高质量数据的重要性
数据的质量直接影响模型的性能和准确性。高质量的数据可以显著提升模型的学习效果,帮助模型更准确地识别模式、进行预测和决策。具体原因包括以下几点:
- 噪音减少:高质量的数据经过清理,减少了无关或错误信息,这可以降低模型学习过程中的干扰,从而提高模型的准确性。
- 一致性:一致的数据格式和规范化处理使模型能够更有效地学习特征,避免因数据格式不一致带来的混淆和误差。
- 代表性:高质量的数据集通常具有良好的代表性,能够覆盖更多的实际场景和情况,使模型在训练过程中接触到更多的可能性,提高其泛化能力。
- 复杂性处理:高质量的数据能帮助模型更好地处理数据的复杂性,通过正确的标签和特征,可以引导模型识别和学习数据中的复杂模式。
数据标注是将原始数据进⾏加⼯处理,⽐如分类、拉框、注释、标记等操作转换成机器可识别信息的过程。国内数据标注⼚商,⼴义称之为基础数据服务提供商,通常需要完成数据集结构/流程设计、数据处理、数据质检等⼯作,为下游客⼾提供通⽤数据集、定制化服务、数据闭环⼯具链等。这也是本次AIGC数据标注全景报告的研究对象。

数据标注中的⼆⼋定律:通常在一个AI项目中,数据准备工作需要80%时长,模型训练和部署仅占20% 。

本文主要介绍再自然语言处理中的英文文本处理。

英文文本相关技术
文本预处理是自然语言处理 (NLP) 中的一个关键步骤,旨在清理和规范化原始文本数据,以便后续的分析和建模。以下是常见的文本预处理步骤:
英文文本预处理
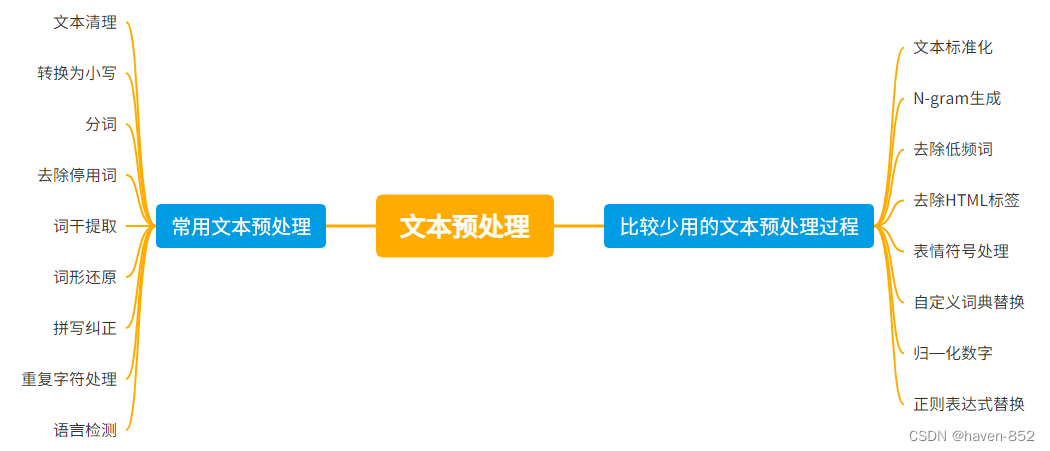
文本清理 (Text Cleaning):
去除标点符号 (Removing Punctuation):删除文本中的标点符号。
去除数字 (Removing Numbers):删除或替换文本中的数字。
去除多余的空格 (Removing Extra Whitespace):规范化空格,去除多余的空格。
去除特殊字符 (Removing Special Characters):删除或替换文本中的特殊字符。
转换为小写 (Lowercasing):
将所有文本转换为小写,以确保一致性。
分词 (Tokenization):
将文本分割成单个单词或标记(tokens)。
去除停用词 (Removing Stopwords):
删除常见的无意义词(如“the”、“is”、“and”)以减少噪音。
词干提取 (Stemming):
将单词还原为词干形式,如“running”变为“run”。
词形还原 (Lemmatization):
将单词还原为其基本形式(词元),如“better”还原为“good”。
拼写纠正 (Spelling Correction):
纠正文本中的拼写错误。
文本标准化 (Text Normalization):
处理缩写和俚语,将其转换为标准形式。
N-gram 生成 (N-gram Generation):
创建连续的 N 个单词的组合,以捕捉上下文信息。
去除低频词 (Removing Rare Words):
删除出现频率很低的单词,以减少噪音和数据维度。
去除 HTML 标签 (Removing HTML Tags):
在处理网页文本时,去除 HTML 标签。
表情符号处理 (Handling Emojis):
识别和处理表情符号,将其转换为文本描述或删除。
重复字符处理 (Handling Repeated Characters):
处理文本中重复的字符,如将“loooove”转换为“love”。
自定义词典替换 (Custom Dictionary Replacement):
使用自定义词典将特定短语或俚语替换为标准形式。
语言检测 (Language Detection):
检测并处理多语言文本,选择性地处理特定语言的文本内容。
归一化数字 (Normalization of Numbers):
统一处理数字表示形式,如将“twenty”转换为“20”。
正则表达式替换 (Regular Expression Replacement):
使用正则表达式进行复杂的文本替换或模式匹配。
其他文本相关技术
主题建模 (Topic Modeling):
使用主题建模技术(如 LDA)提取文本中的主题,以简化文本表示。
特征提取 (Feature Extraction):
使用 TF-IDF、词嵌入(如 Word2Vec、GloVe)或句子嵌入(如 BERT)等技术将文本转换为数值特征向量。
这些步骤的具体选择和顺序可能会根据具体的任务和数据集而有所不同,但上述步骤提供了一个全面的文本预处理流程概览。
文本拆分 (Text Segmentation):
尤其是在处理中文文本时,将连续的汉字分割成独立的词语。
实体识别 (Named Entity Recognition, NER):
识别文本中的专有名词,如人名、地名、机构名等。
情感分析 (Sentiment Analysis):
预处理过程中标记文本的情感极性,如积极、消极、中性。
话题过滤 (Topic Filtering):
只保留或删除特定话题相关的文本片段。
特定领域术语处理 (Domain-Specific Term Handling):
处理特定领域的术语和缩写,确保其正确解析和分析。
处理否定 (Handling Negations):
在情感分析中特别重要,标记或处理否定词以正确捕捉其影响。
上下文扩展 (Context Expansion):
使用上下文信息扩展或解释单词的含义,增强文本理解。
这些步骤可以根据具体的应用场景和文本数据的特点进行选择和组合,以实现最佳的文本预处理效果。