Python绕过登录爬虫:实现快速爬取网站数据
在进行网站数据爬取时,有些网站会要求用户先进行登录操作,才能够获取到需要的数据。这对于爬虫来说是一个挑战,因为传统的爬虫方法无法绕过登录部分的限制获取数据。然而,通过Python编程技巧,我们可以轻松地绕过登录限制,快速地进行数据爬取。本文将介绍Python绕过登录爬虫的方法,并提供实例代码供读者参考。
什么是Python绕过登录爬虫?
绕过登录爬虫是指使用编程工具来模拟登录过程,以达到通过爬虫程序获得登录后的数据的目的。目前,大部分网站都会在用户访问时要求用户登录或注册。因此,通过Python编写绕过登录爬虫程序,可以有效地获取登录后的数据。
Python绕过登录的操作步骤
1. 获取登录页表单信息
首先,我们需要获取登录页表单信息,在Python中,我们可以使用requests库获取对应url的网页源代码,然后在源代码中查找登录表单的url和参数信息。
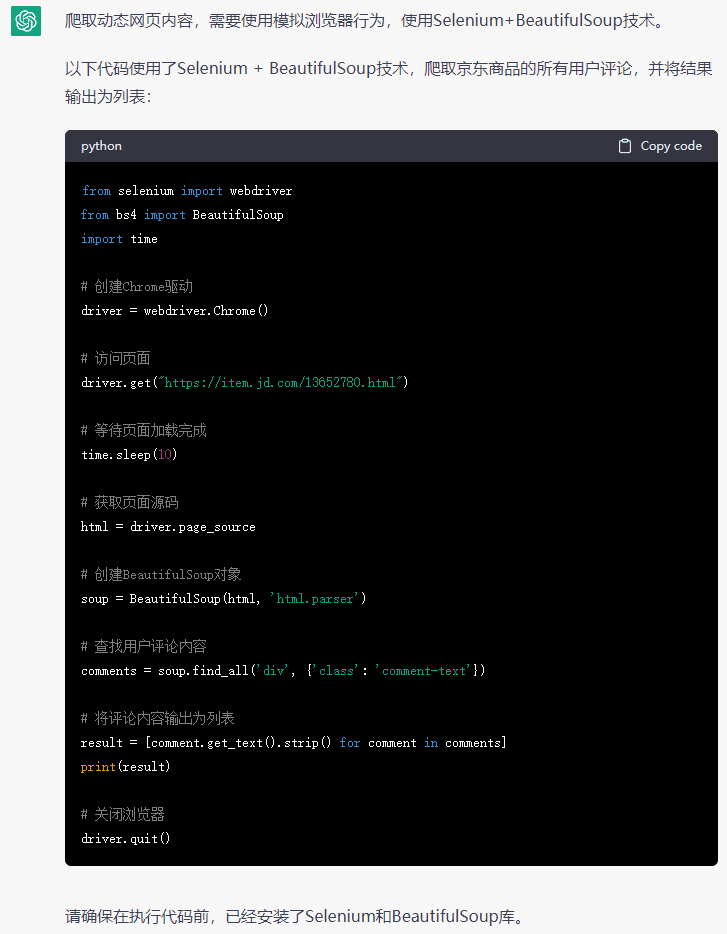
例如,如果我们需要登录一个名为“webdriveruniversity”的网站,可以通过以下代码获取登录页表单信息:
import requests
from bs4 import BeautifulSoupurl = "https://www.webdriveruniversity.com/Login-Portal/index.html"
response = requests.get(url) # 获取网页源代码
soup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析源代码login_form_url = soup.find('form', {'id': 'login-portal'})['action'] # 查找登录表单的url
form_inputs = soup.find('form', {'id': 'login-portal'}).find_all('input') # 查找登录表单的参数
2. 构建post请求提交登录信息
获取表单信息后,我们需要构建POST请求,将获取到的表单信息作为参数提交给登录表单。在Python中,我们可以使用requests库的post方法实现模拟登录,如下所示:
import requestsurl = "https://www.webdriveruniversity.com/Login-Portal/"+login_form_url
session = requests.session() # 创建一个Session对象parameters = {}
for input in form_inputs:param_name = input['name']if 'value' in input.attrs:parameters[param_name] = input['value']else:parameters[param_name] = ""parameters['username'] = "your_username" # 替换为你的用户名
parameters['password'] = "your_password" # 替换为你的密码response = session.post(url, data=parameters) # 提交登录表单,保存Session对象
此时,我们已经通过Session对象模拟了登录过程,并保存了登录后的状态。
3. 访问需要登录才能获取数据的页面
登录成功后,我们可以在Session对象下使用get方法访问需要登录才能获取数据的页面,请求头部会包含登录时保存的cookie信息。如下所示:
url = "https://www.webdriveruniversity.com/To-Do-List/index.html"
response = session.get(url) # 使用Session对象访问需要登录才能获取数据的页面
此时,我们获得的response对象实际上是登录后的跳转页面的源代码,包含所需要的数据。
4. 解析数据
通过上述步骤,我们已经成功地绕过了网站的登录限制,获取了需要的数据。接下来,我们可以使用解析工具(如BeautifulSoup或正则表达式)解析数据内容,并保存到本地或上传到数据库。
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, 'html.parser') # 使用BeautifulSoup解析源代码items = []
for item in soup.find_all('td', {'class': 'ng-binding'}):items.append(item.text.strip()) # 解析需要的数据with open('result.txt', 'w') as f:f.write('\n'.join(items)) # 将数据保存到本地
结论
使用Python绕过登录爬虫可以有效地获取需要登录才能获取的数据。通过构建post请求和保存Session对象的方法,我们可以轻松地模拟登录过程。注意,在使用Python绕过登录爬虫时要遵循合法的数据获取规则,防止侵犯网站的合法权益。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
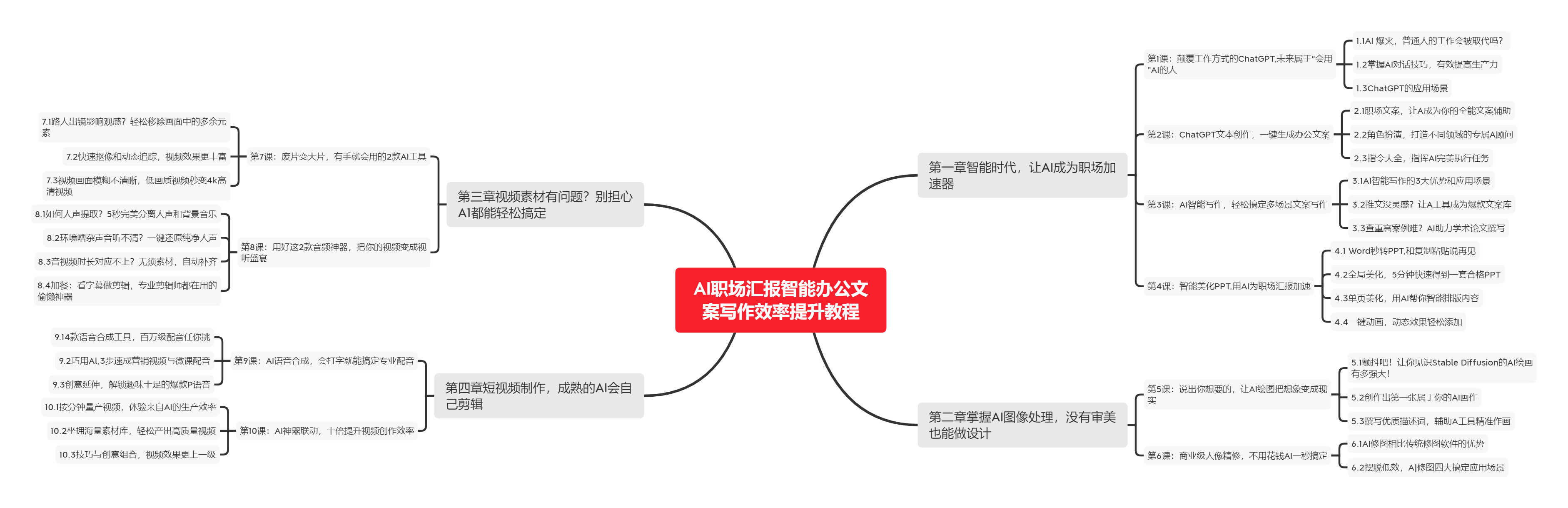
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |