目录
1 什么是特征分箱
2 分箱的重要性及其优势
3 有监督分箱
3.1卡方分箱原理
3.2 决策树分箱
4 无监督分箱
4.1 等距分箱
4.2 等频分箱
4.3 分位数分箱
实验数据:链接:https://pan.baidu.com/s/1yT1ct_ZM5uFLgcYsaBxnHg?pwd=czum 提取码:czum
实验数据介绍:参考文章1.2节(数据介绍链接)
1 什么是特征分箱
特征分箱(Feature Binning)是一种数据预处理技术,主要用于将连续特征(或密集离散特征)转换为离散特征,可以提高模型的性能。
目的:特征分箱的目的是将连续(或密集离散)变量的值范围划分为多个区间(或“箱子”),并将这些区间映射到离散的类别或标签上。
原因:连续(或密集离散)变量可能包含非线性关系或复杂的模式,这些模式对于某些机器学习算法来说可能难以捕捉。通过分箱,我们可以将这些复杂的连续变量(或密集离散)简化为更易于模型处理的离散变量。
例如,我们有一组关于人年龄的数据,如下图所示:
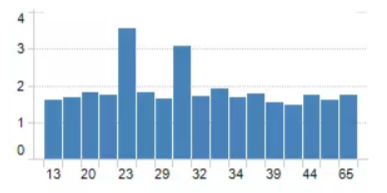
现在希望将他们的年龄分组到更少的间隔中,可以通过设置一些条件来实现:
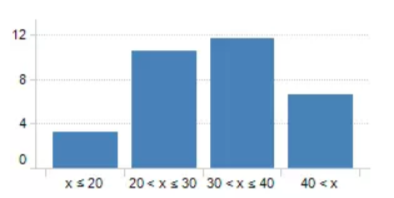
2 分箱的重要性及其优势
一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险。分箱的有以下重要性及其优势:
- 易于迭代:离散化特征的增加和减少都很容易,便于模型快速迭代优化。
- 计算效率:稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 鲁棒性强:离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个少见数据“年龄120岁”会给模型造成很大的干扰;
- 特征交叉:离散化后可进行特征交叉,进一步增加非线性,提高模型的表达力。
- 简化模型:降低过拟合风险,同时允许将缺失值视为独立类别,统一变量尺度。
3 有监督分箱
3.1卡方分箱原理
卡方分箱概念
卡方分箱(ChiMerge)是一种基于统计学原理的特征离散化方法,它依赖于卡方检验来评估相邻区间的类分布是否相似。如果两个相邻区间的类分布相似,则可以合并这些区间;如果不同,则应保持分开。卡方分箱的基本思想是在精确的离散化中,一个区间内的相对类频率应当完全一致。
卡方分布
为了更好地理解卡方分箱,我们先来看下卡方分布。卡方分布(Chi-square Distribution)是概率论与统计学中常用的一种概率分布,也是统计推断里应用最广泛的概率分布之一。卡方分布的定义基于标准正态分布,其数学定义如下:
若k个独立的随机变量Z1、Z2、……、Zk满足标准正态分布N(0,1),则这k个随机变量的平方和
![]()
服从自由度为k的卡方分布,记作:
![]()
卡方检验
卡方检验是以卡方分布为基础的一种假设检验方法。主要用于比较观察值和期望值之间是否存在差异。这种方法特别适用于分类数据,如性别、教育水平等。
其基本思想是根据样本数据推断总体的分布与期望分布是否有显著差异,或者推断两个分类变量是否相关或者独立。一般可以设原假设为:观察频数和期望频数没有差异,或者两个变量相互独立不相关,即该因素不会影响到目标变量。
实际应用中,我们先假设原假设成立,计算出卡方值,卡方值的计算公式为:
![]()
其中,A为实际频数,E为期望频数。
该假设计算出卡方值,它表示观察值与理论值之间的偏离程度。根据卡方分布及自由度可以确定在原假设成立的情况下获得当前统计量及更极端情况的概率P。
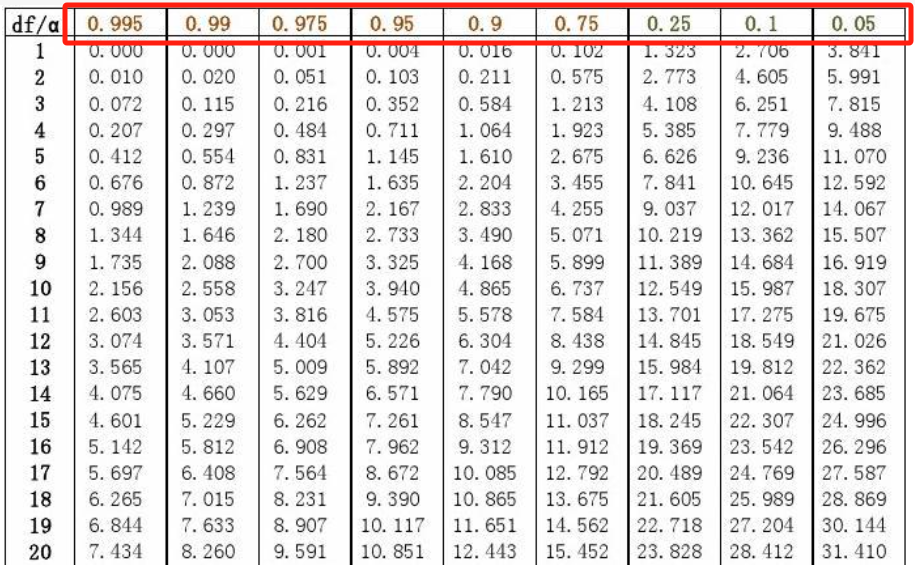
其中第一列对应自由度,红框中对应P值,不同自由度和P值对应的是卡方值。可以发现相同自由度下,卡方值越大,P值越小。反过来,如果P值越小,则卡方值越大,说明观察值与理论值偏离程度太大,应当拒绝原假设。
卡方分箱的基本思想在于,对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并,否则,它们应当保持分开。
卡方分箱步骤
(1) 初始分箱:将连续变量的值范围分成多个初始的区间(箱子)。可以基于等宽(每个箱子的值范围相同)或等频(每个箱子的样本数量大致相同)。
(2) 计算卡方统计量:使用以下公式计算卡方统计量,以评估箱子之间的独立性:
![]()
其中,A为实际频数,E为期望频数。
(3) 合并箱子:选择具有最小卡方统计量的箱子对进行合并。对于每一对相邻箱子,如果它们的卡方统计量小于某个阈值(基于p值),则认为这两个箱子在目标变量的分布上没有显著差异,可以合并。
(4) 迭代过程:重复步骤2到3,直到满足终止条件,如达到预定的箱子数量或无法进一步合并。
3.2 决策树分箱
决策树分箱通过评估不同的分割点来寻找最优的分箱边界,从而使得每个箱内的数据在目标变量上尽可能地同质。通过这种方式,决策树能够学习到数据中的复杂模式,并在分类或回归任务中提高模型的预测准确性。
