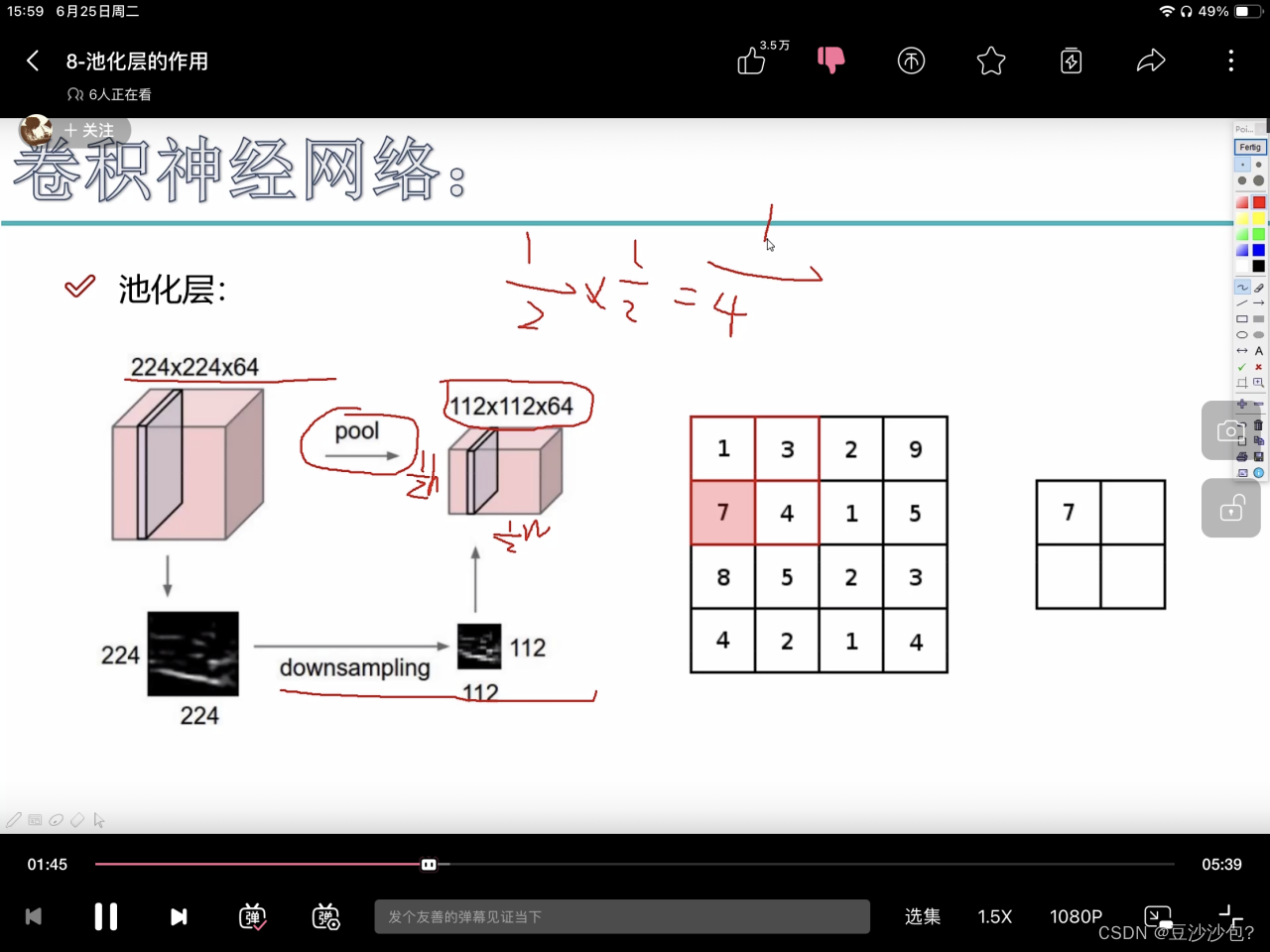
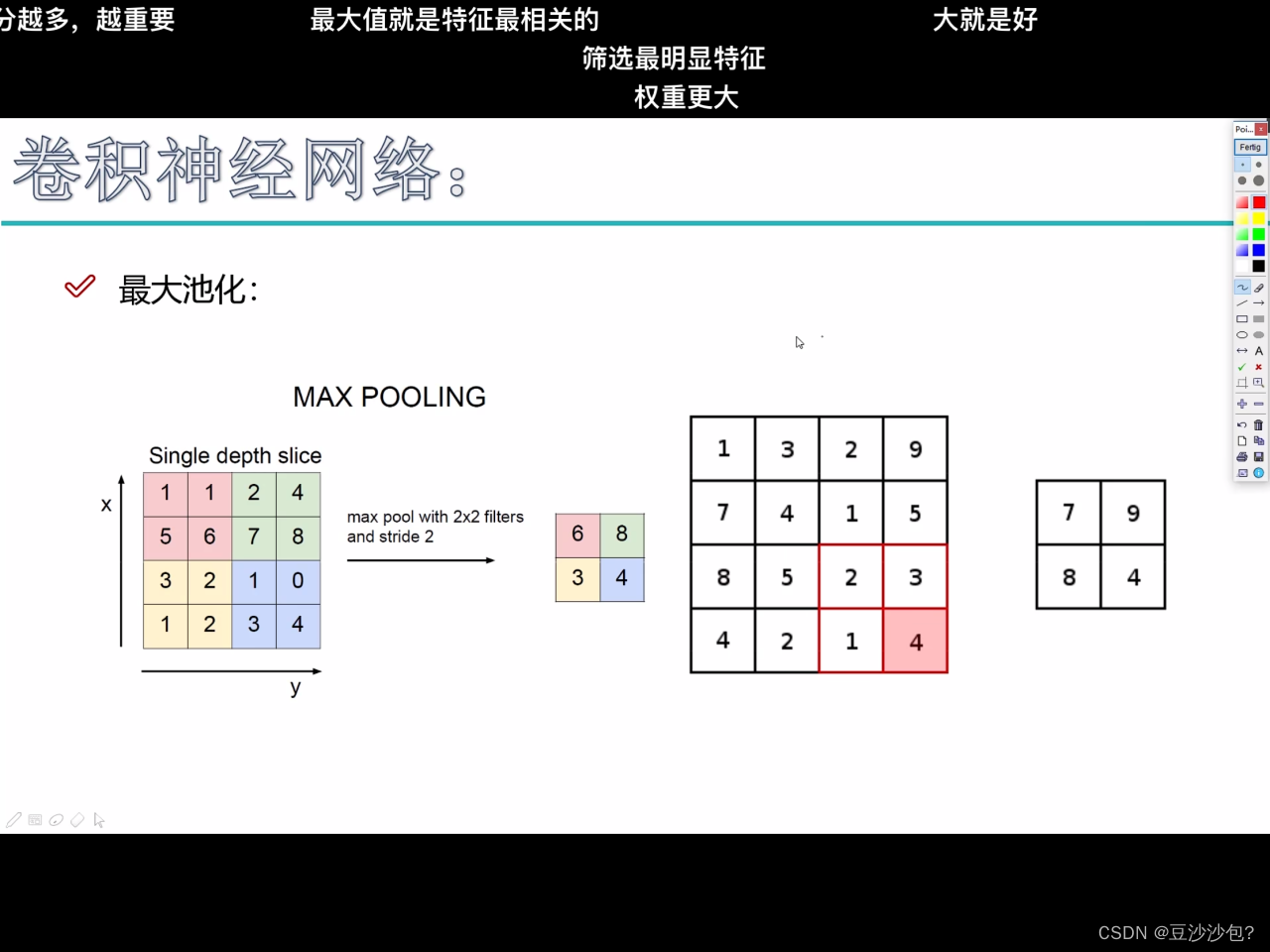
1.池化层作用(筛选、过滤、压缩)
h和w变为原来的1/2,64是特征图个数保持不变。
每个位置把最大的数字取出来
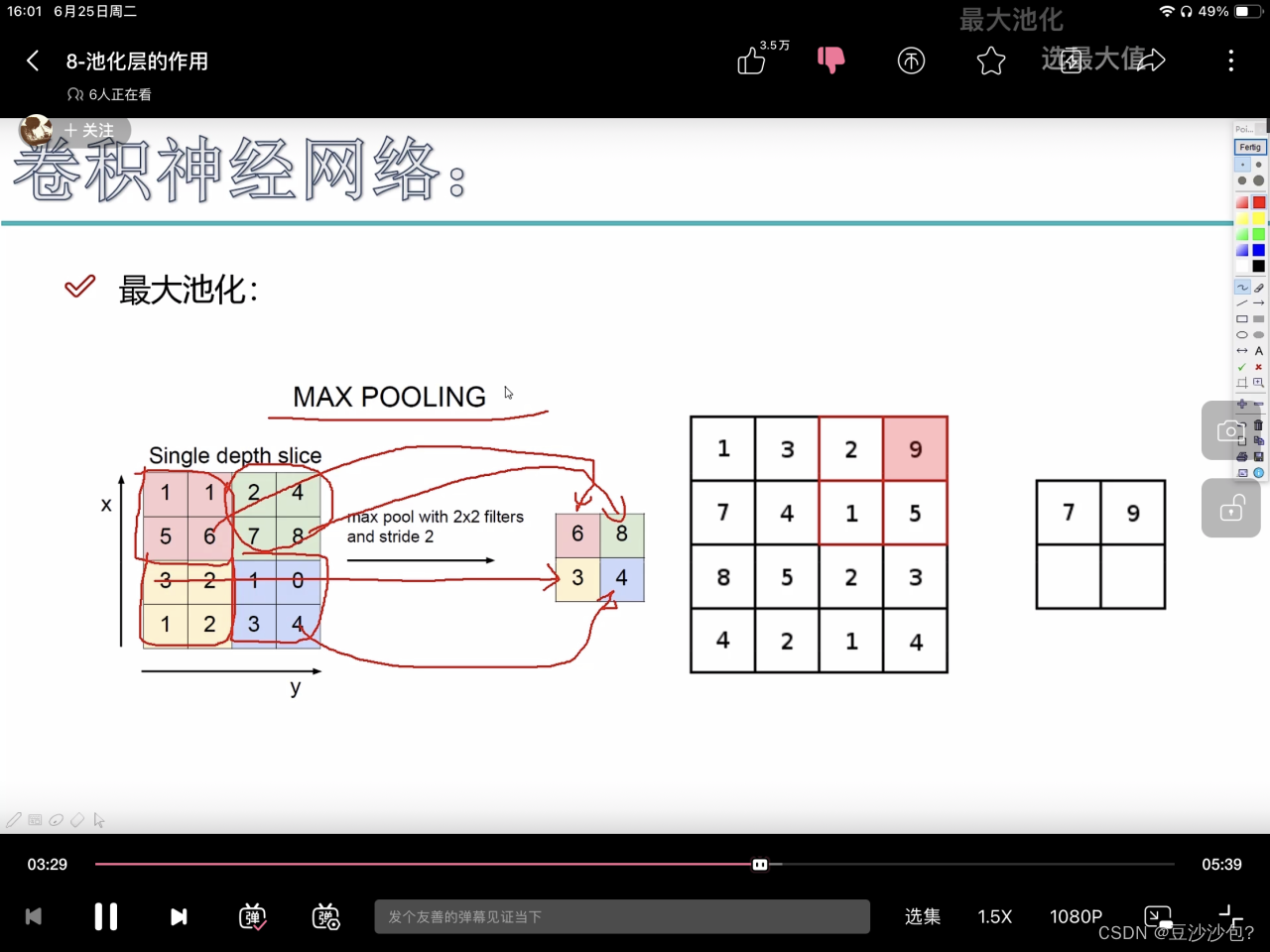
用滑动窗口把最大的数值拿出来,把44变成22
2.卷积神经网络
(1)conv:卷积进行特征提取,带参数
(2)relu:激活函数,非线性变换,不带参数
卷积层和relu搭配组合
两次卷积一次池化,池化是进行压缩,不带参数
FC全连接层【323210=10240特征,5分类】,有权重参数矩阵

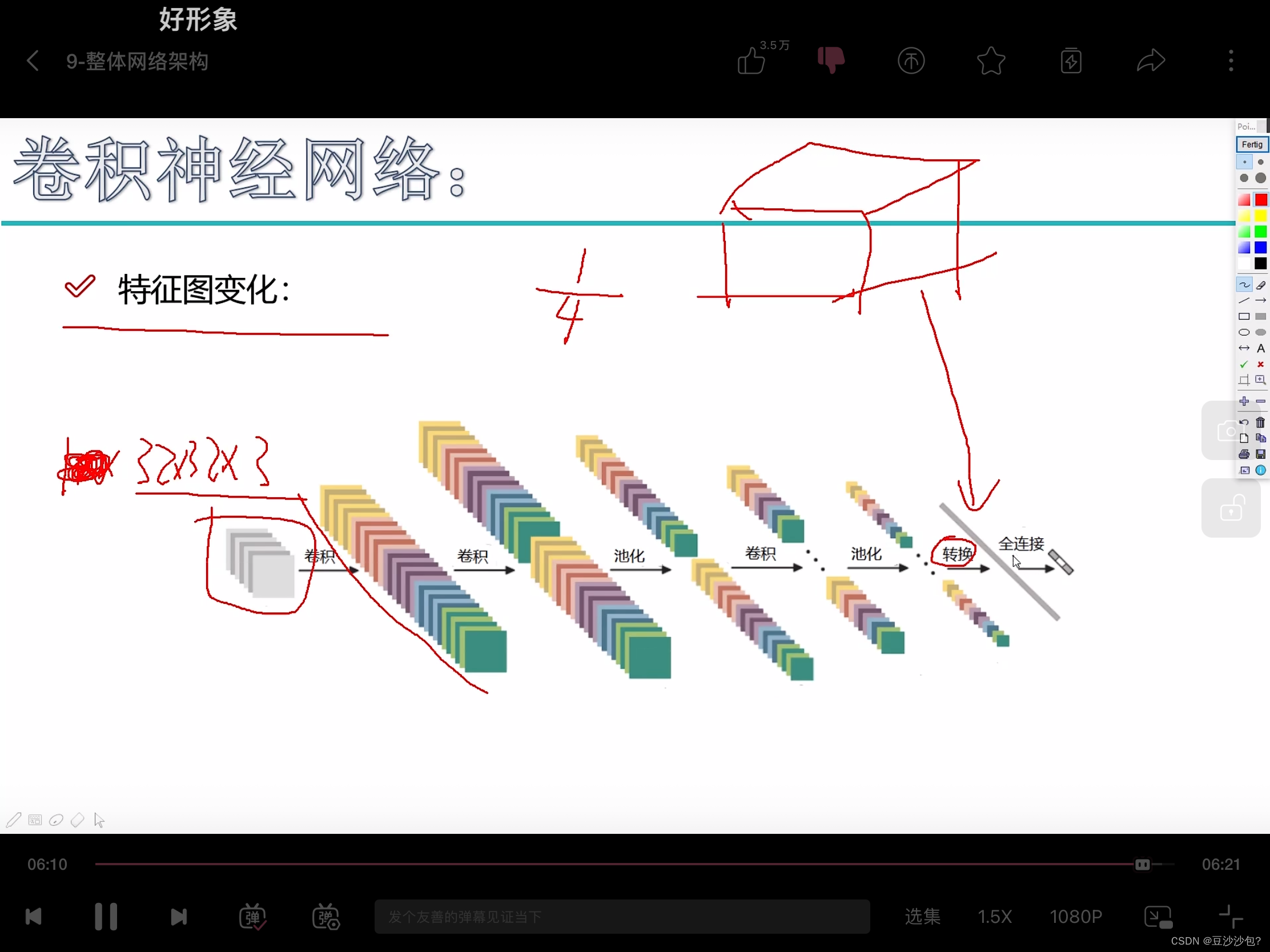
(3)七层卷积神经网络conv,conv,conv,conv,conv,conv,fc
(4)特征图变化: 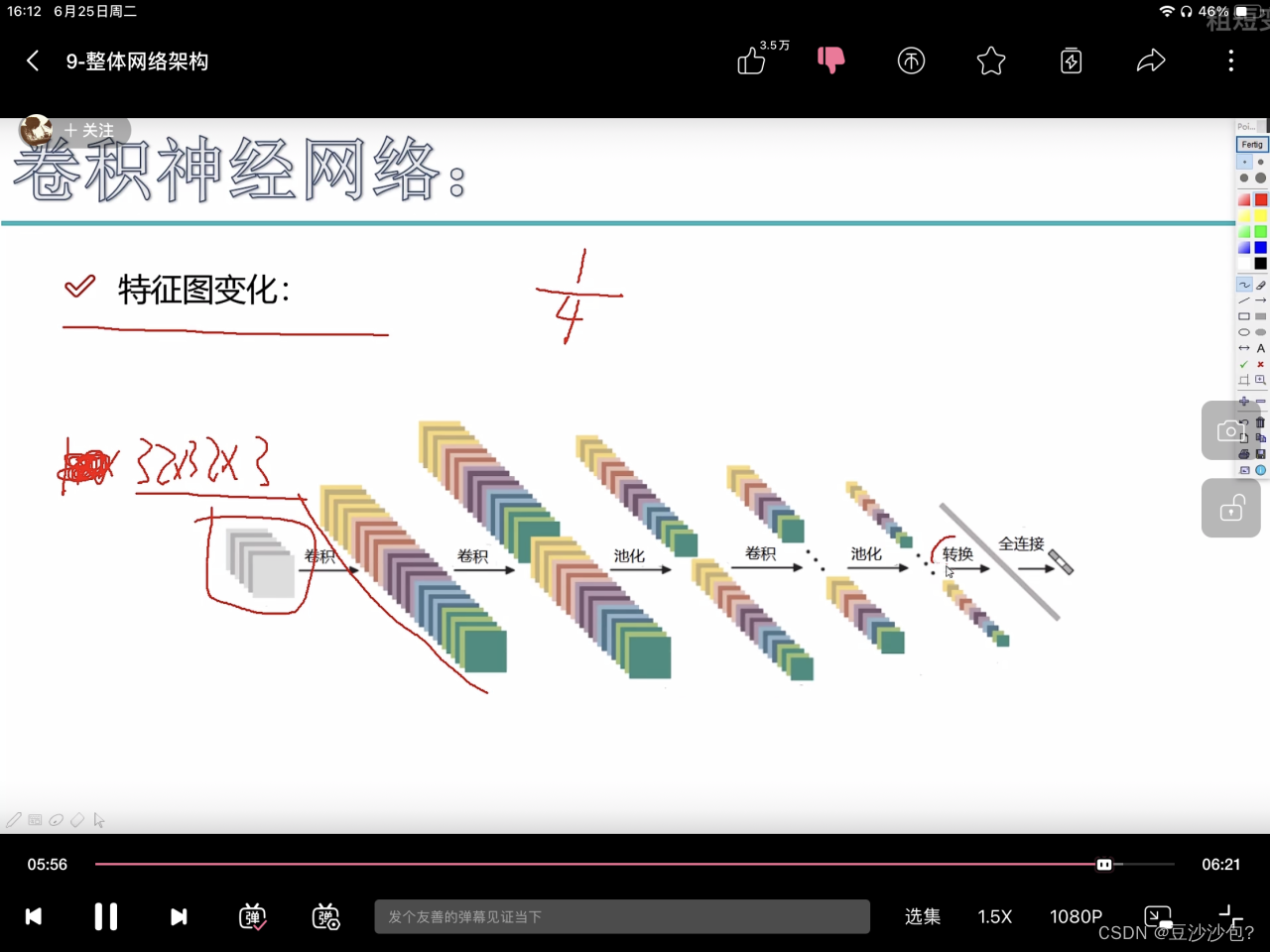
(5)把长方体或者立方体通过转换变成一条向量矩阵,连全连接层。
(5)agg的训练时长大于alexnet的训练时长
3.残差网络
(1)用经典网络去实验,agg和resnet都是比较主流的神经网络框架。




4.感受野的作用
second conv粉红色小格的感受野是first conv33,first conv感受的是输入数据的55,所以最后的一个值是由之前的55得来的。
一般希望感受野越大越好。

(2)用3个小的参数得到的 比用1个大的卷积核得到的参数要小
一个77的卷积核需要1个relu,3个3*3的卷积核需要3个relu
,3个relu的非线性特征越强
4.递归神经网络
(1)加入一个时间序列,隐层会多一个数据,前一个时刻训练出来的特征也会对后一个特征有影响。




(2)cnn用于cv计算机视觉,rnn用于nlp自然语言处理。
(3)rnn记忆能力比较强,最后一个结果会把前面所有的结果考虑进来,可能会产生误差。l s t m可以忘记一些特征,c为控制参数,可以决定什么样的信息会被保留什么样的信息会被遗忘。




(4)门单元乘法操作
5.词向量模型的通俗解释
(1)nlp和自然语言都是同一个词 ,所以他们在空间上的表达和向量上的表达上一致的。


(2)谷歌给出的官方数据是300维更精确。
然后根据向量之间的距离,用欧式距离、余弦距离用来计算两个单词的词向量。

这个图是代表50维的词向量,粉红色这些数字的含义相当于编码,在空间上有意义的,能被计算机识别。
(3)man和boy训练出来的颜色上很相近的。在词向量中输入是有顺序的。让神经网络学到语句的先后顺序。输出层很像多分类层。类似多分类任务后面加入一个softmax层


(4)look up embedding 词嵌入查找。a向量找a的词嵌入。
前向传播计算loss function,反向传播通过损失函数计算更新权重参数。word2vec不仅更新权重参数模型,也会更新输入。相当于词嵌入查找表是随机初始化


6.训练数据的构建
(1)指定滑动窗口来构建输入、输出数据
(前提是要保障词句之间的逻辑关系)

(2)cbow模型的对比,知道上下文去求中间那个词


(3)skipgram模型根据某个词去预测上下文的内容


(4)在gensim的工具包中可以选择cbow模型以及skipgram模型

(5)由输入数据,根据embedding look up去查找该词在词库表的位置。假设拿到一个比较大的语料库,所以最后的分类的类别也会比较多,这是个问题。最后一层相当于softmax。旧方法是由a预测b,新方法是由a预测b在a之后的概率(把a,b都当成输入数据)



(6)在词向量模型中不仅要更新参数,也要更新x。所以在反向传播当中,我们要更新权重参数和输入数据x。