目录
一、DataSophon是什么
1.1 DataSophon概述
1.2 架构概览
1.3 设计思想
二、集成组件
三、环境准备
四、安装kerberos服务
4.1 Zookeeper
4.2 HDFS
4.3 HBase
4.4 YARN
4.5 hive
【DataSophon】大数据管理平台DataSophon-1.2.1安装部署详细流程-CSDN博客
【DataSophon】大数据服务组件之Flink升级_datasophon1.2 升级flink-CSDN博客
【DataSophon】大数据管理平台DataSophon-1.2.1基本使用-CSDN博客
一、DataSophon是什么
1.1 DataSophon概述
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。
主要特性有:
- 快速部署,可快速完成300个节点的大数据集群部署
- 兼容复杂环境,极少的依赖使其很容易适配各种复杂环境
- 监控指标全面丰富,基于生产实践展示用户最关心的监控指标
- 灵活便捷的告警服务,可实现用户自定义告警组和告警指标
- 可扩展性强,用户可通过配置的方式集成或升级大数据组件
官方地址:DataSophon | DataSophon
GITHUB地址:datasophon/README_CN.md at dev · datavane/datasophon

1.2 架构概览

1.3 设计思想
为设计出轻量级,高性能,高可扩的,可满足国产化环境要求的大数据集群管理平台。需满足以下设计要求:
(1)一次编译,处处运行,项目部署仅依赖java环境,无其他系统环境依赖。
(2)DataSophon工作端占用资源少,不占用大数据计算节点资源。
(3)可扩展性高,可通过配置的方式集成托管第三方组件。
二、集成组件
各集成组件均进行过兼容性测试,并稳定运行于300+个节点规模的大数据集群,日处理数据量约4000亿条。在海量数据下,各大数据组件调优成本低,平台默认展示用户关心和需要调优的配置。如下DDP1.2.1服务版本信息:
| 序号 | 名称 | 版本 | 描述 |
| 1 | HDFS | 3.3.3 | 分布式大数据存储 |
| 2 | YARN | 3.3.3 | 分布式资源调度与管理平台 |
| 3 | ZooKeeper | 3.5.10 | 分布式协调系统 |
| 4 | FLINK | 1.16.2 | 实时计算引擎 |
| 5 | DolphoinScheduler | 3.1.8 | 分布式易扩展的可视化工作流任务调度平台 |
| 6 | StreamPark | 2.1.1 | 流处理极速开发框架,流批一体&湖仓一体的云原生平台 |
| 7 | Spark | 3.1.3 | 分布式计算系统 |
| 8 | Hive | 3.1.0 | 离线数据仓库 |
| 9 | Kafka | 2.4.1 | 高吞吐量分布式发布订阅消息系统 |
| 10 | Trino | 367 | 分布式Sql交互式查询引擎 |
| 11 | Doris | 1.2.6 | 新一代极速全场景MPP数据库 |
| 12 | Hbase | 2.4.16 | 分布式列式存储数据库 |
| 13 | Ranger | 2.1.0 | 权限控制框架 |
| 14 | ElasticSearch | 7.16.2 | 高性能搜索引擎 |
| 15 | Prometheus | 2.17.2 | 高性能监控指标采集与告警系统 |
| 16 | Grafana | 9.1.6 | 监控分析与数据可视化套件 |
| 17 | AlertManager | 0.23.0 | 告警通知管理系统 |
三、环境准备
| IP | 主机名 |
| 192.168.2.115 | ddp01 |
| 192.168.2.116 | ddp02 |
| 192.168.2.120 | ddp03 |
四、安装kerberos服务
选择kerberos服务
选择 KDC和 Kadmin安装节点
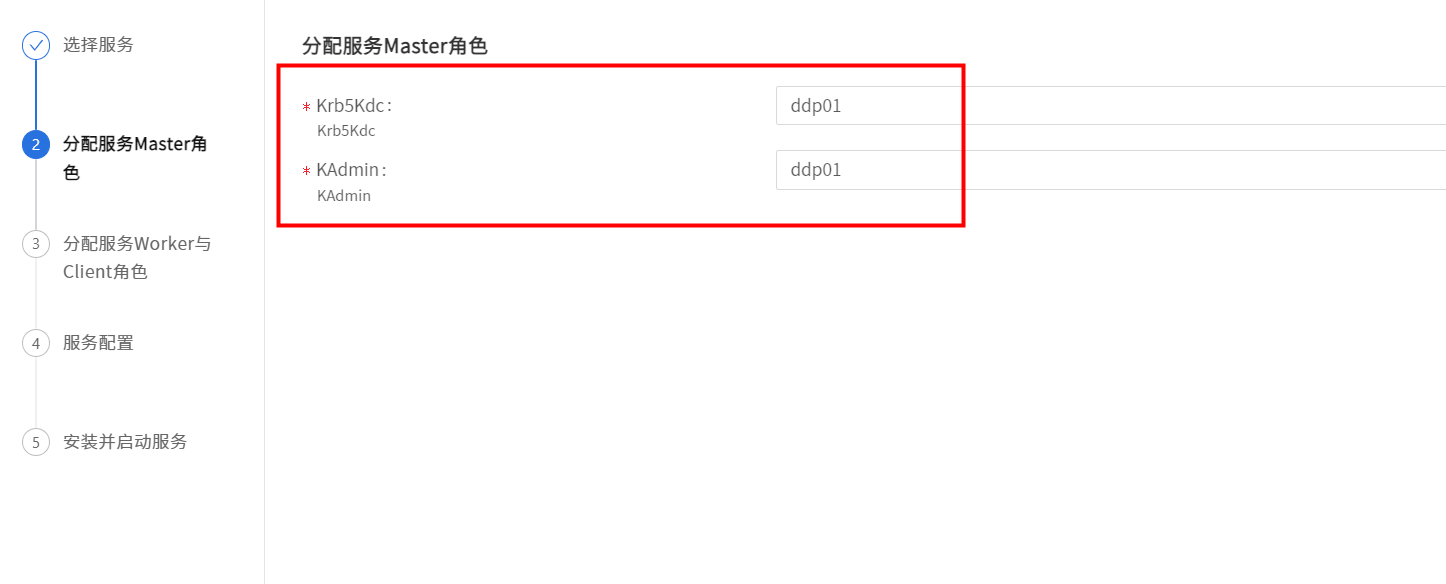
选择Client安装节点

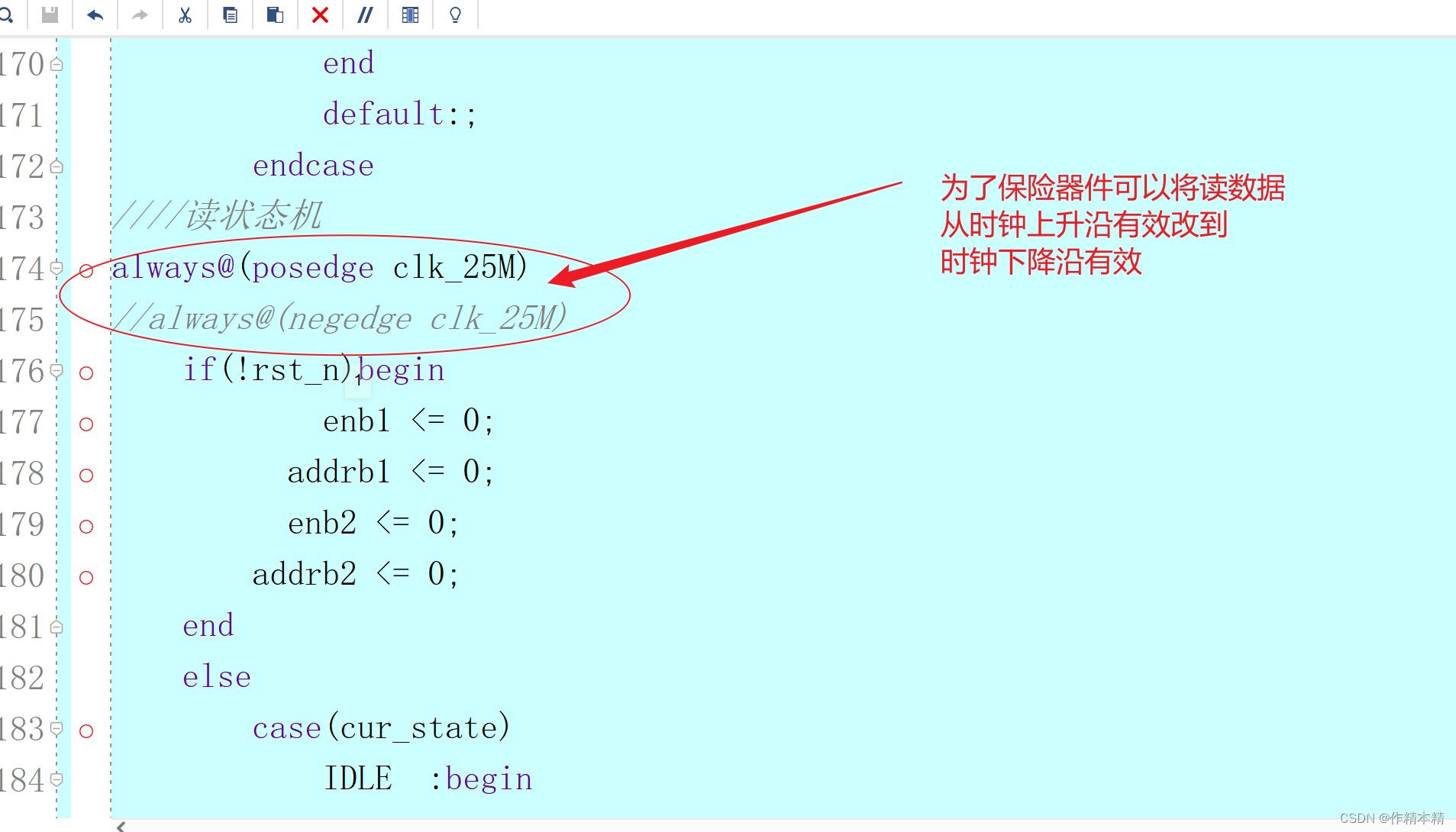
域名使用默认的 HADOOP.COM ,如需修为改自定义 则需要比如在HBase zk-jaas.ftl 改为传参,因为他默认是写死为 HADOOP.COM。

如下是datasophon-woker ,下的 zk-jaas.ftl默认配置
修改后的
<#assign realm = zkRealm!"">
<#if realm?has_content>Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truekeyTab="/etc/security/keytab/hbase.keytab"useTicketCache=falseprincipal="hbase/${host}@${realm}";};
</#if>安装完成
4.1 Zookeeper
enableKerberos 点击开启即可后重启即可。

4.2 HDFS
如下图 按钮开启kerberos
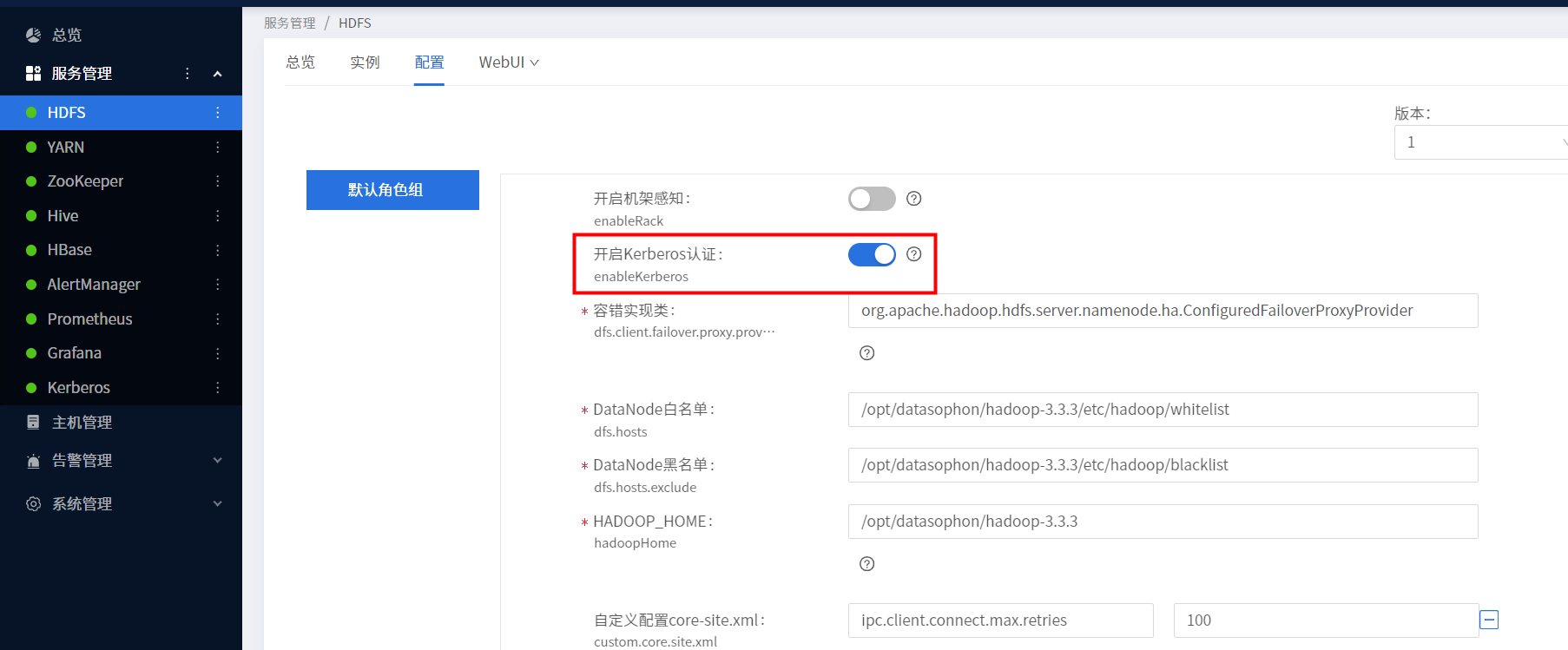
开启之后我们需要重启HDFS服务,全部重启可能会报错,我们可以对服务内部的角色逐个重启。

4.3 HBase
开启

HBase2.4.16 开启Kerberos后 HMaster启动报错
2024-06-12 10:40:46,421 ERROR [main] regionserver.HRegionServer: Failed construction RegionServer
org.apache.hadoop.hbase.ZooKeeperConnectionException: master:16000-0x1000ff4d1270007, quorum=ddp01:2181,ddp02:2181,ddp03:2181, baseZNode=/hbase Unexpected KeeperException creating base nodeat org.apache.hadoop.hbase.zookeeper.ZKWatcher.createBaseZNodes(ZKWatcher.java:258)at org.apache.hadoop.hbase.zookeeper.ZKWatcher.<init>(ZKWatcher.java:182)at org.apache.hadoop.hbase.zookeeper.ZKWatcher.<init>(ZKWatcher.java:135)at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:662)at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:425)at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)at java.lang.reflect.Constructor.newInstance(Constructor.java:423)at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2926)at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:247)at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:145)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:140)at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2946)
Caused by: org.apache.zookeeper.KeeperException$InvalidACLException: KeeperErrorCode = InvalidACL for /hbaseat org.apache.zookeeper.KeeperException.create(KeeperException.java:128)at org.apache.zookeeper.KeeperException.create(KeeperException.java:54)at org.apache.zookeeper.ZooKeeper.create(ZooKeeper.java:1538)at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.createNonSequential(RecoverableZooKeeper.java:525)at org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper.create(RecoverableZooKeeper.java:505)at org.apache.hadoop.hbase.zookeeper.ZKUtil.createWithParents(ZKUtil.java:874)at org.apache.hadoop.hbase.zookeeper.ZKUtil.createWithParents(ZKUtil.java:856)at org.apache.hadoop.hbase.zookeeper.ZKWatcher.createBaseZNodes(ZKWatcher.java:249)... 14 more
2024-06-12 10:40:46,424 ERROR [main] master.HMasterCommandLine: Master exiting
问题解决:没有使用默认的HADOOP域修改为自定义之后有的配置文件无法完成动态更新,包括配置页面也是如此需要手动更新,那我之后也就采用了默认的 HADOOP域。
zk-jaas.conf

或者可以修改zk_jaas.ftl安装文件
<#assign realm = zkRealm!"">
<#if realm?has_content>Client {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truekeyTab="/etc/security/keytab/hbase.keytab"useTicketCache=falseprincipal="hbase/${host}@${realm}";};
</#if>修改后接着报错如下:
2024-06-14 15:07:23,137 INFO [Thread-24] hdfs.DataStreamer: Exception in createBlockOutputStream
java.io.IOException: Invalid token in javax.security.sasl.qop: Dat org.apache.hadoop.hdfs.protocol.datatransfer.sasl.DataTransferSaslUtil.readSaslMessage(DataTransferSaslUtil.java:220)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.doSaslHandshake(SaslDataTransferClient.java:553)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.getSaslStreams(SaslDataTransferClient.java:455)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.send(SaslDataTransferClient.java:298)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend(SaslDataTransferClient.java:245)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.socketSend(SaslDataTransferClient.java:203)at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.socketSend(SaslDataTransferClient.java:193)at org.apache.hadoop.hdfs.DataStreamer.createBlockOutputStream(DataStreamer.java:1705)at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1655)at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:710)
2024-06-14 15:07:23,138 WARN [Thread-24] hdfs.DataStreamer: Abandoning BP-268430271-192.168.2.115-1717646949749:blk_1073742094_1293
2024-06-14 15:07:23,159 WARN [Thread-24] hdfs.DataStreamer: Excluding datanode DatanodeInfoWithStorage[192.168.2.120:1026,DS-3dec681b-fa1e-4bdc-89bf-0fd969f7ddbe,DISK]
2024-06-14 15:07:23,187 INFO [Thread-24] hdfs.DataStreamer: Exception in createBlockOutputStream
java.io.IOException: Invalid token in javax.security.sasl.qop:
查询GitHub看是HBase 开启kerberos 版本不兼容 ,启动有问题
Apache HBase – Apache HBase Downloads

查看 Hadoop与HBase的版本兼容性:Apache HBase® Reference Guide
[Bug] [Module Name] v2.4.16 hbase in kerberos did't run · Issue #445 · datavane/datasophon · GitHub

如上测试 使用 HBase2.4.16 那我们换成2.0.2 再次测试安装 ,HBase 版本换为2.0.2 需要修改启动脚本。
bin/hbase-daemon.sh 
增加监控信息,至于修改脚本的具体信息我们可以参考HBase 2.4.16 的写法修改即可。
bin/hbase
修改完成后,我们再次安装 HBase 并开启kerberos成功,至于高版本的兼容性 我们后面再研究。
4.4 YARN
NodeManager启动报错如下:
2024-06-12 09:23:55,033 WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.privileged.PrivilegedOperationExecutor: Shell execution returned exit code: 127. Privileged Execution Operation Stderr:
/opt/datasophon/hadoop-3.3.3/bin/container-executor: error while loading shared libraries: libcrypto.so.1.1: cannot open shared object file: No such file or directoryStdout:
Full command array for failed execution:
[/opt/datasophon/hadoop-3.3.3/bin/container-executor, --checksetup]
2024-06-12 09:23:55,034 WARN org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor: Exit code from container executor initialization is : 127
org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.privileged.PrivilegedOperationException: ExitCodeException exitCode=127: /opt/datasophon/hadoop-3.3.3/bin/container-executor: error while loading shared libraries: libcrypto.so.1.1: cannot open shared object file: No such file or directoryat org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.privileged.PrivilegedOperationExecutor.executePrivilegedOperation(PrivilegedOperationExecutor.java:182)at org.apache.hadoop.yarn.server.nodemanager.containermanager.linux.privileged.PrivilegedOperationExecutor.executePrivilegedOperation(PrivilegedOperationExecutor.java:208)at org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor.init(LinuxContainerExecutor.java:330)at org.apache.hadoop.yarn.server.nodemanager.NodeManager.serviceInit(NodeManager.java:403)at org.apache.hadoop.service.AbstractService.init(AbstractService.java:164)at org.apache.hadoop.yarn.server.nodemanager.NodeManager.initAndStartNodeManager(NodeManager.java:962)at org.apache.hadoop.yarn.server.nodemanager.NodeManager.main(NodeManager.java:1042)
Caused by: ExitCodeException exitCode=127: /opt/datasophon/hadoop-3.3.3/bin/container-executor: error while loading shared libraries: libcrypto.so.1.1: cannot open shared object file: No such file or directory
执行命令报错如下:
/opt/datasophon/hadoop-3.3.3/bin/container-executor
那我们就安装openssl
# 下载libcrypto.so.1.1o.tar.gz 执行如下命令
cd ~
wget https://www.openssl.org/source/openssl-1.1.1o.tar.gz# 解压libcrypto.so.1.1o.tar.gz 执行如下命令
sudo tar -zxvf openssl-1.1.1o.tar.gz# 切换到解压好的openssl-1.1.1o目录下
cd openssl-1.1.1o#编译安装
sudo ./config
sudo make
sudo make install
既然有这个库,那就好办了,把它创建一下软链到/usr/lib64的路径中
ln -s /usr/local/lib64/libcrypto.so.1.1 /usr/lib64/libcrypto.so.1.1再次启动NodeManager

认证过后,运行任务可能报HDFS访问的权限问题:

我们修改下权限
kinit -kt /etc/security/keytab/nn.service.keytab nn/ddp01@WINNER.COM
hdfs dfs -chmod -R 777 /tmp/hadoop-yarn/4.5 hive
开启 Kerberos

HiveServer2有warning信息 我们不管
2024-06-21 15:05:51 INFO HiveServer2:877 - Stopping/Disconnecting tez sessions.
2024-06-21 15:05:51 INFO HiveServer2:883 - Stopped tez session pool manager.
2024-06-21 15:05:51 WARN HiveServer2:1064 - Error starting HiveServer2 on attempt 1, will retry in 60000ms
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfigurationat org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolSession$AbstractTriggerValidator.startTriggerValidator(TezSessionPoolSession.java:74)at org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolManager.initTriggers(TezSessionPoolManager.java:207)at org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolManager.startPool(TezSessionPoolManager.java:114)at org.apache.hive.service.server.HiveServer2.initAndStartTezSessionPoolManager(HiveServer2.java:839)at org.apache.hive.service.server.HiveServer2.startOrReconnectTezSessions(HiveServer2.java:822)at org.apache.hive.service.server.HiveServer2.start(HiveServer2.java:745)at org.apache.hive.service.server.HiveServer2.startHiveServer2(HiveServer2.java:1037)at org.apache.hive.service.server.HiveServer2.access$1600(HiveServer2.java:140)at org.apache.hive.service.server.HiveServer2$StartOptionExecutor.execute(HiveServer2.java:1305)at org.apache.hive.service.server.HiveServer2.main(HiveServer2.java:1149)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.util.RunJar.run(RunJar.java:323)at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
Caused by: java.lang.ClassNotFoundException: org.apache.tez.dag.api.TezConfigurationat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)... 16 more
命令行show databases报错如下:
2024-06-25 09:26:17 WARN ThriftCLIService:795 - Error fetching results:
org.apache.hive.service.cli.HiveSQLException: java.io.IOException: java.io.IOException: Can't get Master Kerberos principal for use as renewerat org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:465)at org.apache.hive.service.cli.operation.OperationManager.getOperationNextRowSet(OperationManager.java:309)at org.apache.hive.service.cli.session.HiveSessionImpl.fetchResults(HiveSessionImpl.java:905)at org.apache.hive.service.cli.CLIService.fetchResults(CLIService.java:561)at org.apache.hive.service.cli.thrift.ThriftCLIService.FetchResults(ThriftCLIService.java:786)at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1837)at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1822)at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)at org.apache.hadoop.hive.metastore.security.HadoopThriftAuthBridge$Server$TUGIAssumingProcessor.process(HadoopThriftAuthBridge.java:647)at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:750)
Caused by: java.io.IOException: java.io.IOException: Can't get Master Kerberos principal for use as renewerat org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:602)at org.apache.hadoop.hive.ql.exec.FetchOperator.pushRow(FetchOperator.java:509)at org.apache.hadoop.hive.ql.exec.FetchTask.fetch(FetchTask.java:146)at org.apache.hadoop.hive.ql.Driver.getResults(Driver.java:2691)at org.apache.hadoop.hive.ql.reexec.ReExecDriver.getResults(ReExecDriver.java:229)at org.apache.hive.service.cli.operation.SQLOperation.getNextRowSet(SQLOperation.java:460)... 13 more
Caused by: java.io.IOException: Can't get Master Kerberos principal for use as renewerat org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodesInternal(TokenCache.java:134)at org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodesInternal(TokenCache.java:102)at org.apache.hadoop.mapreduce.security.TokenCache.obtainTokensForNamenodes(TokenCache.java:81)at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:221)at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:332)at org.apache.hadoop.hive.ql.exec.FetchOperator.generateWrappedSplits(FetchOperator.java:425)at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextSplits(FetchOperator.java:395)at org.apache.hadoop.hive.ql.exec.FetchOperator.getRecordReader(FetchOperator.java:314)at org.apache.hadoop.hive.ql.exec.FetchOperator.getNextRow(FetchOperator.java:540)... 18 more
执行 insert 语句报错如下:
2024-06-25 14:20:56,454 Stage-1 map = 0%, reduce = 0%
2024-06-25 14:20:56 INFO Task:1224 - 2024-06-25 14:20:56,454 Stage-1 map = 0%, reduce = 0%
2024-06-25 14:20:56 WARN Counters:235 - Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
Ended Job = job_1719295126228_0001 with errors
2024-06-25 14:20:56 ERROR Task:1247 - Ended Job = job_1719295126228_0001 with errors
Error during job, obtaining debugging information...
2024-06-25 14:20:56 ERROR Task:1247 - Error during job, obtaining debugging information...
2024-06-25 14:20:57 INFO YarnClientImpl:504 - Killed application application_1719295126228_0001
2024-06-25 14:20:57 INFO ReOptimizePlugin:70 - ReOptimization: retryPossible: false
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
2024-06-25 14:20:57 ERROR Driver:1247 - FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
2024-06-25 14:20:57 INFO Driver:1224 - MapReduce Jobs Launched:
2024-06-25 14:20:57 WARN Counters:235 - Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
2024-06-25 14:20:57 INFO Driver:1224 - Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
2024-06-25 14:20:57 INFO Driver:1224 - Total MapReduce CPU Time Spent: 0 msec
2024-06-25 14:20:57 INFO Driver:2531 - Completed executing command(queryId=hdfs_20240625142022_e1ec801e-ee1d-411e-b96d-d4141b5e2918); Time taken: 33.984 seconds
2024-06-25 14:20:57 INFO Driver:285 - Concurrency mode is disabled, not creating a lock manager
2024-06-25 14:20:57 INFO HiveConf:5034 - Using the default value passed in for log id: 202267cf-76bc-43ff-8545-67bd0b4d73ce
2024-06-25 14:20:57 INFO SessionState:449 - Resetting thread name to main
如上问题是 没有安装yarn 服务,大意了,这种服务组件强依赖的检查机制还需要升级一下。
DDP集成rananger:
datasophon集成rangerusersync · 语雀
DDP集成Hue:
datasophon集成hue · 语雀
zookeeper、hbase集成kerberos - 北漂-boy - 博客园
Kerberos安全认证-连载11-HBase Kerberos安全配置及访问_kerberos hbase(4)_hbase2.2.6适配java版本-CSDN博客
HBase 官网:Apache HBase® Reference Guide
Kerberos安全认证-连载11-HBase Kerberos安全配置及访问_kerberos hbase(4)_hbase 配置 kerberos 认证-CSDN博客
/opt/datasophon/hadoop-3.3.3/ranger-hdfs-plugin/enable-hdfs-plugin.sh