在决策树分箱过程中,算法会遍历数据集中的所有特征,并尝试在每个特征上进行分割,以减少节点的不纯度。不纯度的度量可以基于信息熵或基尼不纯度等指标。算法递归地选择最优的分割点,直到满足停止条件,如达到预设的最大树深度或节点中的样本数量低于某个阈值。这种方法不仅提高了模型的泛化能力,还增强了模型的可解释性,因为分箱后的特征更容易被人类理解和解释。
4 无监督分箱
4.1 等距分箱
等距分箱(Equal-width binning)是一种简单的分箱技术,它将数据范围划分为若干个等宽的区间。等距分箱通常用于数据可视化和预处理,尤其是在数据分布比较均匀时。
import pandas as pddef equal_width_binning(df, column_name, num_bins, print_info=True):"""对指定的列进行等距分箱,并可选择打印分箱信息。参数:df : pd.DataFrame,输入的DataFrame。column_name : str,要分箱的列名。num_bins : int,箱的数量。print_info : bool, optional,是否打印分箱信息,默认为True。返回:pd.DataFrame包含原始数据和分箱结果的新DataFrame。"""# 检查列是否存在于DataFrame中if column_name not in df.columns:raise ValueError(f"Column '{column_name}' does not exist in the DataFrame.")# 检查箱的数量是否为正数if num_bins <= 0:raise ValueError("Number of bins must be a positive integer.")# 计算箱宽bin_width = (df[column_name].max() - df[column_name].min()) / num_bins# 创建箱边界bins = [df[column_name].min() + i * bin_width for i in range(num_bins + 1)]# 打印分箱信息if print_info:print(f"Column: {column_name}")print(f"Number of bins: {num_bins}")print(f"Bin width: {bin_width:.2f}")print("Bin edges:")print(bins)# 将数据分到箱中binned_column_name = f"{column_name}_binned"df[binned_column_name] = pd.cut(df[column_name], bins=bins, right=True)return df# 示例用法
# 假设df是您的DataFrame,'feature_column'是您要分箱的特征列名
df_binned = equal_width_binning(data, 'Age', num_bins=5)
df_binned对数据的‘Age’进行等距分段,运行的结果如下:

4.2 等频分箱
等频分箱(Equal-frequency binning)是一种将数据分为具有相同或几乎相同数据点数量的箱的技术。这种方法确保每个箱内的数据点数量大致相等,而不是箱的大小(宽度或范围)相等。等频分箱对于数据的分布不均匀或有极端值时特别有用。
import pandas as pddef equal_frequency_binning(df, column_name, num_bins, print_info=True):"""对指定的列进行等频分箱,并可选择打印分箱信息。参数:df : pd.DataFrame,输入的DataFrame。column_name : str,要分箱的列名。num_bins : int,箱的数量。print_info : bool, optional,是否打印分箱信息,默认为True。 返回:pd.DataFrame,包含原始数据和分箱结果的新DataFrame。"""# 参数检查if column_name not in df.columns:raise ValueError(f"Column '{column_name}' does not exist in the DataFrame.")if num_bins <= 0:raise ValueError("Number of bins must be a positive integer.")