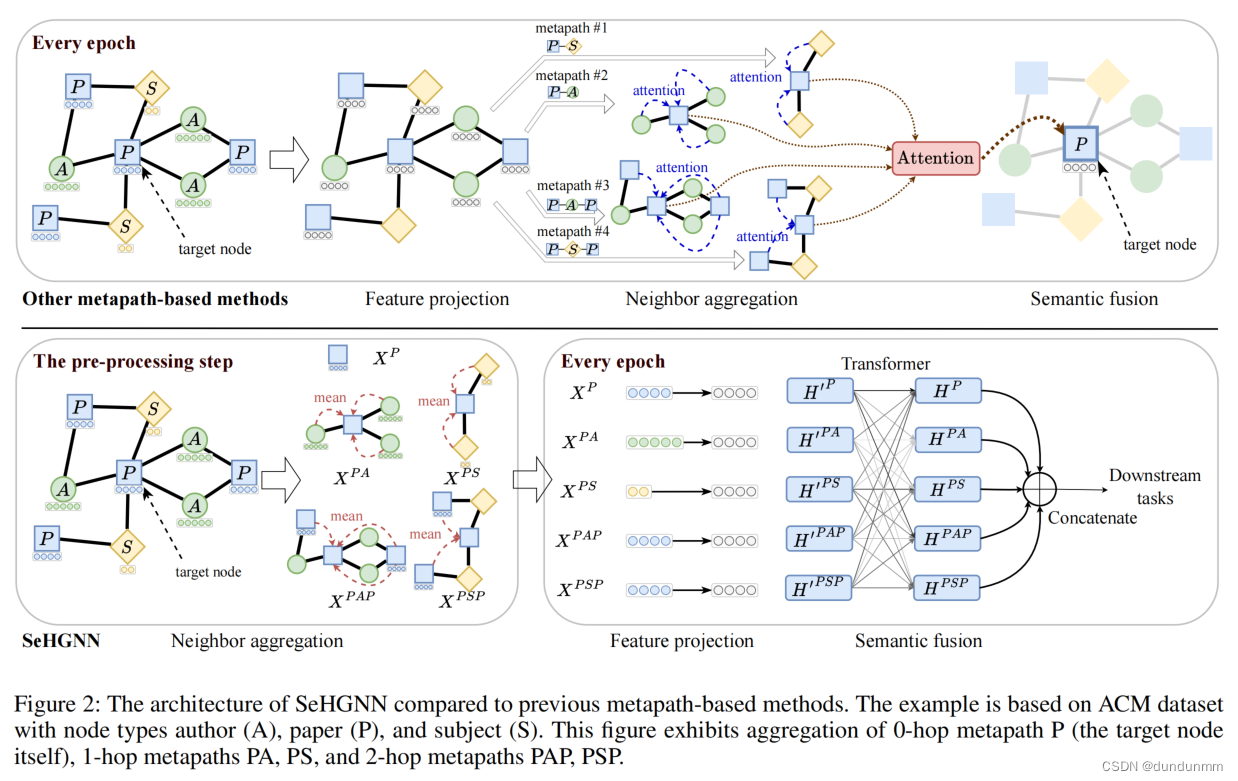
如图2所示,SeHGNN包括三个主要组件:简化近邻聚合、多层特征投影和基于transformer的语义融合。图2还强调了SeHGNN和其他基于元路径的hgnn之间的区别,即SeHGNN在预处理步骤中预先计算近邻聚合,从而避免了在每个训练周期中重复近邻聚合的过度复杂性。
简化近邻聚合
简化的邻居聚合在预处理步骤中只执行一次,并为所有给定元路径的集合ΦX生成不同语义的特征矩阵![]() 列表。一般来说,对于每个节点vi,它采用均值聚合对每个给定元路径的基于元路径的邻居进行特征聚合,并输出一个语义特征向量列表,表示为:
列表。一般来说,对于每个节点vi,它采用均值聚合对每个给定元路径的基于元路径的邻居进行特征聚合,并输出一个语义特征向量列表,表示为:
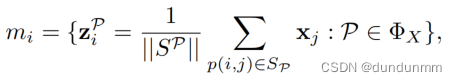

受GCN分层传播的启发,作者使用邻接矩阵的乘法计算每个节点对目标的最终贡献权重。
对于![]()
简化的近邻聚合过程可以表示为:
![]()

此外,之前的研究已经证明,将标签作为额外的输入可以提高模型的性能。为了利用这一点,与原始特征的聚合类似,作者以one-hot格式表示标签,并在各种元路径上传播它们。为了避免标签泄漏导致过滤波,通过去除邻接矩阵乘法结果中的对角线值来防止每个节点接收自身的真值标签信息。标签传播也在邻居聚合步骤中执行,并产生语义矩阵作为后续训练的额外输入。
多层特征投影
因为不同元路径的语义向量可能具有不同的维度或位于不同的数据空间中,因此,特征投影步骤将语义向量投影到相同的数据空间中。
通常,它为每个元路径P定义一个特定于语义的转换矩阵WP并计算![]() 。为了获得更好的表示能力,对每个元路径P使用多层感知块MLP,其中包含一个归一化层、一个非线性层和两个连续线性层之间的dropout层。那么,该特征投影过程可以表示为:
。为了获得更好的表示能力,对每个元路径P使用多层感知块MLP,其中包含一个归一化层、一个非线性层和两个连续线性层之间的dropout层。那么,该特征投影过程可以表示为:

基于transformer的语义融合
语义融合步骤对语义特征向量进行融合,生成每个节点的最终嵌入向量。作者提出了一个基于transformer (Vaswani et al. 2017)的语义融合模块,而不是使用简单的加权和形式,以进一步探索每对语义之间的相互关系。

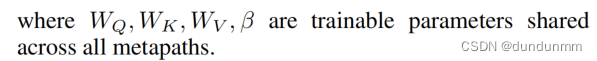
实验
在融合图结构时,异构图确实是一个值得考虑的方向。








![[leetcode]squares-of-a-sorted-array. 有序数组的平方](https://img-blog.csdnimg.cn/direct/dee5990dbee24f3fb57450b62d0a0bb5.png)
![春秋云境:CVE-2022-25411[漏洞复现]](https://img-blog.csdnimg.cn/direct/8927f0354d134f6bad727ffc4ff36c29.png)