一、引入
虽然之前写过 Attention 的文章,但现在回头看之前写的一些文章,感觉都好啰嗦,正好下一篇要写的 Stable Diffusion 中有 cross-attention,索性就再单拎出来简单说一下 Attention 吧,那么这篇文章的作用有两个:第一是为 Stable Diffusion 做补充,第二是为后续的 Vision Transformer 和 Swin Transformer 做铺垫。
为了保证篇幅开头的完整性,还得啰嗦一下 Transformer,它最开始提出是针对nlp领域的,在此之前除了seq2seq这种encoder-decoder架构,大家主要还是用的rnn、lstm这种时序网络,像rnn系列网络它是有问题的,首先就是它记忆的长度是有限的,其次是无法并行化计算,也就是必须要先计算xt时刻的数据才能计算时刻xt+1,这就导致效率低下。针对这些问题,Google就提出了 Transformer,在 Transformer 中有两个非常重要的模块:Self Attention 和 Multi-Head Attention,本文会先介绍 Attention 的基本思想,然后再对 Self Attention 和 Multi-Head Attention 进行概述,最后再讲本文的主题 Cross Attention,其实 Cross Attention 非常简单,不要被它的名字吓到,一定要理解透彻前面的 Multi-Head Attention。
二、Attention 思想
注意力机制的核心目标是从众多信息中选择出对当前任务目标更关键的信息,将注意力放在上面。其本质思想就是【从大量信息中】【有选择的筛选出】【少量重要信息】并将注意力【聚焦到这些重要信息上】,【忽略大多不重要的信息】。聚焦的过程体现在【权重系数】的计算上,权重越大越聚焦于其对应的value值上。即权重代表了信息的重要性,而value是其对应的信息。
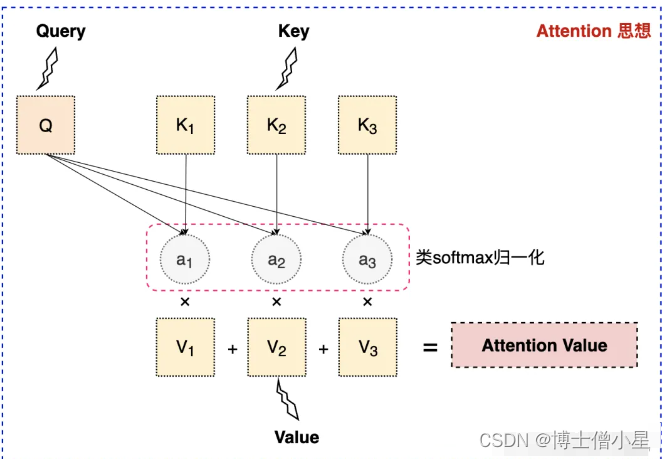
Q是Query,是输入的信息,即当前任务的目标,用于和key进行匹配;
K和V分别是Key和Value,一般是相同的数据,比如原始文本经过Embedding后的表征;
通过计算Q与K之间的相关性,得到权重a,再将权重a进行类似于softmax的归一化操作,表示不同的key对于Q的重要程度,或者说权重a越大,我们就会把更多的注意力放到其对应的value上;
用权重a再与对应的Value相乘,意思是我们从Value中提取到的重要信息,或者说是对Q有用的信息;
加权后的结果再求和就得到了针对Query的Attention输出,用新的输出代替原来的Q参与之后的一系列运算。
我们以机器翻译为例进一步加深理解,假设有文本“汤姆追逐杰瑞”,方便起见我们规定词库单词就为tom、chase、jerry,当我们对“汤姆”进行翻译的时候,套用上述 Attention 机制:

三、Self Attention
我们可以观察上面的传统 Attention 机制,我们可以发现每个词只表示自身的含义,不包含上下文的语义信息。而 Self Attention 则顾名思义,它指的是关注输入序列元素之间的关系,也就是说每个元素都有自己的Q、K、V,经过 Self Attention 对词向量进行重构后,使得词向量即包含自己的信息,又综合考虑了上下文的语义信息,如下图所示:
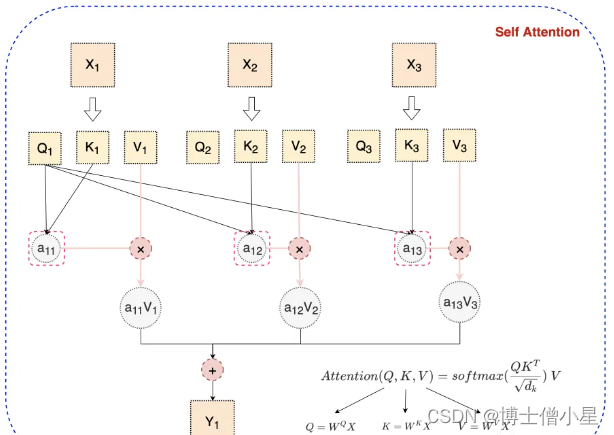


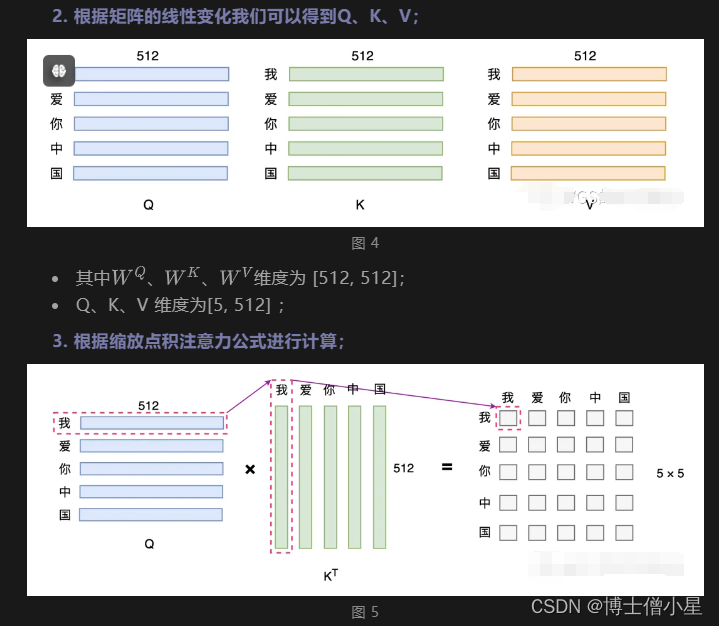
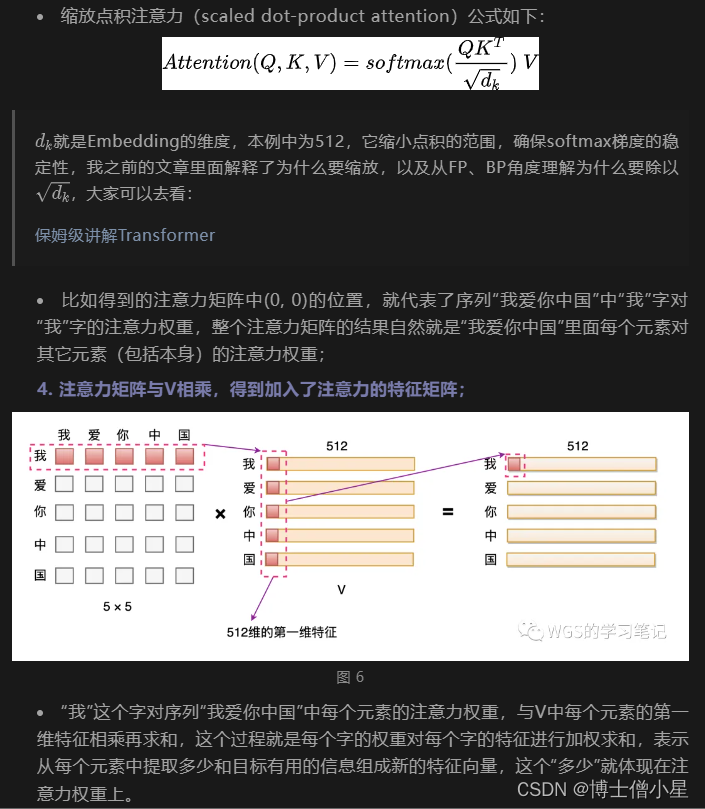
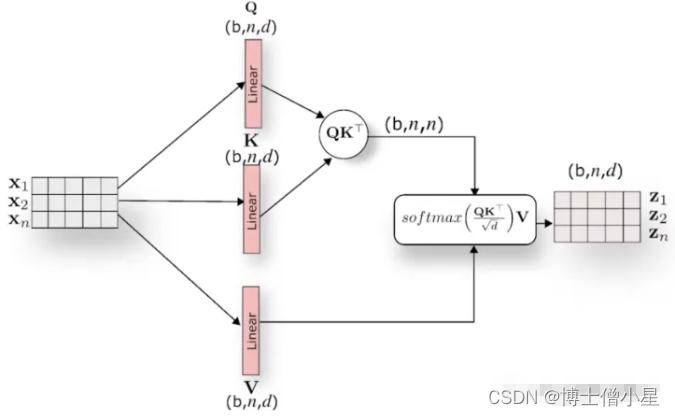
四、Multi-Head Attention
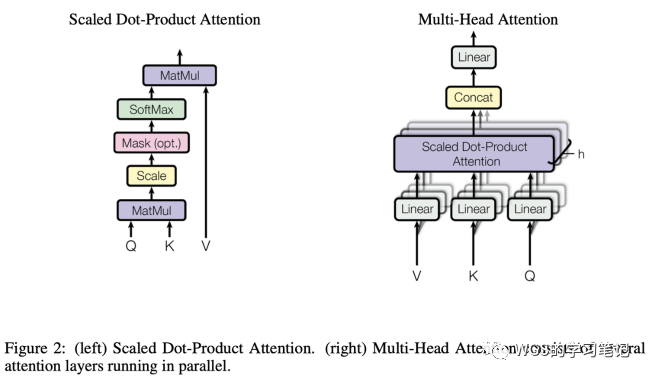

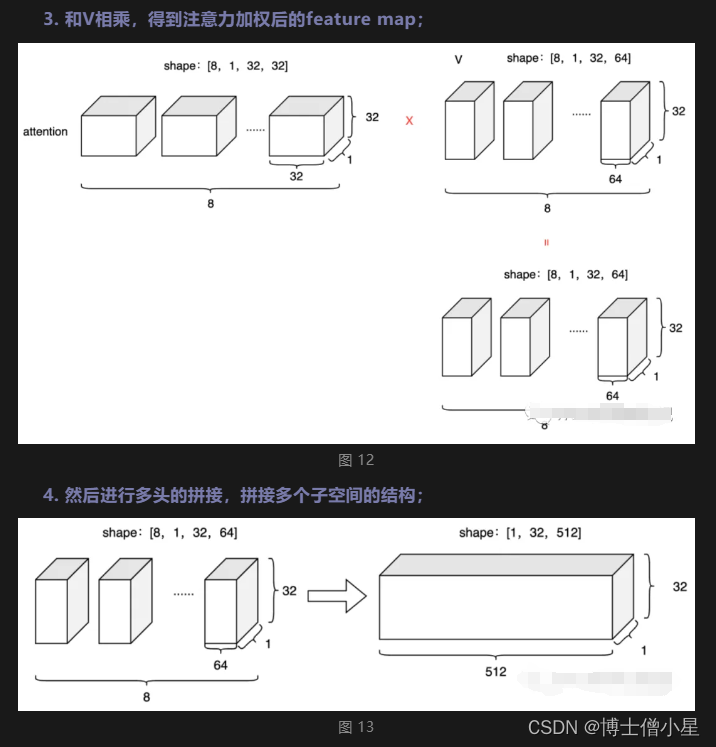
在理解了 Self Attention 之后,Multi-Head Attention 就很容易了,它相当于 h 个不同的 Self Attention 的集成,说白了就是对其的堆叠。
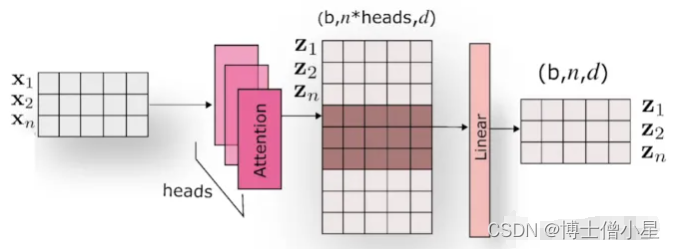

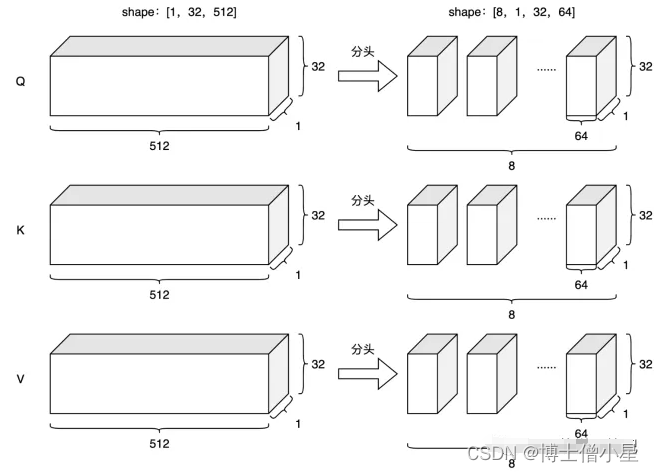

Multi-Head Attention的优点:
多头保证了我们可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
能够捕捉到特征的多样性,说白了就是因为有多头,可以从多个角度去理解内容。
换句话说,经过注意力之后的矩阵会有自己理解的语义信息,那么多个头就会有多个不同的理解。
通过注意力可以充分的解读上下文的语义信息,能够充分的带入到一个场景中做理解。
五、Padding Mask
在做注意力的时候,我们还需要进行 padding mask 来消除 padding 部分的影响,因为有softmax的存在,padding项的注意力也会作为x^{i}进行缩放,首先对padding项添加注意力本身就不合理,其次它作为x^{i}就相当于也会产生权重,所以要消除 padding 带来的影响。
具体而言,我们会在输入序列中定位到 padding 的位置,然后标记为1,其余标记为0,然后构建一个与 attention 矩阵同维度的mask矩阵,其中填充位置对应元素为1,其它位置对应元素为0,关键代码如下:
# 构建padding mask矩阵
pad_mask = input_ids.eq(0) # 逻辑矩阵pad_mask:将填充位置标记为True,其他位置标记为False [batch_size, seq_len]
# 增加维度,和 QK^T 后的att权重维度等同 [batch_szie, seq_len, seq_len]
pad_mask = pad_mask.unsqueeze(1).expand(batch_size, seq_len, seq_len) # (batch_size, num_heads, seq_len, seq_len)
att_weights = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # 点积操作# 因为是多头,所以mask矩阵维度要扩充到4维 [batch_size, seq_len, seq_len] -> [batch_size, nums_head, seq_len, seq_len]
pad_mask = pad_mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1)
att_weights.masked_fill_(pad_mask, float('-inf')) # 将填充位置对应的元素设置为负无穷
att_weights = torch.softmax(att_weights, dim=-1) # 在最后一个维度上进行softmaxcontext = torch.matmul(att_weights, V) # (batch_size, num_heads, seq_len, emb_dim)六、Cross Attention
理解上面了,cross-attention就更简单了,它用于处理两个不同模态序列之间的关联,在多模态场景中用于将文本和图像等不同类型的数据进行交互处理:


七、代码实现
7.1 self-attention
class SelfAttention(nn.Module):def __init__(self, emb_dim):super(SelfAttention, self).__init__()self.emb_dim = emb_dimself.Wq = nn.Linear(emb_dim, emb_dim, bias=False)self.Wk = nn.Linear(emb_dim, emb_dim, bias=False)self.Wv = nn.Linear(emb_dim, emb_dim, bias=False)self.fc = nn.Linear(emb_dim, emb_dim)def forward(self, x, pad_mask=None):# [batch_szie, seq_len, emb_dim] = [3, 5, 512]Q = self.Wq(x)K = self.Wk(x)V = self.Wv(x)att_weights = torch.bmm(Q, K.transpose(1, 2)) # [batch_szie, seq_len, seq_len] = [3, 5, 5]att_weights = att_weights / math.sqrt(self.emb_dim)if pad_mask is not None:att_weights = att_weights.masked_fill(pad_mask, -1e9)att_weights = F.softmax(att_weights, dim=-1)output = torch.bmm(att_weights, V) # [batch_szie, seq_len, emb_dim] = [3, 5, 512]output = self.fc(output)return output, att_weights
7.2 Multi-Head Attention
class MultiHeadAttention(nn.Module):def __init__(self, emb_dim, num_heads, att_dropout=0.0):super(MultiHeadAttention, self).__init__()self.emb_dim = emb_dimself.num_heads = num_headsself.att_dropout = att_dropoutassert emb_dim % num_heads == 0, "emb_dim must be divisible by num_heads"self.depth = emb_dim // num_headsself.Wq = nn.Linear(emb_dim, emb_dim, bias=False)self.Wk = nn.Linear(emb_dim, emb_dim, bias=False)self.Wv = nn.Linear(emb_dim, emb_dim, bias=False)self.fc = nn.Linear(emb_dim, emb_dim)def forward(self, x, pad_mask=None):# [batch_szie, seq_len, emb_dim] = [3, 5, 512]batch_size = x.size(0)# [batch_szie, seq_len, emb_dim] = [3, 5, 512]Q = self.Wq(x)K = self.Wk(x)V = self.Wv(x)# 分头 [batch_szie, num_heads, seq_len, depth] = [3, 8, 5, 512/8=64]Q = Q.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)K = K.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)V = V.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)# [batch_szie, num_heads, seq_len, seq_len] = [3, 8, 5, 5]att_weights = torch.matmul(Q, K.transpose(-2, -1))att_weights = att_weights / math.sqrt(self.depth)if pad_mask is not None:# 因为是多头,所以mask矩阵维度要扩充到4维 [batch_size, seq_len, seq_len] -> [batch_size, nums_head, seq_len, seq_len]pad_mask = pad_mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1)att_weights = att_weights.masked_fill(pad_mask, -1e9)att_weights = F.softmax(att_weights, dim=-1)# 自己的多头注意力效果没有torch的好,我猜是因为它的dropout给了att权重,而不是fcif self.att_dropout > 0.0:att_weights = F.dropout(att_weights, p=self.att_dropout)# [batch_szie, num_heads, seq_len, depth] = [3, 8, 5, 64]output = torch.matmul(att_weights, V)# 不同头的结果拼接 [batch_szie, seq_len, emb_dim] = [3, 5, 512]output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.emb_dim)output = self.fc(output)return output, att_weights
7.3 Cross_MultiAttention
class Cross_MultiAttention(nn.Module):def __init__(self, in_channels, emb_dim, num_heads, att_dropout=0.0, aropout=0.0):super(Cross_MultiAttention, self).__init__()self.emb_dim = emb_dimself.num_heads = num_headsself.scale = emb_dim ** -0.5assert emb_dim % num_heads == 0, "emb_dim must be divisible by num_heads"self.depth = emb_dim // num_headsself.proj_in = nn.Conv2d(in_channels, emb_dim, kernel_size=1, stride=1, padding=0)self.Wq = nn.Linear(emb_dim, emb_dim)self.Wk = nn.Linear(emb_dim, emb_dim)self.Wv = nn.Linear(emb_dim, emb_dim)self.proj_out = nn.Conv2d(emb_dim, in_channels, kernel_size=1, stride=1, padding=0)def forward(self, x, context, pad_mask=None):''':param x: [batch_size, c, h, w]:param context: [batch_szie, seq_len, emb_dim]:param pad_mask: [batch_size, seq_len, seq_len]:return:'''b, c, h, w = x.shapex = self.proj_in(x) # [batch_size, c, h, w] = [3, 512, 512, 512]x = rearrange(x, 'b c h w -> b (h w) c') # [batch_size, h*w, c] = [3, 262144, 512]Q = self.Wq(x) # [batch_size, h*w, emb_dim] = [3, 262144, 512]K = self.Wk(context) # [batch_szie, seq_len, emb_dim] = [3, 5, 512]V = self.Wv(context)Q = Q.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2) # [batch_size, num_heads, h*w, depth]K = K.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2) # [batch_size, num_heads, seq_len, depth]V = V.view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)# [batch_size, num_heads, h*w, seq_len]att_weights = torch.einsum('bnid,bnjd -> bnij', Q, K)att_weights = att_weights * self.scaleif pad_mask is not None:# 因为是多头,所以mask矩阵维度要扩充到4维 [batch_size, h*w, seq_len] -> [batch_size, nums_head, h*w, seq_len]pad_mask = pad_mask.unsqueeze(1).repeat(1, self.num_heads, 1, 1)att_weights = att_weights.masked_fill(pad_mask, -1e9)att_weights = F.softmax(att_weights, dim=-1)out = torch.einsum('bnij, bnjd -> bnid', att_weights, V)out = out.transpose(1, 2).contiguous().view(batch_size, -1, self.emb_dim) # [batch_size, h*w, emb_dim]print(out.shape)out = rearrange(out, 'b (h w) c -> b c h w', h=h, w=w) # [batch_size, c, h, w]out = self.proj_out(out) # [batch_size, c, h, w]return out, att_weights
7.4 Cross Attention
class CrossAttention(nn.Module):def __init__(self, in_channels, emb_dim, att_dropout=0.0, aropout=0.0):super(CrossAttention, self).__init__()self.emb_dim = emb_dimself.scale = emb_dim ** -0.5self.proj_in = nn.Conv2d(in_channels, emb_dim, kernel_size=1, stride=1, padding=0)self.Wq = nn.Linear(emb_dim, emb_dim)self.Wk = nn.Linear(emb_dim, emb_dim)self.Wv = nn.Linear(emb_dim, emb_dim)self.proj_out = nn.Conv2d(emb_dim, in_channels, kernel_size=1, stride=1, padding=0)def forward(self, x, context, pad_mask=None):''':param x: [batch_size, c, h, w]:param context: [batch_szie, seq_len, emb_dim]:param pad_mask: [batch_size, seq_len, seq_len]:return:'''b, c, h, w = x.shapex = self.proj_in(x) # [batch_size, c, h, w] = [3, 512, 512, 512]x = rearrange(x, 'b c h w -> b (h w) c') # [batch_size, h*w, c] = [3, 262144, 512]Q = self.Wq(x) # [batch_size, h*w, emb_dim] = [3, 262144, 512]K = self.Wk(context) # [batch_szie, seq_len, emb_dim] = [3, 5, 512]V = self.Wv(context)# [batch_size, h*w, seq_len]att_weights = torch.einsum('bid,bjd -> bij', Q, K)att_weights = att_weights * self.scaleif pad_mask is not