# 对数据进行排序df_sorted = df.sort_values(by=column_name)# 计算每个箱的大致数据点数量bin_size = len(df) // num_bins# 确定箱边界bins = [df_sorted[column_name].min()] # 包括最小值for i in range(1, num_bins):bin_bound = df_sorted.iloc[i * bin_size - 1][column_name]bins.append(bin_bound) # 包括最大值bins.append(df_sorted[column_name].max()) # 包括最大值# 打印分箱信息if print_info:print(f"Column: {column_name}")print(f"Number of bins: {num_bins}")print("Bin edges:")for i, bin_edge in enumerate(bins[:-1]):print(f"Bin {i}: x <= {bin_edge}")print(f"Bin {num_bins - 1}: x > {bins[-2]}")print("Bin centers and counts:")for i in range(num_bins):center = df_sorted.iloc[(i * bin_size + (i + 1) * bin_size) // 2][column_name]count = len(df_sorted[(df_sorted[column_name] > bins[i]) & (df_sorted[column_name] <= bins[i + 1])])print(f"Bin {i} center: {center}, count: {count}")# 将数据分到箱中df[f'{column_name}_binned'] = pd.cut(df[column_name], bins=bins, right=True, labels=range(num_bins))return df# 示例用法
# 假设df是您的DataFrame,'feature_column'是要分箱的特征列名
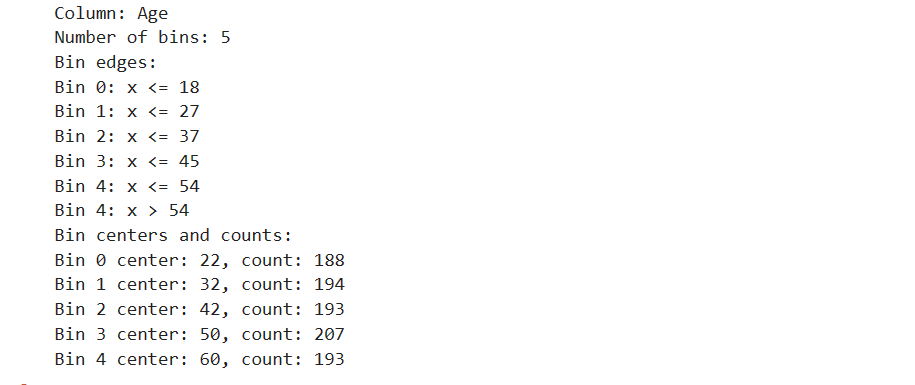
df_binned = equal_frequency_binning(data, 'Age', num_bins=5)
df_binned对数据的‘Age’进行等距分段,运行的结果如下,可也看到不同区间有大致相同的数量:
4.3 分位数分箱
分位数分箱(Quantile Binning)是一种基于数据分布的分箱技术,它利用数据的分位数来确定分箱边界。这种方法可以确保每个箱内的数据点具有相似的累积概率,从而使得每个箱在统计上是相似的。分位数分箱对于处理具有偏态分布的数据特别有用。
import pandas as pddef quantile_binning(df, column_name, num_bins, print_info=True):"""对指定的列进行分位数分箱,并可选择打印分位数信息。参数:df : pd.DataFrame,输入的DataFrame。column_name : str,要分箱的列名。num_bins : int,箱的数量。print_info : bool, optional,是否打印分位数信息,默认为True。返回:pd.DataFrame,包含原始数据和分箱结果的新DataFrame。"""# 参数检查if column_name not in df.columns:raise ValueError(f"Column '{column_name}' does not exist in the DataFrame.")if num_bins <= 1:raise ValueError("Number of bins must be greater than 1.")# 计算分位数quantiles = df[column_name].quantile([(i + 1) / num_bins for i in range(num_bins - 1)])# 确定箱边界bins = [df[column_name].min()] + quantiles.tolist() + [df[column_name].max()]# 打印分位数信息if print_info:print(f"Column: {column_name}")print(f"Number of bins: {num_bins}")print("Quantile cuts:")for i, quantile in enumerate(quantiles, start=1):print(f"Quantile {i}/{num_bins}: {quantile}")# 将数据分到箱中df[f'{column_name}_binned'] = pd.cut(df[column_name], bins=bins, right=True, labels=range(num_bins))return df# 示例用法
# 假设df是您的DataFrame,'feature_column'是您要分箱的特征列名
df_binned = quantile_binning(data, 'Age', num_bins=5)对数据的‘Age’进行等距分段,运行的结果如下,可也看到不同分位数下的分段点: