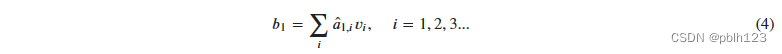参考阅读:https://zhuanlan.zhihu.com/p/74857888
文章目录
- 综合对比
- Estimator
- model_fn
- EstimatorSpec
- 关系
- 总结
- Estimator
- 主要功能
- 构造函数参数
- 示例用法
- 小结
- model_fn
- EstimatorSpec
- 字段解释
- 解释代码
- 用途
综合对比
Estimator、model_fn 和 EstimatorSpec 是 TensorFlow 中用于构建、训练和评估模型的三个核心组件。它们之间的关系可以总结如下:
Estimator
- 定义:
Estimator是 TensorFlow 提供的高层 API,用于简化和标准化模型的训练、评估和预测。 - 功能:
- 封装训练、评估和预测的逻辑。
- 管理检查点、日志记录和模型保存。
- 提供一致的接口来处理不同类型的模型。
- 参数:
model_fn: 定义模型的函数。model_dir: 模型保存目录。config: 执行环境的配置信息。params: 超参数字典。warm_start_from: 热启动配置。
model_fn
- 定义:
model_fn是一个函数,定义了模型的结构和行为。它由Estimator在训练、评估和预测时调用。 - 功能:
- 构建模型的计算图。
- 根据运行模式(TRAIN、EVAL、PREDICT)返回不同的操作。
- 接受特征、标签、模式、超参数和配置信息作为输入。
- 返回值:
- 返回一个
EstimatorSpec对象,定义了模型在不同模式下的行为。
- 返回一个
EstimatorSpec
- 定义:
EstimatorSpec是一个对象,包含了模型在训练、评估和预测模式下的所有必要信息。 - 功能:
- 定义模型的预测、损失、训练操作和评估指标。
- 提供一致的接口,使
Estimator能够在不同模式下正确运行模型。
- 字段:
mode: 运行模式(TRAIN、EVAL、PREDICT)。predictions: 预测结果。loss: 损失值。train_op: 训练操作。eval_metric_ops: 评估指标操作。export_outputs: 导出输出。training_chief_hooks,training_hooks,scaffold,evaluation_hooks,prediction_hooks: 各种钩子和脚手架对象,用于在不同阶段执行自定义操作。
关系
-
Estimator使用model_fn:Estimator调用model_fn来构建模型的计算图并定义其行为。model_fn接受特征、标签、模式、超参数和配置信息,并返回一个EstimatorSpec对象。
-
model_fn返回EstimatorSpec:model_fn根据当前的运行模式(TRAIN、EVAL、PREDICT)创建并返回一个EstimatorSpec对象。EstimatorSpec对象包含了模型在当前模式下所需的所有操作和输出。
-
Estimator使用EstimatorSpec:Estimator使用EstimatorSpec中定义的操作来执行训练、评估和预测。- 根据
EstimatorSpec中的信息,Estimator知道如何处理模型的预测、损失计算和训练步骤。
总结
Estimator是高层接口,用于管理和运行模型。model_fn是用户定义的函数,用于构建模型的计算图并返回EstimatorSpec。EstimatorSpec定义了模型在不同模式下的行为,由model_fn返回,并由Estimator使用。
Estimator
Estimator 是 TensorFlow 提供的一个高层 API,用于简化模型的训练和评估。它封装了一个模型,模型通过 model_fn 指定。Estimator 负责处理训练、评估和预测所需的所有操作,并将结果输出到指定的目录。
主要功能
- 模型训练、评估和预测:
Estimator封装了这些操作,简化了模型的开发和部署过程。 - 模型保存和恢复: 所有输出(如检查点、事件文件等)都写入
model_dir,或其子目录。这样可以方便地保存和恢复模型。 - 运行配置: 通过
config参数,Estimator可以获取有关执行环境的信息,并将其传递给model_fn。 - 超参数传递: 通过
params参数,Estimator可以将超参数传递给model_fn和输入函数。
构造函数参数
-
model_fn: 模型函数,定义了如何构建模型。它接受以下参数:
features: 从input_fn返回的特征,通常是Tensor或Tensor字典。labels: 从input_fn返回的标签,通常是Tensor或Tensor字典。在预测模式下,labels为None。mode: 运行模式,可以是TRAIN、EVAL或PREDICT。params: 超参数字典,包含传递给Estimator的超参数。config:RunConfig对象,包含执行环境的配置信息。
-
model_dir: 模型参数、图等的保存目录,也可以用于从目录加载检查点以继续训练之前保存的模型。
-
config:
RunConfig配置对象,包含执行环境的配置信息。如果model_fn函数也定义config这个变量,则会将config传给model_fn。 -
params: 超参数字典,包含传递给
model_fn的超参数。 -
warm_start_from: 检查点或
SavedModel的文件路径,用于热启动,或一个WarmStartSettings对象以完全配置热启动。
示例用法
-
创建一个
Estimator实例:estimator = tf.estimator.DNNClassifier(feature_columns=[categorical_feature_a_emb, categorical_feature_b_emb],hidden_units=[1024, 512, 256],warm_start_from="/path/to/checkpoint/dir" ) -
定义
model_fn:def my_model_fn(features, labels, mode, params):# 构建模型logits = build_model(features, mode, params)predictions = {'classes': tf.argmax(input=logits, axis=1),'probabilities': tf.nn.softmax(logits)}# PREDICT 模式if mode == tf.estimator.ModeKeys.PREDICT:return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)# 计算损失loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)# 训练操作if mode == tf.estimator.ModeKeys.TRAIN:optimizer = tf.train.AdamOptimizer(learning_rate=params['learning_rate'])train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)# 评估指标eval_metric_ops = {'accuracy': tf.metrics.accuracy(labels=labels, predictions=predictions['classes'])}return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops) -
使用
Estimator进行训练、评估和预测:# 训练 estimator.train(input_fn=train_input_fn, steps=1000)# 评估 eval_result = estimator.evaluate(input_fn=eval_input_fn) print(eval_result)# 预测 predictions = estimator.predict(input_fn=predict_input_fn) for pred in predictions:print(pred)
小结
Estimator 提供了一种结构化的方法来定义和管理 TensorFlow 模型,使得模型的训练、评估和预测更加方便和标准化。它通过 model_fn 将模型的构建与训练、评估和预测逻辑分离,并且通过配置和参数化提供了灵活性。
model_fn
输入:
features: 从input_fn返回的特征,通常是Tensor或Tensor字典。labels: 从input_fn返回的标签,通常是Tensor或Tensor字典。在预测模式下,labels为None。mode: 运行模式,可以是TRAIN、EVAL或PREDICT。params: 超参数字典,包含传递给Estimator的超参数。config:RunConfig对象,包含执行环境的配置信息。
返回值:
一个EstimatorSpec
前两个参数是从输入函数中返回的特征和标签批次;也就是说,features 和 labels 是模型将使用的数据。
params 是一个字典,它可以传入许多参数用来构建网络或者定义训练方式等。例如通过设置params[‘n_classes’]来定义最终输出节点的个数等。
config 通常用来控制checkpoint或者分布式什么,这里不深入研究。
mode 参数表示调用程序是请求训练、评估还是预测,分别通过tf.estimator.ModeKeys.TRAIN / EVAL / PREDICT 来定义。另外通过观察DNNClassifier的源代码可以看到,mode这个参数并不用手动传入,因为Estimator会自动调整。例如当你调用estimator.train(…)的时候,mode则会被赋值tf.estimator.ModeKeys.TRAIN。
模型有训练,验证和测试三种阶段,而且对于不同模式,对数据有不同的处理方式。例如在训练阶段,我们需要将数据喂给模型,模型基于输入数据给出预测值,然后我们在通过预测值和真实值计算出loss,最后用loss更新网络参数,而在评估阶段,我们则不需要反向传播更新网络参数,换句话说,model_fn需要对三种模式设置三套代码。
EstimatorSpec
collections.namedtuple 是 Python 标准库中的一个函数,用于创建不可变的、具名的元组(named tuple)。这些具名元组可以像类一样使用,有字段名称,使代码更具可读性和可维护性。
在这段代码中,collections.namedtuple 被用来创建一个名为 EstimatorSpec 的具名元组,它包含了一组用于定义模型在不同模式下行为的字段。以下是每个字段的解释:
字段解释
- mode: 模式,表示当前的运行模式,可以是训练(TRAIN)、评估(EVAL)或预测(PREDICT)模式。
- predictions: 预测值,可以是一个
Tensor或Tensor字典,用于预测模式下输出结果。 - loss: 损失值,一个标量
Tensor,表示模型的损失,用于训练和评估模式。 - train_op: 训练操作,表示在训练模式下执行的操作(通常是优化步骤)。
- eval_metric_ops: 评估指标操作,是一个字典,包含评估模式下的度量结果。
- export_outputs: 导出输出,是一个字典,定义了模型在导出为
SavedModel时的输出签名。 - training_chief_hooks: 主训练钩子,是一个迭代器,包含在主 worker 上运行的
SessionRunHook对象。 - training_hooks: 训练钩子,是一个迭代器,包含在所有 worker 上运行的
SessionRunHook对象。 - scaffold: 脚手架,是一个
tf.train.Scaffold对象,用于设置初始化、保存和恢复操作。 - evaluation_hooks: 评估钩子,是一个迭代器,包含在评估过程中运行的
SessionRunHook对象。 - prediction_hooks: 预测钩子,是一个迭代器,包含在预测过程中运行的
SessionRunHook对象。
解释代码
collections.namedtuple('EstimatorSpec', ['mode', 'predictions', 'loss', 'train_op', 'eval_metric_ops','export_outputs', 'training_chief_hooks', 'training_hooks', 'scaffold','evaluation_hooks', 'prediction_hooks'
])
这行代码创建了一个名为 EstimatorSpec 的具名元组类,它包含了上述的这些字段。EstimatorSpec 类可以用于存储和传递这些字段的值,使得在模型函数(model_fn)中可以方便地定义和返回这些值。
用途
EstimatorSpec 主要用于 TensorFlow 的 Estimator API 中,以统一的方式定义模型的各个组成部分。通过使用 EstimatorSpec,可以确保模型在不同模式下的行为是一致且正确的。例如:
- 在训练模式下,必须提供
loss和train_op。 - 在评估模式下,必须提供
loss。 - 在预测模式下,必须提供
predictions。
使用 EstimatorSpec,可以更简洁和清晰地定义模型的各个部分,并且通过具名元组的方式,使代码更加可读和易于维护。