目录
01 评测榜单
02 实际效果
什么?许多大模型的文科成绩竟然超过了一本线,还是在竞争激烈的河南省?
没错,最近有一项大模型“高考大摸底”评测引起了广泛关注。
河南高考文科今年的一本线是521分,根据这项评测,共有四个大模型的分数大于或等于这个分数,其中最值得关注的是前两名:
GPT-4o:562分
字节豆包:542.5分
……
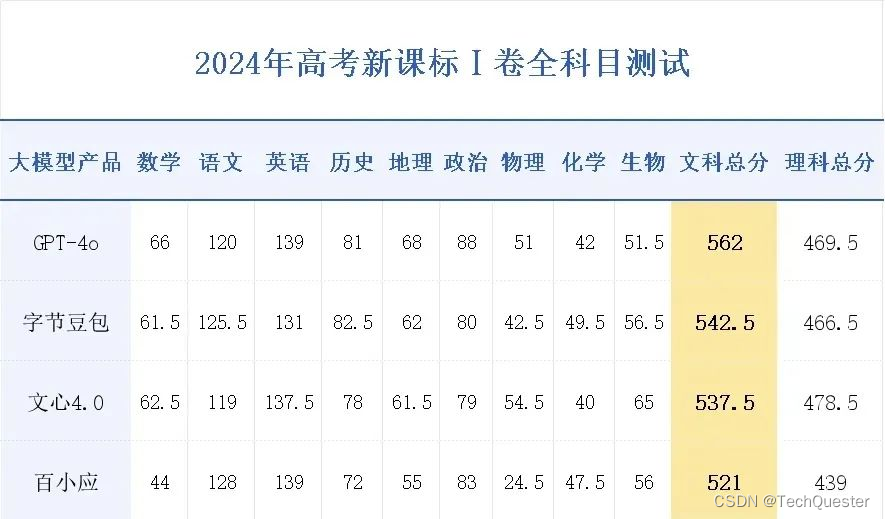
从结果来看,GPT-4o依旧表现领先,而在国产大模型中,豆包的成绩尤为亮眼。
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!官网有更详细介绍:WildCard
https://www.zhihu.com/pin/1768399982598909952如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!官网有更详细介绍:WildCard
在语文和历史等科目上,豆包超越了GPT-4o。
这让不少网友感叹:
AI在文科成绩上表现如此出色,看来在处理语言和逻辑方面确实有优势。
不过,考虑到国产大模型的竞争如此激烈,这份评测的排名真的靠谱吗?
01 评测榜单
要回答这些问题,我们不妨先查一查豆包在最新的权威评测榜单中的表现是否一致。
首先来看由智源研究院发布的FlagEval(天秤)。
它的评测方式如下:
对于开源模型,FlagEval会综合概率选择和自由生成两种方式来评测;对于闭源模型,FlagEval只采用自由生成的方式来评测,两种评测方式的区别参照。
在主观评测时,部分闭源模型对极小部分题目有拒绝回答的情况,这部分题目并没有计入能力分数的计算。
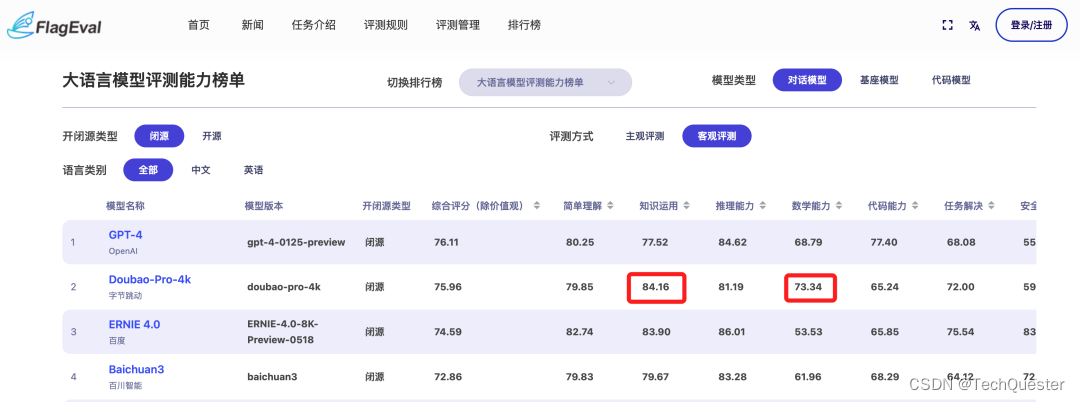
在“客观评测”这个维度上,榜单成绩如下。
不难看出,在FlagEval的客观评测维度中,前四名的成绩与“高考大摸底”的名次一致。
大模型依旧分别来自OpenAI、字节跳动、百度和百川智能。
并且豆包在“知识运用”和“数学能力”两个维度上的成绩还高于第一名的GPT-4。
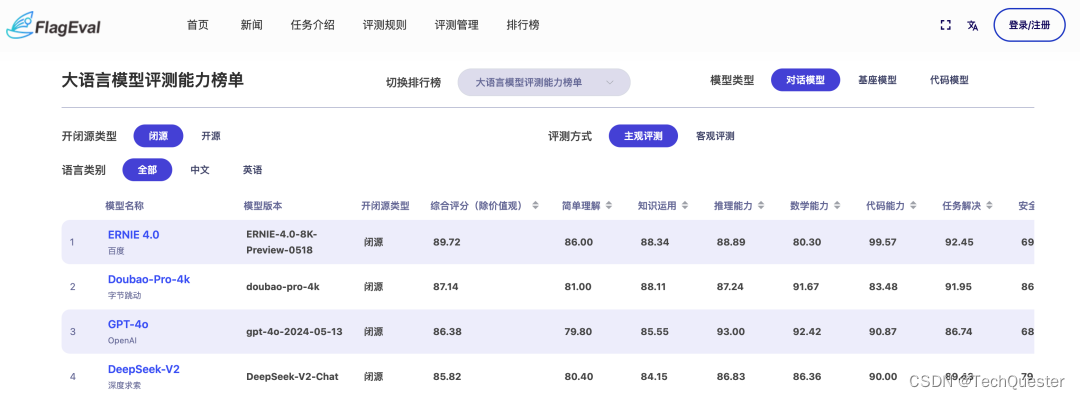
如果将评测方式调整至“主观评测”,结果如下。
此时,百度的大模型跃居第一,而字节的豆包依旧稳居第二。
由此可见,无论是主观还是客观维度,前几位的名次都与“高考大摸底”的成绩相当接近。
02 实际效果
接下来的实际效果测试,采用“LLM链路+数学”的方式进行。
首先,试试这次的选择题:

把题目在PC端“喂”豆包之后,它的作答如下:

因此,豆包给出的答案是:
A、C、D、D、B、B、A、A
这里我们再来引入排名第一选手GPT-4o的作答:
A、D、B、D、C、A、C、B

对于更多的数学题的作答,其实复旦大学自然语言处理实验室在高考试卷曝光后第一时间做了更加全面的测试(所有大模型只能依靠LLM推理答题,不能通过RAG检索答案):

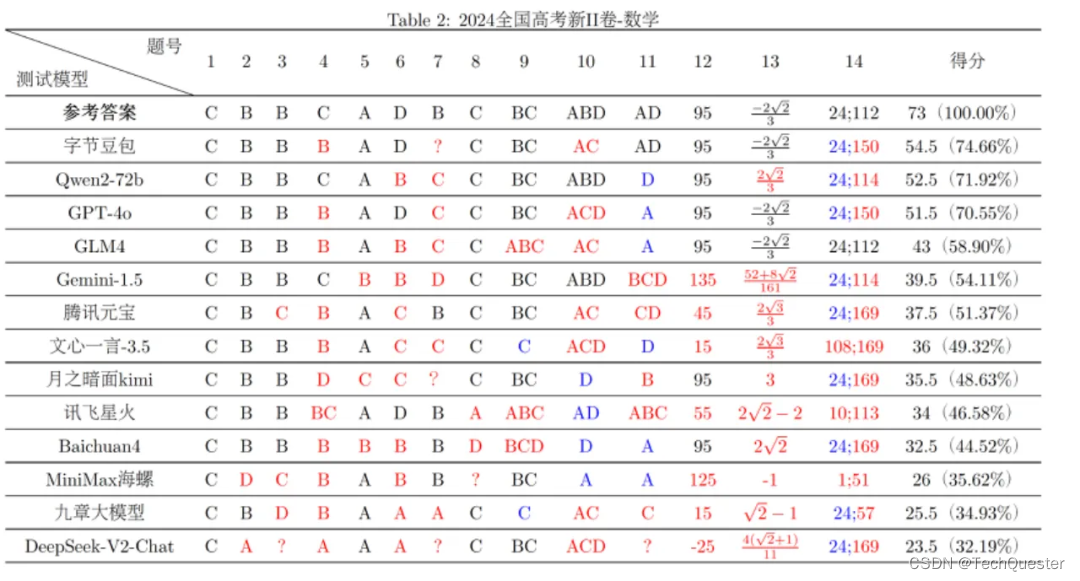
由此可见,大模型并不能完全应对高考数学题目,并且不同人生成的答案结果也会有所偏差。
反复测试后发现,在对话答题时存在一定的随机性,多轮测试的结果并不完全一致。上文仅展示了其中一轮的结果。
这也正如广大网友所反馈的那样——大模型在文科方面表现强劲,而在理科方面则相对较弱。
推荐阅读:
超越GPT-4o!新王Claude 3.5 Sonnet来啦!
GPT-4替代大学生参加考试,94%成功作弊未被发现!