None:# [batch_size, h*w, seq_len]att_weights = att_weights.masked_fill(pad_mask, -1e9)att_weights = F.softmax(att_weights, dim=-1)out = torch.einsum('bij, bjd -> bid', att_weights, V) # [batch_size, h*w, emb_dim]out = rearrange(out, 'b (h w) c -> b c h w', h=h, w=w) # [batch_size, c, h, w]out = self.proj_out(out) # [batch_size, c, h, w]print(out.shape)return out, att_weights
7.5 main
# coding:utf-8
# @Email: wangguisen@donews.com
# @Time: 2023/3/22 22:58
# @File: att_test.py
'''
Self Attention
Multi-Head Attention
Cross Attention
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange, repeat
from torch.nn import MultiheadAttentionif __name__ == '__main__':'''''''''假设词表映射后输入 batch_size = 3seq_len = max_len = 5pad = 0emb_dim = 512'''batch_size = 3seq_len = 5emb_dim = 512# 本例子则词表大小为 301vocab_size = 301input_ids = torch.tensor([[100, 200, 300, 300, 0],[22, 33, 44, 0, 0],[66, 55, 66, 30, 0]], dtype=torch.long)pad_mask = input_ids.eq(0) # 逻辑矩阵pad_mask:将填充位置标记为True,其他位置标记为False# pad_mask = pad_mask.unsqueeze(1).expand(batch_size, seq_len, seq_len) # [batch_size, seq_len, seq_len] = [3, 5, 5]inputs = nn.Embedding(vocab_size, embedding_dim=emb_dim)(input_ids) # [batch_szie, seq_len, emb_dim] = [3, 5, 512]# self_att = SelfAttention(emb_dim=emb_dim)# self_att(inputs, pad_mask=pad_mask)# multi_att = MultiHeadAttention(emb_dim=emb_dim, num_heads=8)# multi_att(inputs, pad_mask=pad_mask)# 定义图片数据 [batch_size, c, h, w]input_img = torch.randn((3, 3, 512, 512))pad_mask = pad_mask.unsqueeze(1).expand(batch_size, 512*512, seq_len)# cross_att = Cross_MultiAttention(in_channels=3, emb_dim=emb_dim, num_heads=8, att_dropout=0.0, aropout=0.0)# cross_att(x=input_img, context=inputs, pad_mask=pad_mask)cross_att = CrossAttention(in_channels=3, emb_dim=emb_dim, att_dropout=0.0, aropout=0.0)cross_att(x=input_img, context=inputs, pad_mask=pad_mask)